Adaptive Weight Assignment Scheme For Multi-task Learning
Adaptive Weight Assignment Scheme For Multi-task Learning
| 题目 | Adaptive Weight Assignment Scheme For Multi-task Learning |
|---|---|
| 译题 | 用于多任务学习的自适应权重分配方案 |
| 时间 | 2022年 |
| 期刊/会议 | IAES International Journal of Artificial Intelligence (IJ-AI) |
摘要:如今,基于深度学习的模型在每一个应用程序中都定期得到了使用。一般来说,我们在一项任务上训练一个模型。然而,在多任务学习设置下,我们可以在单个模型上训练多个任务。这为我们提供了许多优点,如更少的训练时间、为多个任务训练单个模型、减少过拟合、提高性能等。要在多任务学习环境中训练模型,我们需要对不同任务的损失值求和。在普通的多任务学习设置中,我们分配相同的权重,但由于并非所有任务的难度都相似,我们需要为难度更大的任务分配更多的权重。此外,不适当的权重分配也会降低模型的性能。我们在本文中提出了一个简单的权重分配方案,它提高了模型的性能,并更加重视困难的任务。我们测试了我们的方法在图像和文本数据上的性能,并将性能与两种流行的权重分配方法进行了比较。经验结果表明,与其他流行的方法相比,我们提出的方法取得了更好的结果。
1. 引言
从过去十年开始,深度学习方法就被广泛应用于各种应用中。它不仅在计算机科学领域,而且在电气工程、土木工程、机械工程和其他领域都取得了巨大的突破。这是因为深度神经网络(DNN)在图像分类[1]、问答[2]、唇语[3]、视频游戏[4]等各种应用中都达到了人类水平。DNNs 能够在没有任何帮助的情况下找出输入数据的复杂和隐藏特征。以前,这些模型依赖于手工制作的功能[5-10]。
人类有能力同时执行多个任务,而不会损害任何任务的性能。人类经常这样做,并且能够决定哪些任务可以同时完成。这就是为什么近年来人们把很多注意力放在使用 DNN 方法的多任务学习上。通常,一个模型专门用于执行一个任务。然而,执行多个任务可以提高模型的性能,减少训练时间和过拟合[11]。通常,我们发现单个任务的数据集很小,但如果任务以某种方式相关,那么我们可以使用这些共享信息并构建一个足够大的数据集,这将减少这个问题。目前,在多任务学习领域,一些研究工作正在进行,以创建用于多任务学习设置的新DNN架构[12,13],决定哪些任务应该一起学习[14],如何为损失值分配权重[15,16]等。在这项研究工作中,我们专注于创建一种动态权重分配技术,该技术将在训练过程中为每个时期的损失值分配不同的权重。在我们的研究工作中,我们提出了一种为所有损失值分配权重的新方法,并在图像和文本领域使用的两个数据集上进行了测试。我们的研究工作贡献如下。
1)我们提出了一种用于多任务学习的直观损失加权方案;
2)我们使用两个不同的数据集,针对图像和文本领域测试了我们的方法。我们这样做是为了确保我们的方法在所有领域都表现良好;
3)我们将我们的方法与两种流行的权重分配方案进行了比较,以比较我们方法的性能。
2. 研究方法
在本节中,我们将对该领域先前的研究工作进行讨论。接下来,我们将提供我们提出的方法。
2.1 文献综述
R.Caruana[11]提供了关于多任务学习的最早论文之一。在手稿中,作者探讨了多任务学习的思想,并展示了它在不同数据集下的有效性。作者还解释了多任务学习是如何工作的,以及如何将其用于反向传播。为了训练基于多任务学习设置的DNN,我们需要考虑哪些网络层在所有任务之间共享,哪些层用于单个任务。此前,大多数研究工作都集中在硬参数共享概念上[17-19]。在这种情况下,用户定义可共享的层,直到特定的点,然后为每个任务分配所有层。还有软参数共享的概念,其中对于网络中的所有任务存在单个列。在所有网络中设计了一种特殊的机制来共享参数。这种方法的流行方法是Cross-Sitch[13]、Sluich[20]等。最近提出了一种名为 Ada-share 的新方法,其中模型动态学习为所有任务共享哪些层,以及为单个任务使用哪些层[14]。作者还提出了一种新的损失函数,以确保模型的紧凑性和性能。
权重分配是多任务学习领域中一项非常关键的任务。以前的权重要么是相等的值,要么是研究人员指定的一些手动调整值[18,21,22]。然而,在多任务学习模型需要执行大量任务的情况下,这种方法是不够的。[15]提出了一种基于不确定性的方法。后来[12]提出了这种方法的修订方法。在本文中,作者通过添加正则化项来改进先前的基于不确定性的方法。[12]提出了动态权重平均法。在这种方法中,作者计算了前两个时期损失值的相对变化,并对这些值使用 softmax 函数来获得权重。[23]对不同的权重分配方案进行了比较研究。然而,除了图像,他们没有在任何领域研究这些方法。此外,他们使用的数据集只有2个任务。
2.2 自适应权重分配
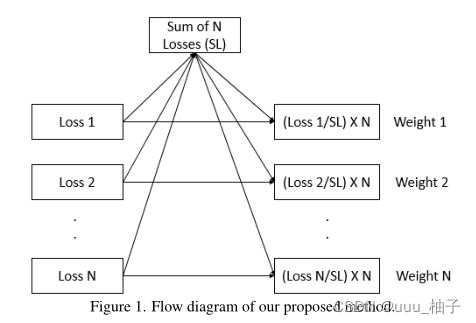
我们提出的方法很简单,它考虑了(take into account of )每个 epoch 中每个任务的损失值。与其他方法相比,我们的方法易于实现。通常,在多任务学习设置中,为了训练模型,我们需要将所有损失值与其权重相加,然后执行反向传播(backpropagation)以更新模型的权重。这种损失的总和可以表示为:
∑ i = 1 , 2 , . . . , n W i L i = W 1 L 1 + W 2 L 2 + . . . + W n L n ( 1 ) \displaystyle\sum_{i=1,2,...,n}W_iL_i=W_1L_1+W_2L_2+...+W_nL_n\kern15em(1) i=1,2,...,n∑WiLi=W1L1+W2L2+...+WnLn(1)
这里, W W W 对应于损失的权重, L L L 表示每个任务的损失。在普通的(vanilla)多任务学习设置中,所有权重都设置为1。然而,我们必须记住(keep in mind),并非所有的任务都是相同的。有些任务比其他任务更难,因此我们需要为困难任务提供更多的权重,以提高整体多任务学习系统的性能。这就是我们提出 算法1 的原因。我们的算法基于一个简单的概念,即困难的任务比容易的任务具有更多的损失值。因此,我们应该更多地强调或加权这些损失值,同时为较小的损失值分配较少的权重。我们所做的是取每个任务的损失值之和,并用它来计算单个任务的损失价值占总损失的比例。我们将这个值与任务总数相乘。一般来说,在普通的多任务学习设置中,所有损失值都具有相等的权重1。因此,对于 n 个任务,总重量为 n 。这就是为什么我们将比率与 n 相乘。最后,我们使用这些权重并使用方程(1)计算多任务学习模型的总损失。图1 提供了该方法的可视化表示(visual representation )。设计损失加权方案的重要一点是,我们需要确保这些权重计算方法不会花费大量时间,因为这会增加训练时间。表1提供了关于执行这些方案(包括我们的方法)所需时间的图表。从表中我们可以看出,尽管我们的方法不是计算权重最快的方法,但它肯定不是最慢的。此外,最快的方法和我们的方法之间的时间差非常小。

3. 结果与讨论
我们将在这部分讨论数据集、实验设置和实验结果。
3.1 数据集描述
在实验中,我们使用了两个不同的数据集。他们是 CIFAR-100[24] 和 AGNews[25]。前者是基于图像的,后者是基于文本的。由于这些数据集是为单任务学习而设计的,我们为多任务学习设置创建了人工任务。我们从 CIFAR-100 中创建了 5 个不同的任务,从 AGNews 数据集中创建了 2 个任务。所有任务都是基于原始任务标签创建的,我们将不同的标签组合在一起形成多个任务。创建任务是为了确保所有任务都不存在类不平衡。
3.2 实验设置
我们用两个不同的 DNN 模型进行实验。我们使用 WRN(wide resnet-28-10) 处理 CIFAR-100 数据集和对 AGNews 数据集使用了自定义的 DNN 。我们将 WRN 模型的最后一层划分为 CIFAR-100 的 5 个输出层和AGNews数据集的 2 个输出层。我们使用 SGD 优化器训练了 100 个 epoch 的 WRN 模型,并将学习率设置为 0.001。我们还使用了单周期学习速率调度器[27]。为了训练 AGNews 数据集,我们首先对数据集进行标记化,并在此基础上创建一个词汇词典。然后我们对将成为模型输入的文本进行嵌入。我们的自定义 DNN 由两个全连接的层组成。我们使用 SGD 优化器训练了这个模型。为了确保我们的方法的有效性,我们将我们提出的方法与两种最先进的方法进行了比较,即动态加权平均(DWA)和不确定度方法。我们还比较了单任务学习和普通多任务设置。
3.3 实验结果
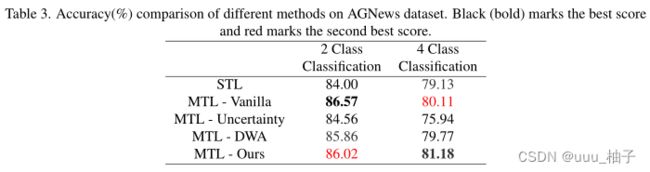
我们将在本节中讨论我们的方法对两个数据集的性能。表 2 和表 3 代表了我们整个实验的结果。我们在图 2 中绘制了 CIFAR-100 和 AGNews 数据集的测试损失曲线。
在表 2 中,我们得到了在 CIFAR-100 数据集上运行实验的结果,该数据集是一个图像数据集。一开始,我们在单个任务学习设置中获得了所有五项任务的结果。也就是说,为了得到这五项任务的结果,对五个不同的模型进行了训练。接下来,在多任务学习设置下,我们为这些任务训练了四种方法。在普通的多任务学习中,我们为每个 epoch 的每个任务分配了相等的权重。其他方法不确定性、DWA 和我们的方法在每个 epoch 中更新权重。从这个表中,我们可以看到我们提出的方法在五分之三的任务中优于其他方法。此外,我们的方法在剩下的两项任务中获得了第二好的性能。我们可以看到,多任务学习模型比 STL 模型表现得更好,而且我们只需要为所有五个任务训练一个模型。

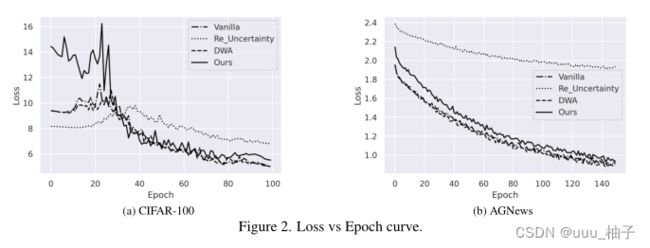
我们在包含文本数据的 AGNews 数据集上评估我们的方法性能。我们有两个任务,一开始我们为这两个任务训练两个单独的模型。之后,我们用不同的权重分配方案训练四个多任务学习模型。我们可以从表中观察到,我们提出的方法在一项任务下表现良好,在另一项任务中得分第二。与其他流行的方法相比,我们可以看到我们提出的方法性能要好得多。如果我们仔细观察这些值,就会发现其他方法无法达到最佳效果。在某些情况下,这些方法甚至无法获得比单任务学习方法更好的性能。我们认为这是由于模型架构对多任务学习设置的性能有很大影响。在我们的实验中,我们专注于统一的DNN 架构进行评估,但有些任务可能需要一些额外的卷积或完全连接层。如果我们进一步强调 DNN架构,那么我们提出的方法在这两项任务中的性能肯定会更好。我们认为,在分配权重时应该采取更简单的方法。由于这一步骤是在每次迭代中执行的,过多的参数化和复杂的方法思想会阻碍模型的性能并增加时间复杂性。
4. 总结
理解并正确执行不同的超参数对于训练 DNN 模型以获得最佳结果至关重要。当涉及到所需的数据量、训练模型的时间、减少过拟合和提高模型性能时,多任务学习设置在单任务学习中占据上风。在多任务学习设置中,由于并非所有任务都具有相同的难度,因此为损失值分配权重对于更加强调困难任务很重要。在本文中,我们提出了一种新的权重分配方案,该方案有助于提高多任务学习模型的性能。我们提出的方法在图像和文本领域都优于其他最先进的权重分配方案,并提高了模型的性能。