监测HDD smart信息的脚本编写
最近需要完成一个测试HDD的项目,因为接的HDD太多,手动查看smart信息太麻烦,所以需要写一个自动帮我们检查smart信息的脚本。此遍文章只介绍直连或者JBOD模式下的信息监测,没有涉及到组RAID模式。
1 首先看下HDD的smart信息,确定要检查哪些信息,以及判断标准
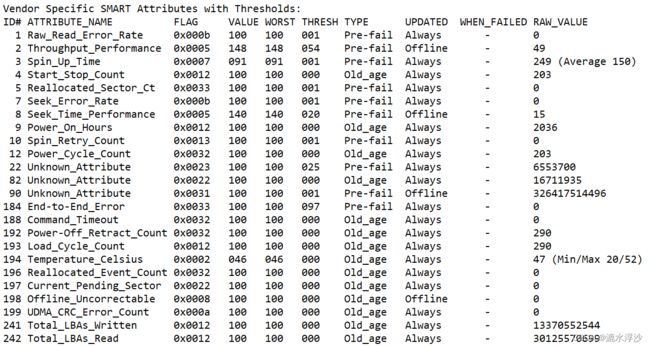
如上图所示,先看一下第一行代表的含义
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
ID
属性ID,通常是一个1到255之间的十进制或十六进制的数字。硬盘SMART检测的ID代码以两位十六进制数表示(括号里对应的是十进制数)硬盘的各项检测参数。目前,各硬盘制造商的绝大部分SMART ID代码所代表的参数含义是一致的,但厂商也可以根据需要使用不同的ID代码,或者根据检测项目的多少增减ID代码
ATTRIBUTE_NAME
硬盘制造商定义的属性名。,即某一检测项目的名称,是ID代码的文字解释。
FLAG
属性操作标志
VALUE
value是各ID项在硬盘运行时根据实测原始数据(Raw value)通过公式计算的结果,1到253之间。253意味着最好情况,1意味着最坏情况。计算公式由硬盘厂家自定。
硬盘出厂时各ID项目都有一个预设的最大正常值,也即出厂值,这个预设的依据及计算方法为硬盘厂家保密,不同型号的硬盘都不同,最大正常值通常为100或200或253,新硬盘刚开始使用时显示的当前值可以认为是预设的最大正常值(有些ID项如温度等除外)。随着使用损耗或出现错误,当前值会根据实测数据而不断刷新并逐渐减小。因此,当前值接近临界值就意味着硬盘寿命的减少,发生故障的可能性增大,所以当前值也是判定硬盘健康状态或推测寿命的依据之一。
WORST
最差值
硬盘运行时各ID项曾出现过的最小的value。
最差值是对硬盘运行中某项数据变劣的峰值统计,该数值也会不断刷新。通常,最差值与当前值是相等的,如果最差值出现较大的波动(小于当前值),表明硬盘曾出现错误或曾经历过恶劣的工作环境(如温度)。
THRESH
临界值
在报告硬盘FAILED状态前,WORST可以允许的最小值。
临界值是硬盘厂商指定的表示某一项目可靠性的门限值,也称阈值,它通过特定公式计算而得。如果某个参数的当前值接近了临界值,就意味着硬盘将变得不可靠,可能导致数据丢失或者硬盘故障。由于临界值是硬盘厂商根据自己产品特性而确定的,因此用厂商提供的专用检测软件往往会跟Windows下检测软件的检测结果有较大出入。
硬盘的每项SMART信息中都有一个临界值(阈值),不同硬盘的临界值是不同的,SMART针对各项的当前值、最差值和临界值的比较结果以及数据值进行分析后,提供硬盘当前的评估状态,也是我们直观判断硬盘健康状态的重要信息。根据SMART的规定,状态一般有正常、警告、故障或错误三种状态。
SMART判定这三个状态与SMART的 Pre-failure/advisory BIT(预测错误/发现位)参数的赋值密切相关,当Pre-failure/advisory BIT=0,并且当前值、最差值远大于临界值的情况下,为正常标志。当Pre-failure/advisory BIT=0,并且当前值、最差值大于但接近临界值时,为警告标志;当Pre-failure/advisory BIT=1,并且当前值、最差值小于临界值时,为故障或错误标志
TYPE
属性的类型(Pre-fail或Oldage)。Pre-fail类型的属性可被看成一个关键属性,表示参与磁盘的整体SMART健康评估(PASSED/FAILED)。如果任何Pre-fail类型的属性故障,那么可视为磁盘将要发生故障。另一方面,Oldage类型的属性可被看成一个非关键的属性(如正常的磁盘磨损),表示不会使磁盘本身发生故障。
UPDATED
表示属性的更新频率。Offline代表磁盘上执行离线测试的时间。
WHEN_FAILED
如果VALUE小于等于THRESH,会被设置成“FAILING_NOW”;如果WORST小于等于THRESH会被设置成“In_the_past”;如果都不是,会被设置成“-”。在“FAILING_NOW”情况下,需要尽快备份重要 文件,特别是属性是Pre-fail类型时。“In_the_past”代表属性已经故障了,但在运行测试的时候没问题。“-”代表这个属性从没故障过
RAW_VALUE
制造商定义的原始值,从VALUE派生。
数据值是硬盘运行时各项参数的实测值,大部分SMART工具以十进制显示数据。
数据值代表的意义随参数而定,大致可以分为三类:
1)数据值并不直接反映硬盘状态,必须经过硬盘内置的计算公式换算成当前值才能得出结果;
2)数据值是直接累计的,如Start/Stop Count(启动/停止计数)的数据是50,即表示该硬盘从出厂到现在累计启停了50次;
3)有些参数的数据是即时数,如Temperature(温度)的数据值是34,表示硬盘的当前温度是34℃。
因此,有些参数直接查看数据也能大致了解硬盘目前的工作状态。
再看以下那些信息需要检查:
1 Raw_Read_Error_Rate : 底层数据读取错误率
3 Spin_Up_Time :主轴起旋时间
5 Reallocated_Sector_Ct :重映射扇区数
7 Seek_Error_Rate :寻道错误率
10 Spin_Retry_Count :主轴起旋重试次数
194 Temperature_Celsius :当前温度
198 Offline_Uncorrectable :脱机无法校正的扇区计数
199 UDMA_CRC_Error_Count :Ultra ATA访问校验错误率
Raw_Read_Error_Rate
数据为0或任意值,当前值应远大于与临界值。
底层数据读取错误率是磁头从磁盘表面读取数据时出现的错误,对某些硬盘来说,大于0的数据表明磁盘表面或者读写磁头发生问题,如介质损伤、磁头污染、磁头共振等等。不过对希捷硬盘来说,许多硬盘的这一项会有很大的数据量,这不代表有任何问题,主要是看当前值下降的程度。
在固态硬盘中,此项的数据值包含了可校正的错误与不可校正的RAISE错误(UECC+URAISE)。
Spin_Up_Time
主轴起旋时间就是主轴电机从启动至达到额定转速所用的时间,数据值直接显示时间,单位为毫秒或者秒,因此数据值越小越好。不过对于正常硬盘来说,这一项仅仅是一个参考值,硬盘每次的启动时间都不相同,某次启动的稍慢些也不表示就有问题。
硬盘的主轴电机从启动至达到额定转速大致需要4秒~15秒左右,过长的启动时间说明电机驱动电路或者轴承机构有问题。旦这一参数的数据值在某些型号的硬盘上总是为0,这就要看当前值和最差值来判断了。
对于固态硬盘来说,所有的数据都是保存在半导体集成电路中,没有主轴电机,所以这项没有意义,数据固定为0,当前值固定为100。
Reallocated_Sector_Ct
数据应为0,当前值应远大于临界值。
当硬盘的某扇区持续出现读/写/校验错误时,硬盘固件程序会将这个扇区的物理地址加入缺陷表(G-list),将该地址重新定向到预先保留的备用扇区并将其中的数据一并转移,这就称为重映射。执行重映射操作后的硬盘在Windows常规检测中是无法发现不良扇区的,因其地址已被指向备用扇区,这等于屏蔽了不良扇区。
这项参数的数据值直接表示已经被重映射扇区的数量,当前值则随着数据值的增加而持续下降。当发现此项的数据值不为零时,要密切注意其发展趋势,若能长期保持稳定,则硬盘还可以正常运行;若数据值不断上升,说明不良扇区不断增加,硬盘已处于不稳定状态,应当考虑更换了。如果当前值接近或已到达临界值(此时的数据值并不一定很大,因为不同硬盘保留的备用扇区数并不相同),表示缺陷表已满或备用扇区已用尽,已经失去了重映射功能,再出现不良扇区就会显现出来并直接导致数据丢失。
这一项不仅是硬盘的寿命关键参数,而且重映射扇区的数量也直接影响硬盘的性能,例如某些硬盘会出现数据量很大,但当前值下降不明显的情况,这种硬盘尽管还可正常运行,但也不宜继续使用。因为备用扇区都是位于磁盘尾部(靠近盘片轴心处),大量的使用备用扇区会使寻道时间增加,硬盘性能明显下降。
这个参数在机械硬盘上是非常敏感的,而对于固态硬盘来说同样具有重要意义。闪存的寿命是正态分布的,例如说MLC能写入一万次以上,实际上说的是写入一万次之前不会发生“批量损坏”,但某些单元可能写入几十次就损坏了。换言之,机械硬盘的盘片不会因读写而损坏,出现不良扇区大多与工艺质量相关,而闪存的读写次数则是有限的,因而损坏是正常的。所以固态硬盘在制造时也保留了一定的空间,当某个存储单元出现问题后即把损坏的部分隔离,用好的部分来顶替。这一替换方法和机械硬盘的扇区重映射是一个道理,只不过机械硬盘正常时极少有重映射操作,而对于固态硬盘是经常性的。
Seek_Error_Rate
数据应为0,当前值应远大于与临界值。
这一项表示磁头寻道时的错误率,有众多因素可导致寻道错误率上升,如磁头组件的机械系统、伺服电路有局部问题,盘片表面介质不良,硬盘温度过高等等。
通常此项的数据应为0,但对希捷硬盘来说,即使是新硬盘,这一项也可能有很大的数据量,这不代表有任何问题,还是要看当前值是否下降。
Spin_Retry_Count
数据应为0,当前值应大于临界值。
主轴起旋重试次数的数据值就是主轴电机尝试重新启动的计数,即主轴电机启动后在规定的时间里未能成功达到额定转速而尝试再次启动的次数。数据量的增加表示电机驱动电路或是机械子系统出现问题,整机供电不足也会导致这一问题。
Temperature
温度的数据值直接表示了硬盘内部的当前温度。硬盘运行时最好不要超过45℃,温度过高虽不会导致数据丢失,但引起的机械变形会导致寻道与读写错误率上升,降低硬盘性能。硬盘的最高允许运行温度可查看硬盘厂商给出的数据,一般不会超过60℃。
不同厂家对温度参数的当前值、最差值和临界值有不同的表示方法:希捷公司某些硬盘的当前值就是实际温度(摄氏)值,最差值则是曾经达到过的最高温度,临界值不具意义;而西部数据公司一些硬盘的最差值是温度上升到某值后的时间函数,每次升温后的持续时间都将导致最差值逐渐下降,当前值则与当前温度成反比,即当前温度越高,当前值越低,随实际温度波动
Offline_Uncorrectable
数据应为0,当前值应远大于临界值。
这个参数的数据累计了读写扇区时发生的无法校正的错误总数。数据值上升表明盘片表面介质或机械子系统出现问题,有些扇区肯定已经不能读取,如果有文件正在使用这些扇区,操作系统会返回读盘错误的信息。下一次写操作时会对该扇区执行重映射。
UDMA_CRC_Error_Count
这个参数的数据值累计了通过接口循环冗余校验(Interface Cyclic Redundancy Check,ICRC)发现的数据线传输错误的次数。如果数据值不为0且持续增长,表示硬盘控制器→数据线→硬盘接口出现错误,劣质的数据线、接口接触不良都可能导致此现象。由于这一项的数据值不会复零,所以某些新硬盘也会出现一定的数据量,只要更换数据线后数据值不再继续增长,即表示问题已得到解决
除此之外,还要检查一下HDD的health状态 确认为 “PASSED”
SMART overall-health self-assessment test result: PASSED
好了,通过上面的介绍,我们总结一下 需要判断的几个信息(暂时不考率HDD的speed)
1 是否有掉盘
2 盘符是否变化
3 smart log 中 1 3 5 7 10 的值(VALUE值大于THRESH的值为pass)
4 smart log 中 194 Temperature_Celsius 的值(温度低于60°为pass)
5 198 199中的RAW_VALUE的值(等于0为pass)
6 health的值(显示"PASSED"为pass)
判断条件清楚以后 就是如何编译shell脚本,下面介绍下脚本的写法
2 编译脚本
其实检查smart log就是测试前后分别收集一下smart的log,然后做下对比。然后根据上面的介绍再判断信息中的值是pass或者failed。
第一步 获取OS盘,可以参考我之前的文章
#echo "check os disk"
bootdisk=`df -h |grep -i boot| awk '{print $1}' | grep -iE "/dev/sd" | sed 's/[0-9]//g' |sort -u|awk -F "/" '{print $NF}'`
if test -z "$bootdisk"
then
bootdisk=`df -h |grep -i boot| awk '{print $1}' | grep -iE "/dev/nvme" | sed 's/p[0-9]//g' |sort -u|awk -F "/" '{print $NF}'`
echo "os disk os $bootdisk"
else
echo "os disk is $bootdisk"
fi
第二步,脚本第一次运行 生成smart_before ;第二次运行 生成 smart_afetr
if [ -d "smart_before" ];
then
echo " create after_smart;and check hdd";
else
echo " create before_smart;and collect hdd";
fi
第三步,在收集log的时候,顺便也可以判断一下pass或者failed
这一部分稍微麻烦点,详细的介绍下
(1). 用lsscsi获取盘符
for hdd in `lsscsi |grep -i sd |grep -vw $bootdisk|awk -F "/" '{print $NF}'`;
do
echo $hdd
done
(2) 只对HDD进行检查
因为lsscsi的命令是把所有的scsi接口的盘都筛选出来,这样就包括HDD,SATA的SSD和U盘,这样的话我们旧的筛选一下HDD
我是用smart的信息检查rpm关键字来判断HDD的
for hdd in `lsscsi |grep -i sd |grep -vw $bootdisk|awk -F "/" '{print $NF}'`;
do
sn=`smartctl -a /dev/$hdd |grep "Serial Number:" |awk '{print $NF}'`
rpm=`smartctl -i /dev/$hdd | grep "Rotation Rate:"|awk '{print $NF}'`
if [ "$rpm" != "rpm" ]
then
echo " $sn is ssd"
else
smartctl -a /dev/$hdd > ${1}_${hdd}_${sn}.log
fi
done
(3) 收集log的时候 可以用AWK语言直接判断此项检查是否pass
比如判断health的状态 如果是"PASSED"则返回pass 不是返回failed
smartctl -a /dev/sdb |grep -i health |awk ‘{if ($NF == “PASSED”) print “pass”;else print “failed”}’
判断Raw_Read_Error_Rate的信息 如果VALUE值大于THRESH的值为pass,不是返回failed
smartctl -a /dev/sdb |grep “Raw_Read_Error_Rate” |awk ‘{if($4 > $6) print “pass”;else print “failed”}’
for hdd in `lsscsi |grep -i sd |grep -vw $bootdisk|awk -F "/" '{print $NF}'`;
do
sn=`smartctl -a /dev/$hdd |grep "Serial Number:" |awk '{print $NF}'`
rpm=`smartctl -i /dev/$hdd | grep "Rotation Rate:"|awk '{print $NF}'`
if [ "$rpm" != "rpm" ]
then
echo " $sn is ssd"
else
smartctl -a /dev/$hdd > ${1}_${hdd}_${sn}.log
mv ${1}_${hdd}_${sn}.log smart_$1
health=`cat smart_${1}/${1}_${hdd}*.log |grep -i health |awk '{if ($NF == "PASSED") print "pass";else print "failed"}'`
read_error=`cat smart_${1}/${1}_${hdd}*.log |grep "Raw_Read_Error_Rate" |awk '{if($4 > $6) print "pass";else print "failed"}'`
spin=`cat smart_${1}/${1}_${hdd}*.log |grep "Spin_Up_Time" |awk '{if($4 > $6) print "pass";else print "failed"}'`
reall=`cat smart_${1}/${1}_${hdd}*.log |grep "Reallocated_Sector_Ct" |awk '{if($4 > $6) print "pass";else print "failed"}'`
seek=`cat smart_${1}/${1}_${hdd}*.log |grep "Seek_Error_Rate" |awk '{if($4 > $6) print "pass";else print "failed"}'`
spin_Retry_Count=`cat smart_${1}/${1}_${hdd}*.log |grep "Spin_Retry_Count" |awk '{if($4 > $6) print "pass";else print "failed"}'`
tem=`cat smart_${1}/${1}_${hdd}*.log |grep "Temperature_Celsius" |awk '{if($(NF-2) <= 60) print "pass";else print "failed"}'`
offline=`cat smart_${1}/${1}_${hdd}*.log |grep "Offline_Uncorrectable" |awk '{if($NF == 0) print "pass";else print "failed"}'`
udma=`cat smart_${1}/${1}_${hdd}*.log |grep "UDMA_CRC_Error_Count" |awk '{if($NF == 0) print "pass";else print "failed"}'`
echo "$sn $hdd $read_error $spin $reall $seek $spin_Retry_Count $tem $offline $udma $health">>before.log
fi
done
以SN为为索引将所有的HDD的信息保存在一个文件里

(4) 最后一步我们要把检查的具体信息生成一个result结果。对比前后的smart log的时候,是以SN为索引的,SN在 说明盘在,检索不到说明此盘lost
for sn in `cat before.log|sed 1d |awk '{print $1}'`;
do
slot_before=`cat before.log |awk '$1=="'$sn'" {print $2}'`
icrc_before=`cat before.log |awk '$1=="'$sn'" {print $NF}'`
sn_after=`cat after.log |awk '$1=="'$sn'" {print $1}'`
if [ "$sn_after" == "$sn" ];
then
echo "**********$sn is exiting ,not lost,check pass***************" >>result.log
slot_after=`cat after.log |awk '$1=="'$sn'" {print $2}'`
if [ "$slot_after" == $slot_before ]
then
echo " $sn slot check pass.slot is $slot_after" >>result.log
else
echo " $sn slot check failed. slot is $slot_after" >>result.log
fi
# echo "check 1 3 5 7 10 194 198 199 health"
Raw_Read_Error_Rate=`cat after.log |awk '$1=="'$sn'" {print $3}'`
echo " $sn check Raw_Read_Error_Rate is $Raw_Read_Error_Rate">>result.log
Spin_Up_Time=`cat after.log |awk '$1=="'$sn'" {print $4}'`
echo " $sn check Spin_Up_Time is $Spin_Up_Time">>result.log
Reallocated_Sector_Ct=`cat after.log |awk '$1=="'$sn'" {print $5}'`
echo " $sn check Reallocated_Sector_Ct is $Reallocated_Sector_Ct">>result.log
Seek_Error_Rate=`cat after.log |awk '$1=="'$sn'" {print $6}'`
echo " $sn check Seek_Error_Rate is $Seek_Error_Rate">>result.log
Spin_Retry_Count=`cat after.log |awk '$1=="'$sn'" {print $7}'`
echo " $sn check Spin_Retry_Count is $Spin_Retry_Count">>result.log
Temperature_Celsius=`cat after.log |awk '$1=="'$sn'" {print $8}'`
echo " $sn check Temperature_Celsius is $Temperature_Celsius">>result.log
Offline_Uncorrectable=`cat after.log |awk '$1=="'$sn'" {print $9}'`
echo " $sn check Offline_Uncorrectable is $Offline_Uncorrectable">>result.log
UDMA_CRC_Error_Count=`cat after.log |awk '$1=="'$sn'" {print $10}'`
echo " $sn check UDMA_CRC_Error_Count is $UDMA_CRC_Error_Count">>result.log
health=`cat after.log |awk '$1=="'$sn'" {print $11}'`
echo " $sn check health is $health">>result.log
else
echo " $sn is lost,check failed" >>result.log
fi
done
(5) 完善一下脚本
#!/bin/bash
#echo "check os disk"
bootdisk=`df -h |grep -i boot| awk '{print $1}' | grep -iE "/dev/sd" | sed 's/[0-9]//g' |sort -u|awk -F "/" '{print $NF}'`
if test -z "$bootdisk"
then
bootdisk=`df -h |grep -i boot| awk '{print $1}' | grep -iE "/dev/nvme" | sed 's/p[0-9]//g' |sort -u|awk -F "/" '{print $NF}'`
echo "os disk os $bootdisk"
else
echo "os disk is $bootdisk"
fi
function before_after_log(){
mkdir smart_$1
echo "SN SLOT 1 3 5 7 10 194 198 199 health ">${1}.log
for hdd in `lsscsi |grep -i sd |grep -vw $bootdisk|awk -F "/" '{print $NF}'`;
do
sn=`smartctl -a /dev/$hdd |grep "Serial Number:" |awk '{print $NF}'`
rpm=`smartctl -i /dev/$hdd | grep "Rotation Rate:"|awk '{print $NF}'`
if [ "$rpm" != "rpm" ]
then
echo " $sn is ssd"
else
smartctl -a /dev/$hdd > ${1}_${hdd}_${sn}.log
mv ${1}_${hdd}_${sn}.log smart_$1
health=`cat smart_${1}/${1}_${hdd}*.log |grep -i health |awk '{if ($NF == "PASSED") print "pass";else print "failed"}'`
read_error=`cat smart_${1}/${1}_${hdd}*.log |grep "Raw_Read_Error_Rate" |awk '{if($4 > $6) print "pass";else print "failed"}'`
spin=`cat smart_${1}/${1}_${hdd}*.log |grep "Spin_Up_Time" |awk '{if($4 > $6) print "pass";else print "failed"}'`
reall=`cat smart_${1}/${1}_${hdd}*.log |grep "Reallocated_Sector_Ct" |awk '{if($4 > $6) print "pass";else print "failed"}'`
seek=`cat smart_${1}/${1}_${hdd}*.log |grep "Seek_Error_Rate" |awk '{if($4 > $6) print "pass";else print "failed"}'`
spin_Retry_Count=`cat smart_${1}/${1}_${hdd}*.log |grep "Spin_Retry_Count" |awk '{if($4 > $6) print "pass";else print "failed"}'`
tem=`cat smart_${1}/${1}_${hdd}*.log |grep "Temperature_Celsius" |awk '{if($(NF-2) <= 60) print "pass";else print "failed"}'`
offline=`cat smart_${1}/${1}_${hdd}*.log |grep "Offline_Uncorrectable" |awk '{if($NF == 0) print "pass";else print "failed"}'`
udma=`cat smart_${1}/${1}_${hdd}*.log |grep "UDMA_CRC_Error_Count" |awk '{if($NF == 0) print "pass";else print "failed"}'`
echo "$sn $hdd $read_error $spin $reall $seek $spin_Retry_Count $tem $offline $udma $health">>${1}.log
fi
done
}
if [ -d "smart_before" ];
then
echo " create after_smart;and check hdd";
before_after_log after
for sn in `cat before.log|sed 1d |awk '{print $1}'`;
do
slot_before=`cat before.log |awk '$1=="'$sn'" {print $2}'`
icrc_before=`cat before.log |awk '$1=="'$sn'" {print $NF}'`
sn_after=`cat after.log |awk '$1=="'$sn'" {print $1}'`
if [ "$sn_after" == "$sn" ];
then
echo "**********$sn is exiting ,not lost,check pass***************" >>result.log
slot_after=`cat after.log |awk '$1=="'$sn'" {print $2}'`
if [ "$slot_after" == $slot_before ]
then
echo " $sn slot check pass.slot is $slot_after" >>result.log
else
echo " $sn slot check failed. slot is $slot_after" >>result.log
fi
# echo "check 1 3 5 7 10 194 198 199 health"
Raw_Read_Error_Rate=`cat after.log |awk '$1=="'$sn'" {print $3}'`
echo " $sn check Raw_Read_Error_Rate is $Raw_Read_Error_Rate">>result.log
Spin_Up_Time=`cat after.log |awk '$1=="'$sn'" {print $4}'`
echo " $sn check Spin_Up_Time is $Spin_Up_Time">>result.log
Reallocated_Sector_Ct=`cat after.log |awk '$1=="'$sn'" {print $5}'`
echo " $sn check Reallocated_Sector_Ct is $Reallocated_Sector_Ct">>result.log
Seek_Error_Rate=`cat after.log |awk '$1=="'$sn'" {print $6}'`
echo " $sn check Seek_Error_Rate is $Seek_Error_Rate">>result.log
Spin_Retry_Count=`cat after.log |awk '$1=="'$sn'" {print $7}'`
echo " $sn check Spin_Retry_Count is $Spin_Retry_Count">>result.log
Temperature_Celsius=`cat after.log |awk '$1=="'$sn'" {print $8}'`
echo " $sn check Temperature_Celsius is $Temperature_Celsius">>result.log
Offline_Uncorrectable=`cat after.log |awk '$1=="'$sn'" {print $9}'`
echo " $sn check Offline_Uncorrectable is $Offline_Uncorrectable">>result.log
UDMA_CRC_Error_Count=`cat after.log |awk '$1=="'$sn'" {print $10}'`
echo " $sn check UDMA_CRC_Error_Count is $UDMA_CRC_Error_Count">>result.log
health=`cat after.log |awk '$1=="'$sn'" {print $11}'`
echo " $sn check health is $health">>result.log
else
echo " $sn is lost,check failed" >>result.log
fi
done
cat result.log |grep -i failed >failed.log
mkdir result
mv *.log result
else
echo " create before_smart;and collect hdd";
before_after_log before
fi
6 脚本运行两次之后 就会出result结果:
