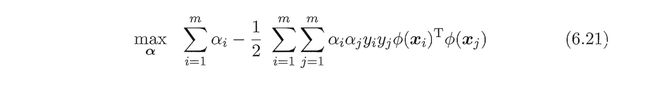一文全解经典机器学习算法之支持向量机SVM(关键词:SVM,对偶、间隔、支持向量、核函数、特征空间、分类)
文章目录
- 一:概述
- 二:间隔与支持向量
- 三:对偶问题
-
- (1)什么是对偶问题
- (2)SVM对偶问题
- (3)SMO算法
- 四:核函数
-
- (1)核函数的概述和作用
- (2)求解
之前所介绍的逻辑回归是基于似然度的分类方法,通过对数据概率进行建模来得到软输出。但这种分类方法其实稍加“繁琐”,因为要估计数据的概率分布作为中间步骤。这就像当一个人学习英语时,他只要直接报个班或者自己看书就行了,而不需要先学习诘屈聱牙的拉丁语作为基础。既然解决分类问题只需要一个简单的判别式,那就没有必要费尽心思计算似然概率或者后验概率。而本节所要介绍的支持向量机(SVM)就是这样一种方法。支持向量机并不关系数据的概率,而是要基于判别式找到最优的超平面作为二分类问题的决策边界,也正是正是这化繁为简的原则给支持向量机带来了超乎寻常的优良效果
一:概述
如下图是一个二维平面上的线性可分数据集,那它的决策边界就是一条简单的直线。可这条能将所有训练数据正确区分的直线是不是唯一的呢?显然,答案是否定的,事实上,像这样的能正确 区分数据的直线有无数条
但问题来了:这无数条直线中应该选择哪一条作为最优决策边界呢?我想作为一个具有机器学习算法常识的人来说,虽然对SVM还不了解,但凭直觉一定会选择 H 3 H_{3} H3。之所以不选择 H 2 H_{2} H2是因为,边界 H 2 H_{2} H2过于靠近一些训练数据,那么这些靠近边界的数据受噪声或干扰影响时,得到的真实数据就更容易从一个类别跳到另一个类别,导致分类错误和泛化性能下降。相比之下,边界 H 3 H_{3} H3对训练数据局部扰动的“容忍性”最好,换言之,边界 H 3 H_{3} H3所产生的分类结果是最鲁棒的,对未见示例的泛化能力最强
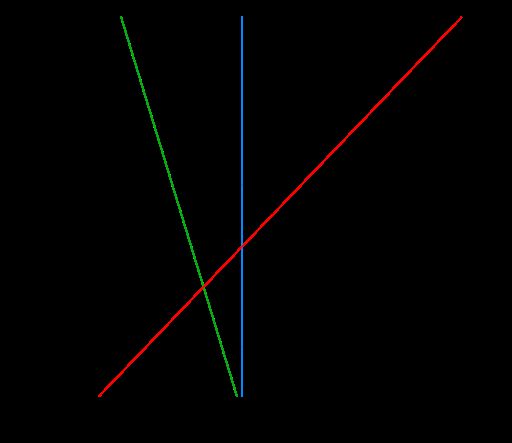
我们换个角度看。假设存在能够将数据完全区分开来的两条平行线,所有正类数据点都在这两条平行 线的一侧,所有负类数据点则在平行线的另一侧。更重要的是,我们要让这两条平行线中的 一条经过一个正类点,另一条则经过一个负类点。不难发现,这两个点就是欧氏距离最近的 两个异类点了。接下来,让这两条平行线以它们各自经过的异类点为不动点进行旋转,同时保证平行关系和 分类特性不变。在旋转的过程中,两个不动点之间的欧氏距离是不变的,但两条线的斜率一 直在改变,因此它们之间的距离也会不断变化。当其中一条直线经过第二个数据点时,两条 直线之间的距离就会达到最大值。这时,这两条平行线中间的直线就是最优决策边界。后面我们会说到,落在两条平行线上的几个异类点就是支持向量 (support vector)。如果将最优决策边界看成一扇双向的推拉门,把这扇门向两个方向 推开就相当于两条平行线的距离逐渐增加。当这两扇门各自接触到支持向量时停止移动,留 下来的门缝就是两个类别之间的间隔

二:间隔与支持向量
在样本空间中,划分超平面可通过如下线性方程来描述
ω T x + b = 0 \omega^{T}x+b=0 ωTx+b=0
其中 ω = ( ω 1 ; ω 2 ; . . . ; ω d ) \omega=(\omega_{1};\omega_{2};...;\omega_{d}) ω=(ω1;ω2;...;ωd)为法向量,决定了超平面的方向, b b b为位移项,决定了超平面与原点之间的距离。显然,划分超平面可由法向量 ω \omega ω和位移 b b b确定。将其记为 ( ω , b ) (\omega,b) (ω,b),样本空间中任意点 x x x到超平面 ( ω , b ) (\omega,b) (ω,b)的距离可以写为
r = ∣ ∣ w T x + b ∣ ∣ ∣ ∣ ω ∣ ∣ r=\frac{||w^{T}x+b||}{||\omega||} r=∣∣ω∣∣∣∣wTx+b∣∣
假设超平面 ( ω , b ) (\omega,b) (ω,b)能将训练样本正确分类,即对于 ( x i , y i ) ∈ D (x_{i},y_{i})\in D (xi,yi)∈D,则有
- 记为(1)式
{ w T x i + b ⩾ + 1 , y i = + 1 w T x i + b ⩽ − 1 , y i = − 1 \left\{\begin{array}{ll}\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}_{i}+b \geqslant+1, & y_{i}=+1 \\\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}_{i}+b \leqslant-1, & y_{i}=-1\end{array}\right. {wTxi+b⩾+1,wTxi+b⩽−1,yi=+1yi=−1
如下图所示,距离超平面最近的这几个训练样本点使上式等号成立,它们被称为支持向量,两个异类支持向量到超平面的距离之和为 g a m m a = 2 ∣ ∣ ω ∣ ∣ gamma=\frac{2}{||\omega||} gamma=∣∣ω∣∣2,称其为间隔
- 间隔(margin)是支持向量机的核心概念之一,它是对支持向量到分离超平面的距离度量,可以进一步表示分类的正确性和可信程度
- 几何间隔:是指一个样本点到分类超平面的距离
- 函数间隔:是指一个样本点到分类超平面的距离再乘以该样本点的真实标签

支持向量机的基本思想就是找出能够正确划分数据集并且具有最大几何间隔的分离超平面。欲找到具有最大间隔的划分超平面,也就是要找到能满足(1)式中约束的参数 ω \omega ω和 b b b,使得 γ \gamma γ最大,也即
- 记为(2)式
max w , b 2 ∥ w ∥ s.t. y i ( w T x i + b ) ⩾ 1 , i = 1 , 2 , … , m . \begin{aligned}\max _{\boldsymbol{w}, b} & \frac{2}{\|\boldsymbol{w}\|} \\\text { s.t. } & y_{i}\left(\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}_{i}+b\right) \geqslant 1, \quad i=1,2, \ldots, m .\end{aligned} w,bmax s.t. ∥w∥2yi(wTxi+b)⩾1,i=1,2,…,m.
显然,为了最大化间隔,仅需要最大化 ∣ ∣ ω ∣ ∣ − 1 ||\omega||^{-1} ∣∣ω∣∣−1,这等价于最小化 ∣ ∣ ω ∣ ∣ 2 ||\omega||^{2} ∣∣ω∣∣2,于是(2)式可改写为
- 记为(3)式
min w , b 1 2 ∥ w ∥ 2 s.t. y i ( w T x i + b ) ⩾ 1 , i = 1 , 2 , … , m . \begin{array}{ll}\min _{\boldsymbol{w}, b} & \frac{1}{2}\|\boldsymbol{w}\|^{2} \\\text { s.t. } & y_{i}\left(\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}_{i}+b\right) \geqslant 1, \quad i=1,2, \ldots, m .\end{array} minw,b s.t. 21∥w∥2yi(wTxi+b)⩾1,i=1,2,…,m.
三:对偶问题
(1)什么是对偶问题
对偶问题:是一种优化问题的转换方式。在对偶问题中,我们将原问题转换为另一个与之等价的问题,这个问题通常更易于求解或分析。对偶问题在数学和工程领域中都有广泛的应用。以线性规划问题为例,我们希望最小化或最大化一个线性函数,满足一组线性不等式或等式限制条件。这个问题可以通过线性规划算法来求解。与此同时,我们可以将这个线性规划问题转化为一个对偶问题,这个对偶问题同样可以用线性规划算法求解。对偶问题的关键是构建一个与原问题等价的问题,使得对偶问题的解能够提供原问题的下界或上界。对于线性规划问题,对偶问题的解提供了原问题的最优解的下界或上界,这可以通过所谓的弱对偶定理和强对偶定理来证明
当我们提到对偶问题时,一个经典的例子是线性规划问题。假设我们有一个最小化的线性规划问题,如下所示
m i n . f ( x ) = c T x min.f(x)=c^{T}x min.f(x)=cTx
- 约束条件为 A x ≥ b , x ≥ 0 Ax \geq b,x\geq 0 Ax≥b,x≥0
其中 c , b c, b c,b 和 A A A 是已知的向量和矩阵, x x x 是变量向量。现在,我们可以将其转换为一个对偶问题,如下所示
m a x . g ( y ) = b T y max.g(y)=b^{T}y max.g(y)=bTy
- 在约束条件下 A T y ≤ c , y ≥ 0 A^{T}y\leq c,y\geq 0 ATy≤c,y≥0
这里的关键点在于构建一个与原问题等价的对偶问题。对偶问题可以从原问题中的约束条件中产生,每个约束条件都对应着对偶问题中的一个变量。在上述线性规划问题中,我们有两组约束条件,所以我们需要两个对偶变量 y 1 y_1 y1 和 y 2 y_2 y2。在对偶问题中,约束条件的符号与原问题中的符号相反。对于不等式约束,它在对偶问题中变为等式约束;对于等式约束,它在对偶问题中变为不等式约束。在这个例子中,我们可以通过求解对偶问题来确定原问题的最优解,同时我们也可以通过求解原问题来确定对偶问题的最优解
(2)SVM对偶问题
- 间隔的作用体现在原理上,而对偶性的作用体现在实现上,虽然我们前面已经说明了最优决策边界,但是却无法求解最优边界,因此我们可以通过引入拉格朗日乘子将原始问题转化为对偶问题来找到最优解
(3)式本身是个凸二次规划问题,求解起来比较轻松,但是借助拉格朗日乘子,此问题就可以改写为所谓的广义拉格朗日函数。具体来说,对(3)式的每条约束添加拉格朗日乘子 α i ≥ 0 \alpha_{i}\geq 0 αi≥0,则该问题的拉格朗日函数可写为
- 这个式子从另一个角度说明了为什么最优决策边界只取决于几个支持向量:对于不是支持向量的数据点来说,等式右边的 1 − y i ( ω T x i + b ) 1-y_{i}(\omega^{T}x_{i}+b) 1−yi(ωTxi+b)是大于0的,因此在让 L ( ω , b , α ) L(\omega,b,\alpha) L(ω,b,α)最小化时,就必须把这些点的贡献给去除掉,去除的方式就是让系数 α i = 0 \alpha_{i}=0 αi=0
- 记为(4)式
- α = ( α 1 ) ; α 2 ; . . . ; α m \alpha=(\alpha_{1});\alpha_{2};...;\alpha_{m} α=(α1);α2;...;αm
L ( w , b , α ) = 1 2 ∥ w ∥ 2 + ∑ i = 1 m α i ( 1 − y i ( w T x i + b ) ) L(\boldsymbol{w}, b, \boldsymbol{\alpha})=\frac{1}{2}\|\boldsymbol{w}\|^{2}+\sum_{i=1}^{m} \alpha_{i}\left(1-y_{i}\left(\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}_{i}+b\right)\right) L(w,b,α)=21∥w∥2+i=1∑mαi(1−yi(wTxi+b))
然后令 L ( ω , b , α ) L(\omega,b,\alpha) L(ω,b,α)对 ω \omega ω和 b b b的偏导为零可得
- 分别记为(5)式和(6)式
ω = ∑ i = 1 m α i y i x i , 0 = ∑ i = 1 m α i y i \omega=\sum_{i=1}^{m}\alpha_{i}y_{i}x_{i},0=\sum_{i=1}^{m}\alpha_{i}y_{i} ω=i=1∑mαiyixi,0=i=1∑mαiyi
将(5)式代入(4)式,可将 ω \omega ω和 b b b消去,再考虑(6)式的约束,就可以得到(3)式的对偶问题如下
- 记为(7)式
max α ∑ i = 1 m α i − 1 2 ∑ i = 1 m ∑ j = 1 m α i α j y i y j x i T x j s.t. ∑ i = 1 m α i y i = 0 , α i ⩾ 0 , i = 1 , 2 , … , m . \begin{aligned}\max _{\boldsymbol{\alpha}} & \sum_{i=1}^{m} \alpha_{i}-\frac{1}{2} \sum_{i=1}^{m} \sum_{j=1}^{m} \alpha_{i} \alpha_{j} y_{i} y_{j} \boldsymbol{x}_{i}^{\mathrm{T}} \boldsymbol{x}_{j} \\\text { s.t. } & \sum_{i=1}^{m} \alpha_{i} y_{i}=0, \\& \alpha_{i} \geqslant 0, \quad i=1,2, \ldots, m .\end{aligned} αmax s.t. i=1∑mαi−21i=1∑mj=1∑mαiαjyiyjxiTxji=1∑mαiyi=0,αi⩾0,i=1,2,…,m.
虽然现在我们将原问题转变为了其对偶问题,但是这两者之间是否能够完全划等号还是一个未知数。仔细看,原函数求出的是 L ( ω , b , α ) L(\omega,b,\alpha) L(ω,b,α)最大值的下界,对偶函数求出的是 L ( ω , b , α ) L(\omega,b,\alpha) L(ω,b,α)最小值的下界,因此后者肯定不会大于前者,但也不是无条件相等。好在数学上可以证明,当上述过程满足KKT条件(Karush-Kuhn-Tucker)时,原问题和对偶问题才能殊途同归。如下,KKT条件要求
- 记为(8)式
{ α i ⩾ 0 ; y i f ( x i ) − 1 ⩾ 0 ; α i ( y i f ( x i ) − 1 ) = 0 \left\{\begin{array}{l}\alpha_{i} \geqslant 0 ; \\y_{i} f\left(\boldsymbol{x}_{i}\right)-1 \geqslant 0 ; \\\alpha_{i}\left(y_{i} f\left(\boldsymbol{x}_{i}\right)-1\right)=0\end{array}\right. ⎩ ⎨ ⎧αi⩾0;yif(xi)−1⩾0;αi(yif(xi)−1)=0
于是,对于任意训练样本 ( x i , y i ) (x_{i},y_{i}) (xi,yi),总有 α i = 0 \alpha_{i}=0 αi=0或 y i f ( x i ) = 1 y_{i}f(x_{i})=1 yif(xi)=1
- 若 α i = 0 \alpha_{i}=0 αi=0,则该样本不会对 f ( x ) f(x) f(x)有任何影响(前面已经说明)
- 若 α i > 0 \alpha_{i}>0 αi>0,则必有 y i f ( x i ) = 1 y_{i}f(x_{i})=1 yif(xi)=1,所对应的样本点位于最大间隔边界上,是一个支持向量。和前面叙述一致,这显示输出了支持向量机的一个重要性质:训练完成后,大部分训练样本都不需要保留,最终模型仅与支持向量有关
(3)SMO算法
- (7)式是一个二次规划问题,可以使用通用的二次规划算法来求解,然而该问题的规模正比于训练样本数,所以会在实际任务中造成很大开销。为了避开这个障碍,人们利用问题本身的特征,提出了很多高效的算法,SMO算法就是其中的代表
SMO(Sequential Minimal Optimization):基本思想是将大规模的二次规划问题分解为多个较小的二次规划子问题,并通过求解这些子问题来优化原始问题。具体来说,SMO算法在每次迭代中选择两个变量进行优化,并固定其他变量不变。这样,在每次迭代中,SMO算法都可以将原始问题转化为一个只有两个变量的二次规划子问题。接着,SMO算法使用解析公式来求解这个子问题的最优解,使得目标函数值有最大的增长。如果这个子问题的解满足一定的约束条件,则保留这个解并优化下一个子问题。否则,SMO算法会调整其中一个变量的值,并继续优化当前的子问题,直到收敛为止
下面内容借助周志强机器学习




四:核函数
(1)核函数的概述和作用
本文前面讨论中,假设训练样本是线性可分而定,也即存在一个划分超平面将训练样本正确分类。然后在现实任务中,原始样本空间也许并不存在一个能正确划分两类样本的超平面。例如经典的“异或”问题
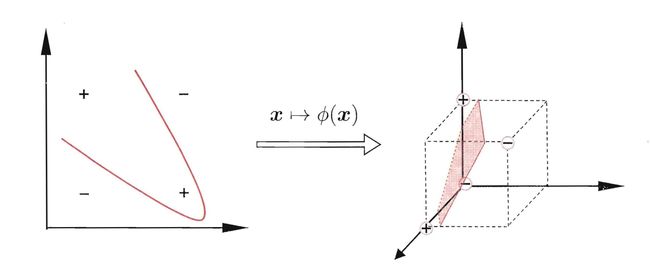
对于这样的问题,可以将样本从原始空间映射到一个根高纬的特征空间,使得样本在这个特征空间内线性可分,如上图中的 ϕ \phi ϕ
对高纬空间上新生成的特征向量进行内积运算,便得到了核函数,其数学表达式如下
k ( x , x ′ ) = ϕ ( x ) T ϕ ( x ′ ) k(x,x\prime)=\phi(x)^{T}\phi(x\prime) k(x,x′)=ϕ(x)Tϕ(x′)
核函数的这个公式给出了生成条件而非判定条件。当给定特征的映射方式后,可以用它来计算核函数;但是当给出一个确定的函数时,如何判定它能不能作为核函数呢?梅塞尔定理(Mercer’s theorem)解决了这个判定问题,其内容为:是任何满足对称性和半正定性的函数都是某个高维希尔伯特空间的内积,只要一个函数满足这两个条件,它就可以用做核函数。但梅塞尔定理只是判定核函数的充分而非必要条件,不满足梅塞尔定理的函数也可能是核函数
之所以要将特征映射表示成核函数,是因为内积的引入简化了高维空间中的复杂运算。映射到高维空间后,待优化的对偶问题(7)式子就变成了
max α ∑ i = 1 m α i − 1 2 ∑ i = 1 m ∑ j = 1 m α i α j y i y j ϕ ( x i ) T ϕ ( x j ) \max _{\boldsymbol{\alpha}} \sum_{i=1}^{m} \alpha_{i}-\frac{1}{2} \sum_{i=1}^{m} \sum_{j=1}^{m} \alpha_{i} \alpha_{j} y_{i} y_{j} \phi\left(\boldsymbol{x}_{i}\right)^{\mathrm{T}} \phi\left(\boldsymbol{x}_{j}\right) αmaxi=1∑mαi−21i=1∑mj=1∑mαiαjyiyjϕ(xi)Tϕ(xj)
按照一般的思路,要直接计算上面的表达式就先得写出 ϕ ( ⋅ ) \phi(·) ϕ(⋅)的形式,再在新的高维特征空间上计算内积,但这在实际运算中存在很大困难。尤其是当 ϕ ( ⋅ ) \phi(·) ϕ(⋅)的表达式未知时,那这内积就没法计算了。可即使 ϕ ( ⋅ ) \phi(·) ϕ(⋅) 的形式已知,如果特征空间的维数较高,甚至达到无穷维的话,内积的运算也会非常困难
这时就需要核函数来发挥威力了,既然优化的对象是内积的结果,那么直接定义内积的表达式就可以了,何苦还要引入特征映射和特征空间这些个中间步骤呢?更重要的是,梅塞尔定理为这种捷径提供了理论依据,只要核函数满足对称性和半正定的条件,对应的映射空间就铁定存在。所以核函数的引入相当于隐式定义了特征映射和特征空间,无需关心这些中间结果的形式就能直接计算待优化的内积,从而大大简化计算
下表列出了一些常用的核函数

(2)求解
- 以下借助周志强机器学习