掌握RDD算子2
文章目录
-
-
- 扁平映射算子案例
-
- 任务1、统计不规则二维列表元素个数
-
- 方法一、利用Scala来实现
- 方法二、利用Spark RDD来实现
- 按键归约算子案例
-
- 任务1、在Spark Shell里计算学生总分
- 任务2、在IDEA里计算学生总分
-
- 第一种方式:读取二元组成绩列表
- 第二种方式:读取四元组成绩列表
- 第三种情况:读取HDFS上的成绩文件
-
扁平映射算子案例
任务1、统计不规则二维列表元素个数
方法一、利用Scala来实现
- 在net.xxr.rdd.day01包里创建Example02单例对象
package net.xxr.rdd.day01
import org.apache.spark.{SparkConf, SparkContext}
/**
* 功能:利用Scala统计不规则二维列表元素个数
*/
object Example02 {
def main(args: Array[String]): Unit = {
// 创建不规则二维列表
val mat = List(
List(7, 8, 1, 5),
List(10, 4, 9),
List(7, 2, 8, 1, 4),
List(21, 4, 7, -4)
)
// 输出二维列表
println(mat)
// 将二维列表扁平化为一维列表
val arr = mat.flatten
// 输出一维列表
println(arr)
// 输出元素个数
println("元素个数:" + arr.size)
}
}

方法二、利用Spark RDD来实现
- 在net.xxr.rdd.day01包里创建Example03单例对象
package net.xxr.rdd.day01
import org.apache.spark.{SparkConf, SparkContext}
/**
* 功能:利用RDD统计不规则二维列表元素个数
*/
object Example03 {
def main(args: Array[String]): Unit = {
// 创建Spark配置对象
val conf = new SparkConf()
.setAppName("PrintDiamond") // 设置应用名称
.setMaster("local[*]") // 设置主节点位置(本地调试)
// 基于Spark配置对象创建Spark容器
val sc = new SparkContext(conf)
// 创建不规则二维列表
val mat = List(
List(7, 8, 1, 5),
List(10, 4, 9),
List(7, 2, 8, 1, 4),
List(21, 4, 7, -4)
)
// 基于二维列表创建rdd1
val rdd1 = sc.makeRDD(mat)
// 输出rdd1
rdd1.collect.foreach(x => print(x + " "))
println()
// 进行扁平化映射
val rdd2 = rdd1.flatMap(x => x.toString.substring(5, x.toString.length - 1).split(", "))
// 输出rdd2
rdd2.collect.foreach(x => print(x + " "))
println()
// 输出元素个数
println("元素个数:" + rdd2.count)
}
}

- 扁平化映射可以简化


按键归约算子案例
任务1、在Spark Shell里计算学生总分
- 创建成绩列表scores,基于成绩列表创建rdd1,对rdd1按键归约得到rdd2,然后查看rdd2内容
val scores = List((“张钦林”, 78), (“张钦林”, 90), (“张钦林”, 76),
(“陈燕文”, 95), (“陈燕文”, 88), (“陈燕文”, 98),
(“卢志刚”, 78), (“卢志刚”, 80), (“卢志刚”, 60))
val rdd1 = sc.makeRDD(scores)
val rdd2 = rdd1.reduceByKey((agg, cur) => agg + cur)
rdd2.collect.foreach(println)

- 可以采用神奇的占位符

任务2、在IDEA里计算学生总分
第一种方式:读取二元组成绩列表
- 在net.xxr.rdd.day02包里创建CalculateScoreSum01单例对象
package net.xxr.rdd.day02
import org.apache.spark.{SparkConf, SparkContext}
/**
* 功能:计算总分
*/
object CalculateScoreSum01 {
def main(args: Array[String]): Unit = {
// 创建Spark配置对象
val conf = new SparkConf()
.setAppName("PrintDiamond") // 设置应用名称
.setMaster("local[*]") // 设置主节点位置(本地调试)
// 基于Spark配置对象创建Spark容器
val sc = new SparkContext(conf)
val scores = List(
("张钦林", 78), ("张钦林", 90), ("张钦林", 76),
("陈燕文", 95), ("陈燕文", 88), ("陈燕文", 98),
("卢志刚", 78), ("卢志刚", 80), ("卢志刚", 60))
// 基于二元组成绩列表创建RDD
val rdd1 = sc.makeRDD(scores)
// 对成绩RDD进行按键归约处理
val rdd2 = rdd1.reduceByKey(_ + _)
// 输出归约处理结果
rdd2.collect.foreach(println)
}
}

第二种方式:读取四元组成绩列表
- 在net.xxr.rdd.day02包里创建CalculateScoreSum02单例对象
package net.xxr.rdd.day02
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable.ListBuffer
/**
* 功能:计算总分
*/
object CalculateScoreSum02 {
def main(args: Array[String]): Unit = {
// 创建Spark配置对象
val conf = new SparkConf()
.setAppName("PrintDiamond") // 设置应用名称
.setMaster("local[*]") // 设置主节点位置(本地调试)
// 基于Spark配置对象创建Spark容器
val sc = new SparkContext(conf)
// 创建四元组成绩列表
val scores = List(
("张钦林", 78, 90, 76),
("陈燕文", 95, 88, 98),
("卢志刚", 78, 80, 60)
)
// 将四元组成绩列表转化成二元组成绩列表
val newScores = new ListBuffer[(String, Int)]()
// 通过遍历算子遍历四元组成绩列表
scores.foreach(score => {
newScores.append(Tuple2(score._1, score._2))
newScores.append(Tuple2(score._1, score._3))
newScores.append(Tuple2(score._1, score._4))}
)
// 基于二元组成绩列表创建RDD
val rdd1 = sc.makeRDD(newScores)
// 对成绩RDD进行按键归约处理
val rdd2 = rdd1.reduceByKey(_ + _)
// 输出归约处理结果
rdd2.collect.foreach(println)
}
}

第三种情况:读取HDFS上的成绩文件
- 将成绩文件上传到HDFS的/input目录
hdfs dfs -mkdir /input
hdfs dfs -put scores.txt /input
hdfs dfs -cat /input/scores.txt
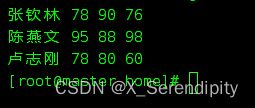
- 在net.xxr.rdd.day02包里创建CalculateScoreSum03单例对象
package net.xxr.rdd.day02
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable.ListBuffer
/**
* 功能:计算总分
*/
object CalculateScoreSum03 {
def main(args: Array[String]): Unit = {
// 创建Spark配置对象
val conf = new SparkConf()
.setAppName("CalculateScoreSum")
.setMaster("local[*]")
// 基于配置创建Spark上下文
val sc = new SparkContext(conf)
// 读取成绩文件,生成RDD
val lines = sc.textFile("hdfs://master:9000/input/scores.txt")
// 定义二元组成绩列表
val scores = new ListBuffer[(String, Int)]()
// 遍历lines,填充二元组成绩列表
lines.collect.foreach(line => {
val fields = line.split(" ")
scores += Tuple2(fields(0), fields(1).toInt)
scores += Tuple2(fields(0), fields(2).toInt)
scores += Tuple2(fields(0), fields(3).toInt)
})
// 基于二元组成绩列表创建RDD
val rdd1 = sc.makeRDD(scores)
// 对成绩RDD进行按键归约处理
val rdd2 = rdd1.reduceByKey((x, y) => x + y)
// 输出归约处理结果
rdd2.collect.foreach(println)
}
}

- 在Spark Shell里完成同样的任务
import scala.collection.mutable.ListBuffer
val lines = sc.textFile("hdfs://master:9000/input/scores.txt")
val scores = new ListBuffer[(String, Int)]()
lines.collect.foreach(line => {
val fields = line.split(" ")
scores.append(Tuple2(fields(0), fields(1).toInt))
scores.append(Tuple2(fields(0), fields(2).toInt))
scores.append(Tuple2(fields(0), fields(3).toInt))
})
val rdd1 = sc.makeRDD(scores)
val rdd2 = rdd1.reduceByKey(_ + _)
rdd2.collect.foreach(println)

- 修改程序,将计算结果写入HDFS文件

