raft算法mysql主从复制_Etcd raft算法实现原理分析
1.1 主要概念
要实现集群数据的一致性,节点在进行通信的时候必定需要遵守特定规则进行数据校验,而这些规则具体都是通过某些具有特定含义的属性来实现的。为了让对Raft 算法比较陌生的读者对算法的关键概念有一个初步认识,作者整理了算法中涉及的概念如下所示:


1.2 节点状态
Raft 算法比较简单,其中一个原因是节点的状态少,一共只有三种角色,大大降低了角色间转换的复杂性。这三种角色分别是Leader 、Follower 和Candidate (其实大部分时间只有Leader 和Follower 角色,因为Candidate 只是选举的一个过渡角色),每种角色都有自己的运行规则。角色之间可以在一定条件下进行角色转换,状态转换如下图所示:
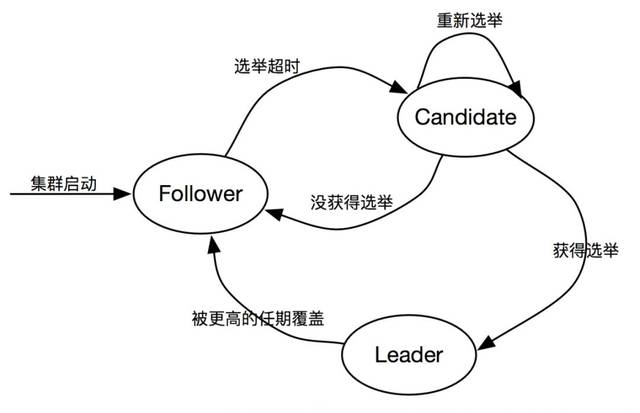
l Follower:集群启动时,每个Raft 节点初始以Follower的角色运行。他们各自维护了一个超时字段(ElectionTick属性),如果在超时时间段内Follower都没有收到来自Leader的消息,Follower就知道这个时候集群中没有Leader节点,这时它会把自己的角色转换为Candidate,并发起领导人选举。
l Candidate:处于Candidate状态的节点会发起选举的操作的操作,如果选举成功,那它将成为下一任的领导人,如果选举失败,就转化为Follower节点,负责处理Leader节点发起的请求,比如添加日志,心跳检测等操作。在选举过程中可能会有多个节点竞争领导人角色,并且多个选举人获得同样多的选票。这时候大家都不能当选Leader,经过一定时间,Follower会重新发起一轮选举,保证一次选举最多只有一个领导人。这里面有一些优化机制,比如每个候选人重新发起选举的间隔时间是不一样的,可以降低多次选票相同,重新选举的问题。
l Leader:Leader节点主要负责集群中数据的管理,包括给Follower发送添加日志、心跳检测(HeartbeatTick 属性)等命令。在Raft 节点运行过程中可能会有这种情况,即当前Leader节点宕机了,这时其他节点会重新选出一个Leader并且运行了一段时间,宕机的Leader节点恢复了,新的Leader会给老的Leader发送消息,这时老的Leader发现消息里面的任期(Term字段)比自己当前的Term更大,老的Leader就知道自己已经不是最新的领导人了,它会主动转换为Follewer角色。
1.3领导人选举
根据1.2 的介绍我们知道,Raft 节点在一启动的时候,就初始化为Follower 角色,并且每个Follower 角色都有一个ElectionTick 的随机超时属性。在超时的时间内如果Leader 对它们发起请求或者心跳检测,Follower 节点会使自己转变为Candidate 进行领导人选举。在领导人选举过程中,每个节点最多只能给一个节点投票,如果有两个节点发起投票,先到的那个节点会获得选票。这样能够保证每次选举期间最多只有一个节点当选。论文中节点发起选举参数和接收者实现规则如下图所示:

1. Follower首先给自己发送一个消息,使自己变为Candidate角色,设置Term+1 然后并发的对集群的所有节点发送选举的消息。集群中每个节点保存了一个数组,这个数组保存集群中所有节点的信息
2. 收到消息的Follower节点会对选举的请求做出参数校验和选举响应,如果Candidate发送的消息里面的Term比自己当前记录的更大,并且Candidate拥有自己已经更新的最新日志信息,就同意为Candidate投票,否则拒绝投票。
3. 如果Candidate收到大多数节点的投票响应,那Candidate就会成为新一任的Leader。给其他发送消息,并更
4. 如果Candidate没有当选Leader,就使自己转变为Follower角色,听从Leader的指令。
步骤1 描述的操作可能会出现一个问题;假如集群出现网络错误,使得集群中的节点(A 、B 、C 、D 、E 五个节点)被分成两部分,节点A 、B 、C 和节点D 、E 。这时D 、E 没收到Leader 节点的消息会重新发起选取,但是由于不能获得多数节点的选票,因此Term 会不断增大。如图3 所示,当网络回复的时候,D 、E 节点的Term 已经比正常集群的Term 更大,因此节点D 或节点E 将当选Leader ,导致节点A 、B 、C 在节点D 、E 宕机时期添加的正常数据被清除,从而破坏集群的历史数据。

这个问题在数据一致性的应用场景是不允许出现的,Raft 算法采用PreVote 算法解决了这个问题。PreVote 算法在Candidate 发起选举之前,会首先向其他节点发送一个预投票信息,这时Term 没有加1 ,如果超过半数节点同意了选举请求,Candidate 才设置Term+1 ,真正发起领导人选举投票。在上述环境中D 、E 节点是没办法获得超过半数节点的选票,因此节点只能反复Prevote ,Term 却没有机会增加。当网络恢复的时候当收到Node A 的消息,立刻使自己变成Follower 继续为集群服务。
1.4日志复制
Raft 集群中Leader 节点负责与客户端的交互,当非Follower 节点接收到客户端请求的时候,该节点会把该请求重定向到leader 节点,这种集中式的处理方式大大降低了集群和客户端的交互复杂度。用户的每次请求操作在Raft 集群中最终都是一个日志复制的过程,我们来看看一次简单日志复制过程:
1. 客户端给Leader节点发送一个 SET X = 5 的请求。
2. Leader节点收到客户端请求,首先把SET X = 5的指令写到日志中,然后把请求并发发送到所有Follower节点。
3. Follower节点收到Leader请求,也把SET X = 5 写到日志中,然后响应Leader 节点。
4. 当Leader节点收到大部分Follower节点写入成功后,把 SET X = 5 这个指令 commit 这个时候,Leader 节点上的X 才真正等于5,并发送commit 成功给所有Follower节点。
5. Follower节点收到Leader节点commit成功的信息,也commit,这个时候就实现了Raft集群数据的一致性。
在日志复制过程中,节点会对相应参数进行检测,避免无效信息被加入到日志中造成集群中数据不一致。论文中日志发送参数和节点校验规则如图5 所示:

添加日志消息的参数及其含义解释如下:
1. Term: 发送者的任期号。
2. LeaderId: 领导人的id。
3. PrevLogIndex: 之前Leader发送给Follower的最后一条日志索引,用于 Follower 确认与 Leader 的日志是否完全一致。新添加的日志会在这个索引之后开始。
4. PrevLogTerm: prevLogIndex索引对应的任期,用于检测Term的合法性。
5. Entries[]: 发送的日志数组,一次可以发送多条日志以提高效率。
6. LeaderCommit: Leader节点已经提交的最大日志索引,当节点收到这个记录的时候就知道,自提交日志到这个索引值是安全的。
消息接收者的数据校验规则:
1. 节点接收到消息时,如果发现消息来源的Term 小于自己当前记录的currentTerm,直接忽略这个消息。
2. 节点会根据prevLogIndex找到自己对应log的任期号term,如果和term和prevLogTerm不匹配,则直接返回false,不处理这个消息。
3. 检测entries数组是否和自己已经保存的log有冲突,如果有冲突,则删除这个冲突索引之后的所有日志。
4. 把所有新的日志entries加到自己的日志中。
5. 如果leaderCommit > commitIndex(自己已提交的最大索引),则设置 commitIndex = min( leaderCommit, entries)数组的最后一个元素的索引。
◆◆
2. Etcd raft 源码分析
◆◆
研究了Raft 的算法设计思想,接下来我们看Etcd 是怎么实现Raft 算法的。研究的Etcd 源码为V3.1.20 版本,下载地址https://github.com/etcd-io/etcd 。为了使读者对raft 算法代码结构有一个大致认识,我根据raft 启动过程画出以下代码调用图。建议要看源码的读者可以对着以下流程自己进入代码走一遍,对etcd 的raft 源码结构有一个大致印象,不然后面的代码可能会看的不知所云。

Etcd 的启动方法在etcdmain/main.go 文件中,应用启动后,raft 相关会启动两个协程,一个运行内层函数(raftnode.go 文件的node.run 方法) ,另一个运行外层函数(etcdserver/raft.go 文件中的start 方法)。内层函数主要处理节点数据内部的变更,外层函数主要负责获取内层函数的变更信息与其他节点的通信。内层函数和外层函数都有node 这个结构体的引用,因此两个协程之间可以通过node 里面的Channel 进行通信。
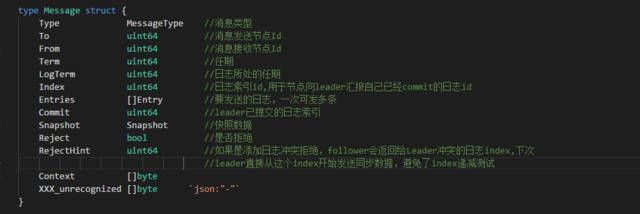
在Etcd 的raft 实现中,所有消息都被封装到一个结构体中,参数根据消息类型进行组装,因此很多参数都是可选的。一开始觉得所有消息的属性都集成在一个结构体不太好,后来看代码过程中发现这个结构体中属性并不多,而且大部分属性在大部分消息中都是要用到的。只是冗余少数字段但是大大减少了消息结构体的数量,使得消息参数整体看起来更简单。消息类型和属性如下图所示:

介绍了消息类型,接下来我们来看看raft 算法中领导人选举的具体源码实现。领导人选举的大致步骤为
1. Candidate: 内层函数raft.run把消息添加到raft.msgs的slice结构中。
2. Candidate: 内层函数监听到raft.msgs有新消息写入,把raft.msgs的消息封装成一个Ready结构体,然后把这个结构体放入 node.readyc这个channel。
3. Candidate: 外层函数raftNode.start 监听到node.readyc这个channel中有数据到达,拿到这个消息,根据消息的目标节点把消息发送出去。
4. Follower: Follower收到Candidate的领导人选举请求,对请求做出响应。
5. Candidate:统计选举的回复,如果超过半数节点同意则当选Leader,否则转为Follower。
源码部分我将从go.etcd.io/etcd/etcdserver/raft.go 文件的StartNode(c *Config, peers []Peer) 函数开始分析,从这里开始主要是Raft 算法的核心实现。在StartNode 方法结尾启动了一个协程用于运行内层函数。
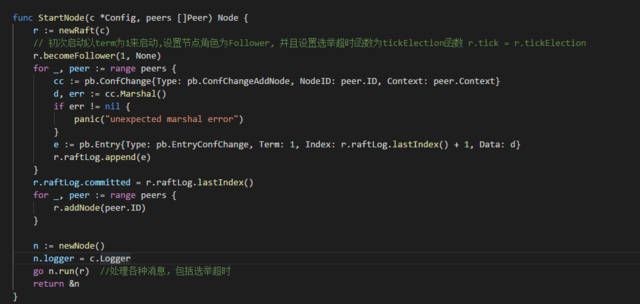
在StartNode 方法中,节点启动后初始化为Follower 角色,如果在选举超时内没有收到Leader 的消息,会发出一个选举超时事件,这个事件在内层函数(raftnode.go 文件的node.run 方法) 中被捕获,调用r.tick 函数,tick 实际上是一个函数变量,在becomeFollower 函数中被赋值为tickElection ,因此r.tick 方法实际上调用的是tickElection 方法进行领导人选举。
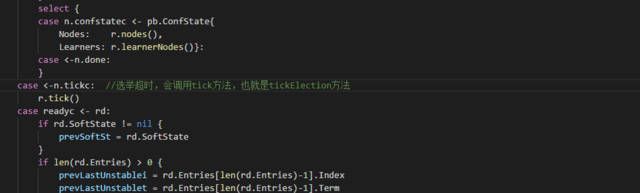
tickElection 方法中会检测相应参数,如果节点当前可选举,并且已超时则会节点的状态机函数(raftraft.go 文件Step 函数)传入一个类型为pb.MsgHup 的选举消息,这个消息不用于节点间通信,只是通知自己可以重新发起一轮领导人选举。
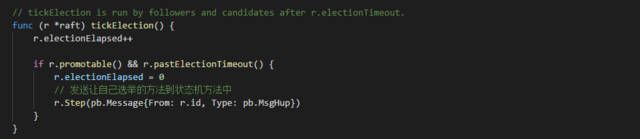
进入Step 状态机函数,pb.MsgHup 消息被捕获到,还是先检测相应参数,如果检测到自己已经是Leader ,就忽略这个消息。否则根据是否是Prevote 阶段进入相应投票阶段,前面我们说到,Prevote 解决了raft 集群网络分区造成的问题。

campaign 方法(raftraft.go 文件campaign 函数)中对消息做进一步处理,这里节点会排除自己对其他每个节点“发送“预选举/ 选举的消息,注意这里并没有真正发送消息,而是把消息加到raft 结构体的msgs 切片中。Raft.msgs 结构体主要用于临时存放待发送的消息。

当数据被写到raft.msgs 切片时,内层函数(raftnode.go 文件的node.run 方法)监听到raft.msgs 中有新数据待发送,会把数据封装成一个Ready 结构体放入node.readyc channel 中,清空raft.msgs 消息,并赋值advancec 为node.advancec channel 。一开始没看懂为什么这样写,后来在外层函数看到有一个往node.advancec 写入空结构体的操作才明白。当源节点往readyc 写入ready 数据后,就是一个异步操作,根本不知道目标节点什么时候能够处理完这个消息。源节点和目标节点通过node.advancec channel 就可以传递消息已经处理完的信号,源节点收到这个信号就可以进行后续的操作。
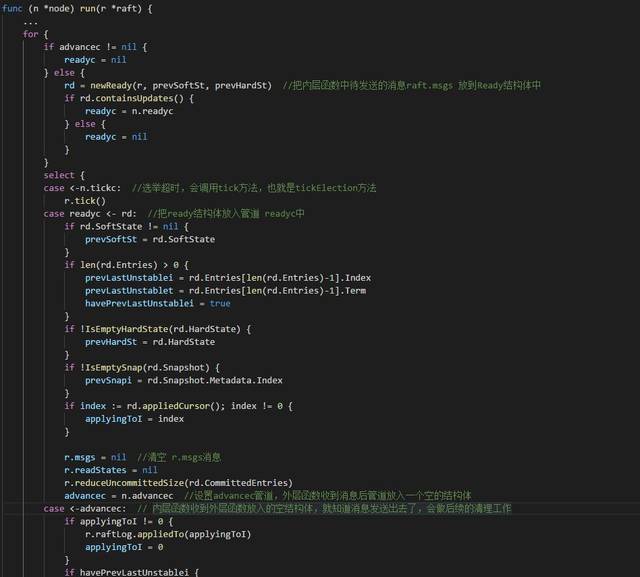
由于外层函数(etcdserver/raft.go 文件中的start 方法)拥有node.readyc 的引用,并且监听着这个管道,把readyc 到来的消息拿出来,根据消息结构体中的目标节点把消息发送出去,这个时候就是端到端节点消息的发送了。
Candidate 节点选举的消息发出去后,目的节点会在状态机函数(raftraft.go 文件Step 函数)中捕获到这个消息,捕获的消息类型为pb.MsgVote 和pb.MsgPreVote 。在这里对Term 和消息的index 进行了检测。对Term 的检测主要包括:1. 之前是不是已经给这个节点投过票,如果没投过票可以继续投,这表示是投票的PreVote 阶段。2. 投票节点的Term 是否大于自己的Term, 只有大于才是合理的Term 值。3. 已经投过票,这次的投票请求者是否和自己投过票的节点一样,这表示正式的投票阶段,第二次投票的必须和第一次投票的一样;对于Index 的检测主要是发起投票节点日志的Term 必须比自己的大,或者Term 相同,但是日志索引更多,也就是说发起投票的节点至少要拥有和自己一样或者更新的日志记录。这部分检测都通过后就回复同意投票的消息,否则回复否定投票的消息。
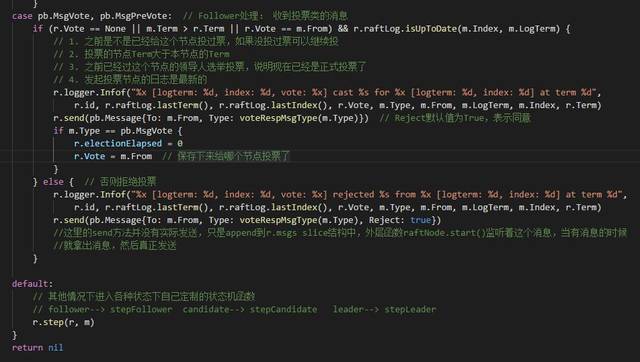
当所有节点都回复完Candidate 选举的请求时。这时候再回到Candidate 节点,消息仍然会在状态机函数(raftraft.go 文件Step 函数)被捕获。因为消息类型既不是pb.MsgHup ,又不是pb.MsgVote ,没有对应消息,所以代码会走到switch case 的default 部分,调用r.step(r, m) 函数,step 是一个函数变量,因为当前节点是Candidate 角色,所以r.step 对应stepCandidate 函数。在这个函数里,Candidate 对选票进行统计,如果获得超过半数的选票,就当选Leader ,否则变为Follower 。

到此,领导人选举的源码分析就大致完成了,日志添加过程,心跳检测机制等其他操作其实是一样的消息流转机制,只不过消息类型不同,只要找到相应的消息类型,一步步分析下来还是比较简单的。另外Etcd存储部分和Raft算法紧密相关,并且Etcd V3版本相比与V2版本的存储机制进行了较大的更新和优化,由于时间和篇幅的关系,这部分内容下次再分析。Etcd raft算法实现原理初步分析就到这里,个人理解有限,如果有不对的地方欢迎指出!
— END—