suricata -- 流管理系统
本文章主要讲解Flow是怎么循环利用的,包含工作线程使用与超时处理,管理线程超时处理等,最后在文章末尾以Flow流转图示总结。
suricata中使用 流(Flow)来管理一个会话。考虑到避免频繁分配释放Flow内存,suricata实现了流管理机制来回收与重复利用Flow。不同状态的Flow主要在Flow哈希表,Flow备用队列,Flow回收队列三个队列中流转。suricata使用不同线程维护这三个队列,这个在之前的文章中有所提及。
三种结构的形态
Flow哈希表: 这个是FlowBucket *flow_hash 数组,数据大小为配置中的 flow_config 的 hash_size,其在数组中的每一个FlowBucket元素中都挂了一串之前数据包对应的Flow链队列。
Flow备用队列: static FlowSparePool *flow_spare_pool 备用池链队列,其每一个链pool中都挂载一个备用Flow队列。
Flow回收队列: FlowQueue flow_recycle_q 回收队列,挂载一个备用Flow队列。
使用Flow来管理一个会话
先看看Flow是怎样管理一个会话的。当一个数据包来到时,首先计算数据包对应的hash值,在后续的模块中将使用这个hash 在Flow哈希表中找到 FlowBucket ,不同会话的hash值可能相同,所以不是比较hash相同来定位Flow,而是在篮子里顺序查找具有相同五元组和vlan的Flow,找到则利用此Flow。若Flow哈希表中没有,则在Flow备用队列取出一个Flow, 或是新建一个Flow使用,同时把这个Flow插入到Flow哈希表。这样相同五元组和vlan信息的包就可以对应同一个Flow,这个Flow就能管理这一个会话。下面我们看一看hash是怎么获取的。
数据包的hash
同一个会话使用一个Flow管理,而依据则是数据包的hash值。数据包的hash值就算依据为五元组和vlan等信息,每一个数据包的hash是在decode模块中调用void FlowSetupPacket(Packet *p) 函数获取的,在此函数中有static inline uint32_t FlowGetHash(const Packet *p),将数据包的五元组和vlan等信息填充到 fhk 中,然后再调用 hashword 函数计算hash值。
static inline uint32_t FlowGetHash(const Packet *p)
{
uint32_t hash = 0;
if (p->ip4h != NULL) {
if (p->tcph != NULL || p->udph != NULL) {
FlowHashKey4 fhk;
int ai = (p->src.addr_data32[0] > p->dst.addr_data32[0]);
fhk.addrs[1-ai] = p->src.addr_data32[0];
fhk.addrs[ai] = p->dst.addr_data32[0];
const int pi = (p->sp > p->dp);
fhk.ports[1-pi] = p->sp;
fhk.ports[pi] = p->dp;
fhk.proto = (uint16_t)p->proto;
fhk.recur = (uint16_t)p->recursion_level;
/* g_vlan_mask sets the vlan_ids to 0 if vlan.use-for-tracking
* is disabled. */
fhk.vlan_id[0] = p->vlan_id[0] & g_vlan_mask;
fhk.vlan_id[1] = p->vlan_id[1] & g_vlan_mask;
hash = hashword(fhk.u32, 5, flow_config.hash_rand);
}
...
}
...
return hash;
}Flow的一生
Flow的创建
Flow根据分配时机分为两种,一种是在主线程初始化时就预先分配,一种是在不够时再创建,这两种就好比战争前征兵和战争时抓的壮丁。
预先分配
在初始化时根据配置中flow.prealloc预分配一定数量的Flow, 在函数void FlowSparePoolInit(void) 中调用static bool FlowSparePoolUpdateBlock(FlowSparePool *p) 分配。FlowSparePoolInit 函数每一次循环创建一个FlowSparePool 新节点,并把这个FlowSparePool 新节点插入到Flow备用队列 flow_spare_pool 的前面,FlowSparePoolUpdateBlock函数则创建flow_spare_pool_block_size多个Flow,并附加到FlowSparePool 新节点中。
void FlowSparePoolInit(void)
{
SCMutexLock(&flow_spare_pool_m);
for (uint32_t cnt = 0; cnt < flow_config.prealloc; ) {
FlowSparePool *p = FlowSpareGetPool();
if (p == NULL) {
FatalError(SC_ERR_FLOW_INIT, "failed to initialize flow pool");
}
FlowSparePoolUpdateBlock(p);
cnt += p->queue.len;
/* prepend to list */
p->next = flow_spare_pool;
flow_spare_pool = p;
flow_spare_pool_flow_cnt = cnt;
}
SCMutexUnlock(&flow_spare_pool_m);
}
static bool FlowSparePoolUpdateBlock(FlowSparePool *p)
{
DEBUG_VALIDATE_BUG_ON(p == NULL);
for (uint32_t i = p->queue.len; i < flow_spare_pool_block_size; i++)
{
Flow *f = FlowAlloc();
if (f == NULL)
return false;
FlowQueuePrivateAppendFlow(&p->queue, f);
}
return true;
}代码中,flow_spare_pool_block_size = 100,则可以计算出预先分配的Flow量为
(flow.prealloc / 100 + 1) * 100。
实时创建
在备用池中没有Flow时,则需要现创建一个Flow, 在函数static Flow *FlowGetNew(ThreadVars *tv, FlowLookupStruct *fls, const Packet *p)中调用f = FlowAlloc();
workThread对Flow的操作
当新数据到达flowworker模块时,如果Flow哈希表 中没有与此数据包对应的Flow时,则从上面的创建中获取一个Flow并加入到Flow哈希表中的某一个篮子里的最前面。
Flow *prev_f = NULL; /* previous flow */
f = fb->head;
do {
Flow *next_f = NULL;
const bool timedout =
(fb_nextts < (uint32_t)p->ts.tv_sec && FlowIsTimedOut(f, (uint32_t)p->ts.tv_sec, emerg));
if (timedout) {
FromHashLockTO(f);//FLOWLOCK_WRLOCK(f);
if (f->use_cnt == 0) {
next_f = f->next;
MoveToWorkQueue(tv, fls, fb, f, prev_f);
/* flow stays locked, ownership xfer'd to MoveToWorkQueue */
goto flow_removed;
}
FLOWLOCK_UNLOCK(f);
} else if (FlowCompare(f, p) != 0) {
FromHashLockCMP(f);//FLOWLOCK_WRLOCK(f);
/* found a matching flow that is not timed out */
if (unlikely(TcpSessionPacketSsnReuse(p, f, f->protoctx) == 1)) {
f = TcpReuseReplace(tv, fls, fb, f, hash, p);
if (f == NULL) {
FBLOCK_UNLOCK(fb);
return NULL;
}
}
FlowReference(dest, f);
FBLOCK_UNLOCK(fb);
return f; /* return w/o releasing flow lock */
}
/* unless we removed 'f', prev_f needs to point to
* current 'f' when adding a new flow below. */
prev_f = f;
next_f = f->next;
flow_removed:
if (next_f == NULL) {
f = FlowGetNew(tv, fls, p);
if (f == NULL) {
FBLOCK_UNLOCK(fb);
return NULL;
}
/* flow is locked */
f->next = fb->head;
fb->head = f;
/* initialize and return */
FlowInit(f, p);
f->flow_hash = hash;
f->fb = fb;
FlowUpdateState(f, FLOW_STATE_NEW);
FlowReference(dest, f);
FBLOCK_UNLOCK(fb);
return f;
}
f = next_f;
} while (f != NULL);遍历找到的FlowBucket 中的Flow, 先判断是否超时,若超时则调用
static inline void MoveToWorkQueue(ThreadVars *tv, FlowLookupStruct *fls, FlowBucket *fb, Flow *f, Flow *prev_f) 函数将这个超时Flow从Flow哈希表 中移除,再根据情况将这个Flow放入到fls->work_queue 或是 fb->evicted中。
static inline void MoveToWorkQueue(ThreadVars *tv, FlowLookupStruct *fls,
FlowBucket *fb, Flow *f, Flow *prev_f)
{
/* remove from hash... */
if (prev_f) {
prev_f->next = f->next;
}
if (f == fb->head) {
fb->head = f->next;
}
if (f->proto != IPPROTO_TCP || FlowBelongsToUs(tv, f)) { // TODO thread_id[] direction
f->fb = NULL;
f->next = NULL;
FlowQueuePrivateAppendFlow(&fls->work_queue, f);
} else {
/* implied: TCP but our thread does not own it. So set it
* aside for the Flow Manager to pick it up. */
f->next = fb->evicted;
fb->evicted = f;
if (SC_ATOMIC_GET(f->fb->next_ts) != 0) {
SC_ATOMIC_SET(f->fb->next_ts, 0);
}
FLOWLOCK_UNLOCK(f);
}
}放入 fb->evicted中的Flow在FlowManager线程中加入Flow回收队列中,然后在recycler线程中将Flow回收队列中的数据转移到全局的Flow备用队列。
放入 fls->work_queue中则在本workThread中的后续处理中将Flow放入到本线程的备用队列或者是全局的备用队列。
管理线程对Flow的操作
管理线程主要是回收不用的或者是超时的Flow,在下面两篇文章有详述:
FlowManagerThread:将Flow哈希表中超时的流放入Flow回收队列。
FlowRecyclerThread:将Flow回收队列中的Flow清空信息并插入到Flow备用队列。
上述就是Flow在工作线程和管理线程中被处理,同时在三种队列结构中流转的详细情况。
Flow如浮萍,飘摇一生,下面以Flow的流转的总结图来结束。
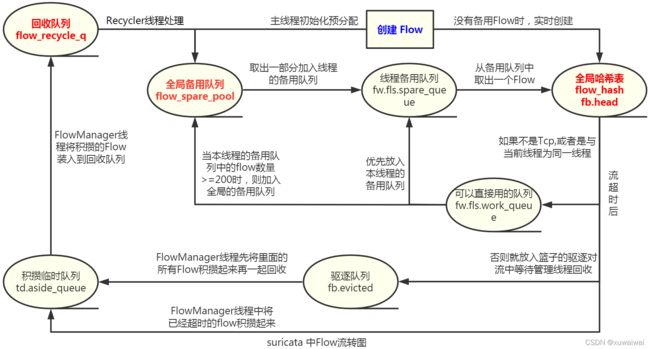
凡是过往,皆为序章