大数据项目(基于spark)--新冠疫情防控指挥作战平台项目
大数据项目(基于spark)–新冠疫情防控指挥作战平台项目
文章目录
- 第一章 项目介绍
-
- 1.1 项目背景
- 1.2 项目架构
- 1.3 项目截图
- 1.4 功能模块
- 第二章 数据爬取
-
- 2.1 数据清单
- 2.2 疫情数据爬取
-
- 2.2.1 环境准备
-
- 2.2.1.1 pom.xml
- 2.2.1.2 application.properties
- 2.2.2 工具类
-
- 2.2.2.1 HttpUtils
- 2.2.2.2 TimeUtils
- 2.2.2.3 KafkaProducerConfig
- 2.2.2.4 RoundRobinPartitioner
- 2.2.3 实体类
-
- 2.2.3.1 CovidBean
- 2.2.3.2 MaterialBean
- 2.2.4 入口程序
- 2.2.5 数据爬取
- 2.3 防疫数据生成
- 第三章 实时数据处理和分析
-
- 3.1. 环境准备
-
- 3.1.1. pom.xml
- 3.1.2. 工具类
-
- 3.1.2.1. OffsetUtil
- 3.1.2.2. BaseJdbcSink
- 3.1.3. 样例类
-
- 3.1.3.1. CovidBean
- 3.1.3.2. StatisticsDataBean
- 3.2. 物资数据实时处理与分析
- 3.3. 疫情数据实时处理与分析
- 第四章 实时数据展示
-
- 4.1. 环境准备
-
- 4.1.1. pom.xml
- 4.1.2. application.properties
- 4.1.3. 静态资源
- 4.2. Echarts入门
-
- 4.2.1. 介绍
- 4.2.2. 入门案例
- 4.3. SpringBoot+Echarts实现数据可视化
-
- 4.3.1. 实体类
- 4.3.2. Mapper
- 4.3.3. Controller
- 4.3.4. index.html
- 第五章 博雅云SaaS平台实现大屏展示
-
- 5.1. 云平台三种模式
-
- 5.1.1. Iaas、Paas、Saas
- 5.1.2. 通俗理解
- 5.2. 博雅云SaaS平台介绍
- 5.3. 博雅云应用案例
-
- 5.3.1. 智慧应用集成管理平台
- 5.3.2. 智慧城市应用中台——领导驾驶舱平台
- 5.3.3. 城市业务平台——城市交通平台
- 5.3.4. 城市舆情监测平台
- 5.4. 云平台组件使用
-
- 5.4.1. 使用流程
- 5.4.2. 连接数据
- 5.4.3. 创建探索
- 5.4.4. 创建大屏
- 5.4.5. 创建项目
- 5.5. 基于云平台实现大屏展示
- 总结
- 附件
-
- 项目效果图
- 数据分享
-
- 数据1:area_trend_chart_data68.json
- 资料网盘分享
第一章 项目介绍
1.1 项目背景
新冠疫情防控指挥作战平台项目的需求由传智播客提出,北京大数据研究院博雅智慧公司策划,双方共同研发。项目实现了疫情态势、基层防控、物资保障、复工复产等多个专题板块,包括新冠疫情防控指挥大屏子系统和新冠疫情防控指挥平台后台管理子系统。
通过新冠疫情防控指挥作战平台的建设及实施,使得从局部作战到中心指挥,让战“疫”指挥官对疫情防控心中有“数”,科学决策,下好疫情防控、救治、复工复产“一盘棋”,更高效地帮助防疫指挥部开展统筹、协调、决策工作,尽快打赢疫情防控战役。
1.2 项目架构
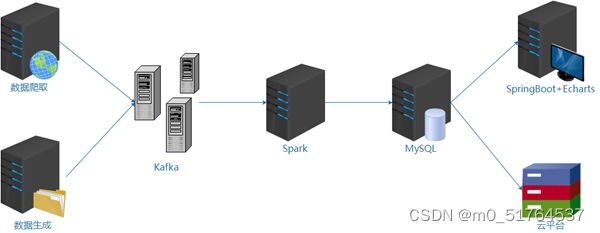
1.3 项目截图
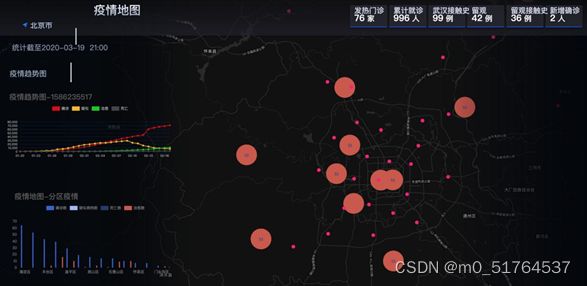
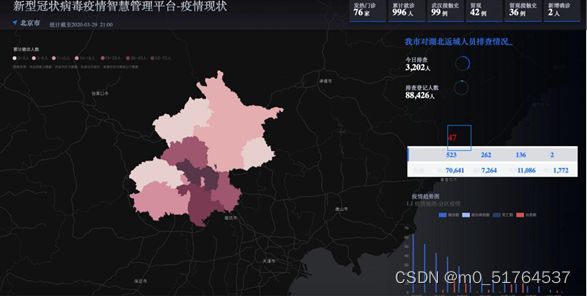
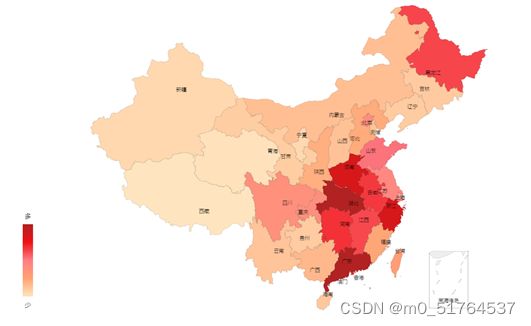
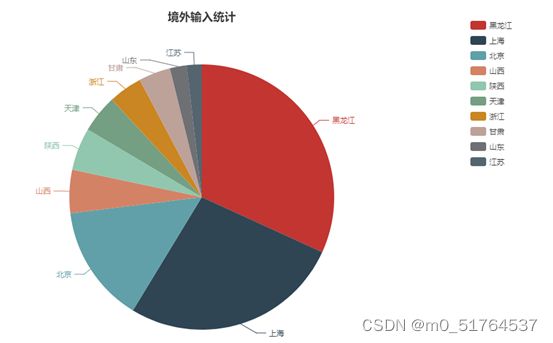
1.4 功能模块
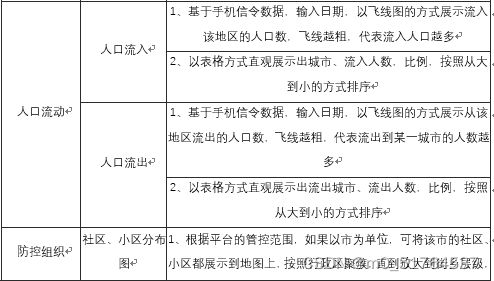
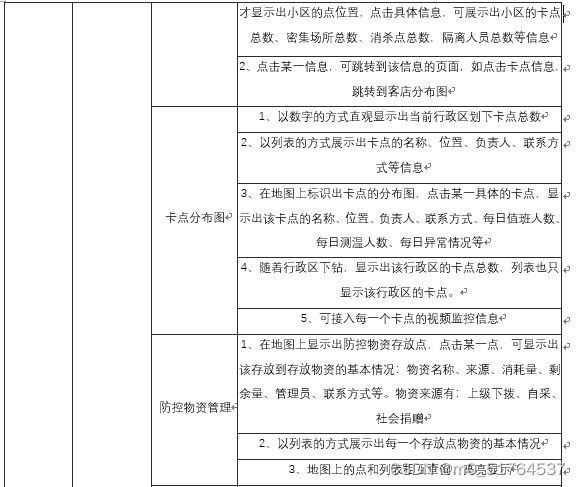
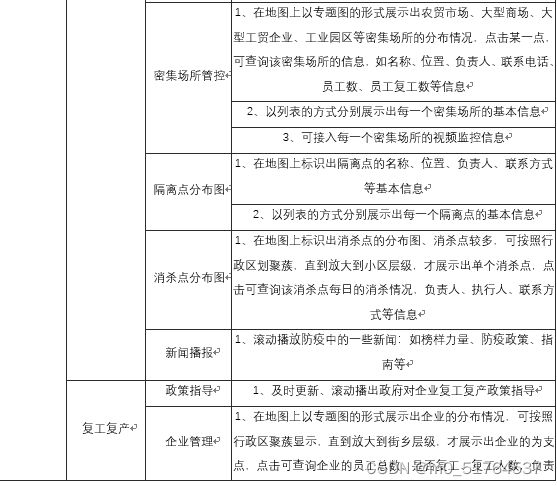
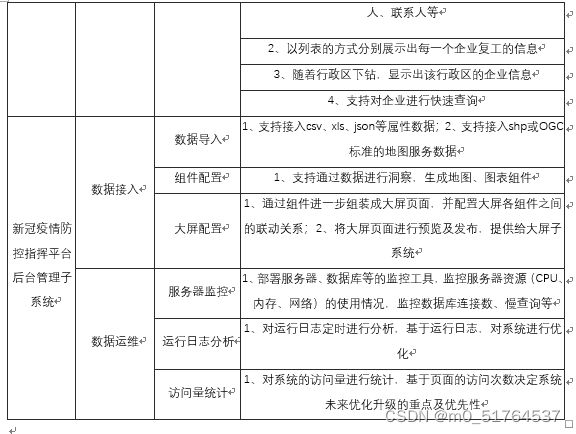
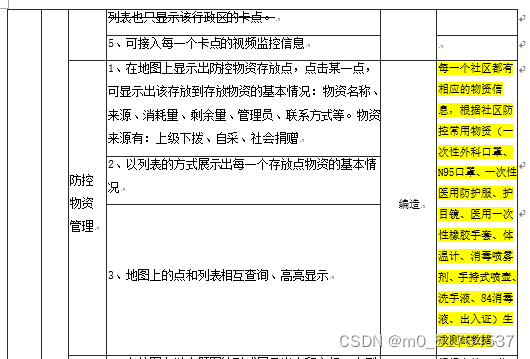
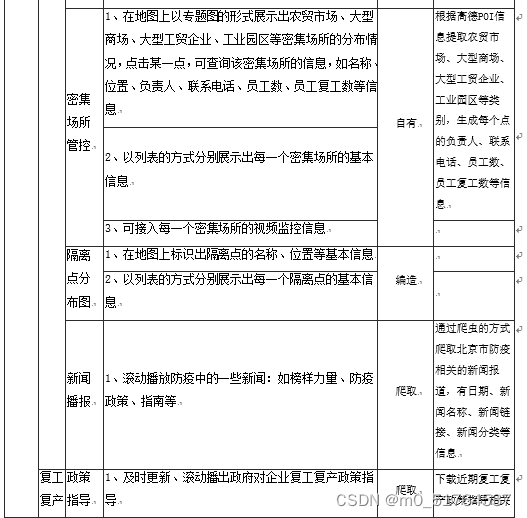
新冠疫情防控指挥作战平台包括新冠疫情防控指挥大屏子系统和新冠疫情防控指挥平台后台管理子系统,其中大屏子系统提供给用户使用,后台管理系统提供给管理员及运维人员使用,每个子系统对应的模块级功能点、功能描述如下表所示。
| 子系统 | 模块名称 | 功能名称 | 功能名说明 |
|---|---|---|---|
| 新冠疫情防控指挥大屏子系统 | 疫情地图 | 各区疫情 | 1、以数字、各区填色图或各区密度图的方式展示出本地确诊、疑似、死亡、治愈、境外输入人数的总数、较昨日新增及在各区的分布情况 |
| 2、专题地图可按照行政区逐级下钻,如市、区县、街乡,下钻后展示的数字是当前行政区层级的汇总 | |||
| 3、以图表的方式展示境外输入趋势、疫情新增趋势(新增确诊人数、新增疑似病例)、累计确诊趋势(累计确诊人数、累计疑似人数)、治愈出院趋势(出院人数、住院人数)、患者类型趋势(普通型、重型、危重)、患者男女比例、患者年龄分布等。横轴为日期、纵轴为人数 | |||
| 4、以图表的方式展示境外输入趋势、疫情新增趋势(新增确诊人数、新增疑似病例)、累计确诊趋势(累计确诊人数、累计疑似人数)、治愈出院趋势(出院人数、住院人数)、患者类型趋势(普通型、重型、危重)、患者男女比例、患者年龄分布等。横轴为行政区名称、纵轴为人数,并且随着行政区下钻,横轴所示的行政区会自动下钻到下一级的行政区 | |||
| 患者轨迹 | 1、对确诊患者在地图上以连续的OD连线的方式展示患者的轨迹;2、以列表的方式直观展示出患者的行程 | ||
| 医疗救治 | 1、在地图上标识出各地区的发热门诊分布情况,点击某一点,可展示出该门诊的病人数、剩余床位数等信息 | ||
| 疫情小区 | 在地图上标出确诊患者所在小区的分布图,点击某一点,可展示出小区的位置、楼数、患者所在的楼编号等信息 | ||
| 传染关系 | 传染关系 | 1、根据确诊患者、疑似患者上报的接触人及接触地点,生成患者传染关系图;每一个患者就是一个节点,点击各节点显示患者基本信息及密切接触者个数,点击各节点间联系显示患者间相互关系。节点大小反应其密切接触者人数;2.可通过行政区快速过滤该行政区内的节点 |

第二章 数据爬取
2.1 数据清单




2.2 疫情数据爬取
2.2.1 环境准备
2.2.1.1 pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<artifactId>crawlerartifactId>
<parent>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-parentartifactId>
<version>2.2.7.RELEASEversion>
<relativePath/>
parent>
<groupId>cn.itcastgroupId>
<version>0.0.1-SNAPSHOTversion>
<properties>
<java.version>1.8java.version>
properties>
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
<dependency>
<groupId>org.springframework.kafkagroupId>
<artifactId>spring-kafkaartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-devtoolsartifactId>
<scope>runtimescope>
<optional>trueoptional>
dependency>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
<optional>trueoptional>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-testartifactId>
<scope>testscope>
<exclusions>
<exclusion>
<groupId>org.junit.vintagegroupId>
<artifactId>junit-vintage-engineartifactId>
exclusion>
exclusions>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>fastjsonartifactId>
<version>1.2.22version>
dependency>
<dependency>
<groupId>org.apache.httpcomponentsgroupId>
<artifactId>httpclientartifactId>
<version>4.5.3version>
dependency>
<dependency>
<groupId>org.jsoupgroupId>
<artifactId>jsoupartifactId>
<version>1.10.3version>
dependency>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<version>4.12version>
dependency>
<dependency>
<groupId>org.apache.commonsgroupId>
<artifactId>commons-lang3artifactId>
<version>3.7version>
dependency>
<dependency>
<groupId>commons-iogroupId>
<artifactId>commons-ioartifactId>
<version>2.6version>
dependency>
<dependency>
<groupId>org.slf4jgroupId>
<artifactId>slf4j-log4j12artifactId>
<version>1.7.25version>
dependency>
dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-maven-pluginartifactId>
plugin>
plugins>
build>
project>

2.2.1.2 application.properties
server.port=9999
#kafka
#服务器地址
kafka.bootstrap.servers=node01:9092,node02:9092,node03:9092
#重试发送消息次数
kafka.retries_config=0
#批量发送的基本单位,默认16384Byte,即16KB
kafka.batch_size_config=4096
#批量发送延迟的上限
kafka.linger_ms_config=100
#buffer内存大小
kafka.buffer_memory_config=40960
#主题
kafka.topic=covid19
2.2.2 工具类
2.2.2.1 HttpUtils
package cn.itcast.util;
import org.apache.http.client.config.RequestConfig;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.impl.conn.PoolingHttpClientConnectionManager;
import org.apache.http.util.EntityUtils;
import java.util.ArrayList;
import java.util.List;
import java.util.Random;
public abstract class HttpUtils {
private static PoolingHttpClientConnectionManager cm;
private static List<String> userAgentList = null;
static {
cm = new PoolingHttpClientConnectionManager();
//设置最大连接数
cm.setMaxTotal(200);
//设置每个主机的并发数
cm.setDefaultMaxPerRoute(20);
userAgentList = new ArrayList<>();
userAgentList.add("Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36");
userAgentList.add("Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:73.0) Gecko/20100101 Firefox/73.0");
userAgentList.add("Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.5 Safari/605.1.15");
userAgentList.add("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 Edge/16.16299");
userAgentList.add("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36");
userAgentList.add("Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:63.0) Gecko/20100101 Firefox/63.0");
}
//获取内容
public static String getHtml(String url) {
CloseableHttpClient httpClient = HttpClients.custom().setConnectionManager(cm).build();
HttpGet httpGet = new HttpGet(url);
int index = new Random().nextInt(userAgentList.size());
httpGet.setHeader("User-Agent", userAgentList.get(index));
httpGet.setConfig(getConfig());
CloseableHttpResponse response = null;
try {
response = httpClient.execute(httpGet);
if (response.getStatusLine().getStatusCode() == 200) {
String html = "";
if (response.getEntity() != null) {
html = EntityUtils.toString(response.getEntity(), "UTF-8");
}
return html;
}
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
if (response != null) {
response.close();
}
// httpClient.close();//不能关闭,现在使用的是连接管理器
} catch (Exception e) {
e.printStackTrace();
}
}
return null;
}
//获取请求参数对象
private static RequestConfig getConfig() {
RequestConfig config = RequestConfig.custom().setConnectTimeout(1000)
.setConnectionRequestTimeout(500)
.setSocketTimeout(10000)
.build();
return config;
}
}
2.2.2.2 TimeUtils
package cn.itcast.util;
import org.apache.commons.lang3.time.FastDateFormat;
/**
* Author itcast
* Date 2020/5/11 14:00
* Desc
*/
public abstract class TimeUtils {
public static String format(Long timestamp,String pattern){
return FastDateFormat.getInstance(pattern).format(timestamp);
}
public static void main(String[] args) {
String format = TimeUtils.format(System.currentTimeMillis(), "yyyy-MM-dd");
System.out.println(format);
}
}
2.2.2.3 KafkaProducerConfig
package cn.itcast.util;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.common.serialization.IntegerSerializer;
import org.apache.kafka.common.serialization.StringSerializer;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.core.DefaultKafkaProducerFactory;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.core.ProducerFactory;
import java.util.HashMap;
import java.util.Map;
@Configuration // 表示该类是一个配置类
public class KafkaProducerConfig {
@Value("${kafka.bootstrap.servers}")
private String bootstrap_servers;
@Value("${kafka.retries_config}")
private String retries_config;
@Value("${kafka.batch_size_config}")
private String batch_size_config;
@Value("${kafka.linger_ms_config}")
private String linger_ms_config;
@Value("${kafka.buffer_memory_config}")
private String buffer_memory_config;
@Value("${kafka.topic}")
private String topic;
@Bean //表示方法返回值对象是受Spring所管理的一个Bean
public KafkaTemplate kafkaTemplate() {
// 构建工厂需要的配置
Map<String, Object> configs = new HashMap<>();
configs.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrap_servers);
configs.put(ProducerConfig.RETRIES_CONFIG, retries_config);
configs.put(ProducerConfig.BATCH_SIZE_CONFIG, batch_size_config);
configs.put(ProducerConfig.LINGER_MS_CONFIG, linger_ms_config);
configs.put(ProducerConfig.BUFFER_MEMORY_CONFIG, buffer_memory_config);
configs.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, IntegerSerializer.class);
configs.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
// 指定自定义分区
configs.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, RoundRobinPartitioner.class);
// 创建生产者工厂
ProducerFactory<String, String> producerFactory = new DefaultKafkaProducerFactory(configs);
// 返回KafkTemplate的对象
KafkaTemplate kafkaTemplate = new KafkaTemplate(producerFactory);
//System.out.println("kafkaTemplate"+kafkaTemplate);
return kafkaTemplate;
}
2.2.2.4 RoundRobinPartitioner
package cn.itcast.util;
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import java.util.Map;
public class RoundRobinPartitioner implements Partitioner {
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
Integer k = (Integer)key;
Integer partitions = cluster.partitionCountForTopic(topic);//获取分区数量
int curpartition = k % partitions;
//System.out.println("分区编号为:"+curpartition);
return curpartition;
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> configs) {
}
}
2.2.3 实体类
2.2.3.1 CovidBean
package cn.itcast.bean;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@NoArgsConstructor
@AllArgsConstructor
public class CovidBean {
private String provinceName;
private String provinceShortName;
private String cityName;
private Integer currentConfirmedCount;
private Integer confirmedCount;
private Integer suspectedCount;
private Integer curedCount;
private Integer deadCount;
private Integer locationId;
private Integer pid;
private String cities;
private String statisticsData;
private String datetime;
}
2.2.3.2 MaterialBean
package cn.itcast.bean;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@NoArgsConstructor
@AllArgsConstructor
public class MaterialBean {
private String name;
private String from;
private Integer count;
}
2.2.4 入口程序
package cn.itcast;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.scheduling.annotation.EnableScheduling;
@SpringBootApplication
@EnableScheduling//开启定时任务
public class Covid19ProjectApplication {
public static void main(String[] args) {
SpringApplication.run(Covid19ProjectApplication.class, args);
}
}
2.2.5 数据爬取
package cn.itcast.crawler;
import cn.itcast.bean.CovidBean;
import cn.itcast.util.HttpUtils;
import cn.itcast.util.TimeUtils;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONArray;
import com.alibaba.fastjson.JSONObject;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* Author itcast
* Date 2020/5/11 10:35
* Desc
* 查看主题:
* /export/servers/kafka/bin/kafka-topics.sh --list --zookeeper node01:2181
* 删除主题
* /export/servers/kafka/bin/kafka-topics.sh --delete --zookeeper node01:2181 --topic covid19
* 创建主题:
* /export/servers/kafka/bin/kafka-topics.sh --create --zookeeper node01:2181 --replication-factor 2 --partitions 3 --topic covid19
* 再次查看主题:
* /export/servers/kafka/bin/kafka-topics.sh --list --zookeeper node01:2181
* 启动控制台消费者
* /export/servers/kafka/bin/kafka-console-consumer.sh --bootstrap-server node01:9092 --from-beginning --topic covid19
* 启动控制台生产者
* /export/servers/kafka/bin/kafka-console-producer.sh --topic covid19 --broker-list node01:9092 *
*/
@Component
public class Covid19DataCrawler {
@Autowired
KafkaTemplate kafkaTemplate;
@Scheduled(initialDelay = 1000, fixedDelay = 1000 * 60 *60 * 12)
//@Scheduled(cron = "0 0 8 * * ?")//每天8点执行
public void crawling() throws Exception {
System.out.println("每隔10s执行一次");
String datetime = TimeUtils.format(System.currentTimeMillis(), "yyyy-MM-dd");
String html = HttpUtils.getHtml("https://ncov.dxy.cn/ncovh5/view/pneumonia");
//System.out.println(html);
Document document = Jsoup.parse(html);
System.out.println(document);
String text = document.select("script[id=getAreaStat]").toString();
System.out.println(text);
String pattern = "\\[(.*)\\]";
Pattern reg = Pattern.compile(pattern);
Matcher matcher = reg.matcher(text);
String jsonStr = "";
if (matcher.find()) {
jsonStr = matcher.group(0);
System.out.println(jsonStr);
} else {
System.out.println("NO MATCH");
}
List<CovidBean> pCovidBeans = JSON.parseArray(jsonStr, CovidBean.class);
for (CovidBean pBean : pCovidBeans) {
//System.out.println(pBean);
pBean.setDatetime(datetime);
List<CovidBean> covidBeans = JSON.parseArray(pBean.getCities(), CovidBean.class);
for (CovidBean bean : covidBeans) {
bean.setDatetime(datetime);
bean.setPid(pBean.getLocationId());
bean.setProvinceShortName(pBean.getProvinceShortName());
//System.out.println(bean);
String json = JSON.toJSONString(bean);
System.out.println(json);
kafkaTemplate.send("covid19",bean.getPid(),json);//发送城市疫情数据
}
String statisticsDataUrl = pBean.getStatisticsData();
String statisticsData = HttpUtils.getHtml(statisticsDataUrl);
JSONObject jsb = JSON.parseObject(statisticsData);
JSONArray datas = JSON.parseArray(jsb.getString("data"));
pBean.setStatisticsData(datas.toString());
pBean.setCities(null);
//System.out.println(pBean);
String pjson = JSON.toJSONString(pBean);
System.out.println(pjson);
kafkaTemplate.send("covid19",pBean.getLocationId(),pjson);//发送省份疫情数据,包括时间序列数据
}
System.out.println("发送到kafka成功");
}
}
2.3 防疫数据生成
package cn.itcast.generator;
import cn.itcast.bean.MaterialBean;
import com.alibaba.fastjson.JSON;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component;
import java.util.Random;
/**
* 物资 库存 需求 消耗 捐赠
* N95口罩 4293 9395 3254 15000
* 医用外科口罩 9032 7425 8382 55000
* 医用防护服 1938 2552 1396 3500
* 内层工作服 2270 3189 1028 2800
* 一次性手术衣 3387 1000 1413 5000
* 84消毒液/升 9073 3746 3627 10000
* 75%酒精/升 3753 1705 1574 8000
* 防护目镜/个 2721 3299 1286 4500
* 防护面屏/个 2000 1500 1567 3500
*/
@Component
public class Covid19DataGenerator {
@Autowired
KafkaTemplate kafkaTemplate;
@Scheduled(initialDelay = 1000, fixedDelay = 1000 * 10)
public void generate() {
System.out.println("每隔10s生成10条数据");
Random random = new Random();
for (int i = 0; i < 10; i++) {
MaterialBean materialBean = new MaterialBean(wzmc[random.nextInt(wzmc.length)], wzlx[random.nextInt(wzlx.length)], random.nextInt(1000));
String jsonString = JSON.toJSONString(materialBean);
System.out.println(materialBean);
kafkaTemplate.send("covid19_wz", random.nextInt(4),jsonString);
}
}
private static String[] wzmc = new String[]{"N95口罩/个", "医用外科口罩/个", "84消毒液/瓶", "电子体温计/个", "一次性橡胶手套/副", "防护目镜/副", "医用防护服/套"};
private static String[] wzlx = new String[]{"采购", "下拨", "捐赠", "消耗","需求"};
}
第三章 实时数据处理和分析
3.1. 环境准备
3.1.1. pom.xml
<properties>
<maven.compiler.source>1.8maven.compiler.source>
<maven.compiler.target>1.8maven.compiler.target>
<encoding>UTF-8encoding>
<scala.version>2.11.8scala.version>
<spark.version>2.2.0spark.version>
properties>
<dependencies>
<dependency>
<groupId>org.scala-langgroupId>
<artifactId>scala-libraryartifactId>
<version>${scala.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-core_2.11artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-sql_2.11artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-streaming_2.11artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-streaming-kafka-0-10_2.11artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-sql-kafka-0-10_2.11artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>com.typesafegroupId>
<artifactId>configartifactId>
<version>1.3.3version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>5.1.38version>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>fastjsonartifactId>
<version>1.2.44version>
dependency>
dependencies>
<build>
<sourceDirectory>src/main/scalasourceDirectory>
<plugins>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-compiler-pluginartifactId>
<version>3.5.1version>
plugin>
<plugin>
<groupId>net.alchim31.mavengroupId>
<artifactId>scala-maven-pluginartifactId>
<version>3.2.2version>
<executions>
<execution>
<goals>
<goal>compilegoal>
<goal>testCompilegoal>
goals>
<configuration>
<args>
<arg>-dependencyfilearg>
<arg>${project.build.directory}/.scala_dependenciesarg>
args>
configuration>
execution>
executions>
plugin>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-surefire-pluginartifactId>
<version>2.18.1version>
<configuration>
<useFile>falseuseFile>
<disableXmlReport>truedisableXmlReport>
<includes>
<include>**/*Test.*include>
<include>**/*Suite.*include>
includes>
configuration>
plugin>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-shade-pluginartifactId>
<version>2.3version>
<executions>
<execution>
<phase>packagephase>
<goals>
<goal>shadegoal>
goals>
<configuration>
<filters>
<filter>
<artifact>*:*artifact>
<excludes>
<exclude>META-INF/*.SFexclude>
<exclude>META-INF/*.DSAexclude>
<exclude>META-INF/*.RSAexclude>
excludes>
filter>
filters>
<transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>mainClass>
transformer>
transformers>
configuration>
execution>
executions>
plugin>
plugins>
build>
3.1.2. 工具类
3.1.2.1. OffsetUtil
package cn.itcast.util
import java.sql.{DriverManager, ResultSet}
import org.apache.kafka.common.TopicPartition
import org.apache.spark.streaming.kafka010.OffsetRange
import scala.collection.mutable
/*
手动维护offset的工具类
首先在MySQL创建如下表
CREATE TABLE `t_offset` (
`topic` varchar(255) NOT NULL,
`partition` int(11) NOT NULL,
`groupid` varchar(255) NOT NULL,
`offset` bigint(20) DEFAULT NULL,
PRIMARY KEY (`topic`,`partition`,`groupid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
*/
object OffsetUtil {
//从数据库读取偏移量
def getOffsetMap(groupid: String, topic: String):mutable.Map[TopicPartition, Long] = {
val connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/bigdata?characterEncoding=UTF-8", "root", "root")
val pstmt = connection.prepareStatement("select * from t_offset where groupid=? and topic=?")
pstmt.setString(1, groupid)
pstmt.setString(2, topic)
val rs: ResultSet = pstmt.executeQuery()
val offsetMap: mutable.Map[TopicPartition, Long] = mutable.Map[TopicPartition, Long]()
while (rs.next()) {
offsetMap += new TopicPartition(rs.getString("topic"), rs.getInt("partition")) -> rs.getLong("offset")
}
rs.close()
pstmt.close()
connection.close()
offsetMap
}
//将偏移量保存到数据库
def saveOffsetRanges(groupid: String, offsetRange: Array[OffsetRange]) = {
val connection = DriverManager
.getConnection("jdbc:mysql://localhost:3306/bigdata?characterEncoding=UTF-8", "root", "root")
//replace into表示之前有就替换,没有就插入
val pstmt = connection.prepareStatement("replace into t_offset (`topic`, `partition`, `groupid`, `offset`) values(?,?,?,?)")
for (o <- offsetRange) {
pstmt.setString(1, o.topic)
pstmt.setInt(2, o.partition)
pstmt.setString(3, groupid)
pstmt.setLong(4, o.untilOffset)
pstmt.executeUpdate()
}
pstmt.close()
connection.close()
}
}
3.1.2.2. BaseJdbcSink
package cn.itcast.process
import java.sql.{Connection, DriverManager, PreparedStatement}
import org.apache.spark.sql.{ForeachWriter, Row}
abstract class BaseJdbcSink(sql:String) extends ForeachWriter[Row] {
var conn: Connection = _
var ps: PreparedStatement = _
override def open(partitionId: Long, version: Long): Boolean = {
conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/bigdata?characterEncoding=UTF-8","root","root")
true
}
override def process(value: Row): Unit = {
realProcess(sql,value)
}
def realProcess(sql:String,value: Row)
override def close(errorOrNull: Throwable): Unit = {
if (conn != null) {
conn.close
}
if (ps != null) {
ps.close()
}
}
}
3.1.3. 样例类
3.1.3.1. CovidBean
package cn.itcast.bean
case class CovidBean(
provinceName: String,
provinceShortName: String,
cityName: String,
currentConfirmedCount: Int,
confirmedCount: Int,
suspectedCount: Int,
curedCount: Int,
deadCount: Int,
locationId: Int,
pid: Int,
cities: String,
statisticsData: String,
datetime: String
)
3.1.3.2. StatisticsDataBean
package cn.itcast.bean
case class StatisticsDataBean(
var dateId: String,
var provinceShortName: String,
var locationId:Int,
var confirmedCount: Int,
var currentConfirmedCount: Int,
var confirmedIncr: Int,
var curedCount: Int,
var currentConfirmedIncr: Int,
var curedIncr: Int,
var suspectedCount: Int,
var suspectedCountIncr: Int,
var deadCount: Int,
var deadIncr: Int
)
3.2. 物资数据实时处理与分析
package cn.itcast.process
import java.sql.{Connection, DriverManager, PreparedStatement}
import cn.itcast.util.OffsetUtil
import com.alibaba.fastjson.{JSON, JSONObject}
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.TopicPartition
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.{SparkConf, SparkContext, streaming}
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, HasOffsetRanges, KafkaUtils, LocationStrategies, OffsetRange}
import scala.collection.mutable
object Covid19WZDataProcessTask {
def main(args: Array[String]): Unit = {
//1.创建ssc
val conf: SparkConf = new SparkConf().setAppName("WordCount").setMaster("local[*]")
val sc: SparkContext = new SparkContext(conf)
sc.setLogLevel("WARN")
val ssc: StreamingContext = new StreamingContext(sc, streaming.Seconds(5))
ssc.checkpoint("./sscckp")
//2.准备Kafka的连接参数
val kafkaParams: Map[String, Object] = Map[String, Object](
"bootstrap.servers" -> "node01:9092,node02:9092,node03:9092", //kafka集群地址
"key.deserializer" -> classOf[StringDeserializer], //key的反序列化类型
"value.deserializer" -> classOf[StringDeserializer], //value的反序列化类型
//消费发给Kafka需要经过网络传输,而经过网络传输都需要进行序列化,即消息发给kafka需要序列化,那么从kafka消费完就得反序列化
"group.id" -> "SparkKafka", //消费者组名称
//earliest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费
//latest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据
//none:当各分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常
//这里配置latest自动重置偏移量为最新的偏移量,即如果有偏移量从偏移量位置开始消费,没有偏移量从新来的数据开始消费
"auto.offset.reset" -> "latest",
//使用手动提交offset
"enable.auto.commit" -> (false: java.lang.Boolean)
)
val topics = Array("covid19_wz")
//3.使用KafkaUtils.createDirectStream连接Kafka
//根据消费者组id和主题,查询该消费者组接下来应该从主题的哪个分区的哪个偏移量开始接着消费
val map: mutable.Map[TopicPartition, Long] = OffsetUtil.getOffsetMap("SparkKafka", "covid19_wz")
val recordDStream: InputDStream[ConsumerRecord[String, String]] = if (map.size > 0) { //表示MySQL中存储了偏移量,那么应该从偏移量位置开始消费
println("MySQL中存储了偏移量,从偏移量位置开始消费")
KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](topics, kafkaParams, map))
} else { //表示MySQL中没有存储偏移量,应该从"auto.offset.reset" -> "latest"开始消费
println("MySQL中没有存储偏移量,从latest开始消费")
KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](topics, kafkaParams))
}
val tupleDS: DStream[(String, (Int, Int, Int, Int, Int, Int))] = recordDStream.map(r => {
val jsonStr: String = r.value()
val jsonObj: JSONObject = JSON.parseObject(jsonStr)
val name: String = jsonObj.getString("name")
val from: String = jsonObj.getString("from") //"采购","下拨", "捐赠", "消耗","需求"
val count: Int = jsonObj.getInteger("count")
from match {
//"采购","下拨", "捐赠", "消耗","需求","库存"
case "采购" => (name, (count, 0, 0, 0, 0, count))
case "下拨" => (name, (0, count, 0, 0, 0, count))
case "捐赠" => (name, (0, 0, count, 0, 0, count))
case "消耗" => (name, (0, 0, 0, -count, 0, -count))
case "需求" => (name, (0, 0, 0, 0, count, 0))
}
})
val updateFunc = (currentValues: Seq[(Int, Int, Int, Int, Int, Int)], historyValue: Option[(Int, Int, Int, Int, Int, Int)]) => {
var current_cg: Int = 0
var current_xb: Int = 0
var current_jz: Int = 0
var current_xh: Int = 0
var current_xq: Int = 0
var current_kc: Int = 0
if (currentValues.size > 0) {
//循环当前批次的数据
for (i <- 0 until currentValues.size) {
current_cg += currentValues(i)._1
current_xb += currentValues(i)._2
current_jz += currentValues(i)._3
current_xh += currentValues(i)._4
current_xq += currentValues(i)._5
current_kc += currentValues(i)._6
}
//获取以前批次值
val history_cg: Int = historyValue.getOrElse((0, 0, 0, 0, 0, 0))._1
val history_xb: Int = historyValue.getOrElse((0, 0, 0, 0, 0, 0))._2
val history_jz: Int = historyValue.getOrElse((0, 0, 0, 0, 0, 0))._3
val history_xh: Int = historyValue.getOrElse((0, 0, 0, 0, 0, 0))._4
val history_xq: Int = historyValue.getOrElse((0, 0, 0, 0, 0, 0))._5
val history_kc: Int = historyValue.getOrElse((0, 0, 0, 0, 0, 0))._6
Option((
current_cg + history_cg,
current_xb + history_xb,
current_jz + history_jz,
current_xh + history_xh,
current_xq + history_xq,
current_kc+history_kc
))
} else {
historyValue //如果当前批次没有数据直接返回之前的值即可
}
}
val result: DStream[(String, (Int, Int, Int, Int, Int, Int))] = tupleDS.updateStateByKey(updateFunc)
//result.print()
/*
"采购","下拨", "捐赠", "消耗","需求","库存"
(防护目镜/副,(0,0,0,0,859,0))
(医用外科口罩/个,(725,0,0,0,0,725))
(防护面屏/个,(0,0,795,0,0,795))
(电子体温计/个,(0,0,947,0,0,947))
(N95口罩/个,(0,723,743,0,0,1466))
(手持式喷壶/个,(0,0,0,0,415,0))
(洗手液/瓶,(0,0,377,0,0,377))
(一次性橡胶手套/副,(0,1187,0,0,0,1187))
*/
result.foreachRDD(rdd=>{
rdd.foreachPartition(lines=>{
/*
CREATE TABLE `covid19_wz` (
`name` varchar(12) NOT NULL DEFAULT '',
`cg` int(11) DEFAULT '0',
`xb` int(11) DEFAULT '0',
`jz` int(11) DEFAULT '0',
`xh` int(11) DEFAULT '0',
`xq` int(11) DEFAULT '0',
`kc` int(11) DEFAULT '0',
PRIMARY KEY (`name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
*/
val conn: Connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/bigdata?characterEncoding=UTF-8","root","root")
val sql: String = "replace into covid19_wz(name,cg,xb,jz,xh,xq,kc) values(?,?,?,?,?,?,?)"
val ps: PreparedStatement = conn.prepareStatement(sql)
try {
for (row <- lines) {
ps.setString(1,row._1)
ps.setInt(2,row._2._1)
ps.setInt(3,row._2._2)
ps.setInt(4,row._2._3)
ps.setInt(5,row._2._4)
ps.setInt(6,row._2._5)
ps.setInt(7,row._2._6)
ps.executeUpdate()
}
} finally {
ps.close()
conn.close()
}
})
})
//4.提交偏移量
//我们要手动提交偏移量,那么就意味着,消费了一批数据就应该提交一次偏移量
//在SparkStreaming的DStream中,一小批数据的表现形式是RDD,也就是说我们接下来应该对DStream中的RDD进行处理,可以使用foreachRDD
recordDStream.foreachRDD(rdd =