HANA Studio-建模-长篇
文章目录
-
- 1. 建模
- 2. 数据仓库中的各种Schema
-
- 2.1 星型模型
- 2.2 雪花模型
- 2.3 星系模型
- 3. 表
-
- 3.1 SQL Editor
- 3.2 GUI Option
- 4. 包
- 5. 属性视图
-
- 5.1 属性视图的特性
- 5.2 如何创建一个属性视图
- 6. 分析视图
-
- 6.1分析视图的属性
- 6.2 怎么创建一个分析师图呢
- +7.1 calculated column(计算列)
-
- 来看下属性视图:
- 来看下分析视图:
- +7.2 输入参数和变量
- 7. 计算视图
-
- 7.1 如何创建计算视图
-
- 7.1.1 用Graphical自动创建:
- 7.1.2 用SQL脚本来创建:
- 8. 分析特权
- 9. Backup
- 10. 导出和导入
- 11.数据提供 data provisioning
-
- SLT:System Landscape Transformation
1. 建模
从HANA Modeler里面建立信息视图(基于Schema-也就是HANA数据库中的表)以用于后续报表需求。这个支持的报表就多了,可以是基于JAVA/HTML的应用(具体我不知道),也可以像是SAPAP Lumira(这个应该没几个人用)还有就是Analysis for Office啦(这个我们在用,以及前端的SAC)。
HANA 建模的话,来看看从哪里建。

每个视图呢,基于维度表和事实表的都有不同的结构。维度表是依据主数据来定义,而事实表有维度表的主键和计量值(价值啦,卖出的数量啦,总价啦)
再理解一下,事实表。一个公司卖东西给客户,每一个交易都是一个事实事情啊。那这个事实表呢,就是为了来记录这些事实事情的。卖的什么东西,卖给谁了,卖了多少钱,卖了多少个。
维度表是个啥呢,客户是一个维度,然后会有具体的信息,这个客户的编号,姓名,性别,年龄,收入水平。产品是一个维度,这个维度的编号,详细描述,规格,尺寸,颜色,大小。
度量值么,就是卖出的数量,总价值。
我记录在事实表的时候,可以只记这些维度的编号,数字总比字母啥的好处理,而且索引好搞(具体我不知道咋搞),方便易查询。跟扩展星型结构啥的有点交叉,这个还没理解透。。。基于主数据的维度在星型结构之外,通过代理键连接,主数据的更改不会影响到已经建立好的模型结构,而且也不会重复储存在系统中。
这样就来看看一个事实表,全是数字和代码:

那维度表是啥样的呢:

实际上事实表记录的第一条就是 Fred Smith这个人在 Time 4 这天买了Product 17 这个东西,买了一个。这样我们建立一个模型的时候,实际上就是把维度表的主键和事实表的一些主键相关联,然后join去取数。
维度可以复用。
最后用到报表里的时候,我们可以下钻,看到客户的其他附加信息。(得在显示或者导航属性里,在组件里的话就是直接显示了)
2. 数据仓库中的各种Schema
说实话由于我是个数据库渣渣,所以Schema这种东西我还没理解概念。很久之前看过一个视频说就是一组表的集合。具体是啥我也不知道。我来查下先:

算了 太乱了 My SQL里面Schema等于database, Oracle里面Schema就只能是database一部分,是一个人一个schema还是啥的。
反正大概就是把表信息组织连接起来,这大概是一种概念,数据库中的表有些是由关联的,有些是没有关联的。把有关联的都组织联系起来,这样就不是单纯的物理存储的表,实际上像把词语串联起来,就变成了一句有意义的话,那Schema就等于是一个有意义的行为模式,而不是单纯的表,是有逻辑的了。
英语解释的比较好:Schemas are logical description of tables in Data Warehouse. Schemas are created by joining multiple fact and Dimension tables to meet some business logic.为某种业务逻辑而建的。
数据库是使用关系模型来存储数据的。 所谓关系模型,是啥呢?就是事实表啦,事实表中的数据就是个有关系的模型(待究)
数据库中的模型有三种:
星型模型
雪花模型
星系模型
(我觉得我看的这个过时了吧,咋没有扩展星型模型呢)
2.1 星型模型
一个简单的星型模型就是这样的:

事实表中含有所有的维度表的主键值,还有一些用来分析的度量值。而且维度表中的属性可以用来分析事实表中的度量值。但是这个维度只关联到一个事实表。
2.2 雪花模型
雪花模型啥意思呢,就是在星型的小角上再做分支。那这个分支咋做,只能是在维度上面做,一样的,在维度上再延伸,那只能是让维度表中含有其他分支表的主键值,这样再做关联。
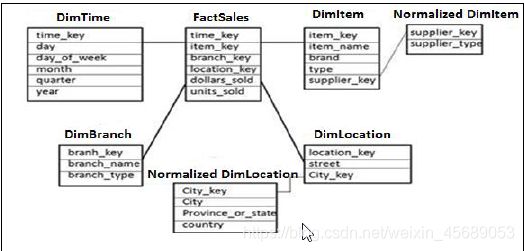
这样的一个好处就是,把维度表分裂成很多小表,这些小表关联到维度表。信息被分化,但是不是说不要这个信息了。这个分化的小表,是可以被其他事实表再复用的,也就是可以被其他模型复用,这样就减少了模型中维度表的冗余。
2.3 星系模型
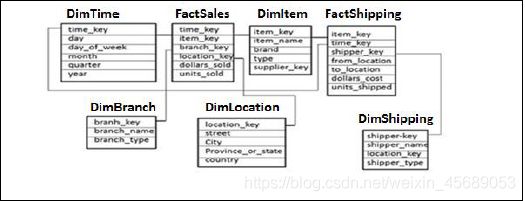
简单理解就是多个事实表混杂在一起,关联很多维度表,架构和星型是一样的。只是分析的维度和度量会更多。这个不就是过时的 BW里的Multi provider的简版概念么。

3. 表
HANA数据库中的表可以在HANA Studio中的catalog目录下的schema里面访问。也可以通过两种方法来建表:
- SQL Editor
- GUI Option
3.1 SQL Editor
来建一个试试看:需要在一个Schema下面打开SQL Console:然后写语句建表。
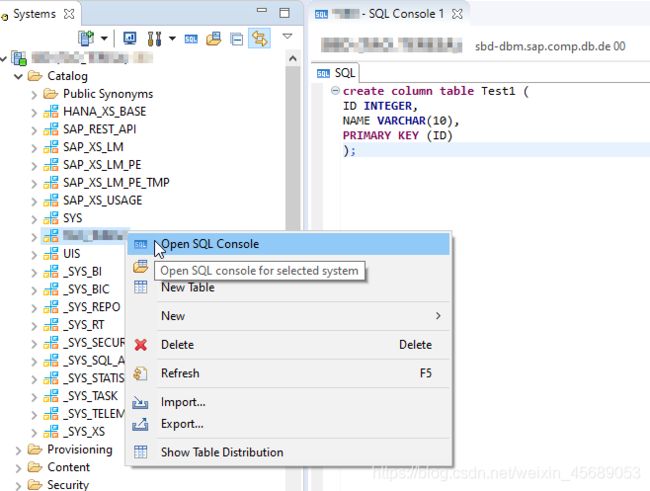
点个执行,发现建完了呢:
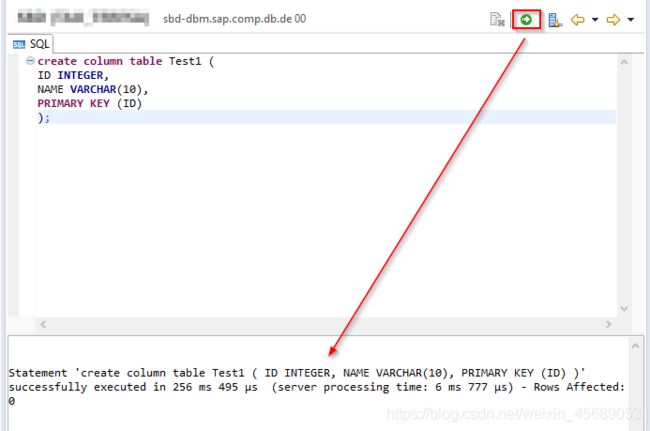
现在表建好了,在schema下面的table里面可以看到的,然后插两条数据进去:
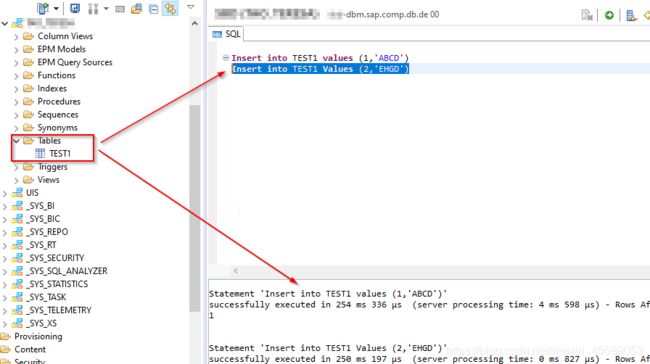
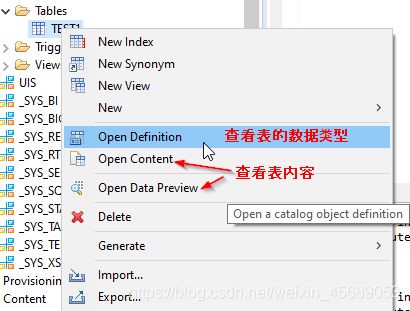

3.2 GUI Option
另外一种方式就是直接在Schema的table下面来新建,直接填写表名,表类型:列存储或行存储。再确定数据类型。

在Key上面点击设立主键(自动变成not null),然后执行,刷新table目录就可以看到建成了这个表。

点击插入数据会自动带出插入语句,执行结束后可以open data preview来查看表的数据。

如果你想用Schema下面的表来创建view,那首先你得有这个Schema的权限。可以用这个语句来赋权:(这一部分呢,就是HANA database管理员做的事情了,这个我不太知道)下次再研究吧,别人来给我们赋权。
到SQL editor下面:
GRANT SELECT ON SCHEMA“
这个_SYS_REPO代表啥内容,具体不知道。

4. 包
这个包的概念就厉害了,package这个东西,长的就像个行李箱。在哪里呢?在Content 内容下面:
所有的HANA 建模都在package下面。
你可以自己建包:
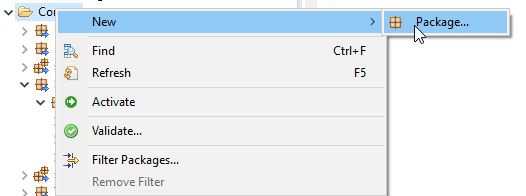
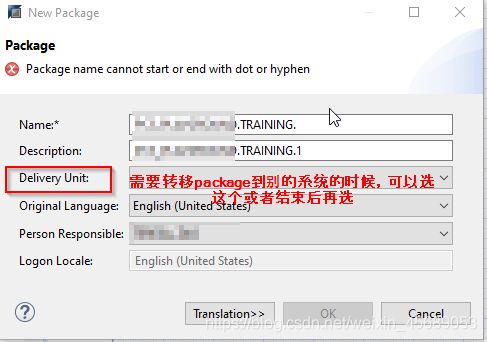
也可以在包内创建子包,如果在包上右键,你将得到7个选项,这里你可以大展拳脚:
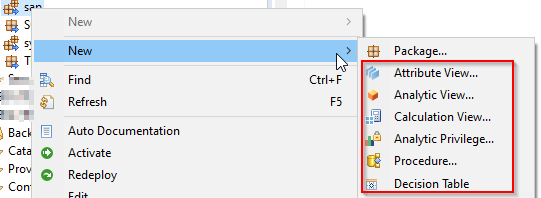
5. 属性视图
Attribute view 一看就知道,是基于维度表创建的view啊,用来和其他维度表关联或者和其他属性视图关联。那肯定的,能新建就能复制,对于已经存在的属性视图,那就肯定能从别的包复制过来,显然,复制的话,那你就改不了这个视图。
5.1 属性视图的特性
- 是用来和其他维度表或属性试图关联的。(不懂)
- 用于分析或计算视图,传递主数据的。(不懂)
- 和BW的特性类似,用来存储主数据的。(不懂)
- 用于大维度表的性能优化,你可以限制属性试图的属性个数,以用于报表或分析。(到这里的话,上面差不多懂了,是个小的维度表视图)
- 用于主数据建模,提供上下文。
5.2 如何创建一个属性视图
右键在包上,直接new 然后attribute view。
子类型会有三个,Time是指在数据基础上有附加一个时间维度。Derive这个派生的就是和copy有点像啦,但是呢,不像copy过来的还可以再更改,derive就像BW里面的reference参考啦,不能再修改。接着创建时,会有三个工作窗(work panes):这个翻译很好哈。
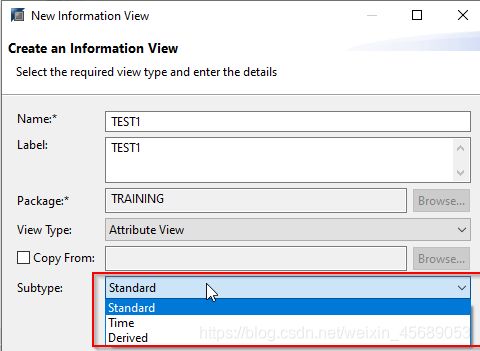
哪三个窗口呢:
- scenario,场景:这个里面是data foundation 和 semantics 语义层。End user看到的内容。
- details,细节:这个里面是data foundation里面的所有表和内部关联关系。
- output,输出:暂时不知道在哪,可以从detail里面来拖字段来过滤报表。

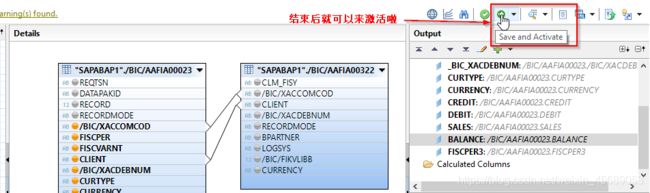
好了下面我们来看看怎么把维度表或者其他属性视图加到这个data foundation里面来,怎么去关联他们的主键。

这个join呢,一般无论在哪里,都可以选择具体的类型的:最好深入理解下数据的关系:
点击这个连接呢,就可以看到具体的连接情况了,连接方式可以选的左联啊,右连啊等等的。
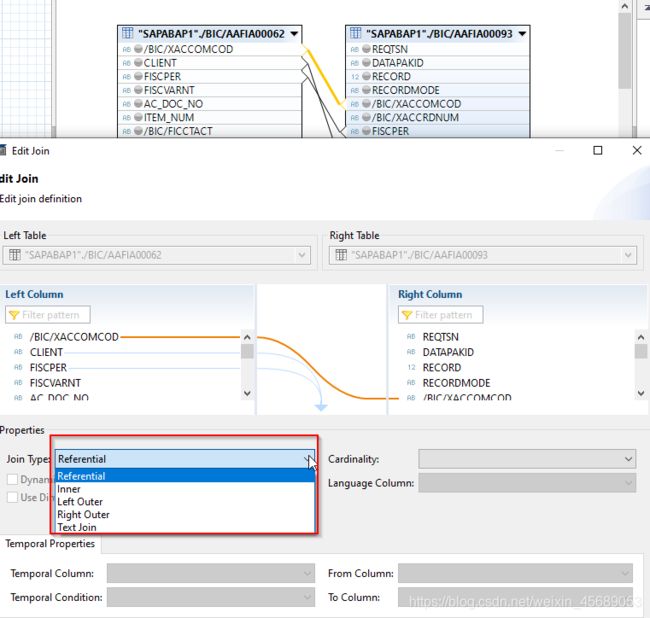
同时这个一对1 ,1对多的关系也可以改的。具体看要求。
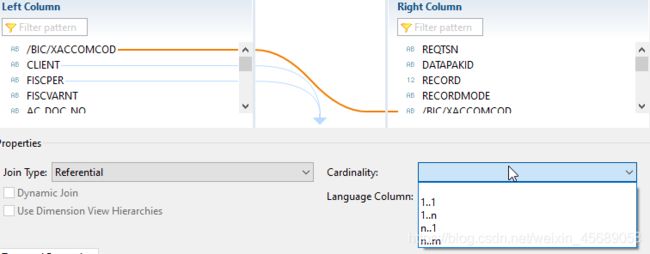
这个其实工具可以给提示的,点击validation join,它就会给你提示,让你用啥join。

接下来,要选中哪些字段要给semantics用,最后可以用于报表的。点亮小黄灯。
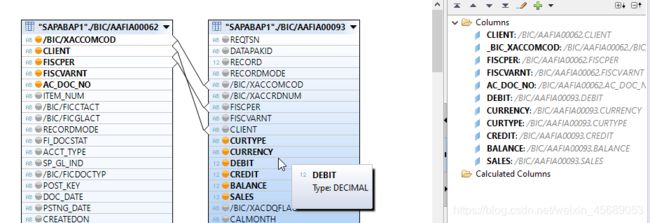
在这里还可以搞个过滤:

这会在右边的output里,点击各个字段,就可以看到字段的属性了,从哪里来的等等等等。
接下来看看semantics,这里面就是可以用于报表的字段了。可以设层级,这个有点用的。
Label就是展示在前端或报表的描述。
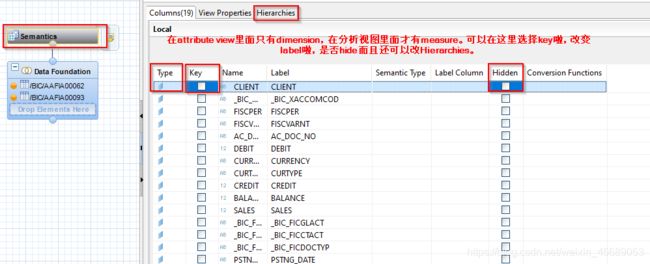
都弄完了可以直接激活,会有确认页。如果没激活,那就是这样的:带个灰色的小菱形。
![]()
然后可以查看数据了。自己玩。
6. 分析视图
分析视图嘛,就是个星型架构。一个事实表和多个维度表关联。
这就展现了HANA的实力了,因为需要执行复杂的计算和聚集功能,需要以星型架构的报表来执行分析,那就得把多个表join起来。具体咋弄呢?
6.1分析视图的属性
先来看下分析师图的属性吧。
- 这个分析视图呢,一听就知道,用来分析的。分析啥呢,复杂的计算和聚集功能啊,(那这个跟计算视图有啥区别啊,再看吧)聚集功能这个点也要知道下,包括SUM/COUNT/MIN/MAX等等。
- 初衷就是用来给星型结构的报表服务的。
- 每个分析视图都有一个事实表,然后被很多个维度表围绕。事实表肯定得包含各个维度表的主键,然后还包括度量值。这个之前讲过了。
6.2 怎么创建一个分析师图呢
还是在package的右键上建Analytic view: 
和之前的属性视图不一样了,这个Analytic view有个Star join在data foundation 上面咯。那我们怎么创建呢?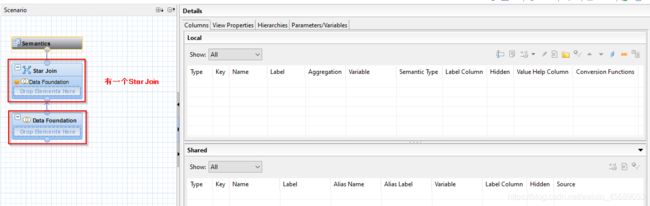
首先在data foundation里面呢,还是要加表,加维度表和事实表,那Star Join里面弄啥呢?这个里面加属性视图(这个啥意思呢:就是如果你已经有了一个属性试图,可以直接加到这个star join里面)。
首先加表,事实表里面的主键和维度表关联。关联模式双击进去选。
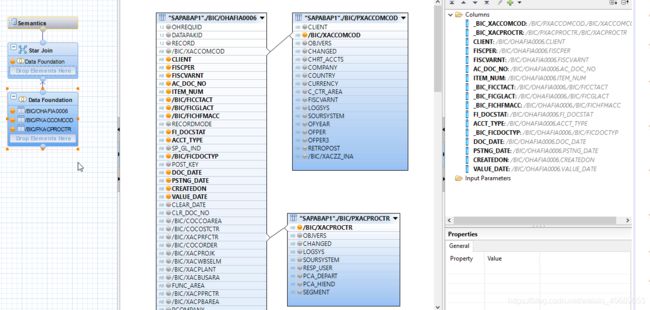
然后选择维度表和事实表里的attributes,添加到output里面。
在Star Join里面我们可以看到所有的output值了。
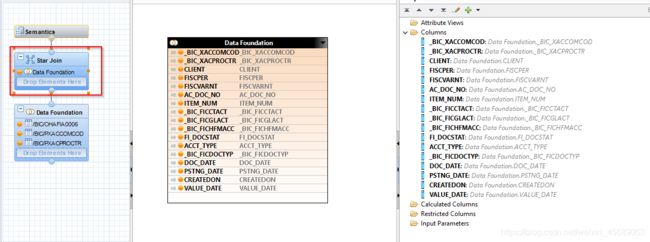
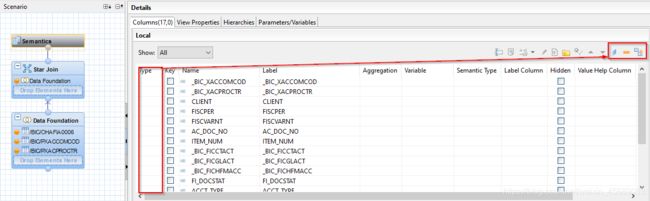
到Semantics里面呢,我们得改点东西:
在语义层,选择事实表的值,改成measure图标。然后激活这个分析视图。
我们改Type的类型,是维度呢,还是度量。还可以设置aggregation啦,Sum什么的。
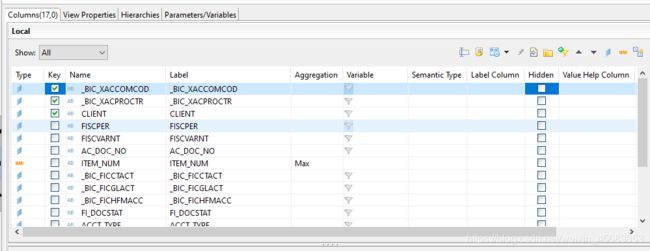
还有其他的选项可以查看。
结束后激活然后,查看或分析数据。
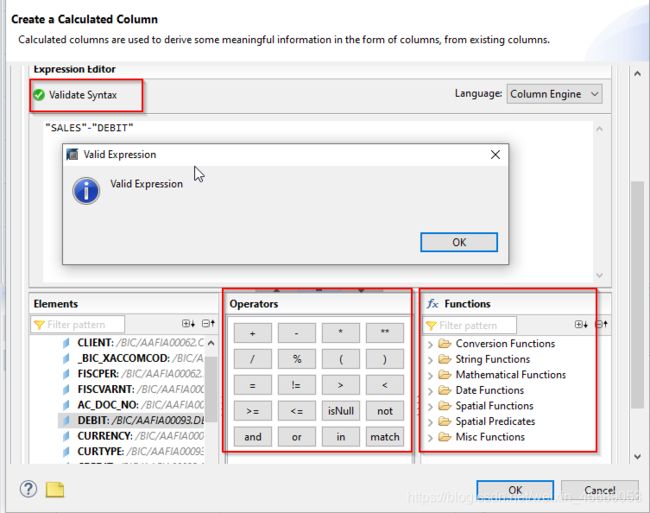
+7.1 calculated column(计算列)
是啥?是view下的客制化的应用。
假设我有个工资列表,但是我还想要加个奖金列来做个综合报表。这个奖金列的计算方式就是工资*0.2
这就是再加一个计算列:
那可以在哪里加呢?肯定不能在表上加,那只能在view里面加。
回忆一下刚才的view,有属性视图和分析视图。
来看下属性视图:
在data foundation 里面有个计算列,这里可以新建,要给出data type,length…
怎么计算呢,下面有计算方式。

来看下分析视图:
data foundation里面没有,只有个参数。
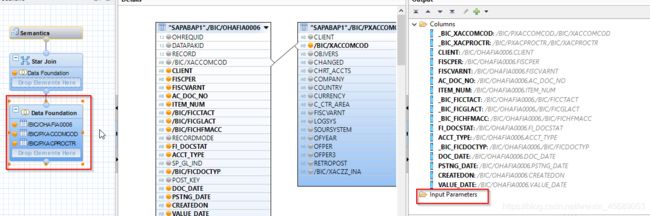
是在Star Join下面:
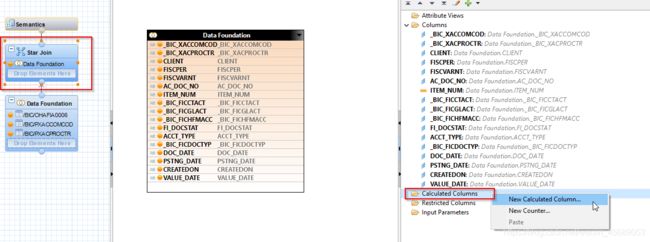
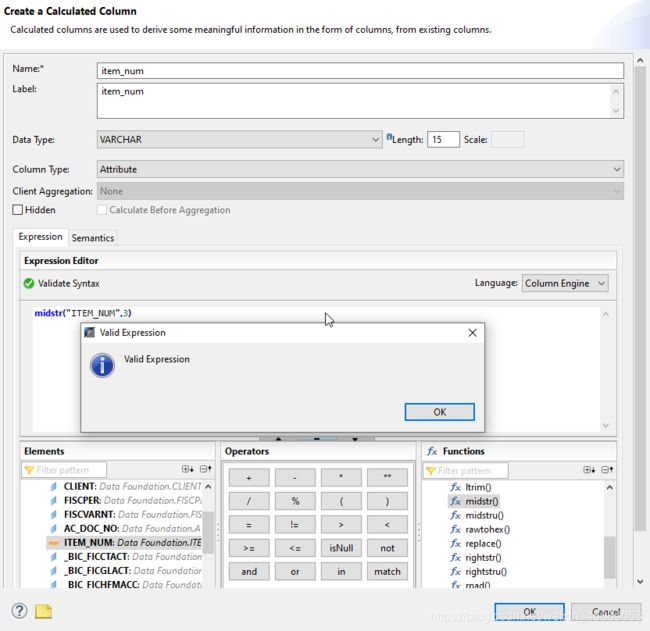
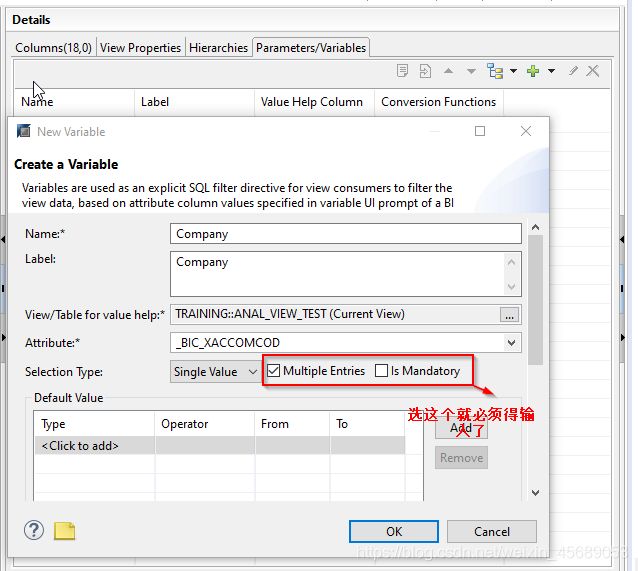
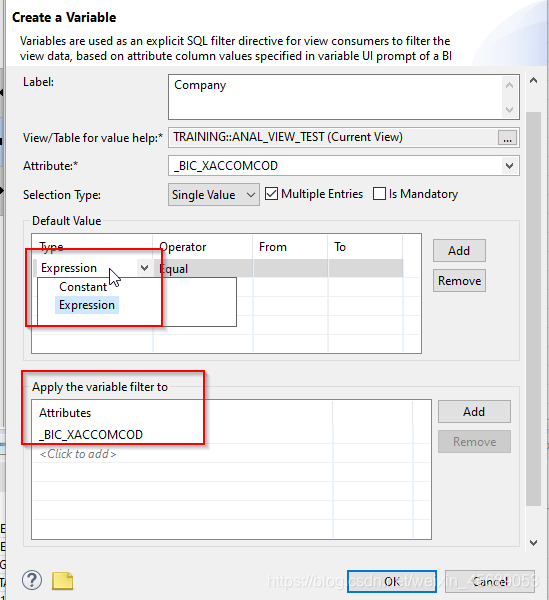
+7.2 输入参数和变量
这个东西呢,在属性视图我们看了,只有一个计算列。没办法加参数和变量的。
那只能在分析视图里面看看了。看看这里就有了。
那这个参数和变量干嘛用的呢?
当用户去执行基于HANA的view的报表的时候,如果没有参数或变量,那返回的是所有的数据。如果我们想开始执行的时候有个过滤值啥的,那我就可以建个参数。
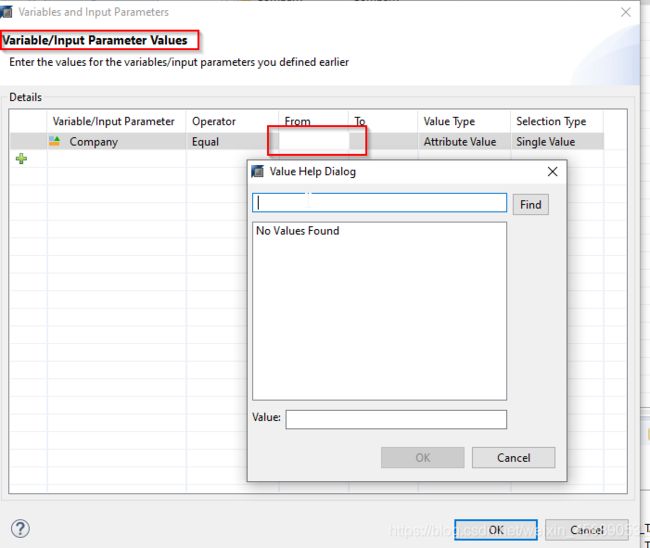
然后就可以激活并查看数据了。会跳出参数窗口来过滤数据的。就是这样的。
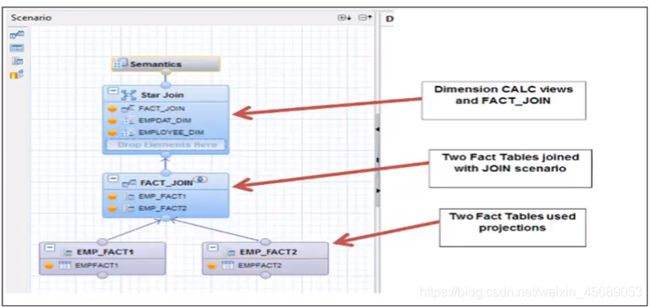
7. 计算视图
现在来详细看看计算视图了,计算视图呢,可以使用分析视图,属性视图,和其他的计算视图来形成列表。用来实现其他视图无法实现的复杂计算。
一句话,就是最牛的视图。怪不得系统里我只看到这个视图,没看到分析视图。
分析视图,其实是一个星型结构,就是只基于一张事实表,但是计算视图,那就是个星系模型了,可以分析多个事实表。更多维度的分析,也就是说可以把不同的分析视图拿来用。至于一开始选不选Star join呢,这个在新建的时候会有。如果你选了star join 那你必须把你的基础列表,转换成维度计算视图,你不能直接用这些基础的表了,属性视图,分析视图也不能用。(那这个维度计算视图怎么转换呢?接下来再看)
在Star Join这个节点里,你选的时候,那就只能选Dimension calculation view, Fact不做限制。
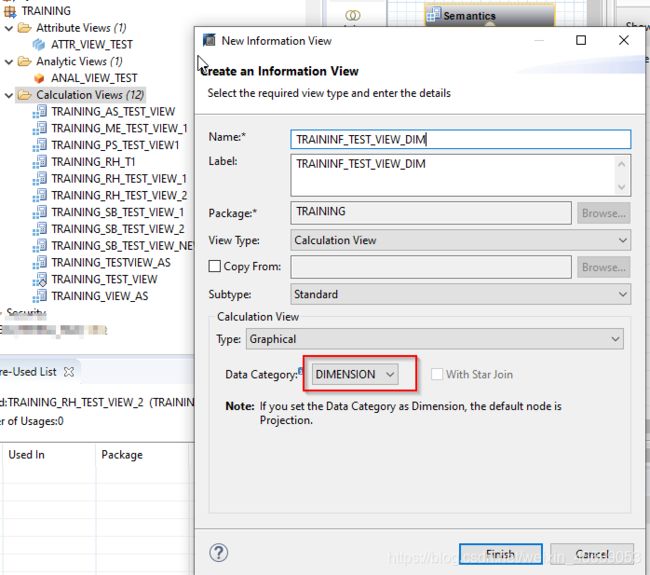
怎么把表转换成维度计算视图呢?那就是新建一个计算视图,选择DIMENSION。
这样我们就有了一个维度计算视图:添加表进去,然后选择output的字段,保存并激活。
有两种方法来创建计算视图:
- SQL Editor
- Graphical Editor
同时还有些概念:join,union,投影和聚合节点(具体不知道啥意思)
往下来看:
join:就是关联两个对象,传到上级节点,这个join就可以是内关联,左关联,右关联,和文本关联。注意一点,只可以join两个对象,多了不行了。
union:关联多个数据源的所有操作。对象可以是多个。
投影:这个就是用来设置列啊,过滤数据啊,添加附加列啊。这个投影一般是在开始选择数据的时候,为上级的union,聚合以及排序打好基础。一个投影节点只有一个对象。
聚集:基于选择的属性列来聚集。
排序:定义分区或排序。
7.1 如何创建计算视图
7.1.1 用Graphical自动创建:
如果自动创建呢,那就会有聚集,投影,内联,外联这些节点。可以基于其他属性,分析和计算视图来创建。
新建一个来看看:
这里呢,要好好看看:

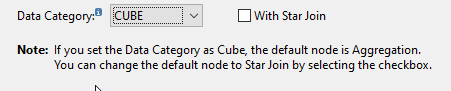

这边呢,就是我不懂的地方了,啥意思叫如果设置数据目录是cube,那就默认是聚集,如果设置是维度,那就是投影。
哈哈,写完就懂了,cube对数据确实默认是sum.
如果是维度指标,那就是啥值就直接给啥值,不要做其他操作。
好的,继续往下看。
如果用Calculation view with Star Join
有星型连接的计算视图,这样的话,所有的基础列表,属性视图,分析视图都不能直接加到data foundation里面来。
所有的维度表必须转换成维度计算视图才能使用star join。
而且所有的事实表都可以被添加,并且可以使用计算视图中的默认节点。
上面一段话,不知道啥意思,嘎嘎。
看个例子吧。
用star join的计算视图:
假设你有四个表,两个维度表,两个事实表。你想要看雇员清单,起中包括他们加入公司的时间,姓名,编号,工资和奖金。
那首先 我们来创建这几张表吧。
开始,在SQL里面弄:

建好了表,来弄这个视图:
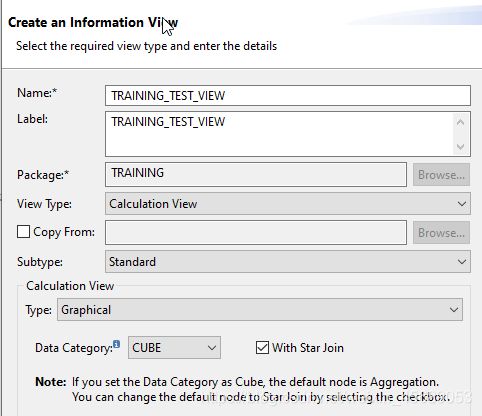
视图左边调色板里拖两个projection给fact表先。左边默认node有join啦,union啦,projection啦,aggregation啦(sum啦),rank啦(top10这种需求)。
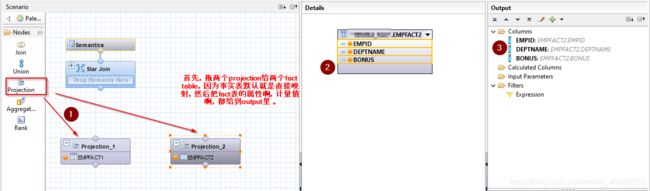
首先把Fact表给到Projection,然后选择每个projection里面的column,最后要到output里面的。
加两个projection,然后选择join,把两个projection 连接起来。选中显示的列。
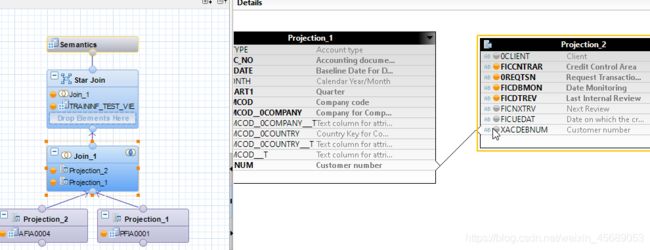
最后我们得在Star Join里面弄了。
Star Join里面呢,把Join里的拉进去,然后还有之前转换的维度计算视图。可以有很多个维度计算视图,因为这样才算是星系schema。

最后到Semantics里面:

然后就可以查看数据了。接下来就是数据的玩法了。
7.1.2 用SQL脚本来创建:
那就是基于SQL命令了,或者是HANA定义的一些功能(具体不会)。
8. 分析特权
这个是干嘛的呢?
在View上限制权限,限制不同公司的不同用户能看到view中的哪些属性列。如果你不需要看到这个view中的某些属性,那我就不给你权限了,把这些属性对你隐身,但是对于数字类型的度量值,那就限制不了了。
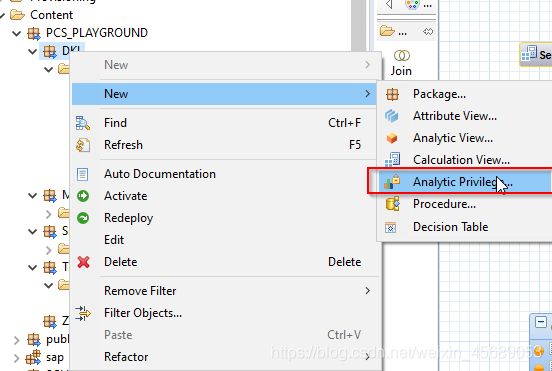
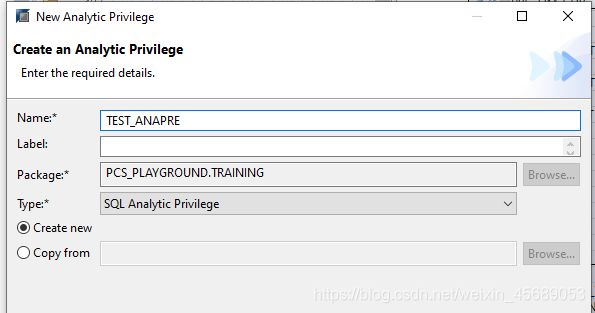
建一个新的,因为也没有已经存在的Analytic Privilege,下一步,干啥呢
那得选view,适用于哪个view。
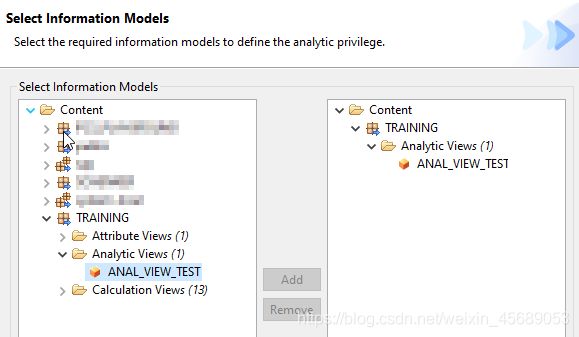
好了,在这个view上设置,选择哪个属性,选择什么限制,是只能看到这个呢,还是不能看到。这个需要测试。
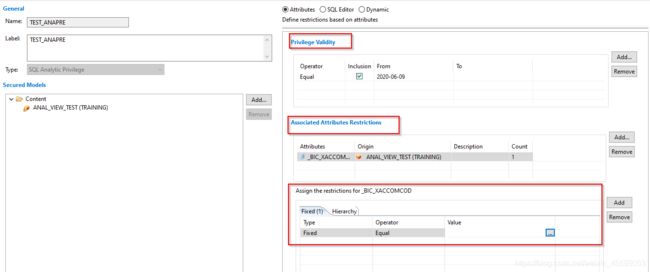
最后一步呢,就是assign给用户。
在User下面:有一个Analytic Privileges给它加上就可以了。
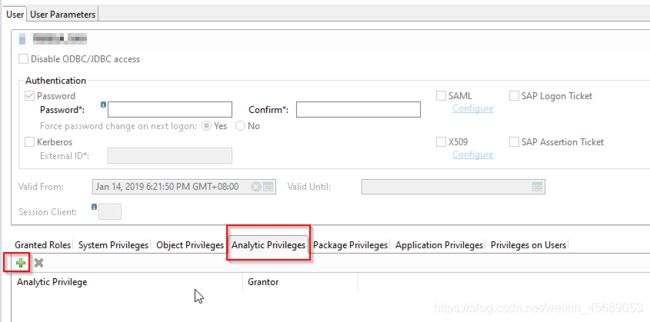
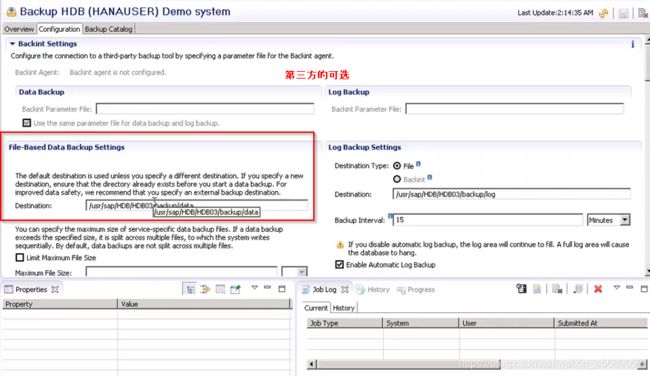
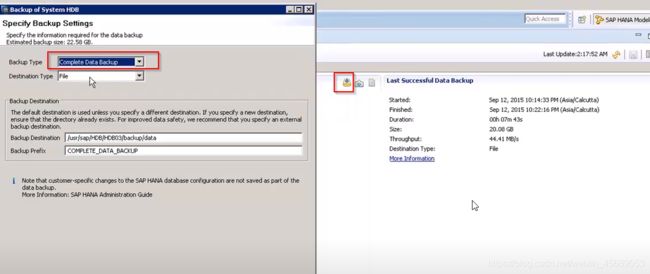
9. Backup
好了现在回到最初,我们刚开始系统第一个folder其实就是备份。
想想呢,备份肯定就是HANA系统备份和恢复。当数据库宕机的时候,有个备份呢,那是极好的。没有备份那就灾难啊。
当前有备份就在左侧能看到,上次备份的就在右边。

10. 导出和导入
这个在另外一篇写过了。
但是我们也可以从本地导入excel文件的。
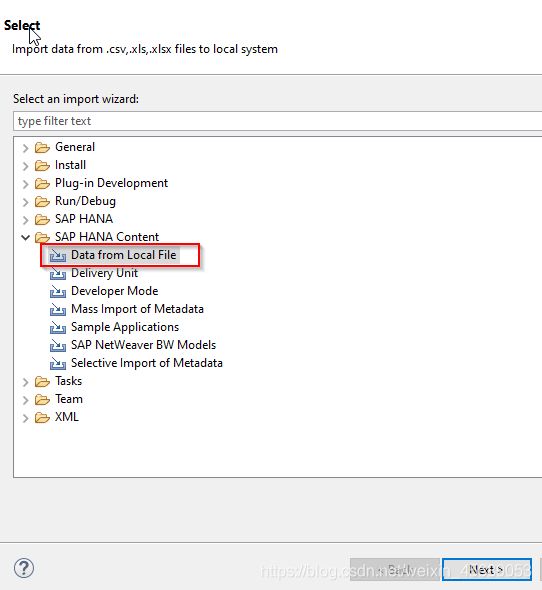
选择你想要导入数据的HANA系统,然后选择本地文件。
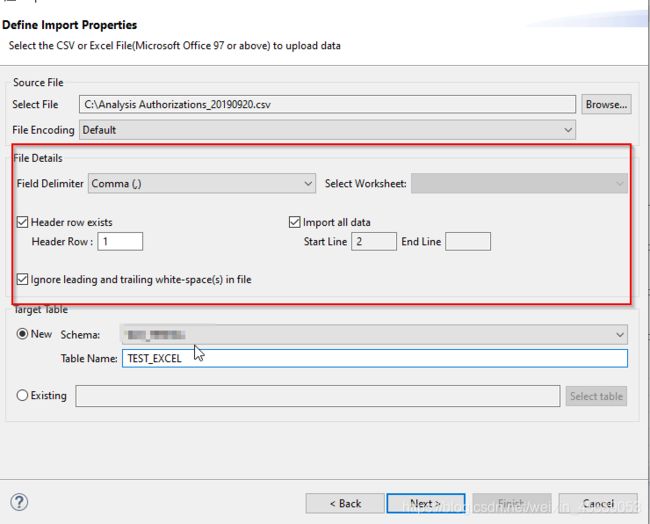
做一些设置,选择你想要的数据。
11.数据提供 data provisioning

数据提供简单来说就是数据复制,replication。
你要能把其他系统的数据都复制过来,这就是你的水平了。
而且你复制别人ECC系统或者其他交易系统的数据的时候,人家要依然在线使用的。
HANA系统里面有三种复制的技术:
- SAP LT Replication 方法
- ETL 工具SAP BO Data Service(BODS) 方法
- Direct Extractor connection方法(DXC)
SLT:System Landscape Transformation
这个是通过trusted RFC connection把数据带到HANA系统,从ECC交易系统到HANA系统。这中间谁来牵头?
那得有个应用服务,来处理所有触发的请求。啥请求?从SAP系统或non-SAP系统实时加载并复制数据到SAP HANA环境中。
SLT application server使用的是基于触发的方法来从源系统传递数据到目标系统。
RFC连接的建立,下次写个小的文章,很简单。
就是你的SAP系统A建立一个RFC连接到目标ECC系统B。你登陆到A上,并且你有够大的权限时,那你可以用RFC连接登录到B上,不需要重复输入用户名和密码的。

SLT有很多优点:
- SLT复制方法可以时从多个源到单一目标,或者从一个源到多个目标。
- 使用的时基于触发的方法,对于源系统没有可计算的性能影响。
- 实时数据复制啊,只复制相关数据到HANA系统。
- 被完全集成在HANA系统和HANA studio里面。
(具体在RFC那篇写了个草稿)