Unsupported major.minor version 51.0解决办法 ——运行MapReduce程序找不到相关类——MapReduce中的Reduce无效
最近重新研究MapReduce,中间出现了不少问题,看样子长时间不弄还是很容易忘记的,特此记录。
问题一:Unsupported major.minor version 51.0解决办法
我使用的是Eclipse-jee + JDK 1.6.0_24环境,结果运行MapReduce程序的时候使用时出现Unsupported major.minor version 51.0错误提示,原来是之前安装过了JDK1.7,编译的版本默认为1.7,当系统找不到这个版本的编译环境时就会发生错误。
解决起来也很方便:打开eclipse中项目上的属性—java compiler–选择一个合适的版本后重新编译即可。
具体步骤
解决:项目------>右键------>属性------>Java Compiler------>Compiler Compliance Level------>选择你使用的JDK版本------>应用。
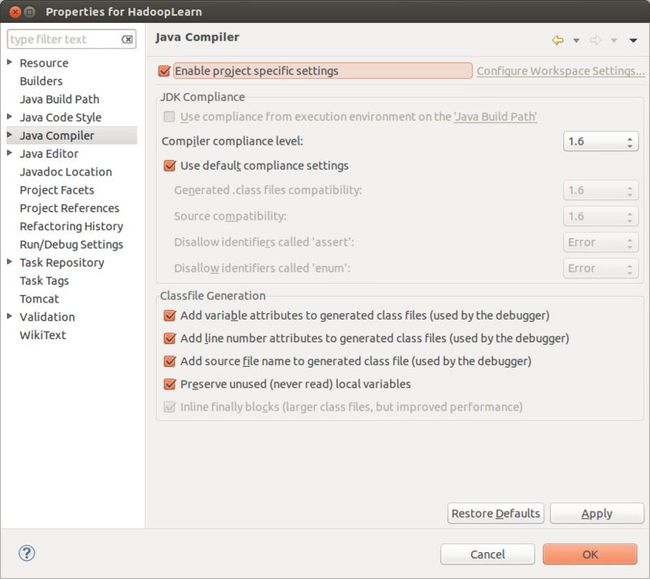
同样也要把属性对话框中的BuildPath改为与上面的一致。
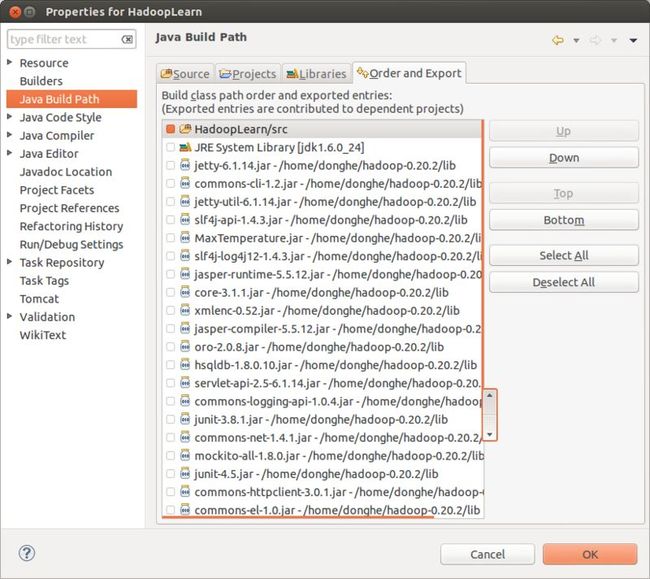
解决这一事件加深了我对eclipse中build path和java compiler compliance level的理解:在eclipse中开发的项目有个java build path中可以配置的jdk,还有个java compiler中可以配置compiler level,这两个是有区别的,build path的JDK版本是你开发的时候编译器需要使用到的,就是你在eclipse中开发代码,给你提示报错的,编译的过程;java compiler compliance level中配置的编译版本号,这个编译版本号的作用是,你这个项目将来开发完毕之后, 要放到服务器上运行,那个服务器上JDK的运行版本。常见的问题就是,build path中配置1.7的JDK,java compiler compliance level中配置的1.7,但是服务器上是1.6的JDK,就报了那个错误,说是编译所用的jdk(1.7)比运行所用的jdk(1.6)高了,这是错误 的。
总结:build path的JDK版本是你开发的时候编译器需要使用到的,例如,如果用的JDK1.4就不能使用泛型。而java compiler compliance level设置的是你写好的JAVA代码按照什么JDK版本级别编译,例如:设置的是1.4,编译出来的class文件可以在1.4以上的JRE上运行, 如果用的是5.0级别编译,就不能运行在1.4的环境里面,会提示版本过高。
补充:后经实例证明,在eclipse中进行开发的时候,build path 中JDK进行类库的编译(就是你使用类在不在这个JDK中),java compiler compliance level是对这个项目语法的编译(就是你的项目中语法的正确与否),在开发的过程中,这两个地方是都起作用的。所以说,最最安全的做法,是build path 和 java complier compliance level和服务器配置的JDK都保持一致,就不会出现任何问题的。
问题二:运行MapReudce找不到相关类
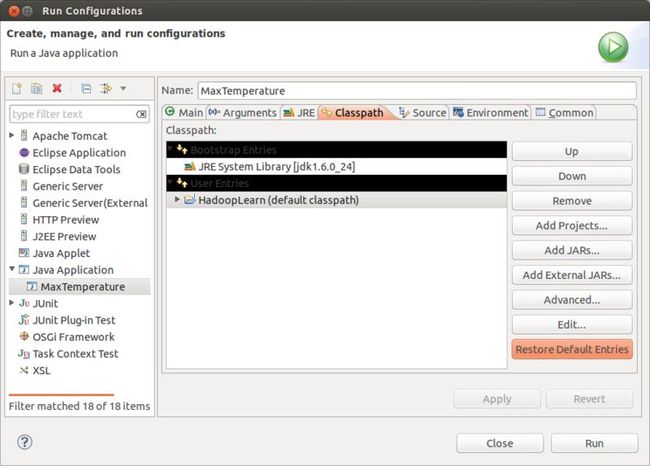
当程序运行一次后,再次修改程序后我发现程序的结果并没有发生变化,我就以为是程序没有重新编译(其实是编译了,只是程序内存出现了不容易发现的错误,即问题三:),然后我就手动删除项目下已经编译产生的class文件,然后重新执行的时候程序会报错误:找不到或无法加载主类 minTemp.MinTemperature 后来无论怎样都是不行,实际上这个类是没有问题的啊,新建项目或者项目重新改名后在Run Configuration 中进行如下的设置,及对ClassPath重建默认的实体,之后程序便可以顺畅执行。
问题三:MapReduce中的Reduce无效
使用Hadoop 自带的最大温度值示例,后来自己把这部分的最大温度值改为,最小温度值。运行后,发现无论最小温度值还是最大温度值,结果都不对,程序的结果Reduce的输入记录数和Reduce的输出记录数一样,正常处理则不会出现这种情况,而这个时候MapOut显示进行类分成了2组,这是对的。这是为什么呢,为什么Reduce没有作用的,仔细查看代码也逻辑没有错误啊,编写也没有错误啊。
13/06/02 10:52:41 INFO mapred.JobClient: Reduce input groups=2
13/06/02 10:52:41 INFO mapred.JobClient: Combine output records=0
13/06/02 10:52:41 INFO mapred.JobClient: Map input records=5
13/06/02 10:52:41 INFO mapred.JobClient: Reduce shuffle bytes=0
13/06/02 10:52:41 INFO mapred.JobClient: Reduce output records=5
13/06/02 10:52:41 INFO mapred.JobClient: Spilled Records=10
13/06/02 10:52:41 INFO mapred.JobClient: Map output bytes=45
13/06/02 10:52:41 INFO mapred.JobClient: Combine input records=0
13/06/02 10:52:41 INFO mapred.JobClient: Map output records=5
13/06/02 10:52:41 INFO mapred.JobClient: Reduce input records=5
经仔细查看代码发现,在旧版的MapReduceAPI中,reduce(Text key, Iterator<IntWritable> values, Context context)方法中Reduce的输入是一个实现了Iterator接口的列表,而新版的API中reduce(Text key, Iterable<IntWritable> values, Context context)方法的Reduce的输入是一个实现了Iterable接口的列表。查看Iterable的源码中看到
/** Implementing this interface allows an object to be the target of
* the "foreach" statement.
* @since 1.5
*/
意思时说实现了此接口的对象,允许该对象可以通过foreach来遍历其中的内容。
而实现类Iterator接口的对象可以使用values.hasNext()和values.next()进行元素的访问。
所以,自己的问题主要是没有完全使用新版本的API,将Reduce的API改为新版的,遍历元素选择相应的既可。
安徽隆兴禽业(www.58lxqy.com)全年大量供应状元红鸡苗(红玉鸡苗)、固始鸡土鸡苗、淮南王土鸡苗,散养鸡苗,大红公鸡苗及各类土鸡种蛋。批发订购:13075005200 QQ:1170693418 地址:阜阳市太和县倪邱镇孙庙105国道东侧。
安徽鸡苗,阜阳鸡苗,安徽土鸡苗,阜阳土鸡苗,鸡苗孵化,河南鸡苗,山东鸡苗,河南土鸡苗,山东土鸡苗,固始鸡,淮南王,纯红肉杂,纯红公鸡。