开发常用的 Linux 命令3(文本处理、打包和压缩)
开发常用的 Linux 命令3(文本处理、打包和压缩)

作为开发者,Linux是我们必须掌握的操作系统之一。因此,在编写代码和部署应用程序时,熟练使用Linux命令非常重要。这些常用命令不得不会,掌握这些命令,工作上会事半功倍,大大提高工作效率。

五、文本处理
grep命令
分析一行的信息,若当中有我们所需要的信息,就将该行显示出来,该命令通常与管道命令一起使用,用于对一些命令的输出进行筛选加工等等
基本用法
grep [options] pattern [files]
其中,pattern 是要查找的模式,可以是普通字符串或正则表达式。files 则是要搜索的文件列表,可以是单个文件、多个文件或者使用通配符匹配多个文件。
常用选项包括:
| 选项 | 执行 |
|---|---|
-i |
忽略大小写 |
-r |
递归搜索子目录中的文件 |
-w |
只匹配整个单词,而不是部分字符串 |
-n |
显示匹配行的行号 |
-c |
统计匹配的行数 |
-v |
显示不匹配的行 |
常用案例:
1.在文件 '/var/log/messages’中查找关键词"Aug"
grep Aug /var/log/messages
2.在文件 '/var/log/messages’中查找以"Aug"开始的词汇
grep ^Aug /var/log/messages
3.选择 ‘/var/log/messages’ 文件中所有包含数字的行
grep [0-9] /var/log/messages
4.在目录 ‘/var/log’ 及随后的目录中搜索字符串"Aug"
grep Aug -R /var/log/*
5.将example.txt文件中的 “string1” 替换成 “string2”
sed 's/stringa1/stringa2/g' example.txt
6.从example.txt文件中删除所有空白行
sed '/^$/d' example.txt
7.使用正则表达式进行高级搜索。例如,要查找以数字开头的行,可以使用以下命令:
grep ^[0-9] file1.txt

paste命令
paste命令用于合并多个文件的行,将它们按列对齐并输出到标准输出。使用以下语法来使用
paste [OPTION]... [FILE]...
示例:
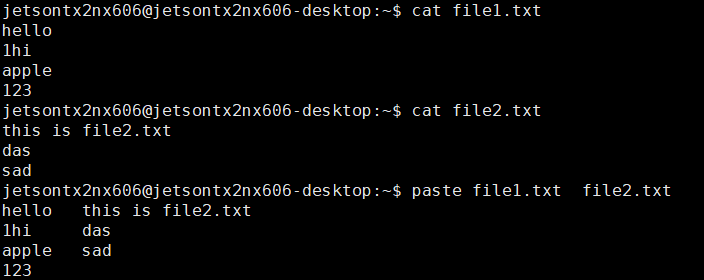
有两个文件 file1.txt 和 file2.txt,将它们的每一行合并在一起
paste file1.txt file2.txt
这将输出类似于以下内容的结果:
Line 1 from file1.txt Line 1 from file2.txt
Line 2 from file1.txt Line 2 from file2.txt
Line 3 from file1.txt Line 3 from file2.txt
2.合并两个文件或两栏的内容,中间用"+"区分
paste -d '+' file1 file2
3.如果只想合并特定的行数,可以使用 head 或 tail 命令将其与 paste 命令一起使用。例如,要合并文件 file1.txt 的前10行和文件 file2.txt 的后5行,使用以下命令:
head -n 10 file1.txt | paste -d '\t' - <(tail -n 5 file2.txt)
这将输出类似于以下内容的结果:
Line 1 from file1.txt Line 996 from file2.txt
Line 2 from file1.txt Line 997 from file2.txt
Line 3 from file1.txt Line 998 from file2.txt
Line 4 from file1.txt Line 999 from file2.txt
Line 5 from file1.txt Line 1000 from file2.txt
sort命令
用于对文本文件进行排序。
该命令的基本语法为:
sort [options] [file]
其中,[options] 为可选参数,用于控制排序的方式和输出格式;[file] 则表示要排序的文件路径。
以下是 sort 命令的一些实例:
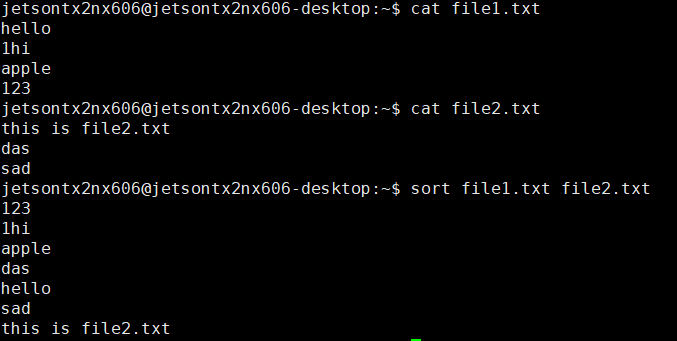
1.排序两个文件的内容
sort file1 file2
2.对文件进行反向排序:
sort -r file.txt
3.按照数值大小排序:
sort -n file.txt
4.忽略行首空格并按照第二个字段进行排序:
sort -k 2 file.txt
5.忽略行首空格并按照第二个字段进行数值排序:
sort -n -k 2 file.txt
6.取出两个文件的并集(重复的行只保留一份)
sort file1 file2 | uniq
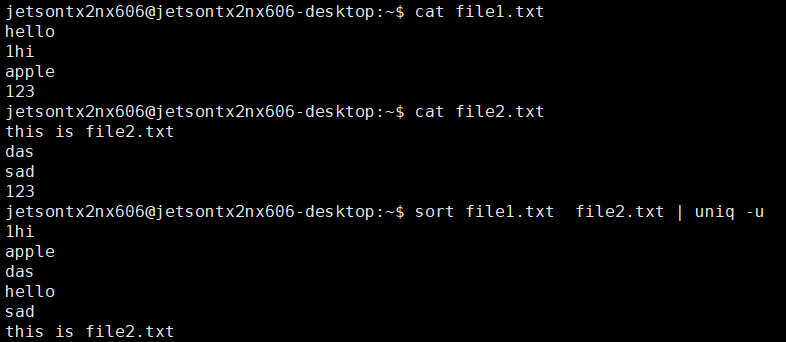
7.删除交集,留下其他的行
sort file1 file2 | uniq -u
8.取出两个文件的交集(只留下同时存在于两个文件中的文件)
sort file1 file2 | uniq -d
9.对文件file1.txt进行排序,并将结果保存到file2.txt中:
sort file1.txt > file2.txt

comm命令
comm 命令是一个用于比较两个已排序的文件行的工具。它可用于找到两个文件中共有的行、仅在第一个文件中独有的行,以及仅在第二个文件中独有的行。
comm 命令的基本语法如下:
comm [OPTION]... FILE1 FILE2
其中 FILE1 和 FILE2 是要比较的两个已排序的文件。OPTION 是一些可选的参数,可以控制输出格式等。
常用的选项包括:
| 选项 | 执行 |
|---|---|
| -1 | 隐藏仅出现在第一个文件中的行 |
| -2 | 隐藏仅出现在第二个文件中的行 |
| -3 | 隐藏同时出现在两个文件中的行 |
| -i | 在比较时忽略大小写 |
常用示例:
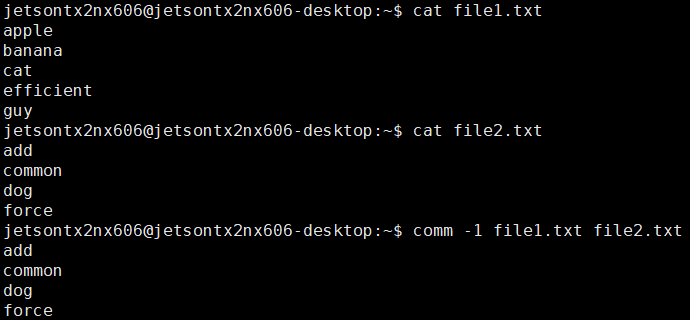
1.比较两个文件的内容只删除 ‘file1’ 所包含的内容
comm -1 file1 file2
2.比较两个文件的内容只删除 ‘file2’ 所包含的内容
comm -2 file1 file2
3.比较两个文件的内容只删除两个文件共有的部分
comm -3 file1 file2
六、打包和压缩文件
tar命令
对文件进行打包,默认情况并不会压缩,如果指定了相应的参数,它还会调用相应的压缩程序(如gzip和bzip等)进行压缩和解压
常用的选项
| 选项 | 执行 |
|---|---|
| -c | 新建打包文件 |
| -t | 查看打包文件的内容含有哪些文件名 |
| -x | 解打包或解压缩的功能,可以搭配-C(大写)指定解压的目录,注意-c,-t,-x不能同时出现在同一条命令中 |
| -j | 通过bzip2的支持进行压缩/解压缩 |
| -z | 通过gzip的支持进行压缩/解压缩 |
| -v | 在压缩/解压缩过程中,将正在处理的文件名显示出来 |
| -f | filename :filename为要处理的文件 |
| -C dir | 指定压缩/解压缩的目录dir |
常用的示例:
1.创建 tar 包
tar -cvf archive.tar file1 file2
这条命令将会创建名为 archive.tar 的归档文件,并将指定的文件(file1、file2)添加到该文件中。 -c 选项表示“创建”,-v 表示“详细”(显示出打包过程中的所有文件),-f 指定了输出的文件名。

这个图片中,原本只有file1.txt,file2.txt,filename.txt,使用tar -cvf abc.tar file1.txt file2.txt filename.txt,将它们打包
2.解压 tar 包
tar -xvf archive.tar
这条命令将会解压名为 archive.tar 的归档文件,并将其中的内容提取到当前目录中。 -x 选项表示“解压”。

这个图片中,原本只有abc.tar,使用tar -xvf abc.tar ,将它们file1.txt file2.txt filename.txt解压到当前目录
3.同时进行压缩和打包
tar -czvf archive.tar.gz file1 file2 ...
这条命令将会创建名为 archive.tar.gz 的归档文件,并将指定的文件(file1、file2)添加到该文件中,并使用 gzip 进行压缩。 -z 选项表示“使用 gzip 压缩”。
4.解压一个叫做 'file1.bz2’的文件
bunzip2 file1.bz2
5.压缩一个叫做 ‘file1’ 的文件
bzip2 file1
6.解压一个叫做 'file1.gz’的文件
gunzip file1.gz
7.压缩一个叫做 'file1’的文件
gzip file1
8.最大程度压缩
gzip -9 file1
9.创建一个叫做 ‘file1.rar’ 的包
rar a file1.rar test_file
10.同时压缩 ‘file1’, ‘file2’ 以及目录 ‘dir1’
rar a file1.rar file1 file2 dir1
11.解压rar包
rar x file1.rar
12.创建一个zip格式的压缩包
zip file1.zip file1
13.解压一个zip格式压缩包
unzip file1.zip
14.将几个文件和目录同时压缩成一个zip格式的压缩包
zip -r file1.zip file1 file2 dir1