Samza文档翻译 : Comparison Introduction
http://samza.incubator.apache.org/learn/documentation/0.7.0/comparisons/introduction.html
这里有一些使得Samza和其它流处理项目不同的高层设计决策。
The Stream Model 流模型
流是Samza job的输入和输出。Samza有非常强的流模械型——不仅是一个简单的消息交换系统。Samza中的stream是一个分区的、每个分区有序的、可重放的、多订阅者的,无损的消息序列。(A stream in Samza is partitioned,ordered-per-partition, replayable, multi-subscriber, lossless sequence of messages)。stream不仅是系统的输入输出,而且将处理步骤进行缓存,使得它们互相隔离。
这个更强的模型需要持久化、容错、以及流的实现提供缓存功能。一个Samza job可以停止消费几分钟,甚至几小时(可能因为一个不好的配置或者长时间运行的运算)而不会对上游的job有任何影响。这使得Samza适于大规模布署,例如处理一个大型公司的所有数据流:job之间的独立使得它们可以被使用不同代码库、有不同SLA的不同小组来写代码实现、拥有、运行。
这样的设计受到我们使用Hadoop构建类似的离线处理流水线之经验的启发。在Hadoop中,processing stages是MapReduce jobs, processing stage的输出是HDFS里一个目录里的文件。下一个processing stage就的输入就是前一个processsing stage的输出。我们发现stage之间的独立使得我们可以有数百个松耦合的job,这些job由不同的小组维护,组成了一个离线处理生态系统。我们的目标是把这样丰富的生态系统复制到近时实的环境里。
这个强“流模型”的第二个好处就是所有的stage都是多订阅者multi-subscriber的。在实际上,这意味着如果一个人添加加了一些生成输数据流的处理流程,那么其它人可以看到这些输出,消费它们,构建于它们之上,而不会和另一个人的job有代码有任何耦合。一个讨人喜的副作用是这使用调试变得方便,因为你可以手动的查看任何一个stage的输出。
最后,这个强“流模型”strong stream model极大简化了Samza框架特性的实现。每个job只需要自己的输入输出,在出故障的时候,每个job都可以独自被恢复和重启。不必要对整个数据流图做中央控制。
为这个strong stream model而做的妥协是消息被写在磁盘上。我们乐于做出这个妥协因为MapReduce和HDFS展示了持久化存储也可以提供很高的读写吞吐量,并且几乎无限的磁盘空间。这个观察是kafka的基础,Kafka提供了数百MB/秒的有备份的吞吐,以及每个节点数TB的磁盘空间。所以按我们的使用方式,磁盘吞吐不是瓶颈。
MapReduce经常被指责进行不必要的磁盘写。但是,这个指责对于流处理不怎么适用:像MapReduce一样的批处理经常被用于处理在短时间内处理很大的历史数据集(比如,在10分钟内查询一分钟的数据),而流处理大都需要跟进稳定的数据流(在10分钟内处理10分钟的数据)。这意味着流处理的原始吞吐量需求大都比批处理低几个数量级。
State 状态
只有非常简单的流处理问题才是无状态的(例如:一次处理一条消息,和其它消息都没有关系)。很多流处理程序需要它的任务能维护一些状态,例如:
- 如果需要知道对于一个user ID 已经有多少条消息,就需要为每个user 维持一个计数器。
- 如果想要知道每天有多少不同的用户访问了你的网站,你需要保持一个use ID的集合,这个集合里的user ID今天至少出现了一次。
- 如果你需要对两个流做join(比如,如果你需要知道广告的点进比click-through rate,你需要把展示广告的消息流和点击广告的消息流做join)你需要存储一个流中的消息直到你从另一个流中收到了相关的消息。
- 如果你需要把从数据库获得的一些信息添加进消息(比如,把页面访问消息用访问页面的用户的信息进行扩展),这个job就需要访问数据库的当前状态。
一些状态,例如计数器,可以被保存在任务的内存中的计数器里,但是如果这个任务重启了,这些状态可能就丢失了。或者,你可以把这些状态存在远端的数据库里,但是如果你每处理一条消息就进行一次数据库查询,那么性能就可能差到不可接受。Kafka可以轻松地在每个节点上处理100k~500k消息/秒(和消息大小有关),但是查询一个远端的键值存储的吞吐量可能只有1~5k请求/秒——慢了两个量级。
在Samza中,我们付出了专门的努力使得它具有高性能以及可靠的状态。关键在于对每个节点保持状态在本地(这样就不需要通过网络进行查询),并且通过复制状态变化到其它流来使得它能应对机器故障(译注:这里的复制应该是说把当前任务的输出发到其它的Stream里,这就利用了其它Stream进行持久化)。
这种做法和数据库的“变化捕获”联系在一起就变得很有趣。拿之前的例子来说:你有一个包括了user ID的页面点击流,你想把这些消息用user的信息进行扩充。乍一看来,你唯一的选择就是对每一个user ID去查用数据库。但是有了Samza,就可以做得更好。
“变化捕获”意味着每次数据库里的数据发生变化,你获得一个消息来告诉你变化是什么。如果你有一个这样的消息流,通过从数据库创建起回放整个流,你可以获得数据库的所有内容。这个changelog流同样可以做为Samza job的输入流。
现在你可以写一个Samza job,它使用页面点击事件和changelog做为输入。你确保它们使用同样的key(例如 user ID)做分区。每次一个changelog事件进来,你就把更新后的用户信息写在task的本地存储上。每次一个页面点击事件进来,你从本地存储中获取最新的用户信息。这样的话,你就可以把所有的状态保持在task的本地,而不用去查询远端的数据库。
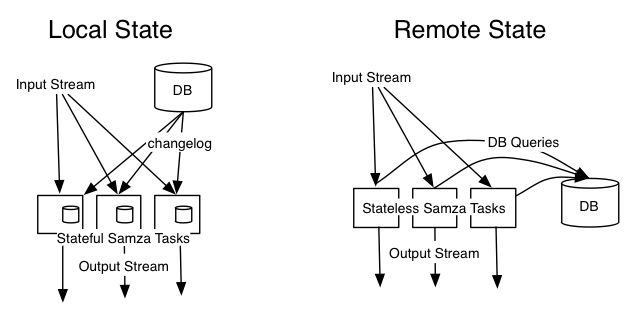
事实上,现在你有了主数据库的一个副本,这个副本被分区,这些分区和Samza task在一台机器上。数据库写仍然需要通过主数据库,但是当你在处理消息时需要读数据库,那你就只需要查询本地的状态。
这种做法不仅比查询远端的数据库要快得多,而且它也更容易操作。如果你使用Samza处理一个很大容量的流,并且对每个消息都做一次远程查询,那么你很容易就使得数据库过载了,这样就会影响其它使用那个数据库的服务。但是,当一个task使用本地状态,它就和其它东西是独立的,就不会影响其它服务。
分区的本地状态不总是好的,也不总是必须的——Samza不会阻止你查询外部的数据库。如果你不能从你的数据库获取其变化信息,或者你需要其它远程服务的逻辑,那么当然从你的Samza job来请求一个远端的服务也是很方便的。但是如果你需要使用在本地的状态,那么 Samza本身提供了这功能。
Execution Framework 执行框架
我们所做的最后一个决定是不去为Samza构建一个自己的分布式执行系统。取而代之后是,执行环境是可插拔的,目前是由YARN来提供。这样有两点好处:
第一个好处是很实际的:有另一群聪明人在搞execution framework。YARN正在以很快的步骤开发,并且己经支持了很多跟资源限定和安全有关的功能。它允许你控制集群的哪一部分由哪些用户和用户组来使用,并且可以通过cgroups控制每个节点的资源使用(CPU,内存等)。YARN可以大规模运行以支持Hadoop,并且有希望成为无所不在的一层。因为Samza整个通过YARN运行,因此在YARN集群之外没有另外的守护进程或者master。也就是说,如果你已经有了Kafka和YARN,你就不用安装其它东西来运行Samza job。
第二点,Samza和YARN的组合完全是组件化的。和YARN的组合在另外一个包里,并且Samza的主框架在编译时并不依赖它。它意味着YARN可以被另一个虚拟化框架取代——我们对增加Samza和AWS的组合很感兴趣。很多公司使用AWS,AWS本身就是一个虚拟化框架,它和YARN对于Samza是一样的:它允许你来创建和销毁虚拟"container“机器以及保证这些container使用确定的资源fixed resources。因为流处理任务是长时间运行的,在AWS之内运行一个YARN集群,然后对单独的job进行调度,这种做法有点傻。反之,一个更合适的方法是为你的job直接分派一些EC2实例。
我们认为在像Mesos和YARN这样的开源的虚拟化框架,以及像Amazon提供的商业化的云服务里有很多创新,所有装Samza和它们进行组合是合理的。
下一节:MUPD8 (先不翻译了)