Redis数据实战之GEO在LBS中应用与自定义新数据类型
Redis数据实战之GEO在LBS中应用与自定义新数据类型
-
- 引言
- 面向 LBS 应用的 GEO 数据类型
- GEO 的底层结构
- GeoHash 的编码方法
- 如何操作 GEO 类型
- 如何自定义数据类型
-
- Redis 的基本对象结构
- 开发一个新的数据类型
引言
Redis 的 5 大基本数据类型:String、List、Hash、Set 和Sorted Set,它们可以满足大多数的数据存储需求,但是在面对海量数据统计时,它们的内存开销很大,而且对于一些特殊的场景,它们是无法支持的。所以,Redis 还提供了 3种扩展数据类型,分别是 Bitmap、HyperLogLog 和 GEO。
面向 LBS 应用的 GEO 数据类型
在日常生活中,我们越来越依赖搜索“附近的餐馆”、在打车软件上叫车,这些都离不开基于位置信息服务(Location-Based Service,LBS)的应用。LBS 应用访问的数据是和人或物关联的一组经纬度信息,而且要能查询相邻的经纬度范围,GEO 就非常适合应用在LBS 服务的场景中,我们来看一下它的底层结构。
GEO 的底层结构
我以叫车服务为例,来分析下 LBS 应用中经纬度的存取特点。
- 每一辆网约车都有一个编号(例如 33),网约车需要将自己的经度信息(例如
116.034579)和纬度信息(例如 39.000452 )发给叫车应用。 - 用户在叫车的时候,叫车应用会根据用户的经纬度位置(例如经度 116.054579,纬度
39.030452),查找用户的附近车辆,并进行匹配。 - 等把位置相近的用户和车辆匹配上以后,叫车应用就会根据车辆的编号,获取车辆的信
息,并返回给用户。
可以看到,一辆车(或一个用户)对应一组经纬度,并且随着车(或用户)的位置移动,相应的经纬度也会变化。
这种数据记录模式属于一个 key(例如车 ID)对应一个 value(一组经纬度)。当有很多车辆信息要保存时,就需要有一个集合来保存一系列的 key 和 value。Hash 集合类型可以快速存取一系列的 key 和 value,正好可以用来记录一系列车辆 ID 和经纬度的对应关系,所以,我们可以把不同车辆的 ID 和它们对应的经纬度信息存在 Hash 集合中。
但问题是,对于一个 LBS 应用来说,除了记录经纬度信息,还需要根据用户的经纬度信息在车辆的 Hash 集合中进行范围查询。一旦涉及到范围查询,就意味着集合中的元素需要有序,但 Hash 类型的元素是无序的。
Sorted Set 类型也支持一个 key 对应一个 value 的记录模式,其中,key 就是 SortedSet 中的元素,而 value 则是元素的权重分数。更重要的是,Sorted Set 可以根据元素的权重分数排序,支持范围查询。这就能满足 LBS 服务中查找相邻位置的需求了。实际上,GEO 类型的底层数据结构就是用 Sorted Set 来实现的。
这时问题来了,Sorted Set 元素的权重分数是一个浮点数(float 类型),而一组经纬度包含的是经度和纬度两个值,是没法直接保存为一个浮点数的,那具体该怎么进行保存呢?那就是GeoHash编码。
GeoHash 的编码方法
为了能高效地对经纬度进行比较,Redis 采用了业界广泛使用的 GeoHash 编码方法,这个方法的基本原理就是“二分区间,区间编码”。当我们要对一组经纬度进行 GeoHash 编码时,我们要先对经度和纬度分别编码,然后再把经纬度各自的编码组合成一个最终编码。
对于一个地理位置信息来说,它的经度范围是[-180,180]。GeoHash 编码会把一个经度值编码成一个 N 位的二进制值,我们来对经度范围[-180,180]做 N 次的二分区操作,其中 N可以自定义。在进行第一次二分区时,经度范围[-180,180]会被分成两个子区间:[-180,0) 和[0,180](我称之为左、右分区)。此时,我们可以查看一下要编码的经度值落在了左分区还是右分区。如果是落在左分区,我们就用 0 表示;如果落在右分区,就用 1 表示。这样一来,每做完一次二分区,我们就可以得到 1 位编码值。当做完 N 次的二分区后,经度值就可以用一个 N bit 的数来表示了。
举个例子,假设我们要编码的经纬度值是 116.37,39.86 用 5 位编码值:
当一组经纬度值都编完码后,我们再把它们的各自编码值组合在一起,组合的规则是:最终编码值的偶数位上依次是经度的编码值,奇数位上依次是纬度的编码值,其中,偶数位从 0 开始,奇数位从 1 开始。
用了 GeoHash 编码后,原来无法用一个权重分数表示的一组经纬度(116.37,39.86)就可以用 1110011101 这一个值来表示,就可以保存为 Sorted Set 的权重分数了。
使用 GeoHash 编码后,我们相当于把整个地理空间划分成了一个个方格,每个方格对应了 GeoHash 中的一个分区。

所以,我们使用 Sorted Set 范围查询得到的相近编码值,在实际的地理空间上,也是相邻的方格,这就可以实现 LBS 应用“搜索附近的人或物”的功能了。但是,有的编码值虽然在大小上接近,但实际对应的方格却距离比较远。所以,为了避免查询不准确问题,我们可以同时查询给定经纬度所在的方格周围的 4 个或8 个方格。
如何操作 GEO 类型
- GEOADD 命令:用于把一组经纬度信息和相对应的一个 ID 记录到 GEO 类型集合中;
- GEORADIUS 命令:会根据输入的经纬度位置,查找以这个经纬度为中心的一定范围内
的其他元素。
假设车辆 ID 是 33,经纬度位置是(116.034579,39.030452),我们可以用一个 GEO集合保存所有车辆的经纬度,集合 key 是 cars:locations。
GEOADD cars:locations 116.034579 39.030452 33
LBS 应用执行下面的命令时,Redis 会根据输入的用户的经纬度信息(116.054579,39.030452 ),查找以这个经纬度为中心的 5 公里内的车辆信息,并返回给 LBS 应用。
GEORADIUS cars:locations 116.054579 39.030452 5 km ASC COUNT 10
我们可以使用 ASC 选项,让返回的车辆信息按照距离这个中心位置从近到远的方式来排序,以方便选择最近的车辆;还可以使用 COUNT 选项,指定返回的车辆信息的数量。
如何自定义数据类型
Redis 的基本对象结构
RedisObject 的内部组成包括了 type,、encoding,、lru 和 refcount 4 个元数据,以及 1个*ptr指针。
- type:表示值的类型,涵盖了我们前面学习的五大基本类型;
- encoding:是值的编码方式,用来表示 Redis 中实现各个基本类型的底层数据结构,例如 SDS、压缩列表、哈希表、跳表等;
- lru:记录了这个对象最后一次被访问的时间,用于淘汰过期的键值对;
- refcount:记录了对象的引用计数;
- ptr:是指向数据的指针。
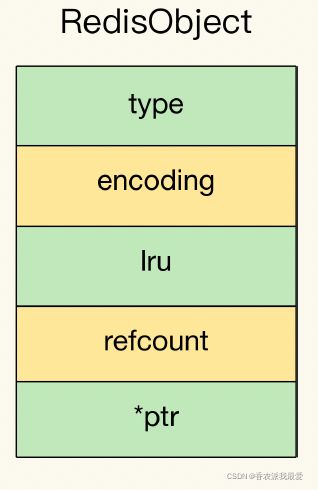
RedisObject 结构借助ptr指针,就可以指向不同的数据类型,例如,*ptr指向一个SDS 或一个跳表,就表示键值对中的值是 String 类型或 Sorted Set 类型。
开发一个新的数据类型

第一步:定义新数据类型的底层结构
我们用 newtype.h 文件来保存这个新类型的定义,具体定义的代码如下所示:
struct NewTypeObject {
struct NewTypeNode *head;
size_t len;
}NewTypeObject;
struct NewTypeNode {
long value;
struct NewTypeNode *next;
};
第二步:在 RedisObject 的 type 属性中,增加这个新类型的定义
这个定义是在 Redis 的 server.h 文件中。比如,我们增加一个叫作 OBJ_NEWTYPE 的宏定义,用来在代码中指代 NewTypeObject 这个新类型。
#define OBJ_STRING 0 /* String object. */
#define OBJ_LIST 1 /* List object. */
#define OBJ_SET 2 /* Set object. */
#define OBJ_ZSET 3 /* Sorted set object. */
…
#define OBJ_NEWTYPE 7
第三步:开发新类型的创建和释放函数
Redis 把数据类型的创建和释放函数都定义在了 object.c 文件中。所以,我们可以在这个文件中增加 NewTypeObject 的创建函数 createNewTypeObject:
robj *createNewTypeObject(void){
NewTypeObject *h = newtypeNew();
robj *o = createObject(OBJ_NEWTYPE,h);
return o;
}
先说 newtypeNew 函数。它是用来为新数据类型初始化内存结构的。这个初始化过程主要是用 zmalloc 做底层结构分配空间,以便写入数据。
NewTypeObject *newtypeNew(void){
NewTypeObject *n = zmalloc(sizeof(*n));
n->head = NULL;
n->len = 0;
return n;
}
newtypeNew 函数涉及到新数据类型的具体创建,而 Redis 默认会为每个数据类型定义一个单独文件,实现这个类型的创建和命令操作,例如,t_string.c 和 t_list.c 分别对应String 和 List 类型。按照 Redis 的惯例,我们就把 newtypeNew 函数定义在名为t_newtype.c 的文件中。
createObject 是 Redis 本身提供的 RedisObject 创建函数,它的参数是数据类型的 type和指向数据类型实现的指针*ptr。createObject 函数中传入了两个参数,分别是新类型的 type 值 OBJ_NEWTYPE,以及指向一个初始化过的 NewTypeObjec 的指针。这样一来,创建的 RedisObject 就能指向我们自定义的新数据类型了。
robj *createObject(int type, void *ptr) {
robj *o = zmalloc(sizeof(*o));
o->type = type;
o->ptr = ptr;
...
return o;
}
对于释放函数来说,它是创建函数的反过程,是用 zfree 命令把新结构的内存空间释放掉。
第四步:开发新类型的命令操作
- 在 t_newtype.c 文件中增加命令操作的实现。比如说,我们定义 ntinsertCommand 函数,由它实现对 NewTypeObject 单向链表的插入操作:
void ntinsertCommand(client *c){
//基于客户端传递的参数,实现在NewTypeObject链表头插入元素
}
- 在 server.h 文件中,声明我们已经实现的命令,以便在 server.c 文件引用这个命令,例
如:
void ntinsertCommand(client *c)
- 在 server.c 文件中的 redisCommandTable 里面,把新增命令和实现函数关联起来。
例如,新增的 ntinsert 命令由 ntinsertCommand 函数实现,我们就可以用 ntinsert 命令
给 NewTypeObject 数据类型插入元素了
struct redisCommand redisCommandTable[] = {
...
{"ntinsert",ntinsertCommand,2,"m",...}
}
觉得有用的客官可以点赞、关注下!感谢支持谢谢!