【ARM CPU 之 Cortex-M7 介绍】
文章目录
-
- 1.1 Cortex-M7 Introduction
-
- 1.1.1 M7 Feature
- 1.1.2 M7 Components
- 1.1.3 Cortex-M7 IN
- 1.3 TCM(Tightly Coupled Memory)
- 1.4 MPU
-
- 1.4.1 Memory Type
- 1.4.2 MPU Region Attribute
- 1.4.3 System Address Map
- 1.4.4 Speculative accesses
- 1.4.5 System Control Space
- 1.5 System Exception
-
- 1.5.1 NVIC (Nested Vectored Interrupt Controller)
- 1.5.2 Interrupt Latency
- 1.5.3 Interrupt Priority
- 1.5.4 Modes of operation and excetion
- 1.5.5 Interrupt Update
- 1.5.6 stack introduction
- 1.5.7 stack on an exception
- 1.5.8 Schedule in ISR
- 1.6.1 VTOR Register
1.1 Cortex-M7 Introduction
Cortex-M7是基于ARMv7架构,ARMv7 架构主要分为以下三类:

其中 Cortex-M 系列应用最广泛,Cortex-M 处理器出货量超过其他所有ARM处理器加起来的总和
Cortex-M系列主要包含以下:
32-bit
年份 核心
2004年 Cortex-M3
2007年 Cortex-M1
2009年 Cortex-M0
2010年 Cortex-M4
2012年 Cortex-M0+
2014年 Cortex-M7
2016年 Cortex-M23
2016年 Cortex-M33
2018年 Cortex-M35P
2020年 Cortex-M55
1.1.1 M7 Feature
Cortex-M7具备六级、顺序、双发射超标量流水线,拥有单精度、双精度浮点单元、指令和数据缓存、分支预测、SIMD支持、紧耦合内存(TCM)。
ARM Cortex-M7 内核的 六级指令流水线 实现如下:每一条指令都会由相同的取指(fetch) 和译码 (decode) 前两级流水线单元处理,在流水线的第三级为指令派发(issue),
识别其指令类型:
- 存储器访问(load/store pipeline)
- 算术逻辑运算(ALU pipeline)
- 乘累加运算(MAC pipeline)
- 浮点数运算(FPU pipeline)
从而进入相应的后级指令流水线进行处理,实现不同指令的并行执行。
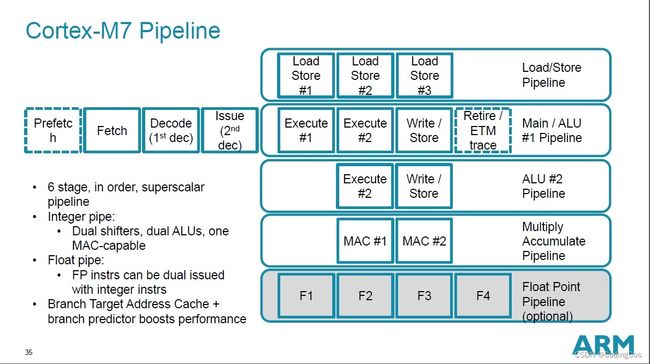
从上图可以看到 Cortex-M7 内核实现了两个移位器和 ALU,拥有两个 ALU pipeline,从而保证常用的整数处理指令也能够并行
处理,从而大大提升了CPU内核的计算性能。
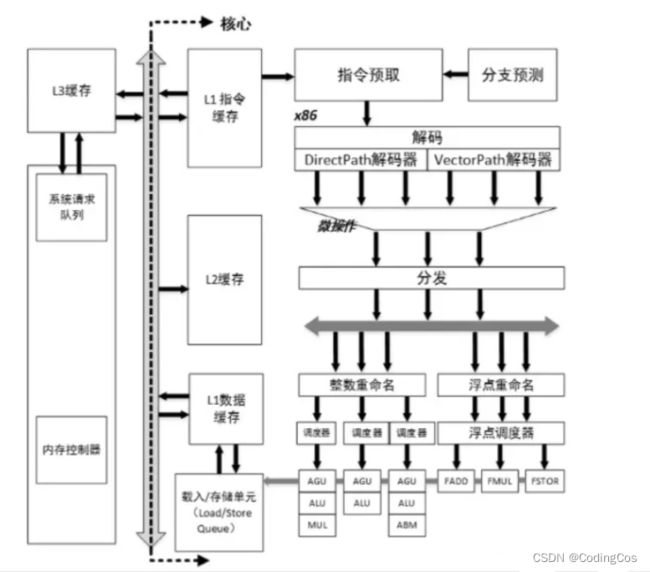
五级流水线架构:
取指,译码,转发,执行,写回 + 超标量 + 乱序执行
指令首先通过主存或 L2 Cache加载到 L1指令cache中,L1 指令 Cache 会在指令预取阶段进行指令预取和分支预测,然后通过指令队列发送给译码器进行多路译码,然后指令会通过转发到 ALU+AGU 中进行乱序执行,最后汇总到LSQ(load store queue)中进行内存一致性管理,确定访问时序,最后 LSU 会去访问 L1 数据 cache。
1.1.2 M7 Components
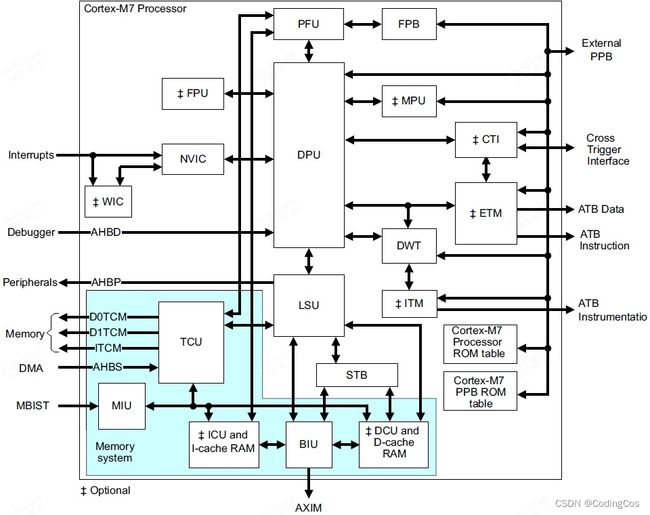
CPU 对 TCM 的访问不通过cache
1.1.3 Cortex-M7 IN
TODO
1.3 TCM(Tightly Coupled Memory)
TCM 分为两种,分别是 ITCM(Instruction TCM)和 DTCM(Data TCM)。这两块内存区域一般被当做特殊的用途。
比如某些对时间要求非常严格的代码,就可以被放到ITCM中执行。这可以有效地提高运行速度。某些需要频繁存
取的数据,也可以放到DTCM中以节省存取时间。TCM与Cache处于平行结构,即在二者均工作的时候,若CPU所
需的数据或指令在Cache中,则通常不会在TCM中。当前RTOS运行在ITCM,DTCM用作栈功能。
1.4 MPU
当前 MPU 一共支持 16 个 regions(0-15), 优先级依次升高,也即 region15 配置的优先级最高,可以覆盖前面 region 的配置属性。
每个region的最小size 为32bytes,最大支持 4G 范围配置。
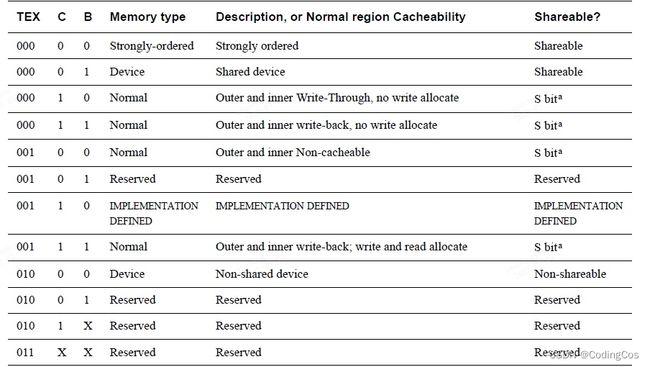
1.4.1 Memory Type
Device memory type:
该memory类型是由连带效应(side-effectts)的,即对一个地址的数据的操作可能会影响到另一个地址中的数据值。
Device空间要求比较苛刻点,Device空间的数据是不允许被cache缓存,否则会导致系统功能紊乱。
Normal memory type:
该memory类型是不具有连带效应的,即地址之间的操作互不干扰,Normal空间的数据可以被cache缓存。
参考:https://blog.csdn.net/W1Z1Q/article/details/104358385
1.4.2 MPU Region Attribute
1.4.3 System Address Map

Internal PPB 主要用来访问 ITM/DWT/PFB/MPU/NVIC
External PPB 主要用来访问 ETM/CTI
1.4.4 Speculative accesses

1.4.5 System Control Space

1.5 System Exception
Cortex-M7 处理器一共有 255个 异常,异常编号为1-255;其中1-15属于内核异常,大于15属于外设中断;在程序开发中,使用-14~-1表示内核中断(异常)请求编号,
大于 -1 表示外设中断请求编号;异常分为非活跃且非挂起状态,挂起状态,活跃状态,活跃且挂起状态。
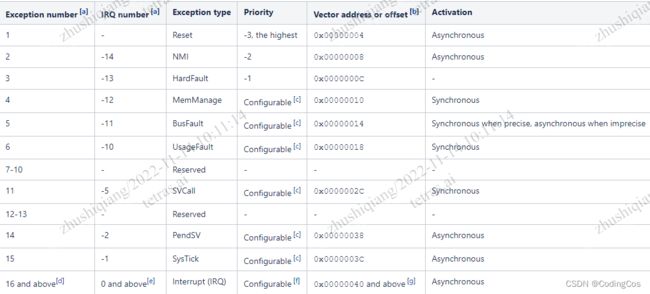
所有能打断正常执行流的事件都称为异常。
异常的概念包含中断的概念,即中断是异常的子集。
异常与中断都是硬件支持的
1.5.1 NVIC (Nested Vectored Interrupt Controller)
中断控制器是CPU众多外设中的一个,它一方面接收其它外设中断信号的输入,另一方面,它会发出中断信号给CPU。可以通过对中断控制器编程实现对中断源
的优先级、触发方式、打开和关闭源等设置操作。在Cortex-M系列控制器中常用的中断控制器是NVIC(内嵌向量中断控制器Nested Vectored Interrupt Controller)。
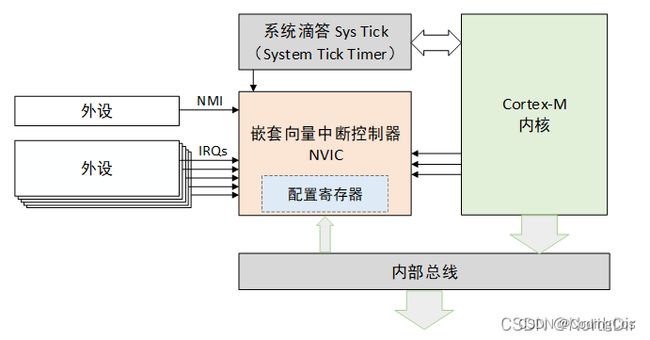
ARMv7-M NVIC架构支持496个中断,所支持的外部中断线可以通过只读寄存器 ICTR(0xE000E004)来获取,
1 个不可屏蔽中断(NMI)、1 个 Systick(滴答定时器)定时器中断和多个系统异常。
NIVC 及支持电平触发又支持脉冲触发,但是脉冲触发方式需要保证脉宽足够大。可以通过Write-only寄存器STIR来触发中断。
NIVC 及支持电平触发又支持脉冲触发,但是脉冲触发方式需要保证脉宽足够大。可以通过Write-only寄存器STIR来触发中断。
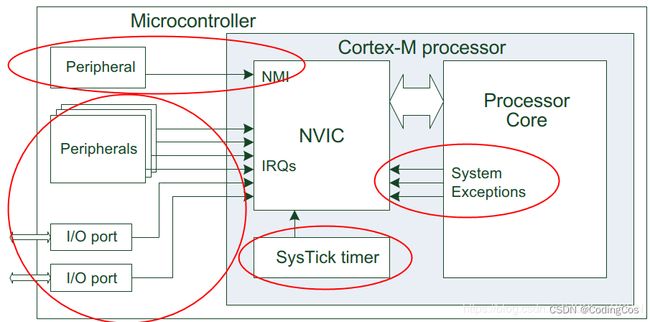
NVIC 是属于Cortex 内核的器件,不可屏蔽中断 (NMI)和外部中断都由它来处理,而SYSTICK 不是由 NVIC 来控制的。
Systick 有自己的中断控制寄存器,不是通过NVIC来是能的:

前 16 号的异常由SCB,不通过NVIC来处理:

1.5.2 Interrupt Latency
中断延迟是指从硬件中断发生到开始执行中断处理程序第一条指令之间的这段时间。也就是:系统接收到中断信号到操作系统作出响应,并完成换到转入中断服务程序的时间。
也可以简单地理解为:(外部)硬件(设备)发生中断,到系统执行中断服务子程序(ISR)的第一条指令的时间。
中断的处理过程是:外界硬件发生了中断后,CPU到中断处理器读取中断向量,并且查找中断向量表,找到对应的中断服务子程序(ISR)的首地址,然后跳转到对应的ISR去做相应处理。这部分时间,我称之为:识别中断时间。
在允许中断嵌套的实时操作系统中,中断也是基于优先级的,允许高优先级中断抢断正在处理的低优先级中断,所以,如果当前正在处理更高优先级的中断,即使此时有低优
先级的中断,也系统不会立刻响应,而是等到高优先级的中断处理完之后,才会响应。而即使在不支持中断嵌套,即中断是没有优先级的,中断是不允许被中断的,所以,如果当前系统正在处理一个中断,而此时另一个中断到来了,系统也是不会立即响应的,而只是等处理完当前的中断之后,才会处理后来的中断。此部分时间,我称其为:等待中断打开时间。
在操作系统中,很多时候我们会主动进入临界段,系统不允许当前状态被中断打断,故而在临界区发生的中断会被挂起,直到退出临界段时候打开中断。此部分时间,我称其为:关闭中断时间。
中断延迟可以定义为,从中断开始的时刻到中断服务例程开始执行的时刻之间的时间段。
中断延迟 = 识别中断时间 + [等待中断打开时间] + [关闭中断时间]。
https://blog.csdn.net/BLBQ962464/article/details/123964567
1.5.3 Interrupt Priority
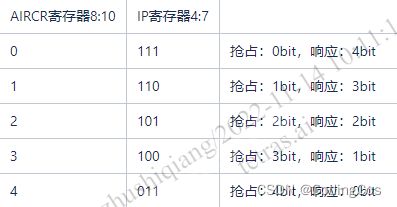
Cortex-M7 每个异常有一个8位寄存器表示其优先级,即支持 0~255 优先级,目前内部只是实现其高 4 位,即支持0~15优先级;通过配置优先级分组后,高优先级可以抢占低优先级异常;
中断优先级分两级 "抢占优先级“ 和 “响应优先级“”。规则如下:
高优先级的抢占优先级是可以打断正在进行的低抢占优先级中断。
抢占优先级相同的中断,高响应优先级不可以打断低响应优先级的中断。
抢占优先级相同的中断,当两个中断同时发生的情况下,哪个响应优先级高,哪个先执行。
如果两个中断的抢占优先级和响应优先级都是一样的,则看哪个中断先发生就先执行。
通过配置AIRC(0xE000ED0C)与IP寄存器可以配置抢占优先级和响应优先级:
1.5.4 Modes of operation and excetion

1.5.5 Interrupt Update
- 入栈:当处理器处理一个异常时,会把当前的信息放到栈上,这个操作叫做入栈,由8个字组成的数据结构叫做栈帧。使用浮点例程时,Cortex-M7 处理器在入栈时将自动把该架构的浮点状态入栈,下图展示了Cortex-M7 处理器发生中断或者异常时的堆栈帧布局。
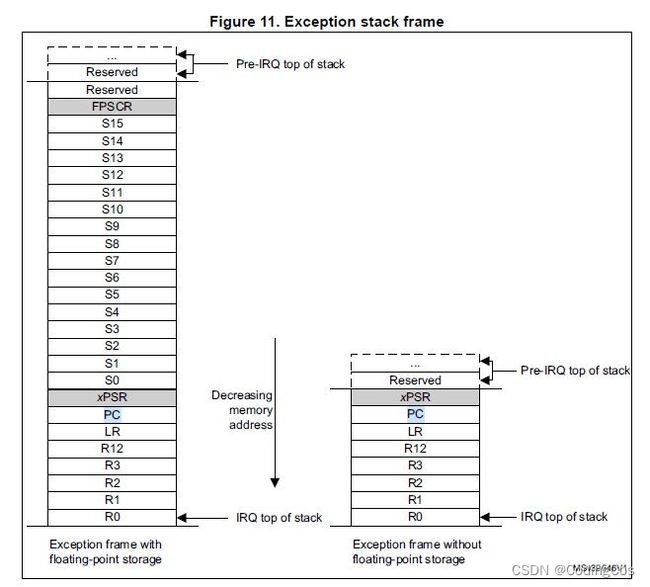
2)SP(R13): 在入栈后会把堆栈指针(PSP或 MSP)更新到新的位置, 在执行服务例程时, 将由 MSP负责对堆栈的访问。
3)PSR: 更新 IPSR位段(地处PSR的最低部分)的值为新响应的异常编号。
4)PC: 在取向量完成后, PC将指向服务例程的入口地址。
5)LR: 在出入 ISR的时候,LR的值将得到重新的诠释,这种特殊的值称为 “EXC_RETURN”,在异常进入时由系统计算并赋给 LR,并在异常返回时使用它。
EXC_RETURN 的二进制值除了最低 4位外全为 1,而其最低4位则有另外的含义:
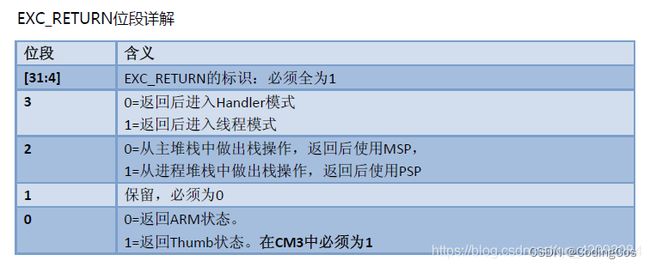
以上是在响应异常时核心寄存器的变化。另一方面,在 NVIC中也会更新若干个相关有寄存器。
例如,新响应异常的悬起位将被清除,同时其活动位将被置位。
1.5.6 stack introduction
堆栈是一种数据结构,按先进后出(First In Last Out,FILO)的方式工作,使用一个称作堆栈指针的专用寄存器指示当前的操作位置,堆栈指针总是指向栈顶。
当堆栈指针指向最后压入堆栈的数据时,称为满堆栈(Full Stack),而当堆栈指针指向下一个将要放入数据的空位置时,称为空堆栈(Empty Stack)。
同时,根据堆栈的生成方式,又可以分为递增堆栈(Ascending Stack)和递减堆栈(DecendingStack)。
当堆栈由低地址向高地址生成时,称为递增堆栈,
当堆栈由高地址向低地址生成时,称为递减堆栈。
这样就有四种类型的堆栈工作方式:
- Full descending 满递减堆栈:堆栈首部是高地址,堆栈向低地址增长。栈指针总是指向堆栈最后一个元素(最后一个元素是最后压入的数据)
- Full ascending 满递增堆栈:堆栈首部是低地址,堆栈向高地址增长。栈指针总是指向堆栈最后一个元素(最后一个元素是最后压入的数据)
- Empty descending 空递减堆栈:堆栈首部是低地址,堆栈向高地址增长。栈指针总是指向下一个将要放入数据的空位置。
- Empty ascending 空递增堆栈:堆栈首部是高地址,堆栈向低地址增长。栈指针总是指向下一个将要放入数据的空位置。
ARMv7-M 使用的是满栈递减工作方式。
1.5.7 stack on an exception
一般的CPU进入中断后都会去进行压栈操作,因为栈就是函数的现场,保护了栈内容,中断退出的时候只需要恢复栈数据就可以恢复到程序执行的状态了。以往这个阶段都是通过人工操作写程序完成的,在Cortex-M上,将部分栈由硬件自动压入。其压入栈的顺序一般如下:
xPSR->PC(返回地址)->LR->R12->R3->R2->R1->R0
这些寄存器硬件自动压入,效率上应该有较大的提升。
另外的一些寄存器可以手动处理,可以参考libcpu/arm/cortex-m7/context_gcc.S 中的 HardFault_Handler 手动入栈 r4-r11 及 exex_return。
.global HardFault_Handler
.type HardFault_Handler, %function
HardFault_Handler:
/* get current context */
MRS r0, msp /* get fault context from handler. */
TST lr, #0x04 /* if(!EXC_RETURN[2]) */
BEQ _get_sp_done
MRS r0, psp /* get fault context from thread. */
_get_sp_done:
STMFD r0!, {r4 - r11} /* push r4 - r11 register */
#if defined (__VFP_FP__) && !defined(__SOFTFP__)
STMFD r0!, {lr} /* push dummy for flag */
#endif
STMFD r0!, {lr} /* push exec_return register */
TST lr, #0x04 /* if(!EXC_RETURN[2]) */
BEQ _update_msp
MSR psp, r0 /* update stack pointer to PSP. */
B _update_done
_update_msp:
MSR msp, r0 /* update stack pointer to MSP. */
_update_done:
PUSH {LR}
BL rt_hw_hard_fault_exception
POP {LR}
ORR lr, lr, #0x04
BX lr
我们用arm gcc编译出cortex-m的elf固件,通过objdump随便看一个函数体的执行。对于一个arm函数的汇编代码,基本上都是下面的执行逻辑:
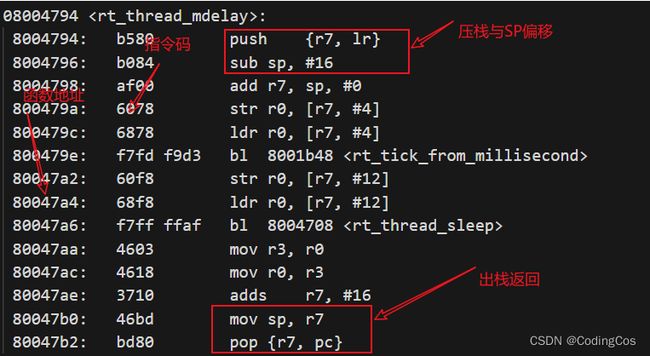
1.5.8 Schedule in ISR
在用户中断服务程序(ISR)中,分为两种情况:
- 第一种情况是:不进行线程切换,这种情况下用户中断服务程序和中断后续程序运行完毕后退出中断模式,返回被中断的线程。
- 另一种情况是:在中断处理过程中需要进行线程切换,这种情况会调用 rt_hw_context_switch_interrupt() 函数进行上下文切换,该函数跟 CPU 架构相关,不同 CPU 架构的实现方式有差异。
在 Cortex-M 架构中 rt_hw_context_switch_interrupt() 将设置需要切换的线程 rt_interrupt_to_thread 变量,然后触发 PendSV 异常(PendSV 异常是专门用来辅助上下文切换的,且被初始化为最低优先级的异常)。PendSV 异常被触发后,不会立即进行 PendSV异常中断处理程序,因为此时还在中断处理中,只有当中断后续程序运行完毕,真正退出中断处理后,才进入 PendSV 异常中断处理程序。
void rt_schedule(void)
{
rt_base_t level;
struct rt_thread *to_thread;
struct rt_thread *from_thread;
/* disable interrupt */
level = rt_hw_interrupt_disable();
/* check the scheduler is enabled or not */
if (rt_scheduler_lock_nest == 0)
{
rt_ubase_t highest_ready_priority;
if (rt_thread_ready_priority_group != 0)
{
/* need_insert_from_thread: need to insert from_thread to ready queue */
int need_insert_from_thread = 0;
to_thread = _get_highest_priority_thread(&highest_ready_priority); //获取下一个将要调度的线程
.....
if (to_thread != rt_current_thread)
{
/* if the destination thread is not the same as current thread */
rt_current_priority = (rt_uint8_t)highest_ready_priority;
from_thread = rt_current_thread; //配置from 线程为当前线程
....
rt_hw_context_switch((rt_ubase_t)&from_thread->sp, (rt_ubase_t)&to_thread->sp); //配置线程信息,trigger PendSv
...
1.6.1 VTOR Register
在 RTOS上默认不支持 0 地址检查,也即可以对 0 地址进行读写,基于以下原因需要对 0 地址及 0 地址附近地址做一定的保护措施:
- 由于 0 地址放的是代码段,所以 0 地址不能进行写操作,这个可以通过配置 MPU来进行操作。
- 由于系统运行中会经常出现访问空指针的问题,所以为了方便问题定位, 需要对0地址进行禁止访问的配置。
如果对 0 地址进行保护, 就需要对0地址及附近的地址进行 Reserve 操作,然后通过MPU 配置为禁止访问的权限,默认情况下 0 地址处放的是向量表,如果要Reserve掉,就需要将向量表的基置于其位置,然后在系统启动的时候将改地址赋值给 VTOR 寄存器。对 VTOR 寄存器的配置需要注意下面内容:

即向量表的基地址至少要 128 Bytes对齐,此外对齐地址应该为:中断个数 x 4,
当前由于我们支持 160 个 NVIC 中断,再加上16个系统异常,所以该向量的基地址对齐方式应是1024Bytes
推荐阅读:
https://tech.hqew.com/fangan_1973287
https://community.arm.com/support-forums/f/architectures-and-processors-forum/5219/how-long-are-the-cortex-m7-pipeline-stages
https://blog.csdn.net/BLBQ962464/article/details/123964567