【Linux】基本开发工具包使用
目录
一, yum ——linux软件包管理器
1. 软件包是啥子?
2. yum基本使用
1. 步骤:
2. 开发工具推荐(centos 7.6)
二,vim —— linux文本编辑器
1. Normal mode —— 命令模式(记不住没关系,多练就行)
2. last line mode—— 末行模式 (如何进入;shift :)
3. Insert mode ——插入模式(同之前的编写代码方法类似,略)
4. vim 简单配置
步骤:
5. sudo 指令
三. gcc & g++使用
1. gcc 编译器
2. 静态库 & 动态库
3. g++ 编译器
四,gdb —— linux 调试器
1. 安装 gdb (centos7)
2. 背景
3. 开始使用
五, make & Makefile ——自动化构建工具
1. 背景
2. 构建
六,手搓小程序——进度条
1. 回车 & 换行的概念
2. 行缓冲区
3. 再聊输入输出流
4. 手搓一个倒计时
5. 手搓进度条
一, yum ——linux软件包管理器
1. 软件包是啥子?
在 Linux 下安装软件 , 一个通常的办法是下载到程序的源代码 , 并进行编译 , 得到可执行程序。 但是这样太麻烦了, 于是有些人把一些常用的软件提前编译好 , 做成软件包 ( 可以理解成 windows 上的安装程序) 放在一个服务器上 , 通过包管理器可以很方便的获取到这个编译好的软件包 , 直接进行安装。
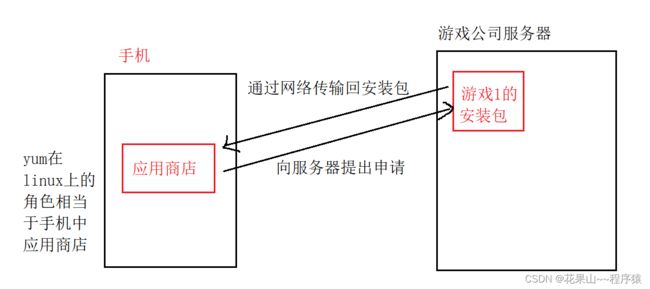
2. yum基本使用
1. 步骤:
查找:
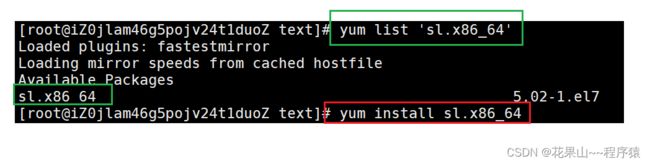
yum list | grep ‘软件名’ (先从软件包目录中查找)
yum list 'sl.x86_64' (也可以直接文件名查找)
安装:
yum intstall sl.x86_64 (安装对应文件)
卸载:
yum remove '软件名'
补充一下:
2. 开发工具推荐(centos 7.6)
man手册:
安装指令:yum intstall -y man-ages
windows与Linux下的拖拽工具:
yum install lrzsz.x86_64
二,vim —— linux文本编辑器
用法:vim text.c (如果未存在此文件,则会创建一个新文件)
vim 存在三种模式:
(1. 正常/普通/命令模式(Normal mode) ——进入vim的默认模式
控制屏幕光标的移动,字符、字或行的删除,移动复制某区段及进入Insert mode下,或者到 last line mode
(2. 插入模式(Insert mode) —— 在默认模式下按下 a, i, o 键
(3. 末行模式(last line mode)
1. Normal mode —— 命令模式(记不住没关系,多练就行)
建议都自己试一遍:

2. last line mode—— 末行模式 (如何进入;shift :)

3. Insert mode ——插入模式(同之前的编写代码方法类似,略)
(注意: vim编辑器中有更多的指令,但这些指令也足够了)
4. vim 简单配置
功能: 我们回想起我们使用vs时的,vs把帮我们自动补齐,行号,语法高亮这让我们使用很方便,高效;在vim下设置简单配置也可以达到这样的效果。
(注意: 1. root有自己的vim配置 2. vim一旦配置只影响当前用户)
步骤:
1. 寻找用户中是否有 .vimrc 的隐藏文件,没有则创建一个,这个文件将是vim配置数据的集合。
2 用vim打开.vimrc 文件。
3. 去网上寻找vim的相关配置代码,即可。
(注:这里是大佬已经做好的插件vimforcpp,在使用的用户(不建议在root用户下安装)下输入下面指令:
curl -sLf https://gitee.com/HGtz2222/VimForCpp/raw/master/install.sh -o ./install.sh && bash ./install.sh
重新链接服务器即可
5. sudo 指令
前面我们了解过sudo 临时(权限提升)登陆root的操作,但会返回:不是信任关系的信息。这次我们通过修改vim修改信任关系。
在root身份下用vim 打开 /etc/sudoers路径
vim /etc/sudoers

三. gcc & g++使用
1. gcc 编译器
这里不做详细解释,编译过程具体看这篇文章 详解C语言预处理&程序环境_花果山~~程序猿的博客-CSDN博客
这里只做指令截断分享,通过对过程的截断并存放至一个文件中,方便我们查看其中的操作。
用法: gcc [选项] [目标文件] -0 [新文件]
-o : 可以理解为产生目标
(1. 预处理
比如:

(2. 编译
比如:

(3. 汇编
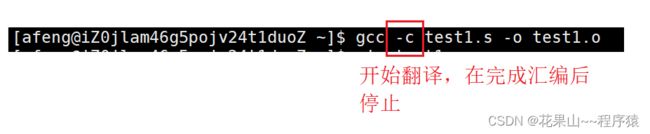
(4. 链接
历史背景: 最早期的程序员大多是一群科学家,他们通过给计算机输入二进制语言进行操作(也就是机器语言),随着时间的推移发现,二进制实在太晦涩,于是科学家们将一些常见二进制指令打包成一条指令,写出了汇编语言,后来丹尼斯*里奇发明了C语言, 后来大家运用时发现,面向过程效率太低,c++, java,python等面向对象语言出现了。这一路走来,语言越来越精简,越来越封装,但计算机还是只认识二进制,语言的翻译就会沿着时间线,利用前人的努力,逐渐底层,逐渐难以理解,这是积淀的过程。
2. 静态库 & 动态库
首先我们以张图来初步认识静态库&动态库
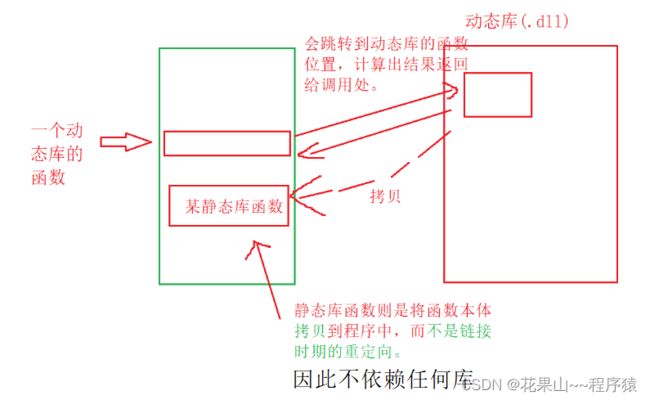
那我们来测试一下一个文件,看看是否存在动态库依赖。
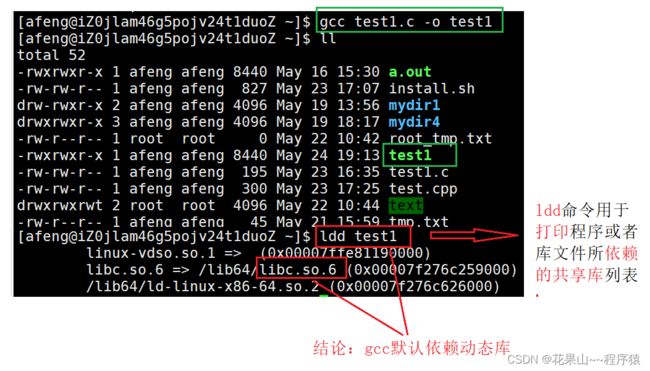
那么如果我们想用静态库来编译呢?
使用静态库来编译用法:gcc [文件] -o [新文件] -static
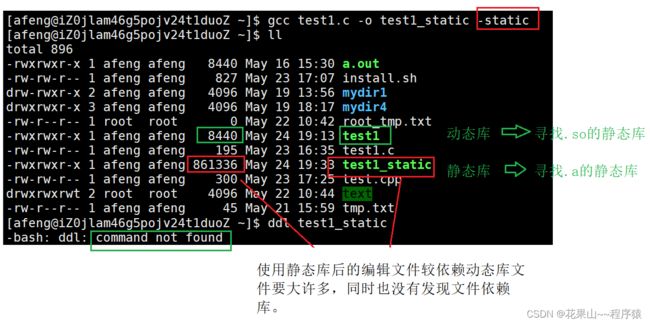
注意:如果出现下面反馈,就是静态库未安装
![]()
这是centos 7.6 C语言静态库
在root身份下输入:yum install glibc-static
3. g++ 编译器
首先我们查看我们是否拥有g++编译器
输入指令:g++ -v
出现这个表示未安装

没安装,现在安装 在centos 7 的root身份下输入以下指令:
yum install gcc gcc-c++
等待安装完成即可(注意:C++向下兼容C,所以g++可以编译C源码,但我们一般不这样用)
四,gdb —— linux 调试器
1. 安装 gdb (centos7)
查看gdb是否安装:gdb -v

则输入快速安装指令 sudo yum -y install gdb
反之则安装成功。
2. 背景
(1. 程序执行有两种版本 debug 和 release 版本。
(2. g++编译器默认编译出 release版本,所以想要编译出debug版本一定要加入debug信息。末尾加上-g
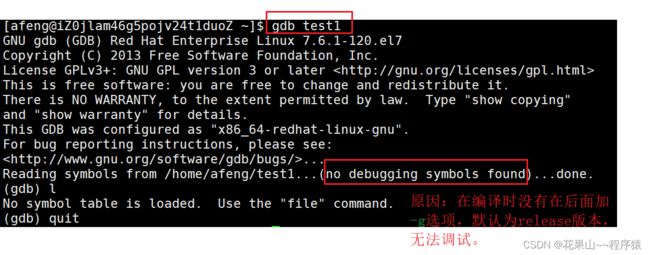
3. 开始使用
list/l 行号:显示编译文件的源代码,接着上次的位置往下列,每次列10行。
list/l 函数名:列出某个函数的源代码。
r 或run:运行程序
n 或 next:单条执行——理解为逐过程
s或step:进入函数调用——理解为逐语句
break(b n) 行号:在某一行设置断点
break 函数名 (b 函数名):在某个函数开头设置断点
info break (i b) :查看断点信息
delete breakpoints:删除所有断点
delete breakpoints n:删除序号为n的断点
disable breakpoints:禁用断点
enable breakpoints:启用断点
display 变量名:跟踪查看一个变量,每次停下来都显示它的值
undisplay + 跟踪值代号:取消对先前设置的那些变量的跟踪
finish:执行到当前函数返回,然后停下来等待命令
continue(或c):从当前位置开始连续执行程序,到达下一个断点停止
until X行号:跳至X行
print(p):打印表达式的值,通过表达式可以修改变量的值或者调用函数
p 变量:打印变量值。
set var:修改变量的值
info breakpoints (i b):参看当前设置了哪些断点
breaktrace (或bt):查看各级函数调用及参数
info(i) locals:查看当前栈帧局部变量的值
quit:退出gdb
在linux下调试,可以做到快速调试,不需要移植代码,对linux调试我们需要有了解的程度,知道怎么打取消断点,跟踪变量。
五, make & Makefile ——自动化构建工具
1. 背景
- 会不会写makefile,从一个侧面说明了一个人是否具备完成大型工程的能力。
- 在VS中编译器会帮我们做,但在Linux中我们得自己构建。 一个工程中的源文件不计数,其按类型、功能、模块分别放在若干个目录中,makefile定义了一系列的规则来指定,哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译,甚至于进行更复杂的功能操作。
- makefile带来的好处就是——“自动化编译”,一旦写好,只需要一个make命令,整个工程完全自动编译,极大的提高了软件开发的效率。
- make是一个命令工具,是一个解释makefile中指令的命令工具,一般来说,大多数的IDE都有这个命令,比如:Delphi的make,Visual C++的nmake,Linux下GNU的make。可见,makefile都成为了一种在工程方面的编译方法。
- make是一条命令,makefile是一个文件,两个搭配使用,完成项目自动化构建。
makefile 这个文件存放文件的 依赖关系&依赖方法

2. 构建
1. 创建一个Makefile文件。
2. 在Makefile 文件中创建 依赖关系&依赖方法。
3. make 指令更新数据,这样我们就不需要每次gcc编译文件了,只要执行编译出的文件。

六,手搓小程序——进度条
1. 回车 & 换行的概念
回车: 回到当前行的开头,也就是 "\r"
换行: 列不变,光标换至下一行
" \n"则是有 回车& 换行两个意思
2. 行缓冲区
我们尝试运行运行下面代码:
#include
#include
int main()
{
printf("hello Makefile!\n");
sleep(3); // 停止执行3秒
return 0;
} 我们发现 ,字符串马上被打印出来,3秒后程序才执行完毕。
我们看下面的代码:
#include
#include
int main()
{
printf("hello Makefile!"); // 我们将\n符去掉
sleep(3);
return 0;
} 这时我们会发现,字符串并没有立刻输出,而是过3秒后才输出。
结论: printf 在打印一个字符串时,不会立即打印,会放在C语言级别的行缓存器中,当遇到"\n"符时才会刷新显示器。
(这里不仅仅有这些知识,目前只分享这些,后面会逐步加深。)
3. 再聊输入输出流
在C语言中我们曾聊过输入输出流,见此文章详解文件操作&相关函数(超详细!)_花果山~~程序猿的博客-CSDN博客
在C语言中,默认会打开 三个输入输出流文件分别是 stdin , stdout , stderr
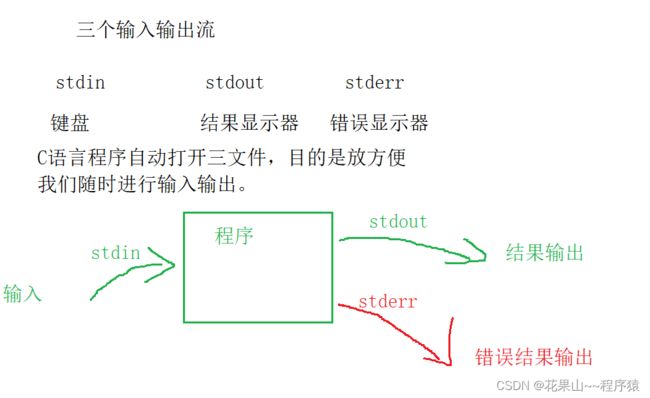
面对第2小节的行缓存,那有什么方法可以立即刷新,行缓冲区呢?有的
int fflush(FILE *stream) —— 流刷新
代码修改:
#include
#include
int main()
{
printf("hello Makefile!"); // 我们将\n符去掉
fflush(stdout) //刷新输出流
sleep(3);
return 0;
}
从结果表现来看,字符串被立即打印,fflush刷新流确实可以。
4. 手搓一个倒计时
代码:
#include
#Inlcude
int main()
{
int i = 10;
while(i > -1)
{
printf("%d\r", i);
fflush(stdout);
i--;
}
return 0;
} 结果我们会发现这样的结果:10 90 80 70 .... 这是因为先打印的是 10占两个字符位,后面的只占一个字符位,所以只更新一个字符位且 \r是回到该行的首字符,因此会有这样的结果。(注: 显示器只会显示字符)
优化方式:%d 写成 %2d
5. 手搓进度条
铺垫完成后,我们开始制作进度条
我们以 “=” 来充当进度单位,实现。思路:用一个存100+ 1个’\0‘的字符数组,存放进度条。代码如下:
#include
#include
#include
int main()
{
int n = 100;
char str[101];
memset(str, '\0', sizeof(str));
for( int i = 0; i <= 100; i++ )
{
printf("[%-100s][%d%%]\r", str, i);
fflush(stdout);
str[i] = '=';
usleep(50000);
}
printf("\n");
return 0;
} 
结语
本小节就到这里了,感谢小伙伴的浏览,如果有什么建议,欢迎在评论区评论;如果给小伙伴带来一些收获请留下你的小赞,你的点赞和关注将会成为博主创作的动力。