so-vits-svc4.0 中文详细安装、训练、推理使用教程【克隆声音】
文章目录
- 项目环境准备
-
- 在这里插入图片描述 [pytorch的各种版本](https://pytorch.org/get-started/previous-versions/)  验证是否安装成功  
- 项目准备
- 数据预处理
-
- 开始训练模型
- `提示:如果想中断训练可以使用快捷键 Ctrl+C`
- 推理展示
项目环境准备
[项目文件包:so-vits-svc]
https://github.com/svc-develop-team/so-vits-svc.git
提示:如果您的网速不理想可以考虑使用: https://ghproxy.com/https://github.com/svc-develop-team/so-vits-svc.git 加速下载

写教程的日期都是2023年4月21日,4月18号项目都大版本更新到了5.0了。
[预训练模型: ContentVec:checkpoint_best_legacy_500.pt]
地址:https://ibm.box.com/s/z1wgl1stco8ffooyatzdwsqn2psd9lrr
放在hubert目录下
# contentvec
wget -P hubert/ http://obs.cstcloud.cn/share/obs/sankagenkeshi/checkpoint_best_legacy_500.pt
# Alternatively, you can manually download and place it in the hubert directory
- python版本 Python 3.8.9
//第一步: 创建一个叫 sovitssvc的 Anaconda 环境
conda create -n sovitssvc python=3.8.9
//第二步: 激活环境 sovitssvc
conda activate sovitssvc
提示:本教程默认是N卡教程,没接触过A卡。
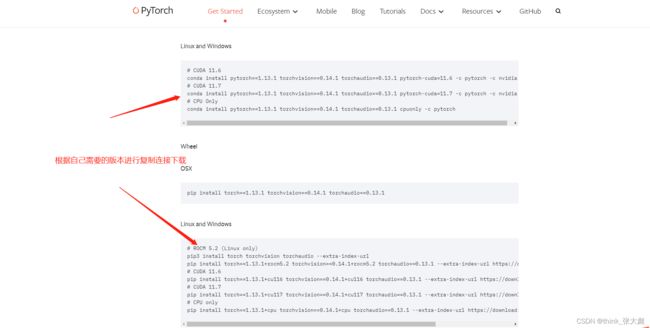
安装:pytorch
//第一步:安装N卡驱动(某度查询)否则又要出教程了
//第二步:查询自己显卡适用的 版本
nvidia-smi

pytorch的各种版本
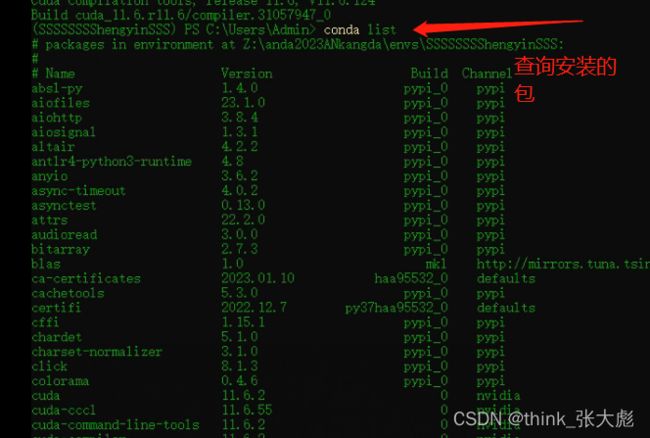
验证是否安装成功

项目准备
pip install -r requirements.txt

注意:如果在使用或者安装过程中出现报错不能安装的情况,尽量根据报错的内容进行根据实际情况调整即可。
数据预处理
安装 伴奏与人声分离工具:UVR5 (Ultimate Vocal Remover GUI v5.5.0)
预先处理出声音
建议:如果硬件不好的同学,尽量把声音文件分割成10M文件以下比较好。
数据预处理:
启动 resample.py
echo 重采样完成结束(如果上面有报错信息代表数据预处理未完成)
echo ====================================
echo 划分数据集并生成配置文件...
启动 preprocess_flist_config.py
echo 配置文件生成结束(如果上面有报错信息代表数据预处理未完成)
echo ====================================
echo 生成hubert/f0文件
启动 preprocess_hubert_f0.py
echo 数据预处理结束(如果上面有报错信息代表数据预处理未完成)
pause
开始训练模型
训练模型命令语句:
python train.py -c configs/config.json -m 44k
建议:如果你得显卡的跟我一样只是一个RTX1650 的4G显卡,可以考虑修改 "batch_size": 1,

在/log/44k/文件目录下会生成

训练日志内容
2023-04-21 09:22:14,809 44k INFO {'train': {'log_interval': 200, 'eval_interval': 800, 'seed': 1234, 'epochs': 10000, 'learning_rate': 0.0001, 'betas': [0.8, 0.99], 'eps': 1e-09, 'batch_size': 1, 'fp16_run': False, 'lr_decay': 0.999875, 'segment_size': 10240, 'init_lr_ratio': 1, 'warmup_epochs': 0, 'c_mel': 45, 'c_kl': 1.0, 'use_sr': True, 'max_speclen': 512, 'port': '8001', 'keep_ckpts': 3, 'all_in_mem': False}, 'data': {'training_files': 'filelists/train.txt', 'validation_files': 'filelists/val.txt', 'max_wav_value': 32768.0, 'sampling_rate': 44100, 'filter_length': 2048, 'hop_length': 512, 'win_length': 2048, 'n_mel_channels': 80, 'mel_fmin': 0.0, 'mel_fmax': 22050}, 'model': {'inter_channels': 192, 'hidden_channels': 192, 'filter_channels': 768, 'n_heads': 2, 'n_layers': 6, 'kernel_size': 3, 'p_dropout': 0.1, 'resblock': '1', 'resblock_kernel_sizes': [3, 7, 11], 'resblock_dilation_sizes': [[1, 3, 5], [1, 3, 5], [1, 3, 5]], 'upsample_rates': [8, 8, 2, 2, 2], 'upsample_initial_channel': 512, 'upsample_kernel_sizes': [16, 16, 4, 4, 4], 'n_layers_q': 3, 'use_spectral_norm': False, 'gin_channels': 256, 'ssl_dim': 256, 'n_speakers': 1}, 'spk': {'shengyin': 0}, 'model_dir': './logs\\44k'}
2023-04-21 09:22:14,809 44k WARNING 项目路径 is not a git repository, therefore hash value comparison will be ignored.
2023-04-21 09:22:39,592 44k INFO Loaded checkpoint './logs\44k\G_10400.pth' (iteration 93)
2023-04-21 09:22:40,156 44k INFO Loaded checkpoint './logs\44k\D_10400.pth' (iteration 93)
2023-04-21 09:25:19,423 44k INFO Train Epoch: 93 [5%]
2023-04-21 09:25:19,424 44k INFO Losses: [2.145604372024536, 2.30800724029541, 9.632743835449219, 24.18358039855957, 1.475522756576538], step: 288400, lr: 9.884415910120204e-05
2023-04-21 09:27:28,330 44k INFO Train Epoch: 93 [12%]
2023-04-21 09:27:28,331 44k INFO Losses: [2.2175517082214355, 2.059602975845337, 7.342342853546143, 27.495437622070312, 1.2441108226776123], step: 288600, lr: 9.884415910120204e-05
2023-04-21 09:29:36,601 44k INFO Train Epoch: 93 [18%]
2023-04-21 09:29:36,602 44k INFO Losses: [3.196673631668091, 2.053837299346924, 1.5211962461471558, 14.538193702697754, 0.9200491905212402], step: 288800, lr: 9.884415910120204e-05
2023-04-21 09:29:47,939 44k INFO Saving model and optimizer state at iteration 93 to ./logs\44k\G_288800.pth
2023-04-21 09:29:49,265 44k INFO Saving model and optimizer state at iteration 93 to ./logs\44k\D_288800.pth
提示:如果想中断训练可以使用快捷键 Ctrl+C
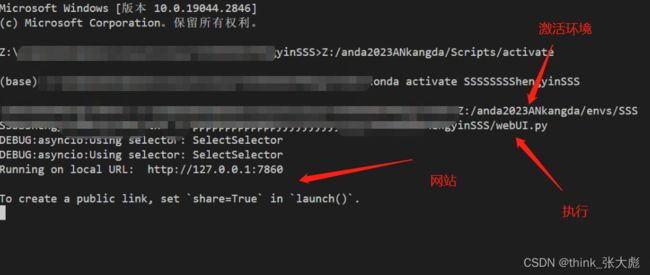
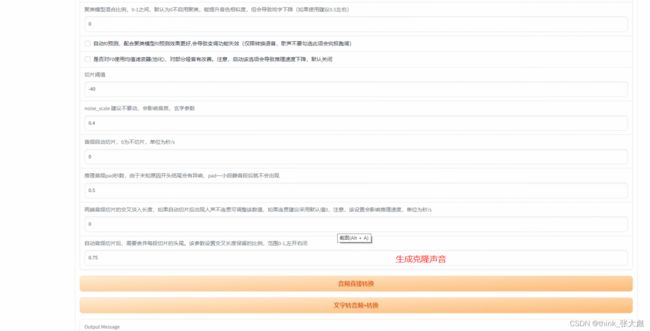
推理展示
执行 webUI.py