读书笔记《A Categorization Scheme for Semantic Web Search Engines》
A Categorization Scheme for Semantic Web Search Engines
语义垂直搜索引擎的一种分类方案
论文作者信息:
Kyumars Sheykh Esmaili, Hassan Abolhassani
Semantic Web Research Laboratory
Computer Engineering Department
Sharif University of Technology, Tehran, Iran
[email protected], [email protected]
关于语义搜索引擎应该做什么,有一些不同的观点。本文中,介绍并详细阐述了一个语义垂直搜索引擎的分类方案。对每一类,根据所推荐的一般架构描述其组件,讨论了这些组件的各种使用途径。我们也建议了一些因子用于评估每一类系统。
1. Introduction
这篇论文尝试分析语义网搜索引擎,并提出一个合理的分类方案。在这篇论文之前,没有这方面的工作报告。
语义网(SW)有一些影响搜索过程的特征
在搜索中包含的是
一般:web documents,语义网:真实世界中的所有对象
被机器可以像人一样,理解语义网的信息
语义网的语言比html要高级
在语义网里,可能对一个单独的概念分配信息
语义搜索引擎与一般搜索引擎的基本区别:
使用逻辑架构,使得更智能的检索成为可能
文件里有更复杂的关系,导致元数据维护、更新问题变得重要,排名更复杂
指明对象间精确的关系,使对(一个搜索结果更好的形象化技术)的需求更显著
语义网搜索的两个重要方面
1. 一个重要方面是本体和元数据 的使用。本体提供特定领域的实体的详细概念。
2. 另一个重要方面是对现有网页的语义标注。标注对于机器理解网页内容是元数据有用的(meta-data useful)。这些元数据概念是指向已定义本体的指针。
语义网的用户可以分为两组。
1. 一组是普通用户,就像现存网络一样做搜索,但是需求比传统搜索引擎更精确和完整的结果
2. 第二组是语义网应用开发者,他们的主要目标是搜索和检索语义网文件
根据这两个分组,可以把语义搜索引擎分为两类:
1. 针对语义网文件的引擎:只搜索用特定语义网语言表示的文件
2. 尝试使用语义网标准和语言改进搜索结果的引擎:这类引擎的一个重要方面是使用内容信息
2. Annotation methods
语义网搜索引擎的主要问题之一是标注。
标注可以基于以下方面分类类:
元数据类型。元数据可以分为两类:
结构化的:关于内容的非上下文信息被表示
语义的:主要关注的是详细内容信息,通常被存储为RDF三元组
生成途径
一个简单的途径是不考虑整个页面的主题,只使用页面的结构化信息和自然语义处理技术
一个更好的途径是在生成过程中使用本体。这种情况下可以使用聚类算法来区分页面的一般类型,然后对得到的类型使用前面的特殊本体,生成元数据使这个页面的本体概念和关系实例化。
产生源:
3. Ontology search engines
由于下列原因,不能将现有搜索引擎用于语义网文件:
现有技术不允许索引和检索语义标签
不使用标签的意思
不能用形象的形式显示结果
本体不是分离的实体,通常具有现有搜索引擎不能处理的交叉引用
通常有两种途径来处理这些文件:
对现有搜索引擎进行修改
创建一个特殊的搜索引擎
A. Ontology meta search engines
这个组通过把一个建立在现有搜索引擎之上的系统来做检索。
这个系统有两种类型:
第一种类型:有一个只搜索特定文件类型的搜索引擎。这类系统关心的是结果的形象化和浏览。
第二种类型:可以搜索语义标签。由于那些标签被下面的搜索引擎忽略,文件和用户查询的一个中间形式被使用。一种称为Swangle的技术用于这个目的。使用这种技术,RDF三元组被翻译成适合下面搜索引擎的字符串。
B. Crawler based ontology search engines
这些搜索引擎使用一个特殊的爬虫爬起语义网文件。
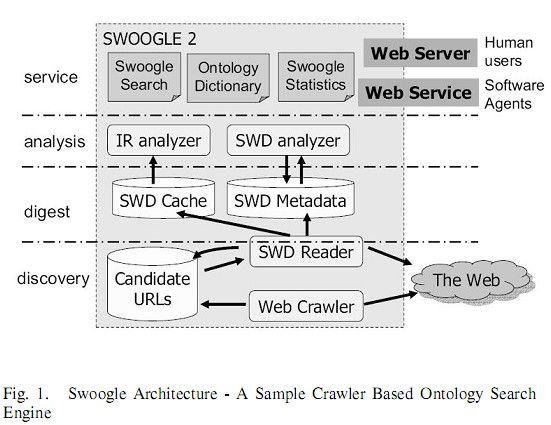
架构的四个部分分析:
Discovery:
爬取SW文件不同于html文件。事实上,它们是比传统爬虫复杂的知识爬虫(knowledge crawler)。在SW,我们使用RDF三元组的URI表示知识(knowledge)。不同于html超链接,RDF里的URI可能指向一个不存在的实体。RDF可能嵌入html文件或者存储在分开的文件。
这些爬虫有以下特征:
Should crawl on heterogeneous web resource(owl,oil,daml,rdf,xml,html)应该在不均匀的网络资源上爬行
Avoid circular links
Completing RDF holes
Finding new SW document from info in the currently under process document
在现在正在处理的文件的信息中发现新的SW文件
这些系统中使用三种类型的元数据
Language attributes
Relationships between SW document(prior version, imports, extends)
Meta data resulting from analysis
Digest:
最近版本的算法使用一个SW文件中概念的排名和优先级之和来计算文件的全局排名。
Analysis:
离线排名可以引用Page Rank的思想。重点是SW中关系的计数、类型和意思比current web更完整。
OntoRank
Service:
4. Semantic search engines
在SW中,改进搜索结果的最重要的工具是内容概念和它与本体的一致性。
这类搜索引擎可以分为三组
第一组,最大,目标是为了更好的结果增加语义操作
第二组,使用SW工具,目标是积累我们所研究的主题的信息
第三组,尝试找出两个或多个项的语义关系
A. Context based search engines
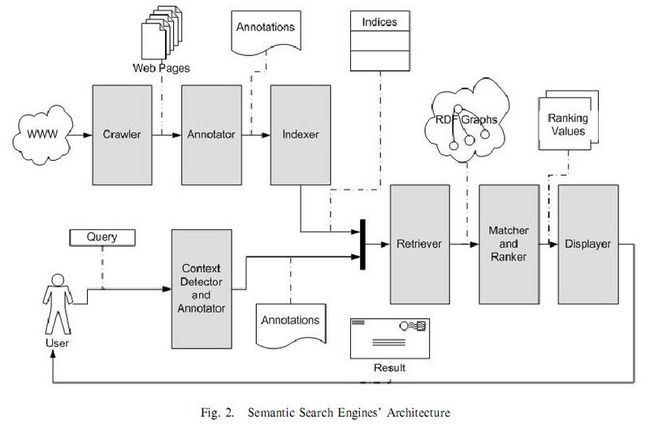
只有很有限的搜索引擎具有图中的所有功能。
1. Crawling the sematic web
2. Metadata generation
3. Indexing
4. Accepting user’s requests
5. Generating meta data for user requests
6. Retrieval and ranking model
7. Display of results
B. Evolutionary search engines
C. Sematic association discovery search engines
5. Discussion and evaluation
6. Conclusion
7. Future work
8. Acknowledgment