目标检测+目标追踪+单目测距(毕设+代码)
项目成果图


废话不多说,切入正文!
目标检测
YOLOv5是一种计算机视觉算法,它是YOLO(You Only Look Once)系列算法的最新版本,由Joseph Redmon和Alexey Bochkovskiy等人开发。它是一种单阶段目标检测算法,可以在图像中检测出多个物体,并输出它们的类别和位置信息。相比于以往的YOLO版本,YOLOv5具有更高的检测精度和更快的速度。

网络架构
YOLOv5使用了一种新的检测架构,称为CSP(Cross-Stage Partial)架构,它将原始的卷积层替换为CSP卷积层,这种新的卷积层可以更好地利用计算资源,提高模型的效率和准确度。此外,YOLOv5还使用了一种新的数据增强技术,称为Mosaic数据增强,这种技术可以在单个图像中合并多个图像,以增加样本的复杂性和多样性,提高模型的泛化能力。
改进点
YOLOv5引入了一种新的训练策略,称为Self-Adversarial Training(SAT),它可以在模型训练过程中自动生成对抗性样本,以帮助模型更好地学习物体的特征和位置信息,提高模型的鲁棒性和准确度。
应用领域
YOLOv5的同时也提供了预训练模型,可以直接用于物体检测任务。此外,YOLOv5还可以在不同的硬件平台上运行,包括CPU、GPU和TPU等。因此,YOLOv5非常适合在嵌入式设备、移动设备和云端服务器等不同场景中应用,可以广泛应用于交通、安防、无人驾驶、智能家居等领域。
deepsort追踪
多目标跟踪算法
DeepSORT是一种基于深度学习的多目标跟踪算法,可以在复杂的场景中实现高效准确的目标追踪。DeepSORT的核心思想是将目标检测和目标跟踪两个任务分开处理,利用深度学习网络提取目标特征,并结合卡尔曼滤波和匈牙利算法等传统跟踪方法,实现对多个目标的准确追踪。

代码
def main(_argv): #--->全部代码qq1309399183--<
# Definition of the parameters
max_cosine_distance = 0.4
nn_budget = None
nms_max_overlap = 1.0
# initialize deep sort
model_filename = 'model_data/mars-small128.pb'
encoder = gdet.create_box_encoder(model_filename, batch_size=1)
# calculate cosine distance metric
metric = nn_matching.NearestNeighborDistanceMetric("cosine", max_cosine_distance, nn_budget)
# initialize tracker
tracker = Tracker(metric)
# load configuration for object detector
config = ConfigProto()
config.gpu_options.allow_growth = True
session = InteractiveSession(config=config)
STRIDES, ANCHORS, NUM_CLASS, XYSCALE = utils.load_config(FLAGS)
input_size = FLAGS.size
video_path = FLAGS.video
# load tflite model if flag is set
if FLAGS.framework == 'tflite':
interpreter = tf.lite.Interpreter(model_path=FLAGS.weights)
interpreter.allocate_tensors()
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
print(input_details)
print(output_details)
# otherwise load standard tensorflow saved model
else:
saved_model_loaded = tf.saved_model.load(FLAGS.weights, tags=[tag_constants.SERVING])
infer = saved_model_loaded.signatures['serving_default']
# begin video capture
try:
vid = cv2.VideoCapture(int(video_path))
except:
vid = cv2.VideoCapture(video_path)
out = None
# get video ready to save locally if flag is set
if FLAGS.output:
# by default VideoCapture returns float instead of int
width = int(vid.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(vid.get(cv2.CAP_PROP_FRAME_HEIGHT))
fps = int(vid.get(cv2.CAP_PROP_FPS))
codec = cv2.VideoWriter_fourcc(*FLAGS.output_format)
out = cv2.VideoWriter(FLAGS.output, codec, fps, (width, height))
frame_num = 0
# while video is running
while True:
return_value, frame = vid.read()
if return_value:
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
image = Image.fromarray(frame)
else:
print('Video has ended or failed, try a different video format!')
break
frame_num += 1
print('Frame #: ', frame_num)
frame_size = frame.shape[:2]
image_data = cv2.resize(frame, (input_size, input_size))
image_data = image_data / 255.
image_data = image_data[np.newaxis, ...].astype(np.float32)
模块
DeepSORT主要有三个模块:特征提取模块、卡尔曼滤波模块和匈牙利算法模块。其中,特征提取模块使用卷积神经网络(CNN)提取每个目标的特征向量,以区分不同目标之间的差异。卡尔曼滤波模块用于预测每个目标的位置和速度,以减小运动模糊和噪声对追踪结果的影响。匈牙利算法模块用于将当前帧中的每个检测框与上一帧中已跟踪的目标进行匹配,以确定每个目标的唯一ID,并更新目标的位置和速度信息。
新特点
DeepSORT除了基本的跟踪功能外,还具有一些高级功能。例如,它可以对目标进行重新识别,以处理目标遮挡、漂移等问题;它还可以使用多个相机进行目标跟踪,以处理多个视角的场景;它还可以实现在线学习,以适应不同场景下的目标特征。
单目测距
# 介绍
YOLO(You Only Look Once)是一种单阶段目标检测算法,可以在图像中检测出多个物体,并输出它们的类别和位置信息。与传统的目标检测方法不同,YOLO不仅可以检测物体,还可以计算物体的深度信息,从而实现单目测距。
代码
depth = (cam_H / np.sin(angle_c)) * math.cos(angle_b)#目标深度
# print('depth', depth)
##联系--方式:----qq1309399183--------
k_inv = np.linalg.inv(in_mat)#K^-1 内参矩阵的逆
p_inv = np.linalg.inv(out_mat)#R^-1 外参矩阵的逆
print("out---:",p_inv)
point_c = np.array([x_d, y_d, 1]) ##图像坐标
point_c = np.transpose(point_c)#目标的世界坐标
# print('point_c', point_c)
print('in----', k_inv)
##相机坐标系和图像坐标系下物体坐标可按照下式转换。
c_position = np.matmul(k_inv, depth * point_c)#Zc*[u,v,1].T*ins^-1==[Xc,Yc,Zc].T #坐标转换
YOLO单目测距的具体实现方法有多种,其中比较常见的方法是基于单目视觉几何学的方法。该方法利用相机成像原理和三角测量原理,通过计算物体在图像中的位置和大小,以及相机的内参和外参等参数,来估计物体的距离。
测距步骤
具体来说,YOLO单目测距可以分为以下几个步骤:
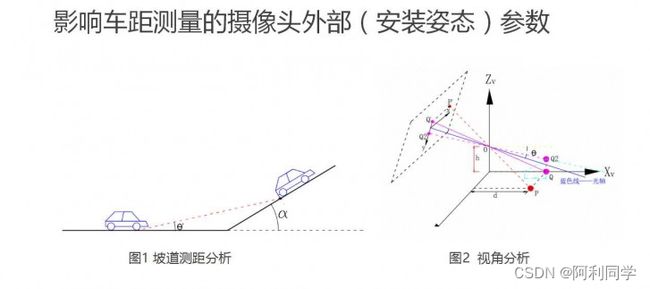
-
相机标定:通过拍摄特定的标定板,获取相机的内参和外参等参数,用于后续的距离计算。
-
目标检测:使用YOLO算法在图像中检测出目标,并获取目标的位置和大小信息。
-
物体位置计算:利用相机成像原理和三角测量原理,计算物体在相机坐标系下的三维坐标。
-
距离计算:利用相机的内参和外参等参数,将物体在相机坐标系下的三维坐标转换为物体在世界坐标系下的三维坐标,并计算物体与相机之间的距离。
除了基于单目视觉几何学的方法外,还有一些其他的方法可以实现YOLO单目测距,例如基于深度学习的方法和基于光流的方法等,这些方法都有其优缺点和适用场景,需要根据实际情况选择合适的方法。

结论
总的来说,YOLO单目测距是一种基于单目视觉的距离估计方法,具有简单、快速、低成本等优点,在自动驾驶、机器人导航、智能交通等领域有广泛的应用前景。但需要注意的是,由于单目视觉存在一些局限性,如遮挡、光照变化、纹理缺失等问题,因此需要结合其他传感器或算法进行辅助,以提高测距的准确度和鲁棒性。