汽车电子AUTOSAR之Event
上文AUTOSAR基础篇之DTC中提到event是故障监控的基本单元,本文将从event的使能条件(Enable Condition)、上报方式、去抖动策略(Debouncing Strategy)、优先级(Priority)、Displacement、依赖关系图(Dependency Node)以及event Storage Condition等七个常见属性进行展开跟大家聊聊:
1.Event 使能条件
作为事件监控的基本单元,Event能否开启监控绝大部分情况下都需要满足一定条件,只有这样,才能够保证Event监控是否存在意义。
若不加以相关的限制条件,那么会导致增加诸多的信息干扰导致最终无法快速排查Root Cause,说的简单点,就是起到了Event过滤器的作用。通过该Event过滤器,可以得到你所允许上报或者抑制的Event上报。
比如典型实例就是当总线Busoff发生时,同时会发生很多报文丢失的故障,但是这些timeout故障只是sequential events,是顺理成章的事。
但我们不希望报出这些sequential events,就会为这些Event添加相应的Busoff的使能条件。即只有当总线没有发生Busoff时,才允许记录这些Timeout的events, 才显得更有意义!
比如上电经过特定时间之后才允许开启电压监控,因为ECU刚上电电压不稳定是一个正常过程,应当予以过滤掉,故而为电压监控的event添加上电初始化时间的使能条件。
即在上电特定时间内禁止电压相关事件监控,其余事件可以正常开启监控;
再比如有些event需要获取KL15状态信息或者其他的一些综合条件,才能够进行event上报,因此使能条件可以自由根据客户的需求进行添加,当然如果涉及到event之间的依赖关系,也可以利用Dependency Node来起到Event过滤器的作用,后面会继续讲到。
event的使能条件就相当于event过滤器,可以实现event在某种特定条件下event才被允许上报,为了更为清楚的了解到event上报的全部流程,如下图1所示:

图1 event上报处理流程图
在上图中可以看出,一个Event从上报到最终被存储需要经历种种千辛万苦的考验,才能最终落地生根,修成正果被你所看到。
- S1:首先,需判断是否开启了Operation Cycle,如果是,则继续下面Enable Condition的判断,否则就直接结束;
- S2:若Enable Condition Fulfilled,则进行85诊断服务的判断,若不满足,则直接结束;
- S3:若此时使能了85服务,则直接结束,若没有,则可以继续往下进行Debouncing;
- S4:经过Debouncing之后,若Event发生变化,则也会反映到DTC Status的变化,若没有变化或者没有结果,便可以直接结束;
- S5:到此并没有结束,Event能否正确存储至NVM中,取决于是否满足Storage Condition, 同时,在满足存储条件之后,若event entry已满,能否最终存储还取决于event优先级以及event之间的依赖关系等。
2.Event 上报方式
当Event满足上述的使能条件之后,其触发的方式主要分为两种:循环上报型与Event触发型,两者的区别显而易见,前者Event一旦触发,就会循环不断地上报event状态,后者则是Event状态发生变化的时候,才会触发一次,并不会一直上报。
有小伙伴就问了,为啥要做这两种区别呢,故障一旦触发,一直上报不就行了吗?问的在理,这是因为从软件架构设计的层面考虑到,event上报来源于各个SW-C模块,经过RTE传输至故障处理模块,但是模块上报的Event数目非常多。
如果都采用Polling上报的方式,那么无疑会增加RTE传输数据的负担,而且对于故障处理模块而言,其实只需知道你的最新状态即可,所以在这种情况下,采用Event触发型无疑是更明智的选择,即仅当Event状态发生变化时才会触发一次上报。
如下图2所示,体现了两种不同上报方式的优缺点以及应用场合。
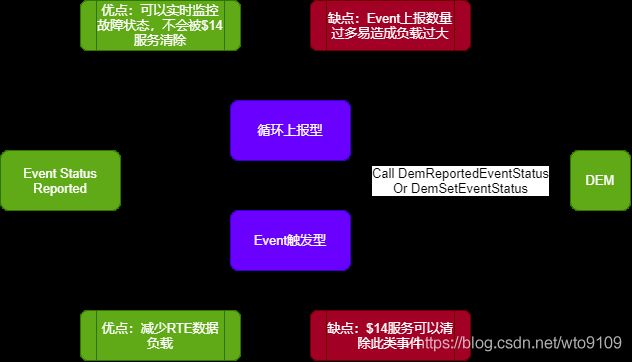
图2 Event触发方式的对比
从上图2可以看出,无论是采用循环上报还是Event触发方式上报,本质上都是调用相同的DEM API函数接口来实现Event进一步的处理,因此,在event上报选择方式上面,应当结合图中优缺点综合考虑,切不可一刀切,应当建立在软件架构的基础上去实现客户的需求,才能保证选择方式的合理性。
3.Event去抖动策略
当Event上报之后交由故障处理模块处理,在处理的过程中有一个非常重要的环节:去抖动策略,该策略就是为了防止所有故障误报应运而生 ,只有经历了去抖动算法之后,Event的最终状态才能够被确定,也就是PASS、FAIL, No Result这三类。
一般而言,去抖动策略也分为两种:TimeBase与Counterbase,TimeBase是通过计时来完成对Event的去抖动的过程,而CounterBase则是通过计数来完成对Event的去抖动,比如timeout类故障,可以直接采用TimeBase的策略来完成去抖动。
比如Event触发型可以采用Counterbase来完成去抖动。下面结合AUTOSAR Diagnostic Event Manager标准文档来针对这两类去抖动算法进行讲解:
3.1 TimeBase Debouncing
如下图3所示,将图划分为3个区域,区域1为Event上报状态区域,区域2为Event TimeBase的去抖动过程,区域3为Event去抖动之后的评估结果。
在区域1中,纵坐标表示Event上报的状态类型,有FAILED、PREFAILED、PREPASSED、PASSED四种基本状态,该状态通过DEM提供的函数接口来体现,具体细节可以参考之前的文章AUTOSAR-DEM模块几点思考!在这里不做过多赘述。
在该区域中,每上报一次不同的event状态,区域2中的FDC(Fault Detection Counter)都会发生相应的变化;在区域2中,当区域1上报一次PREFAILED时,FDC会基于tFailed的时间阈值换算为线性关系上升至阈值(127),若没有event 状态更新的上报,将保持至阈值不变;
当区域1上报一次与上次Event状态不同的状态如PREPASSED时, FDC无论如何首先会回归至0,然后基于tPassed的时间换算成对应的线性关系下降至阈值(-128);
如果在下降或者上升的过程中发生状态的变化,如下图从PREPASSED变为PREFAILED,那么在下降的某个时刻会首先回归至0,然后再继续以一定斜率上升至阈值(127);
如果上报的Event状态直接就是PASS或者FAIL,那么FDC会直接到达至相应阈值-128(Passed)或者127(Failed)。
在区域3中,纵坐标是event经过去抖动算法之后的最终评估结果,亦称为故障成熟结果,分为PASS,FAIL两种结果。
当FDC == 127(Failed)时,Event Status == FAIL;
当FDC == -128(Passed)时,Event Status == PASS;
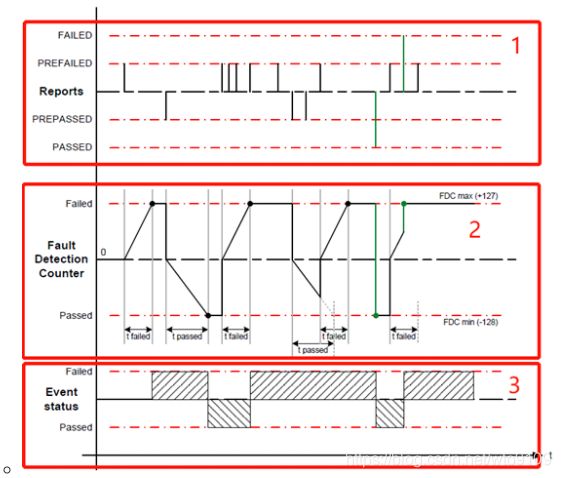
图3 TimeBase 去抖动算法
通过上述场景的分析可以得出:对于TimeBased的去抖动算法,主要适用于在满足连续时间内故障便可以成熟的event,如timeout类事件或者其他跟时间密切相关的Event。
当然,一般而言,如果能够用timebased的时间也可以转化为Counterbase的算法来实现,因为两者本质就是基于时间来实现去抖动算法。
3.2 CounterBase Debouncing
如下图4所示,相比上图3,除了区域2有所区别以外,区域1与3含义与上图一致。在讲解下图之前,需要解释几个专有名词如下所示:
Internal Debouncing Counter(IDC): 表示用户自定义的debouncing counter,该IDC与FDC会在软件内部转化为一种线性比例关系;
DemDebounceCounterFailedThreshold: 表示事件Fail时的IDC阈值(event active);
DemDebounceCounterPassedThreshold: 表示事件Pass时的IDC阈值(event passive);
DemDebounceCounterIncrementStepSize: 表示事件每上报一次Prefail时IDC上升的步距;
DemDebounceCounterDecrementStepSize: 表示事件每上报一次PrePass时IDC下降的步距;
DemDebounceCounterJumpDownValue: 表示如果Jump-Down行为使能,在当前的IDC大于此值时,IDC就会首先跳转到该值处,然后才进行接下来的Debouncing行为;
DemDebounceCounterJumpUpValue:表示如果Jump-Up行为使能,当前的IDC小于此值时,FDC就会首先跳转到该值处,然后才进行接下来的Debouncing行为;
如图中所示,每当Event以PreFailed上报一次,IDC就会上升一次步距,该步距长度为DemDebounceCounterIncrementStepSize,直至到达DemDebounceCounterFailedThreshold,Event判定结果为FAIL;
同理,每当Event以PrePassed上报一次,IDC就会下降一个步距,该步距长度为DemDebounceCounterDecrementStepSize,直至到达DemDebounceCounterPassedThreshold,Event判定结果为PASS;
若Event直接以Failed或者Passed上报,那么IDC就会直接到相应的Pass或者Fail阈值;
如没有新的Event 状态上报,那么就会IDC就会保持当前的IDC值不变;
如果使能了Jump-Down或者Jump-Up行为,那么就会根据上述DemDebounceCounterJumpDownValue或者DemDebounceCounterJumpUpValue的解释跳转到相应的位置,然后进行Debouncing行为;
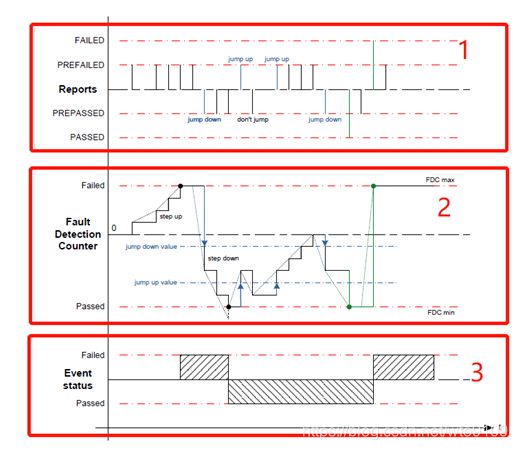
图4 CounterBased 去抖动算法
该CounterBased的算法主要适用于Event上报型的故障,基于次数来决定Event是否成熟,因此,无论使用上述哪种Debouncing算法,只要合理并正确使用,将能够大大减少故障的误触发,提高整个系统的稳定性与鲁棒性!