翻译:An Incremental Approach to Compiler Construction 逐步构建编译器的方法
原文
http://scheme2006.cs.uchicago.edu/11-ghuloum.pdf
目标语言scheme
文档: https://www.scheme.com/tspl4/
scheme语法简单说明,前置式

实际是LISP的两大分支之一(Common Lisp、scheme),可参考LISP语法。
对照翻译
An Incremental Approach to Compiler Construction
逐步构建编译器的方法
Abdulaziz Ghuloum
Department of Computer Science, Indiana University, Bloomington,
印第安纳大学,计算机科学系,布卢明顿分校
IN 47408
[email protected]

摘要
编译器被认为是由巫师精心制作的神奇工具,仅凭凡人无法理解。关于编译器的书籍更像是巫师的对话:由全知全能的从业者编写和阅读。现实生活中的编译器太复杂,无法作为教学工具。而现实生活中的编译器与教学玩具编译器之间的差距太大。新手编译器编写者面对着一道难以逾越的障碍,“最好写一个解释器”。
本文的目标是打破这种障碍。我们展示了构建编译器可以和构建解释器一样容易。我们构建的编译器接受Scheme编程语言的一个大子集,并为英特尔x86架构生成汇编代码,这是个人计算机的主导架构。编译器的开发分为许多小的增量步骤。每个步骤产生了一个逐渐扩展的Scheme子集的完全可工作的编译器。每个编译器步骤产生了可以直接由硬件汇编然后执行的真实汇编代码。我们假设读者熟悉基本的计算机体系结构:其组件和执行模型。不需要详细了解英特尔x86架构。
编译器的开发在一个扩展教程中进行了详细描述。教程的支持材料,如与全面测试套件配合使用的自动化测试设施,也随教程提供。我们希望Scheme的现有和未来的实现者能在本文中找到开发高性能编译器的动力和实现目标的方法。
分类和主题描述
D.3.4 [处理器]:编译器;K.3.2 [计算机和信息科学教育]:计算机科学教育
关键词
Scheme(Lisp语言的一种方言,奉行极简主义),编译器


1.引言
编译器传统上被视为复杂的软件。这种复杂性的观念主要源自传统的编译器教学方法,以及缺乏针对实际语言的小型且功能齐全的编译器示例。
编译器书籍分为两个极端。一些书籍关注于“教育性”玩具编译器,而另一些关注于“工业级”优化编译器。玩具编译器过于简单,无法帮助新手编译器编写者构建出有用的编译器。这些编译器的源语言通常缺乏深度,目标机器通常是虚构的。尼古劳斯·维尔特(Niklaus Wirth)指出:“为了使得生成的编译器相对简单,并且开发过程不受只对于特定机器及其特性相关的细节的影响,我们假定一个按照我们自己选择的架构”[20]。另一方面,高级书籍主要关注优化技术,因此面向的是已经精通该主题的人群。在编译器编写领域,没有逐步进展的方式。介绍编译器的通常方法是描述一个已经完成和精炼的编译器的结构和组织。这些书籍中所呈现的材料的顺序与编译器的传递相吻合。许多编译器编写者需要了解的问题已经在之前解决了,只有最终的解决方案才被呈现出来。读者并没有参与到开发编译器的过程中。
在这些书籍中,编译器实现的顺序呈现导致了对整体情况的关注不足。太多的关注点放在了编译器的各个传递上;因此,读者并没有积极意识到单个传递与其他传递的相关性以及它在整个情景中的位置。安德鲁·阿佩尔(Andrew Appel)指出:“实现了书中第一部分描述的所有阶段的学生将拥有一个可工作的编译器”[2]。Appel书中的第一部分在介绍了有关Tiger不同传递的11章后,通过一个关于“将所有内容整合起来”的6页章节结束。
此外,实践性的主题,例如针对真实机器的代码生成,与操作系统或其他语言的接口,堆分配和垃圾收集,以及围绕动态语言的问题,要么完全省略,要么放在附录中。Muchnick指出:“本书中大部分与编译器相关的材料都致力于适合编译的语言:具有静态、编译时类型系统,不允许用户逐步更改代码,并且通常更多地使用堆存储而不是栈存储的语言”[13]。


2. 初步问题
要开发一个编译器,需要做出几项决定。
必须选择源语言、实现语言和目标架构。必须设定开发时间框架。必须确定开发方法论和最终目标。为了我们的教程目的,我们做出了以下决定。
2.1 我们的目标受众
我们不假设读者对汇编语言有任何了解,除了对计算机组织、内存和数据结构的了解之外。假定读者在编写编译器方面有非常有限或没有经验。一些编写简单解释器的经验会有所帮助,但并非必需。我们假设读者具备C语言和C标准库的基本知识(例如malloc、printf等)。尽管我们的编译器将生成汇编代码,但一些功能在C中更容易实现;将其直接实现为汇编例程会让读者分心,使他们无法专注于更重要的任务。

2.2 源语言
在我们的教程中,我们选择Scheme的一个子集作为源编程语言。Scheme简单且统一的语法消除了对扫描器和解析器的长篇讨论的必要性。Scheme的执行模型,采用严格的传值调用,简化了实现。此外,在该子集中的所有Scheme原语都可以用简短的汇编指令序列来实现。尽管第一个编译器没有实现所有的Scheme功能,但解决了所有主要的与编译器相关的问题。这种实现是在完整的Scheme编译器和玩具编译器之间的折中。
选择了一个特定的源语言,我们获得了一个优势,即演示更具体,消除了从抽象概念到实际语言的联系的负担。
2.3 实现语言
我们选择Scheme作为编译器的实现语言。Scheme的数据结构简单,大多数Scheme程序员熟悉基本任务,如构造和处理列表和树。能够将Scheme程序视为Scheme数据结构大大简化了构建编译器的第一步,因为读取输入程序的问题已经解决。将实现词法分析器和解析器推迟到教程的末尾。
选择Scheme作为实现语言还消除了对复杂和专门化工具的需求。这些工具会给初学者带来很大的负担,并使读者分心,无法掌握基本概念。
2.4 选择目标架构
我们选择Intel-x86架构作为目标平台。x86架构是个人计算机上的主导架构,因此广泛可用。
谈论与特定架构脱离的编译器,把抽象的思想放在读者身上,让他们自己从抽象到具体机器的联系中衔接起来。初学者编译器作者不太可能能够自己推导出这种联系。此外,我们开发的编译器小到可以轻松移植到其他架构,并且大多数编译器过程是与平台无关的。

2.5 开发时间框架
编译器的开发必须采取小步骤进行,每个步骤都可以在一次坐下来实现和测试。需要多次实现才能完成的功能被分解成更小的步骤。完成每个步骤的结果是一个完全工作的编译器。因此,编译器编写者在开发的每个步骤中都取得了进展。这与传统的开发策略形成对比,传统策略主张将编译器作为一系列通过,只有最后一个才能给人一种成就感。采用我们的增量开发方法,每个步骤都会为Scheme的某个子集生成一个完全工作的编译器,从而将“完成”编译器的风险降至最低。这种方法对于自学编译器的人来说非常有用,因为他们可以随时调整自己能够投入的时间。在时间有限的情况下,比如学术学期,这种方法也很有用。

2.6 开发方法论
我们提倡以下迭代式开发方法:
- 选择源语言的一个小子集,可以直接编译成汇编语言。
- 编写尽可能多的测试用例,以覆盖所选语言子集。
- 编写一个编译器,接受一个表达式(在所选的源语言子集中),并输出相应的汇编指令序列。
- 确保编译器功能正常,即通过事先编写的所有测试。
- 如有必要,重构编译器,确保由于不正确的重构而导致的测试不会失败。
- 在非常小的步骤中扩展语言子集,并通过编写更多测试和扩展编译器来满足新添加的要求,然后重复该周期。
在开发周期的每个阶段,从开发的第一天开始,都可以获得给定语言子集的完全工作的编译器。编写测试用例旨在确保实现符合规范,并防止在重构步骤中引入的可能出现的错误。编译技术和目标机器的知识都是逐步建立的。消除了学习目标机器的汇编指令的初始开销——指令仅在需要时引入。编译器从小处开始,并专注于将源语言转换为汇编语言,每个增量步骤都加强了这种专注。

2.7 测试基础设施
编译器的接口由一个Scheme过程compile-program定义,该过程以表示Scheme程序的s表达式作为输入。输出的汇编代码通过emit形式发出,将编译器的输出路由到一个汇编文件中。
将编译器定义为一个Scheme过程使我们能够通过检查输出的汇编代码来交互式地开发和调试编译器。它还允许我们利用一个自动化测试设施。测试基础设施有两个核心组件:测试用例和测试驱动程序。
测试用例由示例程序和它们的预期输出组成。例如,原始+的测试用例可以定义如下:
(test-section “Simple Addition”)
(test-case ’(+ 10 15) “25”)
(test-case ’(+ -10 15) “5”)
…
测试驱动程序遍历测试用例执行以下操作:(1)输入表达式传递给compile-program以产生汇编代码。 (2)汇编代码和一个最小的运行时系统(支持打印)被汇编和链接成一个可执行文件。 (3)运行可执行文件并将输出与预期输出字符串进行比较。如果任何之前的步骤失败,则发出错误信号。


2.8 最终目标
对于本文的目的,我们将最终目标定义为编写一个功能强大到足以编译交互式求值器的编译器。构建这样一个编译器迫使我们解决许多有趣的问题。编译器必须支持Scheme核心形式(lambda、quote、set!等)和扩展形式(cond、case、letrec、内部定义等)的大型子集。虽然大多数这些形式不是必需的,但它们的存在使我们能够以更自然的方式编写我们的程序。在实现扩展形式时,我们展示了如何添加大量语法形式而不改变编译器支持的核心语言。
需要实现大量的原语(cons、car、vector?等)和库过程(map、apply、list->vector等)。其中一些库过程可以直接实现,而另一些则需要编译器的额外支持。例如,一些原语无法在不支持可变参数过程的情况下实现,而另一些则需要apply的存在。实现写入器和读取器需要添加与外部运行时系统进行通信的方法。

3. 在24个小步骤中编写编译器
现在我们已经描述了开发方法论,我们将注意力转向实际构建编译器所采取的步骤。本节简要描述了24个渐进式阶段:第一个是仅由小整数组成的小语言,最后涵盖了R5RS的大部分要求。这些阶段的更详细介绍在附带的扩展教程中。


3.1 整数
我们可以编译和测试的最简单的语言是由固定大小的整数或fixnums组成的。让我们编写一个小型编译器,它以fixnum作为输入,并生成一个返回该fixnum的程序。由于我们还不知道如何做到这一点,所以我们请求另一个已经知道的编译器gcc来帮助我们。让我们编写一个返回整数的小型C函数:
int scheme_entry(){
return 42;
}
让我们使用 gcc -O3 --omit-frame-pointer -S test.c 编译它,并查看输出。输出文件中最相关的行如下:
1. .text
2. .p2align 4,,15
3. .globl scheme_entry
4. .type scheme_entry, @function
5. scheme_entry:
6. movl $42, %eax
7. ret
第1行开始一个文本段,代码位于其中。第2行将过程的起始位置对齐到4字节边界(在这一点上不重要)。第3行通知汇编器,Scheme入口标签是全局的,以便它对链接器可见。第4行表示Scheme入口是一个函数。第5行表示Scheme入口过程的开始。第6行将%eax寄存器的值设置为42。第7行将控制返回给调用者,调用者期望接收到的值在%eax寄存器中。
从Scheme生成这个文件很简单。我们的编译器以整数作为输入,并打印给定的汇编代码,其中用要返回的值替换了输入。
(define (compile-program x)
(emit "movl $~a, %eax" x)
(emit "ret"))
为了测试我们的实现,我们编写一个小型的C运行时系统,调用我们的Scheme入口并打印它返回的值:
/* a simple driver for scheme_entry */
#include 
3.2 立即常量
在Scheme中的值不仅限于fixnum整数。布尔值、字符和空列表构成了一组立即值。立即值是那些可以直接存储在机器字中的值,因此不需要额外的存储。Scheme中的立即对象的类型是不相交的,因此,实现不能使用fixnums来表示布尔值或字符。类型还必须在运行时可用,以便驱动程序适当地打印值,并允许我们提供类型谓词(在下一步中讨论)。
一种编码类型信息的方法是将机器字的一些较低位专用于类型信息,并使用机器字的其余部分来存储值。每种类型的值由掩码和标记定义。掩码定义整数的哪些位用于类型信息,标记定义这些位的值。
对于fixnums,低两位(掩码=11b)必须为0(标记=00b)。这样就留下了30位来存储fixnum的值。
字符使用8位标记(标记=00001111b),剩下24位用于值(其中有7位实际上用于编码ASCII字符)。
布尔值给出了一个7位的标记(标记=0011111b),和1位值。空列表被赋予值00101111b。
我们扩展了编译器以适当处理立即类型。代码生成器必须将不同的立即值转换为相应的机器整数值。
(define (compile-program x)
(define (immediate-rep x)
(cond
((integer? x) (shift x fixnum-shift))
...))
(emit "movl $~a, %eax" (immediate-rep x))
(emit "ret"))
驱动程序还必须扩展以处理新增的值。以下代码阐明了这个概念:
#include 

3.3 一元基元
我们现在扩展语言以包括调用接受一个参数的基元。我们从最简单的基元开始:add1 和 sub1。要编译形如 (add1 e) 的表达式,我们首先生成 e 的代码。该代码将评估 e 并将其值放入 %eax 寄存器中。剩下的工作是通过 4 增加 %eax 寄存器的值(即 1 的移位值)。执行加法/减法的机器指令是 add1/subv。
(define (emit-expr x)
(cond
((immediate? x)
(emit "movl $~a, %eax" (immediate-rep x)))
((primcall? x)
(case (primcall-op x)
((add1)
(emit-expr (primcall-operand1 x))
(emit "addl $~a, %eax" (immediate-rep 1)))
...))
(else ...)))
接下来可以添加基元 integer->char 和 char->integer。要将整数(假设它在适当的范围内)转换为字符,首先将整数(已经左移了 2 位)进一步左移 6 位,以形成 char-shift 的总量,然后将结果标记为 char-tag。将字符转换为固定数需要将其右移 6 位。为固定数和字符选择标记对于实现这种简洁且潜在快速的转换非常重要。我们实现谓词 null?、zero? 和 not。实现每个谓词都有许多可能的方法。对于 zero?(假设操作数的值在 %eax 寄存器中),以下序列适用:
1. cmpl $0, %eax
2. movl $0, %eax
3. sete %al
4. sall $7, %eax
5. orl $63, %eax
第1行将 %eax 的值与 0 进行比较。第2行将 %eax 的值清零。第3行将 %eax 的低字节 %al 设置为 1(如果两个比较的值相等)或者设置为 0(如果不相等)。第4行和第5行从 %eax 中的一位构造出适当的布尔值。谓词 integer? 和 boolean? 处理方式类似,唯一的区别是在将其与 fixnum/boolean 标记比较之前必须提取值的标记(使用 andl)。


3.4 二元基元
一般情况下,对于二元及更高元的基元,不能使用单个寄存器来进行评估,因为评估一个子表达式可能会覆盖为另一个子表达式计算的值。为了实现二元基元(如 +、*、char
栈被安排为一组连续的内存位置。栈基址指针存储在 %esp 寄存器中。栈的基址,即 0(%esp),包含返回点。返回点是内存中的一个地址,在计算值后返回该地址,因此不应被修改。我们可以使用返回点上方的内存位置(-4(%esp)、-8(%esp)、-12(%esp) 等)来保存我们的中间值。
为了保证在表达式评估后不会覆盖任何将需要的值,我们安排代码生成器来维护栈索引的值。栈索引是一个负数,指向第一个空闲的栈位置。栈索引的值初始化为 -4,并且每次将新值保存到栈上时都会减去 4(即字大小,4 字节)。以下代码片段说明了如何实现基元 +:
(define (emit-primitive-call x si)
(case (primcall-op x)
((add1) ...)
((+)
(emit-expr (primcall-operand2 x) si)
(emit "movl %eax, ~a(%esp)" si)
(emit-expr
(primcall-operand1 x)
(- si wordsize))
(emit "addl ~a(%esp), %eax" si))
...))
其他基元(-、*、=、<、char=? 等)可以通过我们目前所知道的知识轻松实现。

3.5 局部变量
现在我们有了一个栈,实现 let 和局部变量就很简单了。所有的局部变量都将保存在栈上,并且会维护一个将变量映射到栈位置的环境。当代码生成器遇到 let 表达式时,它首先逐个评估右侧表达式,并将每个值保存在特定的栈位置。一旦所有右侧表达式都评估完毕,环境就会扩展,将新变量与它们的位置关联起来,并在新扩展的环境中生成 let 主体的代码。当遇到对变量的引用时,代码生成器会在环境中定位变量,并发出从该位置加载的指令。
(define (emit-expr x si env)
(cond
((immediate? x) ...)
((variable? x)
(emit "movl ~a(%esp), %eax" (lookup x env)))
((let? x)
(emit-let (bindings x) (body x) si env))
((primcall? x) ...)
...))
(define (emit-let bindings body si env)
(let f ((b* bindings) (new-env env) (si si))
(cond
((null? b*) (emit-expr body si new-env))
(else
(let ((b (car b*)))
(emit-expr (rhs b) si env)
(emit "movl %eax, ~a(%esp)" si)
(f (cdr b*)
(extend-env (lhs b) si new-env)
(- si wordsize)))))))


3.6 条件表达式
在汇编级别上,条件评估是简单的。最简单的 (if test conseq altern) 实现如下:
(define (emit-if test conseq altern si env)
(let ((L0 (unique-label)) (L1 (unique-label)))
(emit-expr test si env)
(emit-cmpl (immediate-rep #f) eax)
(emit-je L0)
(emit-expr conseq si env)
(emit-jmp L1)
(emit-label L0)
(emit-expr altern si env)
(emit-label L1)))
上面的代码首先评估测试表达式,并将结果与假值进行比较。如果测试的值为假,则控制转移到替代代码;否则,控制将继续执行到结果代码。


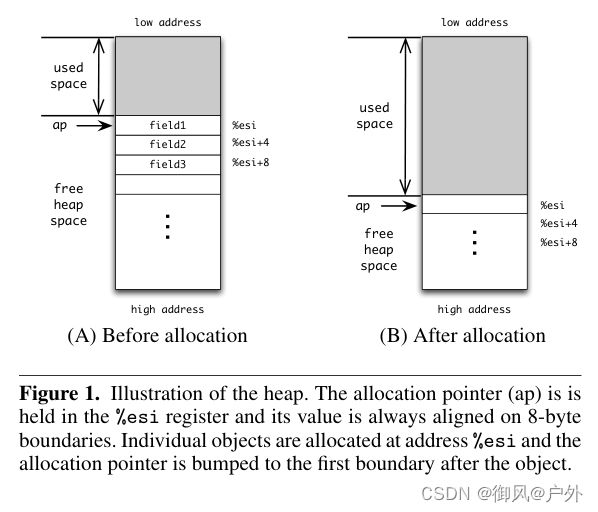
3.7 堆分配
Scheme 的pairs对、vector向量、字符串等对象不能放在一个机器字中,必须在内存中进行分配。我们将所有对象都分配在内存的一个连续区域中。堆在程序开始时预先分配,并且其大小足够大,以满足当前的需求。堆的起始指针被传递给 Scheme 入口作为分配指针。我们指定一个寄存器 %esi 来保存分配指针。每次构造一个对象时,根据对象的大小递增 %esi 的值。
对象的类型也必须彼此可区分。我们使用与对固定数、布尔值和字符相似的标记方案。每个指向堆分配对象的指针都用一个 3 位标记标记(001b 用于对、010b 用于向量、011b 用于字符串、101b 用于符号,110b 用于闭包;000b、100b 和 111b 已用于固定数和其他即时对象)。为使该标记方案正常工作,我们需要保证每个堆分配对象的最低三位为 000b,以便标记和指针的值不会干扰。这通过始终在双字(或 8 字节)边界上分配对象来实现。
首先让我们考虑如何实现对。对需要两个字的内存来保存其 car 和 cdr 字段。调用 (cons 10 20) 可以被转换为:
movl $40, 0(%esi) # set the car
movl $80, 4(%esi) # set the cdr
movl %esi, %eax # eax = esi | 1
orl $1, %eax
addl $8, %esi # bump esi
基元 car 和 cdr 非常简单;我们只需要记住,对于对来说,其指针就是其地址加 1。因此,car 和 cdr 字段分别位于指针的 -1 和 3 处。例如,基元 caddr 的转换为:
movl 3(%eax), %eax # cdr
movl 3(%eax), %eax # cddr
movl -1(%eax), %eax # caddr
向量和字符串与对不同,因为它们的长度是可变的。这有两个影响:(1) 我们必须在向量/字符串中保留一个额外的内存位置来存储长度,以及 (2) 分配完对象后,分配指针必须对齐到下一个双字边界(分配对是可以的,因为它们的大小是 8 的倍数)。例如,对基元 make-vector 的调用转换为:
movl %eax, 0(%esi) # set the length
movl %eax, %ebx # save the length
movl %esi, %eax # eax = esi | 2
orl $2, %eax
addl $11, %ebx # align size to next
andl $-8, %ebx # object boundary
addl %ebx, %esi # advance alloc ptr
字符串的实现方式类似,只是字符串的大小比同样长度的向量的大小小。基元 string-ref(和 string-set!)还必须注意将一个字节值转换为字符(反之亦然)。

Figure 2. 从(A)调用者在进行过程调用之前的栈视图,以及(B)调用过程进入过程时的被调用者侧的栈视图。

3.8 过程调用
过程和过程调用的实现可能是构建我们编译器中最困难的部分。其难度在于 Scheme 的 lambda 形式执行了多个任务,编译器必须将这些任务分开。首先,lambda 表达式会封闭在其体中出现的自由变量,因此我们必须执行一些分析来确定在 lambda 体中引用但未定义的变量集合。其次,lambda 构造一个可以传递的闭包对象。第三,过程调用和参数传递的概念必须在同一点引入。我们将逐一处理这些问题,从过程调用开始,暂时忘记 lambda 周围的其他问题。
我们将我们的代码生成器接受的语言扩展为包含顶层标签(每个标签绑定到一个代码表达式,其中包含形式参数列表和一个主体表达式)和标签调用。
<Prog> ::= (labels ((lvar <LExpr>) ...) <Expr>)
<LExpr> ::= (code (var ...) <Expr>)
<Expr> ::= immediate
| var
| (if <Expr> <Expr> <Expr>)
| (let ((var <Expr>) ...) <Expr>)
| (primcall prim-name <Expr> ...)
| (labelcall lvar <Expr> ...)
新形式的代码生成如下:
- 对于 labels 表单,创建一组新的唯一标签,并构建初始环境,将每个 lvar 映射到其相应的标签。
- 对于每个代码表达式,首先发出标签,然后是主体的代码。用于主体的环境除了 lvar 外,还包含每个形式参数到第一组栈位置(-4、-8 等)的映射。用于评估主体的栈索引从形式参数之上的最后一个索引开始。
- 对于 (labelcall lvar e …),首先评估参数,并将它们的值保存在连续的栈位置中,跳过一个位置以用于返回点。一旦所有参数都被评估,栈指针 %esp 的值会递增,指向返回点下方的一个字。发出与 lvar 关联的标签的调用。调用指令将 %esp 的值减少 4,并将下一条指令的地址保存在适当的返回点槽中。一旦被调用的过程返回(在 %eax 中有一个值),栈指针将调整回其初始位置。
图 2 说明了来自调用者和被调用者角度的栈视图。


3.9 闭包
在我们目前所拥有的基础上实现闭包应该是直接的。首先,我们修改我们的代码生成器接受的语言,如下所示:
- 添加形式 (closure lvar var …)。此形式负责构造闭包。闭包的第一个单元格包含过程的标签,其余单元格包含自由变量的值。
- 将 code 形式扩展为包含自由变量的列表,除了现有的形式参数。
- 将 labelcall 替换为 funcall 形式,其第一个参数取任意表达式,而不是一个 lvar。
闭包形式类似于对向量的调用。与 lvar 关联的标签存储在 0(%esi) 处,变量的值存储在接下来的位置。为了获取闭包的值,%esi 的值被标记,然后根据需要递增 %esi 的值。
代码形式除了将形式参数与相应的栈位置关联起来之外,还将每个自由变量与其在闭包指针 %edi 中的偏移关联起来。
funcall 在评估所有参数之前和以前一样,但是跳过的不是一个而是两个栈位置:一个用于保存当前闭包指针的当前值,另一个用于返回点。在评估和保存参数之后,对操作符进行评估,并将其值移动到 %edi(其值必须保存到其栈位置)。%esp 的值进行调整,并通过闭包指针的第一个单元格进行间接调用。从调用返回时,%esp 的值进行调整,并且 %edi 的值从保存它的位置恢复。
还需要解决一个额外的问题。我们编译器接受的源语言具有 lambda 形式,但没有标签、代码、闭包形式。因此,在我们的代码生成器接受之前,必须将 Scheme 输入转换为此形式。转换在两个步骤中很容易完成:
- 进行自由变量分析。源程序中出现的每个 lambda 表达式都用其引用但在 lambda 体中未定义的变量集合进行注释。例如,
(let ((x 5))
(lambda (y) (lambda () (+ x y))))
转换为:
(let ((x 5))
(lambda (y) (x) (lambda () (x y) (+ x y))))
- 将 lambda 形式转换为闭包形式,并将代码收集到顶部。先前的示例产生:
(labels ( (f0 (code () (x y) (+ x y)))
(f1 (code (y) (x) (closure f0 x y))))
(let ((x 5)) (closure f1 x)))

3.10 适当的尾调用
Scheme 报告要求实现必须正确处理尾递归。通过正确处理尾调用,我们保证可以在常量空间中执行无限数量的尾调用。到目前为止,我们的编译器会将尾调用编译为普通调用,然后跟随一个返回。另一方面,适当的尾调用必须执行 jmp 到调用的目标,使用调用者自身的栈位置。
实现尾调用的一个非常简单的方法如下(在图 3 中说明):
- 所有参数都按照非尾调用参数的方式进行评估并保存在栈上。
- 对操作数进行评估,并将其放置在 %edi 寄存器中,替换当前的闭包指针。
- 将参数从它们当前在栈上的位置复制到栈底的返回点旁边的位置。
- 通过闭包指针中的地址进行间接 jmp,而不是 call。
这种处理尾调用的方法是实现要求目标的最简单的方式。在第 4 节后面讨论了通过最小化过多复制来提高性能的其他方法。
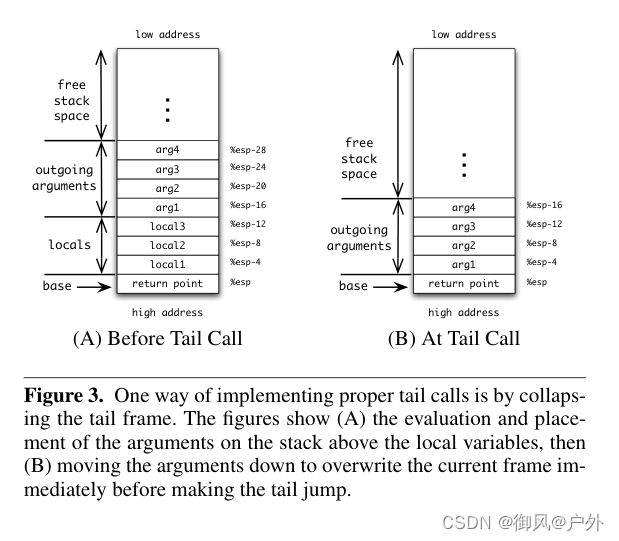
Figure 3. 实现正确尾调用的一种方式是通过折叠尾帧。图示了(A)在本地变量之上对参数进行评估和放置,然后(B)在进行尾跳转之前将参数移动下来以覆盖当前帧。

3.11 复杂常量
Scheme 的常量不仅限于即时对象。使用 quote 形式,列表、向量和字符串也可以转换为常量。Scheme 的形式语义要求引用的常量始终求值为相同的对象。下面的例子必须始终求值为 true:
(let ((f (lambda () (quote (1 . "H")))))
(eq? (f) (f)))
因此,通常情况下,我们不能将引用的常量转换为未引用的一系列构造,如以下错误的转换所示:
(let ((f (lambda () (cons 1 (string #\H)))))
(eq? (f) (f)))
一种实现复杂常量的方法是将它们的构造提升到程序的顶部。示例程序可以转换为一个不包含复杂常量的等价程序,如下所示:
(let ((tmp0 (cons 1 (string #\H))))
(let ((f (lambda () tmp0)))
(eq? (f) (f))))
在闭包转换之前执行此转换会使引入的临时变量出现为封闭 lambda 中的自由变量。这会增加许多闭包的大小,增加堆的消耗,并减慢编译后的程序。
另一种实现复杂常量的方法是引入全局内存位置来保存这些常量的值。每个复杂常量都被分配一个标签,表示其位置。所有复杂常量都在程序开始时初始化。我们的运行示例将被转换为:
(labels ((f0 (code () () (constant-ref t1)))
(t1 (datum)))
(constant-init t1 (cons 1 (string #\H)))
(let ((f (closure f0)))
(eq? (f) (f))))
现在,代码生成器应该被修改以处理数据标签以及两个内部形式 constant-ref 和 constant-init。


3.12 赋值
让我们来看看我们的编译器如何处理变量。在源级别上,变量通过 let 或 lambda 引入。到了代码生成阶段,第三种变量(自由变量)也存在了。当一个 lambda 闭合对一个变量的引用时,我们将变量的值复制到闭包中的一个字段中。如果多个闭包引用该变量,则每个都得到其自己的值的副本。如果变量是可赋值的,那么代码中发生的所有引用和赋值都必须引用/赋值到持有变量值的同一位置。因此,每个可赋值变量都必须分配一个唯一的位置来保存其值。
我们处理赋值的方式是使可赋值变量的位置显式化。这些位置通常不能由于 Scheme 闭包的无限范围而在堆栈上分配。因此,对于每个可赋值变量,我们在堆上分配空间(大小为 1 的向量)来保存其值。对变量 x 的赋值被重写为对保存 x 的内存位置的赋值(通过 vector-set!),对 x 的引用被重写为对 x 的位置的引用(通过 vector-ref)。
下面的示例说明了赋值转换应用于一个包含一个可赋值变量 c 的程序时的情况:
(let ((f (lambda (c)
(cons (lambda (v) (set! c v))
(lambda () c)))))
(let ((p (f 0)))
((car p) 12)
((cdr p))))
=>
(let ((f (lambda (t0)
(let ((c (vector t0)))
(cons (lambda (v) (vector-set! c 0 v))
(lambda () (vector-ref c 0)))))))
(let ((p (f 0)))
((car p) 12)
((cdr p))))

3.13 扩展语法
大多数核心形式(lambda、let、quote、if、set!、常量、变量、过程调用和原始调用)已经就绪,我们可以转向扩展语言的语法。我们编译器的输入由一个宏展开器预处理,该展开器执行以下任务:
- 通过α转换将所有变量重命名为新的唯一名称。这有两个目的。首先,使所有变量都变得唯一消除了变量之间的歧义。这使得闭包和赋值转换所需的分析过程更简单。其次,不会混淆核心形式和使用相同名称的局部变量的过程调用(例如,lambda 是一个词法变量的出现 (lambda (x) x))。
- 此外,此过程在所有内部形式上放置显式标签,包括函数调用(funcall)和原始调用(primcall)。
- 扩展形式被简化为代码形式。let*、letrec、letrec*、cond、case、or、and、when、unless 和内部定义等形式按照核心形式的方式重写。


3.14 符号、库和分开编译
到目前为止,我们支持的所有原始形式都足够简单,可以直接在编译器中实现为一系列汇编指令。对于简单的原始形式,比如 pair? 和 vector-ref,这样做没问题,但对于更复杂的原始形式,比如 length、map、display 等,这种方法将不太实用。
另外,我们将语言限制为只允许原始形式出现在操作符位置:不允许传递原始形式 car 的值,因为 car 没有值。修复这个问题的一种方法是执行逆 η 转换:car ⇒ (lambda (x) (car x))。
这种方法有许多缺点。首先,生成的汇编代码中包含了太多在源程序中不存在的闭包,导致代码臃肿。其次,这些原始形式不能递归定义,也不能使用通用辅助函数定义。
另一种使扩展库可用的方法是通过将用户代码包装在一个大的 letrec 中,该 letrec 定义了所有原始库。这种方法不被鼓励,因为用户代码与库代码的混合会妨碍我们调试编译器的能力。
更好的方法是将库在单独的文件中定义,将它们独立编译,并直接与用户代码链接。在进入用户程序之前,库原语被初始化。每个原始形式都被赋予一个全局位置或标签,以保存其值。我们修改我们的编译器以处理两个额外的形式:(primitive-ref x) 和 (primitive-set! x v),它们类似于我们在 3.11 中介绍的 constant-ref 和 constant-init。唯一的区别是全局标签被用来保存原始形式的值。
第一个库文件初始化了一个原始形式:string->symbol。我们的第一个 string->symbol 的实现不需要很高效:一个简单的符号链表就足够了。string->symbol 原始形式,顾名思义,以字符串作为输入并返回一个符号。通过添加核心原始形式 make-symbol(符号类似于对,具有两个字段:一个字符串和一个值) 和 symbol-string,string->symbol 的实现简单地遍历符号链表,查找具有相同字符串的符号。如果不存在具有相同名称的符号,则构造一个新的符号。然后将此新符号添加到列表中,然后再返回。
一旦实现了 string->symbol,通过以下转换向我们的有效复杂常量集中添加符号就很简单了:
(labels ((f0 (code () () ’foo)))
(let ((f (closure f0)))
(eq? (funcall f) (funcall f))))
=>
(labels ((f0 (code () () (constant-ref t1)))
(t1 (datum)))
(constant-init t1
(funcall (primitive-ref string->symbol)
(string #\f #\o #\o)))
(let ((f (closure f0)))
(eq? (funcall f) (funcall f))))

3.15 外部函数
我们的 Scheme 实现不能孤立存在。为了执行输入/输出和许多其他有用的操作,它需要一种与主机操作系统进行交互的方式。现在我们添加了一种非常简单的调用外部 C 过程的方法。
我们在编译器中添加了一个额外的形式:
::= (foreign-call ...)
foreign-call 形式以字符串文字作为第一个参数。该字符串表示我们打算调用的 C 过程的名称。首先评估每个表达式,然后将它们的值作为参数传递给 C 过程。C 的调用约定与我们用于 Scheme 的调用约定不同,参数是放在返回点下面且顺序相反的。图 4 显示了这种差异。
为了适应 C 的调用约定,我们以相反的顺序评估 foreign-call 的参数,将值保存在堆栈上,调整 %esp 的值,发出对命名过程的调用,然后将堆栈指针调整回其初始位置。我们不必担心 C 过程会破坏分配和闭包指针的值,因为应用程序二进制接口 (ABI) 保证了被调用者会保留 %edi、%esi、%ebp 和 %esp 寄存器的值。
由于我们传递给外部过程的值是带标记的,我们将在运行时文件中编写包装器过程来负责在 Scheme 值和 C 值之间进行转换。
我们首先实现并测试调用 exit 过程。调用 (foreign-call “exit” 0) 应该会导致我们的程序退出而不执行任何输出。我们还实现了一个 write 的包装器,如下所示:
ptr s_write(ptr fd, ptr str, ptr len){
int bytes = write(unshift(fd),
string_data(str),
unshift(len));
return shift(bytes);
}
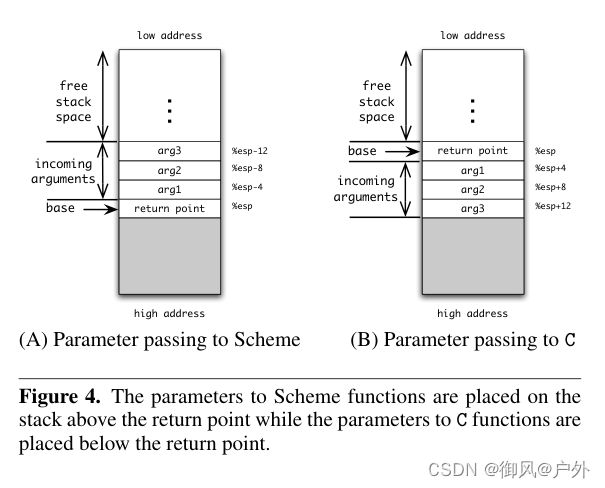
图 4. Scheme 函数的参数被放置在返回点之上的堆栈上,而 C 函数的参数被放置在返回点之下的堆栈上。


3.16 错误检查和安全原语
利用我们新获得的写和退出能力,我们可以定义一个简单的错误过程,它接受两个参数:一个符号(表示错误调用者),一个字符串(描述错误)。错误过程会将错误消息写入控制台,然后导致程序退出。
有了错误过程,我们可以保护实现的某些部分,以提供更好的调试功能。更好的调试功能可以让我们更快地实现系统的其余部分,因为我们不必去寻找段错误的原因。
导致致命错误的三个主要原因是:
- 尝试调用非过程对象。
- 向过程传递错误数量的参数。
- 使用无效参数调用原语。例如:执行 (car 5) 会立即导致段错误。更糟糕的是,使用超出范围的索引执行 vector-set! 会导致系统的其他部分被损坏,从而产生难以调试的错误。
调用非过程对象可以通过在进行过程调用之前进行过程检查来处理。如果操作数不是过程,则控制转移到一个错误处理程序标签,该标签设置一个调用报告错误并退出的过程。
向过程传递错误数量的参数可以通过调用方和被调方的协作来处理。一旦调用方执行过程检查,它就会将 %eax 寄存器的值设置为传递的参数数量。被调方检查 %eax 的值是否与它期望的参数数量一致。无效参数会导致跳转到一个标签,该标签调用一个报告错误并退出的过程。
对于原语调用,我们可以修改编译器,在每个原语调用处插入显式检查。例如,car 的翻译如下:
movl %eax, %ebx
andl $7, %ebx
cmpl $1, %ebx
jne L_car_error
movl -1(%eax), %eax
...
L_car_error:
movl car_err_proc, %edi # load handler
movl $0, %eax # set arg-count
jmp *-3(%edi) # call the handler
...
另一种方法是限制编译器只能使用不安全的原语。对安全原语的调用不会被编译器直接转换为机器码,而是发出对安全原语的过程调用。安全原语被定义为自行执行错误检查。虽然这种策略比直接转换安全原语更不高效,但实现起来更简单,更少出错。

3.17 可变参数过程
在我们迄今定义的架构中,接受可变数量参数的 Scheme 过程易于实现。假设一个过程被定义为接受两个或更多参数,就像以下示例中的那样:
(let ((f (lambda (a b . c) (vector a b c))))
(f 1 2 3 4))
对 f 的调用在栈位置 %esp-4、%esp-8、%esp-12 和 %esp-16 处传递了四个参数,另外 %eax 中包含了参数数量。进入 f 后,在执行参数检查后,f 进入一个循环,将参数从后向前构造成一个列表。
实现可变参数过程使我们能够定义许多接受任意数量参数的库过程,包括 +、-、*、=、<、...、char=?、char、string=?、string、list、vector、string 和 append 等。
其他类似 lambda 的变体,如 case-lambda,允许我们根据实际参数的数量来分派代码的不同部分,可以通过一系列比较和条件跳转轻松高效地实现。

3.18 应用
apply 的实现类似于可变参数过程的实现。接受可变数量参数的过程将传递给它们的额外参数转换为一个列表。另一方面,调用 apply 则会将一个参数列表插入到栈上。
当代码生成器遇到 apply 调用时,它生成的代码方式与普通过程调用相同。操作数被评估并保存在它们适当的栈位置中,如常规情况下一样。操作数被评估并检查。对于非尾调用,保存当前闭包指针并调整栈指针。对于尾调用,将操作数移动到覆盖当前帧。参数数量像往常一样放在 %eax 中。唯一的区别是,我们不是直接调用该过程,而是调用/jmp 到 L apply 标签,该标签在将最后一个参数插入到栈上后将控制转移给目标过程。
实现 apply 使得能够定义接受函数以及任意数量参数的库过程,如 map 和 for-each。


3.19 输出端口
使用编译器提供的功能在Scheme中实现输出端口涉及将输出端口表示为具有特定字段的向量。以下是字段的详细说明:
- 唯一标识符:此标识符有助于区分输出端口和普通向量。
- 文件名:一个表示与端口关联的文件名的字符串。
- 文件描述符:与打开文件关联的文件描述符。
- 输出缓冲区:用作输出缓冲区的字符串。
- 缓冲区索引:指向缓冲区中下一个位置的索引。
- 缓冲区大小:缓冲区的大小。
在初始化过程中,current-output-port 被设置,其文件描述符通常为Unix系统上的 1(表示标准输出)。缓冲区被选择为足够大,例如 4096 个字符,以最小化对操作系统的访问次数。
write-char 过程将字符写入缓冲区,增加索引,并在达到缓冲区大小时刷新缓冲区。刷新涉及使用先前介绍的 s_write 过程,然后重置索引。
此外,还实现了诸如 output-port?、open-output-file、close-output-port 和 flush-output-port 等过程,用于处理与输出端口相关的各种操作。
通过实现这些功能,您可以有效地在Scheme中使用编译器管理输出操作。

3.20 写操作和显示操作
一旦实现了 write-char,实现 write 和 display 过程就变得很简单,只需根据参数的类型进行分派即可。这两个过程在对待字符串和字符方面是相同的,因此可以基于一个通用过程来实现。为了写入固定数值,编译器必须添加原语 quotient。
在Scheme中实现 write 允许我们消除现在多余的写入器,该写入器是作为C运行时系统的一部分实现的。
3.21 输入端口
输入端口的表示与输出端口非常相似。唯一的区别在于,我们添加了一个额外的字段,用于支持“未读取”字符,这对 read-char 和 peek-char 这两个原语增加了非常小的开销,但极大地简化了标记器的实现(下一步)。在此阶段添加的原语包括 input-port?、open-input-file、read-char、unread-char、peek-char 和 eof-object?(通过添加类似于空列表的特殊文件结束对象)。
3.22 标记器
为了实现 read 过程,我们首先实现了 read-token。read-token 过程以输入端口作为参数,并使用 read-char、peek-char 和 unread-char,返回下一个标记。读取标记涉及编写一个模拟Scheme语法的确定有限状态自动机。read-token 的返回值是以下之一:
- 一个对
(datum . x),其中x是在扫描端口时遇到的固定数值、布尔值、字符、字符串或符号。 - 一个对
(macro . x),其中x表示Scheme的预定义读取宏之一:quote、quasiquote、unquote 或 unquote-splicing。 - 一个表示对应非数据标记的符号 left-paren、right-paren、vec-paren 或 dot。
- 如果
read-char在我们找到其他任何标记之前返回文件结束对象,则返回文件结束对象。
3.23 读取器
read 过程是建立在 read-token 上的递归下降解析器。由于语法的简单性(即唯一可能的输出是 eof-object、数据、列表和向量),整个实现,包括错误检查,不应超过40行直接Scheme代码。


3.24 解释器
我们已经准备好为核心Scheme实现一个环境传递的解释器所需的所有要素。此外,我们可以将编译器的第一遍提升,并将其作为解释器的第一遍。我们可能希望对解释器的语言添加一些限制(例如,禁止 primitive-set!),以防止用户代码干扰运行时系统。我们还可能希望添加不同的绑定模式,以确定对原语名称的引用是指实际的原语还是当前顶层绑定,以及是否允许对原语名称进行赋值。

4. 提升基本编译器的功能
可以沿着几个方面增强基本编译器。增强的两个主要方面是功能方面和性能方面。

4.1 增强功能
在第3节中介绍的实现具有许多Scheme的基本要求,包括正确的尾调用、可变参数过程和apply。它还具有执行foreign-call的功能,这使我们可以轻松利用主机操作系统及其库提供的功能。通过分离编译,我们可以实现一个扩展库,其中包括R5RS或各种SRFI所需的过程。
可以直接添加的缺失功能而不会对编译器的架构造成太大改变的包括:
- 可以添加完整的数字塔。扩展的数字原语可以直接在Scheme中编码,也可以由外部库(如GNU MP)提供。
- 使用我们基于堆栈的实现,多值很容易高效地实现,对不使用多值的过程调用的性能影响很小。
- 用户定义的宏和强大的模块系统可以通过编译和加载免费提供的可移植语法-case实现简单地添加。
- 我们的编译器不处理堆溢出。通过在分配尝试之前插入溢出检查,可以简单快速地比较分配指针的值和分配限制指针的值(在其他地方保存),然后跳转到溢出处理程序标签。可以首先实现一个简单的复制收集器,然后尝试更雄心勃勃的收集器,例如Chez Scheme或The Glasgow Haskell Compiler中使用的收集器。
- 同样,我们没有处理栈溢出。基于堆栈的实现可以通过将栈指针与堆栈末尾指针(在其他地方保存)进行比较,然后跳转到栈溢出处理程序来执行快速的栈溢出检查。处理程序可以分配一个新的堆栈段,并通过利用下溢处理程序将两个堆栈连接起来。实现栈溢出和下溢处理程序简化了实现高效的续延捕获和恢复。
- 或者,我们可以在执行闭包转换之前将输入程序转换为延续传递风格。这种转换消除了大部分堆栈溢出检查,并简化了call/cc的实现。不过,这样做的缺点是,会在运行时构建更多的闭包,导致变量过多复制和更频繁的垃圾回收。Shao等人展示了如何优化这些闭包的表示。


4.2 提升性能
在第3节中介绍的Scheme实现简单而直接。我们通过仅执行分配和闭包转换所需的基本分析步骤,避免了几乎所有优化。另一方面,我们选择了非常紧凑和高效的Scheme数据结构表示。这种表示选择使得错误检查更快,减少了内存需求和缓存耗尽。
尽管我们没有实现任何源级或后端优化,但这些优化步骤未来也可以添加。我们提到一些“简单”的步骤,可以添加到编译器中,并且很可能会产生很高的收益:
- 我们目前对letrec和letrec*的处理效率极低。按照[19]中描述的更好的letrec处理方式将允许我们:(1)减少堆分配的数量,因为大多数letrec绑定的变量不会是可分配的;(2)通过消除没有自由变量的闭包来减小许多闭包的大小;(3)识别对已知过程的调用,这允许我们对已知的汇编标签进行调用,而不是通过闭包中存储的代码指针间接进行所有调用;(4)在对静态已知过程的调用处消除过程检查;(5)识别递归调用,从而消除重新评估闭包值的需要;(6)在静态已知调用目标时跳过参数计数检查;以及(7)为接受可变数量参数的已知过程的已知调用组成其余参数。
- 我们的编译器为所有复杂操作数引入了临时堆栈位置。例如,(+ e 4) 可以通过先评估 e 并将结果加 16 来编译。相反,我们将其转换为 (let ((t0 e)) (+ t0 4)),这导致了对 e 的值进行不必要的保存和重新加载。直接评估很可能会产生更好的性能,除非进行了良好的寄存器分配。
- 我们对尾调用的处理可以通过识别可以在原地评估和存储参数的情况来大大改进。贪婪洗牌算法是一种简单的策略,可以消除我们目前为尾调用引入的大部分开销。
- 编译器中没有实现安全原语。对安全原语的开放编码减少了执行的过程调用数量。
- 简单的常量和不可变变量的复制传播以及常量折叠和强度减少将使我们能够编写更简单的代码,而不必担心效率低下。例如,使用我们当前的编译器,我们可能会因为这些名称会增加包含对它们的引用的任何闭包的大小而感到不鼓舞。
一旦完成了简单的优化,就可以针对更复杂的优化,例如寄存器分配、内联、消除运行时类型检查等。

5. 结论
编译器构建并不像通常认为的那样复杂。在本文中,我们展示了构建一个针对真实硬件的Scheme大部分子集的编译器是简单的。基本编译器通过集中精力处理编译的基本方面,并将编译器从复杂的分析和优化步骤中释放出来而实现的。这有助于初学者编译器编写者建立对编译器内部运作的直觉,而不被细节所分散。通过亲身经历实现基本编译器,实现者更能感受到编译器的不足之处,从而为增强编译器提供动力。一旦掌握了基本编译器,初学者实现者就更能胜任处理更有雄心的任务。

致谢
我要感谢Will Byrd、R. Kent Dybvig以及匿名审稿人的深刻评论。
支持材料
扩展教程和附带的测试套件可从作者的网站下载:
http://www.cs.indiana.edu/~aghuloum

参考
[1] AHO, A. V., SETHI, R., AND ULLMAN, J. D. 编译器:原理、技术和工具。1986年。
[2] APPEL, A. W. ML中的现代编译器实现。剑桥大学出版社,英国剑桥,1998年。
[3] ASHLEY, J. M.和DYBVIG, R. K. Scheme中多返回值的高效实现。在LISP和函数编程(1994年),pp. 140–149。
[4] BURGER, R. G.、WADDELL, O.和DYBVIG, R. K. 使用懒惰保存、急切恢复和贪婪洗牌的寄存器分配。在程序设计语言设计与实现(SIGPLAN)会议(1995年)中,pp. 130–138。
[5] CHAITIN, G. J. 寄存器分配和通过图着色。在SIGPLAN’82:1982年SIGPLAN编译器构造研讨会论文集(纽约,纽约,美国,1982年),ACM出版社,pp. 98–101。
[6] DYBVIG, R. K.、Eby, D.和BRUGGEMAN, C. 不要停止BIBOP:为动态类型语言提供灵活高效的存储管理。技术报告400,印第安纳大学,1994年。
[7] DYBVIG, R. K.、HIEB, R.和BRUGGEMAN, C. Scheme中的语法抽象。Lisp Symb. Comput. 5, 4(1992),295–326。
[8] DYBVIG, R. K.、HIEB, R.和BUTLER, T. 目的地驱动的代码生成。技术报告302,印第安纳大学计算机科学系,1990年2月。
[9] HIEB, R.、DYBVIG, R. K.和BRUGGERMAN, C. 在第一类延续存在的情况下表示控制。在ACM SIGPLAN’90编程语言设计与实现会议论文集(1990年6月,纽约州怀特普莱恩斯),卷25,pp. 66–77。
[10] JAGANNATHAN, S.和WRIGHT, A. K. 有效的流分析以避免运行时检查。在第2届国际静态分析研讨会(1995年9月)上,编号为LNCS 983。
[11] KELSEY, R.、CLINGER, W.和(编辑者), J. R. Scheme算法语言修订第5版报告。ACM SIGPLAN通知33, 9(1998),26–76。
[12] MARLOW, S.和JONES, S. P. 新的ghc/hugs运行时系统。
[13] MUCHNICK, S. S. 高级编译器设计与实现。Morgan Kaufmann Publishers,1997年。
[14] SCO。System V应用二进制接口,Intel386TM架构处理器补充第四版,1997年。
[15] SHAO, Z.和APPEL, A. W. 空间高效的闭包表示。在LISP和函数编程(1994年),pp. 150–161。
[16] TRAUB, O.、HOLLOWAY, G. H.和SMITH, M. D. 线性扫描寄存器分配中的质量和速度。在SIGPLAN编程语言设计与实现会议(1998年)中,pp. 142–151。
[17] WADDELL, O.和DYBVIG, R. K. 快速有效的过程内联。在第四届静态分析国际研讨会(SAS’97)(1997年9月),第1302卷Springer-Verlag计算机科学讲义,pp. 35–52。
[18] WADDELL, O.和DYBVIG, R. K. 扩展语法抽象范围。在POPL’99:第26届ACM SIGPLAN-SIGACT原理编程语言研讨会
论文集(1999年纽约,纽约州,美国),ACM出版社,pp. 203–215。
[19] WADDELL, O.、SARKAR, D.和DYBVIG, R. K. 修复letrec:Scheme的递归绑定构造的忠实且高效实现。Higher Order Symbol. Comput. 18, 3-4(2005),299–326。
[20] WIRTH, N. 编译器构造。Addison Wesley Longman Limited,埃塞克斯,英格兰,1996年。
[21] WRIGHT, A. K.和CARTWRIGHT, R. Scheme的实用软类型系统。交易程序语言和系统(1997年)。

