MODRL/D-AM论文笔记
MODRL/D-AM
- 论文总结
模型流程图
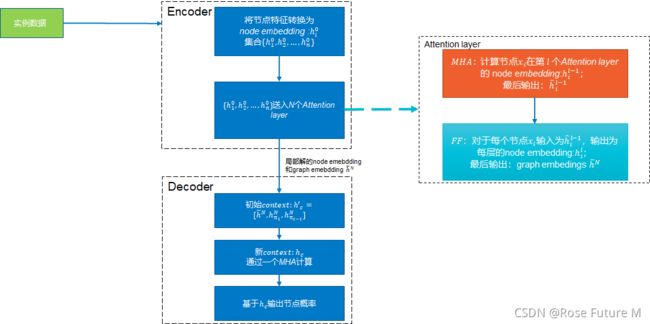
模型训练流程图:

结合NSGA-II流程图:

一、问题的定义
1.VRPTW
- 定义一个vrptw类:class VRPTW(boject)
class VRPTW(object):
2.问题的状态
- 定义StateVRPTW类
class StateVRPTW(NamedTuple):
3.问题数据集 VRPTWDataSet
- 定义VRPTWDataSet类
class VRPTWDataset(Dataset):
二、模型
1.Model——Attention Model
- 模型参数:
embedding_dim = 128,
hidden_dim = 128,
problem = vrptw,
n_encode_layers = 1,
mask_inner = True,
mask_logits = True,
normalization = batch
tanh_clipping = 10
checkpoint_encoder = False,
shrink_size = None
初始化模型:
vrptw_contenxt向量:在原来的embedding_dim的基础上+2(* remaining_capacity + current time*)
cvrp_contex向量:
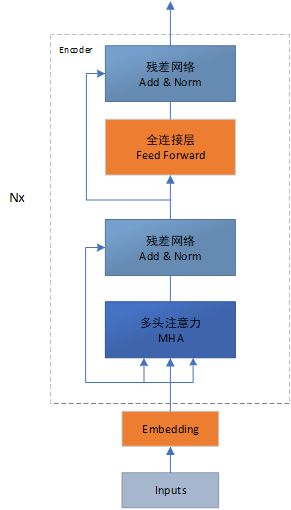
Attention Model:Encoder+Decoder
### 模型初始化
### AttentionModel组成
- 定义AttentionModel类
class AttentionModel(nn.Module):
- GraphAttentionEncoder类:
class GraphAttentionEncoder(nn.Module):
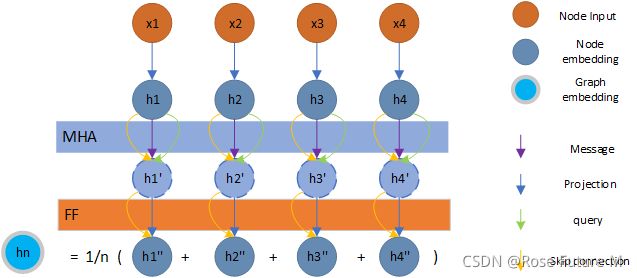
Encoder:
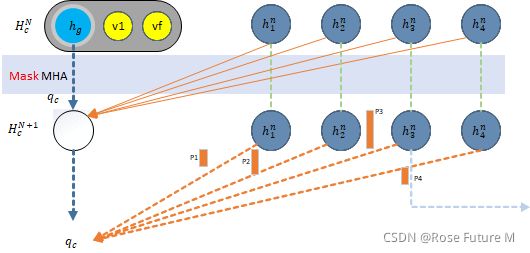
Decoder:
2.Train
总的流程:
读取参数→加载数据(如果参数有写数据路径的前提)→初始化模型AttentionModel→初始化baseline→初始化优化器Adam,并定义两个Adam分别用于更新Model参数和baseline网络参数→生成 验证数据 val_dataset(VRPTWDataset)→生成权重向量矩阵w1,w2 weights = torch.cat((w2, w1), dim=-1) →开始训练 train_epoch→train.py 的train_epoch()
训练过程:
-
设置训练步数
-
生成VRPTW训练数据
-
转换数据格式
-
设置模型的选取节点方式(sampling)
-
开始训练
定义获取训练数据
- 计算每个节点的概率和 和cost
1.Embedding()
- _init_embed()
Embedding结束,Embedding为[50,26,128]
2.根据Embedding计算概率和求解(解码过程)
_log_p, pi = self._inner(input, embeddings)
- __inner()
def _inner(self, input, embeddings):
定义下一个节点prev_nodes 和 指针prev:self.prev_nodes = None,self.prev = None
初始化输出概率列表、解集合:outputs = [ ],sequences = []
根据输入的数据初始化问题状态:state = self.problem.make_state(input)
根据Embedding计算key和用于MHA的key、values`fixed = self._precompute(embeddings)
得到batch值(每次训练抽取的实例个数):batch_size = state.ids.size(0)
开始解码:
判断节点是否全部被访问:
- 得到每个节点的概率和mask
- 概率归一化:log_p = F.log_softmax(log_p / self.temp, dim=-1)
- 返回log_p, mask
- 根据设置的选取方法(‘sampling’)得到选择的点的序列:selected = self._select_node(log_p.exp()[:, 0, :], mask[:, 0, :])
- 根据selected更新问题状态:state = state.update(selected)
- 输出概率集合outputs和节点集合selected
3.根据节点集合pi和输入数据input得到cost和mask
-
计算baseline的评价值和损失函数loss
bl_val, bl_loss = baseline.eval(x, cost, weight)算法2中的 Lφ -
计算目标函数的权重和
c = weight[0] * cost[0] + weight[1] * cost[1] -
计算强化学习的损失函数
reinforce_loss = ((c - bl_val) * log_likelihood).mean()算法2中的 dθ用于更新模型的梯度 -
计算总的损失函数
loss = reinforce_loss + bl_loss -
梯度更新
优化器梯度清零optimizer.zero_grad()
反向传播计算梯度loss.backward()
梯度裁剪grad_norms = clip_grad_norms(optimizer.param_groups, opts.max_grad_norm)
根据梯度更新网络参数 optimizer.step()
输出并保存模型
三、训练好的模型基于solomon数据进行测试
参数设置
-
加载solomon数据
-
加载五种动态性数据 list
d存放 动态性数据 -
循环100个模型生成多个解
- 1.定义为访问节点集合
- 2.定义节点id,刚开始的ID等于所有尚未访问过的结点
- 3.定义并初始mask集合 1为不可选 0 为可选
- 4.定义存储车辆的集合 prev = []
- 5.加载模型设置模型 选点方式
- 6.生成解和当前输入(动态)
![(image/image_9.png)
5. 遍历选点
根据当前点,更新mask(time、used_capactiy、)
得到的解的形式:
![(image/image_10.png)
- 7. 根据解和当前输入(动态)计算每条线路的目标值
- 8.根据当前的点和到达时间更新
- 9.更新后生成新的解
- 10.再次计算每条线路的目标值
- 11.最后规划好一条路径得到的解:
![(image/image_11.png)
- 12.计算所有解f1、f2两个函数的值
初始化两个目标函数存放tensor
保存 两个函数值
- 13.NSGA-II计算f1、f2的拥挤度
- 14.可视化
原文:MODRL/D-AM: Multiobjective Deep Reinforcement Learning Algorithm Using Decomposition and Attention Model for Multiobjective Optimization