【干货】Python:wordcloud库绘制词云图
【干货】Python:wordcloud库绘制词云图
- 词云的优势
- wordcloud库与可视化词云
-
- 常用参数&方法
-
- WordCloud对象创建的常用参数
- WordCloud类的常用方法
- 字体的选择
- 背景图的选择
- 读取excel词频文件并转换为字典
- 自定义词云图“颜色”样式(参数)
-
- color_func 参数
- colormap 参数
- 生成及保存词云图
词云的优势
数据展示的方式多样。针对文本来说,更直观、带有一定艺术感的展示效果需求很大。
词云以词语为基本单元,根据其在文本中出现的频率设计不同大小以形成视觉上的不同效果,因此,若要将词频可视化,“词云图”是一个很好的选择。
wordcloud库是专门用于根据文本生成词云的Python第三方库,该库的详细介绍请访问:https://amueller.github.io/word_cloud/
wordcloud库与可视化词云
在生成词云时,wordcloud默认会以空格或标点为分隔符对目标文本进行分词处理。因此,对于
- 英文文本:无需分词,可直接调用wordcloud库函数
- 中文文本:分词处理需要由用户自主完成。一般步骤为:
分词处理 → 空格拼接 → 调用wordcloud库函数
from wordcloud import WordCloud
txt = 'I like python. I am learning python.'
wc = WordCloud()
wc.generate(txt)
wc.to_file('testcloud.png')
输出如下:

常用参数&方法
WordCloud对象创建的常用参数
wordcloud库的核心是WordCloud类,所有功能的封装都在WordCloud类中。使用时需要实例化一个WordCloud类的对象,并调用generate(text)方法将text文本转换为词云。WordCloud类在创建时有一系列可选参数,用于配置词云图片,具体如下。我们只需要关注常用的几个即可,其它可作为了解。
wordcloud.WordCloud(font_path=None, width=400, height=200, margin=2, ranks_only=None, prefer_horizontal=0.9, mask=None, scale=1, color_func=None, max_words=200, min_font_size=4, stopwords=None, random_state=None, background_color='black', max_font_size=None, font_step=1, mode='RGB', relative_scaling='auto', regexp=None, collocations=True, colormap=None, normalize_plurals=True, contour_width=0, contour_color='black', repeat=False, 'include_numbers=False', 'min_word_length=0', 'collocation_threshold=30')
以下检索表按照参数使用频率排列:
| 参数 | 作用 |
|---|---|
| font_path | 字体路径。字体存在C:\Windows\Fonts目录,在想要的字体上点右键,选择“属性”可查看其名称,然后连同路径复制,赋给font_path即可。比如本例使用的黑体。需要注意的是,若是中文词云,需要选中文字体。 |
| width, height | 画布的宽度和高度,单位为像素。若没设置mask值,才会使用此默认值400*200。 |
| mask | mask:nd-array or None (default=None), 用于设定绘制模板,需要是一个nd-array(多维数组),所以在用Image.open()读取图片后,需要用np.array转换成数组。当mask不为0时,那么之前依据height和width设置的画布则作废,此时“画布”形状大小由mask决定。默认None,即方形图。 |
| max_words | 词云图中最多显示词的字数,默认200。设定一个值,可让那些出现次数极少的词不显示出来。 |
| background_color | 词云图背景色,默认为黑色。可根据需要调整。 |
| mode | 当设置为"RGBA" 且background_color设置为"None"时可产生透明背景。 |
| max_font_size | 字号最大值,默认None。 |
| min_font_size | 字号最小值,默认为4号。 |
| scale | 比例尺,用于放大画布的尺寸。一般使用默认值。 |
| margin | 词间距(默认为2)。 |
| color_func | 颜色函数,后文会详细介绍。 |
| colormap | 每个词对应的颜色,若设置了color_func则忽略此参数。 |
| prefer_horizontal | 词语横排显示的概率(默认为90%,则竖排显示概率为10%) |
| stopwords | 被排除词列表,排除词不在词云中显示。 |
| random_state | 文档未说明。 |
| ranks_only | 文档未说明。 |
| font_step | 字体的步长,默认为1。大于1的时候可提升运算速度,但匹配较差。 |
| relative_scaling | 词频对字体大小的影响度,一般使用默认。 |
| regexp | 正则表达式分割输入的字符。一般是先处理好才给到wordcloud,所以基本不用。 |
| collocations | 是否包含两个词的搭配,若使用了generate_from_frequencies方法则忽略此参数。一般不用。 |
| normalize_plurals | 是否移除英文复数单词末尾的s ,比如可将word和words视同为一个词,并将词频算到word头上。如果使用了generate_from_frequencies方法则忽略此参数。 |
| contour_width | 如果mask有设置,且contour_width>0,将会绘制mask轮廓。 |
| contour_color | mask轮廓的颜色,默认为黑色。 |
| repeat | 当词不足以满足设定的max_words时,是否重复词或短语以使词云图上的词数量达到max_words |
| include_numbers | 是否将数字作为词。 |
| min_word_length | 设置一个词包含的最少字母数量。 |
| collocation_threshold | 界定英文中的bigrams,对于中文不适用。 |
WordCloud类的常用方法
| 方法 | 功能 |
|---|---|
| generate(text) | 由text文本生成词云 |
| to_file(filename) | 将词云图保存为名为filename的文件 |
字体的选择
处理中文时还需要指定中文字体,若未指定,生成的图片可能是这样的:

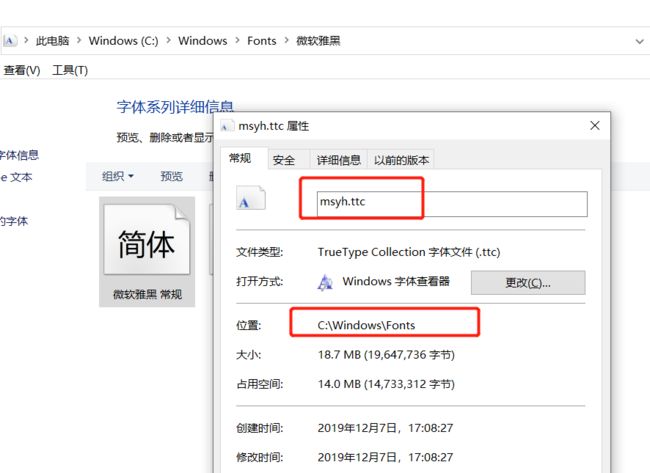
若选择微软雅黑字体(msyh.ttc)作为显示效果,需要
- 将该字体文件与代码存放在同一目录下,或
- 在字体文件名前增加完整路径
查看方法:Windows(C:) > Windows > Fonts,得到参数font_path的内容为 'C:/Windows/Fonts/msyh.ttc'
示例代码:
import jieba
from wordcloud import WordCloud
txt = '程序设计语言是计算机能够理解和识别用户操作意图的一种交互体系,它按照特定规则组织计算机指令,使计算机能够自动进行各种运算处理。'
words = jieba.lcut(txt) # 精确分词
# print(words)
newtxt = ' '.join(words) # 空格拼接
print(newtxt)
wc = WordCloud(font_path='msyh.ttc') # 定义字体
wc.generate(newtxt)
wc.to_file('ciyun.png')
输出词云:

背景图的选择
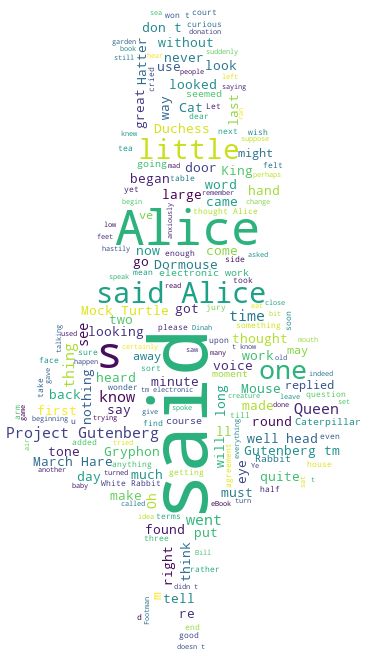
wordcloud可以生成任何形状的词云,为了获取形状,需要提供一张形状的图片。以下实例选取爱丽丝梦游仙境为主题进行展示:
背景图为爱丽丝的图像,文件命名为AliceMask.png

《爱丽丝梦游仙境》原文(下载链接),文件保存为AliceInWonderland.txt
from wordcloud import WordCloud
# from scipy.misc import imread # scipy中已经找不到该函数了,因为scipy版本>=1.3.0已经移除了
# import imageio # 使用该代码可能会出现一个小的warning,改成下面的格式就行
import imageio.v2 as imageio
img = imageio.imread('AliceMask.png')
f = open('AliceInWonderland.txt', 'r', encoding='utf-8')
txt = f.read()
wc = WordCloud(background_color='white',
width=800,
height=600,
max_words=200,
max_font_size=80,
mask=img)
wc.generate(txt)
wc.to_file('AliceInWonderland.png')
小warning的解决:import imageio警告处理
输出:
词云图是可以自定义背景图的,但不是随便拿一张图用都可以。np.array(Image.open(“图片名.jpg/png”)) 打开图片后转为数组,存入maskImage变量。需要注意词频背景图中想要的形状的背景需要是白色的,不然无法得到想要的词云图形状。比如如下背景图片,左边的图片因为猴子的背景不是白色,做出的词云图会占满整个图片,即是一个矩形的词云图;右边的图片中,猴子的背景是白色的,做出的词云图看起来就是一只猴子的形状。

读取excel词频文件并转换为字典
wb = load_workbook('入党申请书.xlsx') # 导入词频excel文件
ws = wb.active
wordFreq = {} # 词频读取成字典
for i in range(2,ws.max_row+1):
word = ws["A"+str(i)].value
freq = ws["B"+str(i)].value
wordFreq[word] = freq
自定义词云图“颜色”样式(参数)
一般的参数无需多讲,这里聊聊更改词云图颜色的两种方式
import numpy as np # numpy数据处理库
import wordcloud # 词云库
from wordcloud import ImageColorGenerator # 该库用于获得背景图的颜色值
from PIL import Image # 图像处理库,用于读取背景图片
from matplotlib import colors # 导入colors库,用于自定义色彩
import matplotlib.pyplot as plt # 图像展示库,以便在notebook中显示图片
from openpyxl import load_workbook # 读取词频Excel文件
color_func 参数
color_func配合ImageColorGenerator方法可以达到利用背景图自身颜色定义词云图颜色的效果,具体实现见如下代码:
maskImage = np.array(Image.open('background.jpg')) # 定义词频背景图
image_color = ImageColorGenerator(maskImage) # 获得背景图的颜色值
# 定义词云样式
wc = wordcloud.WordCloud(
font_path = 'C:/Windows/Fonts/simhei.ttf', # 设置字体
mask = maskImage, # 设置背景图
background_color = 'white',# 设置背景色为白色
color_func = image_color,# 设置字体颜色
max_words = 500, # 最多显示词数
max_font_size = 100,# 字号最大值
min_font_size = 5) # 字号最小值
绘制结果:

效果似乎有些不尽人意,由于背景图自身颜色的原因,导致有些词的颜色过浅,可以使用下文的方法进行改进。
colormap 参数
colormap参数可以根据自己的喜好设置词云图的颜色,只需要将的序号传递给计算机即可,详见:(常见的954种颜色及其序号: https://xkcd.com/color/rgb/)。为了符合党徽的 “气质” ,我自定义的color_list颜色数组中多为红橙黄等 “又红又专” 的色组。具体实现见如下代码:
#定义词云样式
maskImage = np.array(Image.open('background.jpg')) # 定义词频背景图
color_list = ['#fd411e','#fcb001','#ff000d','#fd3c06','#e50000']# 建立颜色数组
colormap = colors.ListedColormap(color_list)# 调用颜色数组
wc = wordcloud.WordCloud(
font_path = 'C:/Windows/Fonts/simhei.ttf', # 设置字体
mask = maskImage, # 设置背景图
background_color = 'white',# 设置背景色为白色
colormap = colormap, # 设置词云图颜色为颜色数组中的颜色
# color_func = image_color,# 设置字体颜色
max_words = 500, # 最多显示词数
max_font_size = 100,# 字号最大值
min_font_size = 5) # 字号最小值
绘制结果:

参考文章:
Matplotlib,colors系列颜色指定:https://blog.csdn.net/m0_37235489/article/details/79761450:
生成及保存词云图
# 生成词云图
wc.generate_from_frequencies(wordFreq) # 从字典生成词云
wc.to_file("入党申请书词云图.png") # 保存词云图
# 在notebook中显示词云图
plt.rcParams['font.sans-serif'] = ['SimHei']# 解决中文显示问题
plt.rcParams['axes.unicode_minus'] = False
plt.title("入党申请书词云图") # 图片显示的名字
plt.imshow(wc) # 显示词云
plt.axis('off') # 关闭坐标轴
plt.show() # 显示图像
感谢你的访问!欢迎交流!