SQL Server 执行计划分析
当一个查询到达数据库引擎时,SQL Server执行两个主要的步骤来产生期望的查询结果:
第一步:查询编译,生成查询计划。
第二步:执行这个查询计划。
1. 用于演示分析执行计划的查询语句
/* 查询返回所有来自London且发生过5个以上订单的所有消费者的ID和订单数 */ USE Northwind GO SELECT C.CustomerID ,COUNT(O.OrderID) AS NumOrders FROM Customers C LEFT OUTER JOIN dbo.Orders O ON C.CustomerID = O.CustomerID WHERE C.City = 'London' GROUP BY C.CustomerID HAVING COUNT(O.OrderID) > 5 ORDER BY NumOrders
2. 图形化的查询计划,如下图:
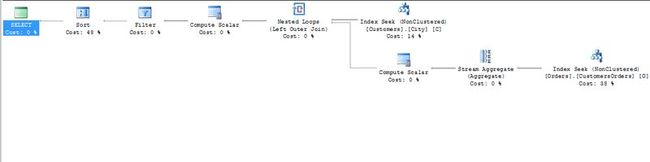
3. 上图中的箭头,表示数据流。箭头的粗细,表示传递数据行数的多少。鼠标放到1所在位置的线上时,可以看到对应的详细信息。
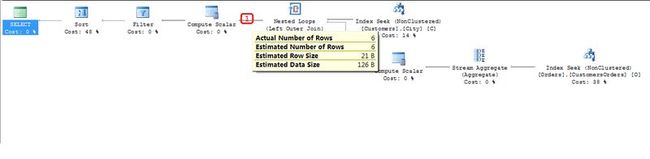
4. 查询引擎先对Customers表执行Index Seek(把鼠标放到Index Seek图表上,可以看到如下提示窗口),找到第一个来自London的Customer,并且把该行数据传递到Nested Loops运算符。
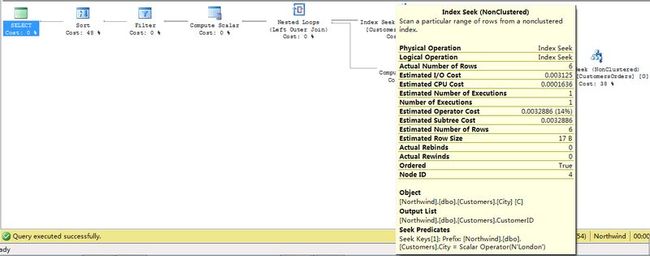
5.数据传递到Nested Loops运算符以后,激活运算符的内侧运算(Compute Scalar,Stream Aggregate,Index Seek).首先执行Index Seek。根据Nested Loops的外部输入对应的CustomerID,查询到对应的Order.
6.上一步Index Seek查询的结果,传递给Stream Aggregate运算符。在执行Stream Aggregate运算中定义了表达式[Expr1009]=Count(*),进行数据统计。
【Stream Aggregate 运算符按一列或多列对行分组,然后计算查询返回的一个或多个聚合表达式。此运算符的输出可供查询中的后续运算符引用和/或返回到客户端。Stream Aggregate 运算符要求输入在组中按列进行排序。如果由于前面的 Sort 运算符或已排序的索引查找或扫描导致数据尚未排序,优化器将在此运算符前面使用一个 Sort 运算符。在 SHOWPLAN_ALL 语句或 SQL Server Management Studio 的图形执行计划中,GROUP BY 谓词中的列会列在 Argument 列中,而聚合表达式列在 Defined Values 列中。】【摘自:technet】
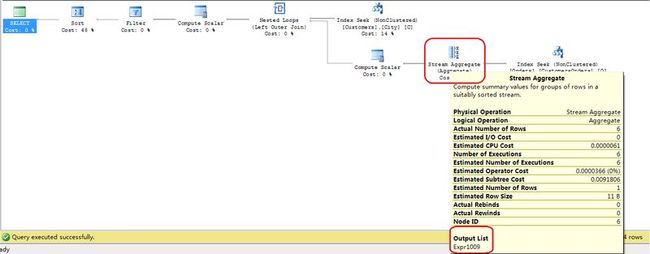
7.Stream Aggregate 运算符的统计结果,传递给Cumpute Scalar运算符,在执行Cumpute Scalar中定义了表达式[Expr1004]=CONVERT_IMPLICIT(int,[Expr1009],0);
Cumpute Scalar运算符把统计结果[Expr1004]保存到从Nested Loops外部输入的那行数据中。
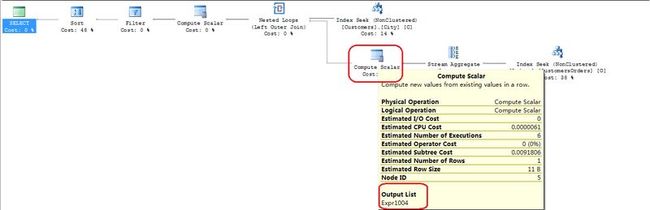
8.新组成的这行数据,被传送到Cumpute Scalar运算符(Nested Loops左侧的),在这一步的过程中Expr1004表达式被重新赋值[Expr1004]=CASE WHEN [Expr1004] IS NULL THEN (0) ELSE [Expr1004] END;重新被赋值的表达式[Expr1004]被传递给Filter运算符。
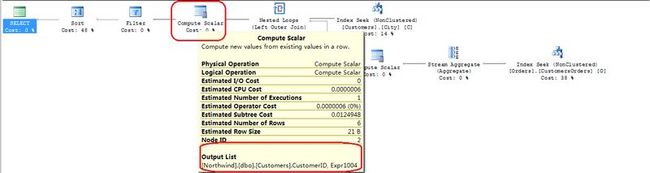
9.Filter运算符接收到数据以后,执行了WHERE:([Expr1004]>(5))的条件判断;如果条件判断为真,则把结果传递给Sort运算符。
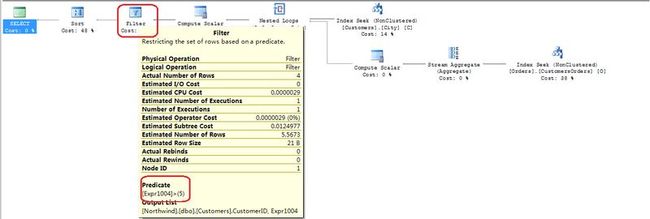
10.Sort运算符接收到数据以后,并不会马上把数据传递到下一步。而是重复4-10的步骤;当所有的行到达Sort运算符后,执行Sort运算符操作,向下一步传递按正确顺序的行数据。

【示例数据库脚本】http://files.cnblogs.com/ucos/Northwind.zip