从经典网络IO模型到新异步IO框架io_uring
网络IO两阶段
网络IO涉及用户空间和内核空间,一般会有以下两阶段:
-
一阶段:等待数据准备就绪,即数据被copy到内核缓冲区(wait for data)
-
二阶段:数据从内核缓冲区copy到用户缓冲区(copy data from kernel to user)
根据以上两阶段不同,出现了多种网络IO模型,接下来一一进行分析。注意所展示的图中(wait for data)和(copy data from kernel to user)字段分别表示一二阶段。
1. 阻塞IO(Blocking IO)
socket fd默认blocking,从下图可以看出,用户进程全程阻塞直到两阶段完成,即,一阶段等待数据会block,二阶段将数据从内核copy到用户空间也会block,只有copy完数据后内核返回,用户进程才会解除block状态,重新运行。
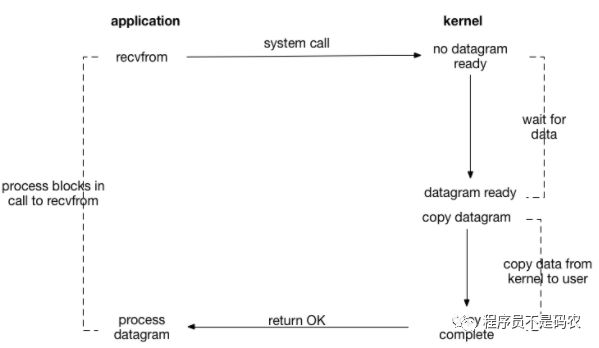
结论:阻塞IO,两阶段都阻塞。
2. 非阻塞IO(Non-blocking IO)
可使用fcntl将socket设置为NON-BLOCKING,使其变为非阻塞。
fcntl(fd, F_SETFL, O_NONBLOCK);
如下图,用户进程recvfrom时,如果没有数据,则直接返回,因此一阶段不会阻塞用户进程。但是,用户进程需要不断轮询kernel数据是否准备好(会造成CPU空转,浪费资源)。当数据准备好时,用户进程会阻塞直到数据从内核空间copy到用户空间完成(二阶段),内核返回结果。

其中recvfrom 返回值含义:
-
error of EWOULDBLOCK, 无数据
-
大于0,接收数据完毕,返回值即收到的字节数
-
等于0,连接已经正常断开
-
等于-1,errno==EAGAIN表示recv操作未完成,errno!=EAGAIN表示recv操作遇到系统错误errno.
结论:非阻塞IO, 一阶段不阻塞(但是会不断轮询),二阶段阻塞。
3. IO多路复用(IO multiplexing)
也称为事件驱动IO(event driven IO),通过使用select/poll/epoll系统调用,可在单个进程/线程中同时监听多个网络连接的(socket fd),一旦有事件触发则进行相应处理,其中select/poll/epoll本身是阻塞的。(IO多路复用后面会用专门文章来详细讲解)

如果连接数不是很高的话,使用select/epoll的web server不一定比使用multi-threading + blocking IO的web server性能更好,可能延迟更大。因为前者需要两个系统调用(select/epoll + read),而后者只有一个(read)。但是在连接数很多的情况下,select/epoll的优势就凸显出来了。(高效事件驱动模型可参考libevent,libev库)
结论:IO多路复用,两阶段都处于阻塞状态,优点是单个线程可同时监听和处理多个网络连接
4. 信号驱动IO(signal driven IO, SIGIO)
通过sigaction系统调用,建立起signal-driven I/O的socket,并绑定一个信号处理函数;sigaction不会阻塞,立即返回,因此一阶段不阻塞。当数据准备好,内核就为进程产生一个SIGIO信号,随后在信号处理函数中调用recvfrom接收数据。

结论:信号驱动IO,一阶段不阻塞,二阶段阻塞
以上四种模型都有一个共同点:二阶段阻塞,也就是在真正IO操作(recvfrom)的时候需要用户进程参与,因此以上四种模型均称为同步IO模型。
5. 异步IO(asynchronous IO, AIO)
POSIX中提供了异步IO的接口aio_function,如下图,内核收到用户进程的aio_read之后会立即返回,不会阻塞,aio_read会给内核传递文件描述符,缓冲区指针,缓冲区大小,文件偏移等;当数据准备好,内核直接将数据copy到用户空间,copy完后给用户进程发送一个信号,进行用户数据异步处理(aio_read)。因此,异步IO中用户进程是不需要参与数据从内核空间copy到用户空间这个过程的,也即二阶段不阻塞。

结论:异步IO,两阶段都不阻塞
上述五种IO模型对比
从上述分析可以得知,阻塞和非阻塞的区别在于内核数据还没准备好时,用户进程是否会阻塞(一阶段是否阻塞);同步与异步的区别在于当数据从内核copy到用户空间时,用户进程是否会阻塞/参与(二阶段是否阻塞)。从下图可以清晰对五种IO模型进行对比,并清晰看到各种模型各个阶段的阻塞情况。

以下为POSIX中对同步和异步IO的描述,可以把真正的I/O操作(recvfrom)是否阻塞看作为两者的区别。
POSIX defines these two terms as followers:
A synchronous I/O operation causes the requesting process to be blocked until that I/O operation completes;
An asynchronous I/O operation does not cause the requesting process to be blocked;
还有一个概念需要区分:异步IO和IO异步操作,IO异步操作其实是属于同步IO模型。
6. 新异步IO-io_uring
POSIX中提供的异步IO接口aio_read和aio_write性能一般,几乎形同虚设,很少被用到,性能不如Epoll等IO多路复用模型。
Linux 5.1引入了一个重大feature:io_uring,由block IO大神Jens Axboe开发,这意味着Linux native aio的时代即将成为过去,io_uring的异步IO新时代即将开启。
以下贴出Jens Axboe的测试数据

从以上数据看出,在非Polling模式下,io_uring性能提升不大,但是polling模式下,io_uring性能远远超出libaio,并接近spdk.
io_uring围绕高效进行设计,采用一对共享内存ringbuffer用于应用和内核间通信,避免内存拷贝和系统调用(感觉这应该是io_uring最精髓的地方):
-
提交队列(SQ):应用是IO提交的生产者,内核为消费者
-
完成队列(CQ):内核是完成事件的生产者,应用是消费者
//io_uring系统调用// 初始化,io_setup返回一个fd,应用程序使用这个fd进行mmap,和kernel共享一块内存// SQ和 CQ是一个典型的 RingBuffer,有 head,tail 两个成员int io_uring_setup(u32 entries, struct io_uring_params *p);// initiate and/or complete asynchronous I/O// initiate and complete I/O using the shared submission and completionint io_uring_enter(...);// register files or user buffers for asynchronous I/O// registers user buffers or files for use in an io_uring(7) instance * referenced by fd.int io_uring_register(...);
为方便使用,Jens Axboe还开发了一套liburing库,用户不必了解诸多细节。
通过全新的设计,共享内存,IO 过程不需要系统调用,由内核完成 IO 的提交, 以及 IO completion polling 机制,实现了高IOPS,高 Bandwidth。相比 kernel bypass,这种 native 的方式显得友好一些。
Linux服务器开发学习视频资料,包括Linux,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK等等
这里分享一个手写代码实现线程池的视频,需要代码的朋友可以加入到群里一起探讨技术交流,领取资料

