【022】C++的结构体、共用体以及枚举详解(最全讲解)
C++的结构体、共用体以及枚举详解
- 引言
- 一、结构体的概述
- 二、结构体变量的操作
-
- 2.1、结构体变量的初始化
- 2.2、清空整个结构体变量
- 2.3、键盘给结构体变量中的成员赋值
- 2.4、单独操作结构体中的成员
- 2.5、相同类型结构体变量之间的赋值
- 三、结构体嵌套结构体
- 四、结构体数组
- 五、结构体指针变量
- 六、结构体的指针成员
-
- 6.1、结构体的浅拷贝
- 6.2、结构体的深拷贝
- 6.3、结构体变量在堆区则结构体的指针成员也指向堆区
- 七、结构体的对齐规则
-
- 7.1、背景知识
- 7.2、结构体自动对齐规则
- 7.3、强制对齐规则
- 八、结构体的位域
-
- 8.1、结构体位域的概述
- 8.2、另起一个存储单元
- 8.3、无意义位段(重要)
- 九、共用体union
- 十、枚举enum
- 总结
引言
作者简介:专注于C/C++高性能程序设计和开发,理论与代码实践结合,让世界没有难学的技术。包括C/C++、Linux、MySQL、Redis、TCP/IP、协程、网络编程等。
️ CSDN实力新星,社区专家博主
专栏介绍:从零到c++精通的学习之路。内容包括C++基础编程、中级编程、高级编程;掌握各个知识点。
专栏地址:C++从零开始到精通
博客主页:https://blog.csdn.net/Long_xu
上一篇:【021】C/C++字符串处理函数
一、结构体的概述
结构体是一种自定义的数据类型,它可以包含多个不同的数据类型的成员。结构体允许用户将相关的数据项组合在一起形成一个单独的实体,并可以对该实体进行操作。结构体通常被用于表示复杂的对象或记录,如人员信息、学生档案等等。结构体由一个或多个成员变量组成,每个成员变量都可以有不同的数据类型和名字。结构体也可以嵌套定义在其他结构体中,以实现更复杂的数据模型。在 C/C++ 语言中,结构体是一种非常重要的数据类型,在很多编程领域都得到了广泛应用。
一个学生有学号、姓名、性别、年龄、地址等属性:
int num;
char name[16];
char sex;
int age;
char addr[32];
单独定义比较繁琐,数据不易于管理。C++提供struct关键字可以将不同类型封装在一起,形成新的结构:结构体。
struct student{
int num;
char name[16];
char sex;
int age;
char addr[32];
};
结构体类型的定义:
在 C++ 语言中,可以使用 struct 关键字来定义一个结构体类型。结构体的基本语法格式如下:
struct 结构体名称 {
数据类型 成员变量1;
数据类型 成员变量2;
...
};//注意以;结束
其中,struct 表示声明一个结构体类型,紧随其后的是结构体的名称。花括号内部是结构体的成员变量列表,每个成员变量都由数据类型和成员变量名组成,并以分号结束。
例如,下面是一个表示学生信息的结构体类型定义:
struct Student {
int id; // 学生学号
char name[20]; // 学生姓名
int age; // 学生年龄
};
// 结构体定义变量
struct Student tom;
struct Student Lion;
这个结构体包含了三个成员变量:id、name 和 age,分别表示学生编号、姓名和年龄。
访问结构体变量中成员的方法:结构体变量.成员名。
// 结构体定义变量
struct Student tom;
struct Student Lion;
tom.name;
tom.id;
Lion.name;
Lion.id;
注意:
- 系统不会为结构体类型开辟空间,只会为结构体类型定义的变量开辟空间。
- 定义结构体类型时,不要给成员初始化值。
三种定义结构体类型的方法:
(1)先定义结构体类型,再定义结构体变量。
struct Student{
int id;
char name[16];
};
struct Student tom;
(2)定义结构体类型的同时定义变量。
struct Student{
int id;
char name[16];
} tom;
(3)定义一次性结构体类型。
struct{
int id;
char name[16];
} tom;
二、结构体变量的操作
局部变量不初始化,变量中的成员内容不确定(随机值)。
2.1、结构体变量的初始化
结构体变量的初始化必须遵循成员的顺序以及成员自身的数据类型。
struct Student{
int id;
char name[16];
};
struct Student tom={101,"tom"};
cout<<tom.id<<" "<<tom.name<<endl;
2.2、清空整个结构体变量
使用memset清空结构体变量。memset()在头文件string.h中。
memset函数原型如下:
void *memset(void *s, int c, size_t n);
其中,s是指向待填充的内存块的指针;c是要填充到内存块中的值(通常为0或者-1);n是要填充的字节数。函数返回s。
该函数会将 s 所指向的内存区域前 n 个字节都设置成字符 c(被转换成无符号字符)。如果参数s和参数 c 都是0,则该函数也可以用来清空内存块。
示例:
#include 2.3、键盘给结构体变量中的成员赋值
#include 输出:
请输入学号 姓名:101 tom
101 tom
2.4、单独操作结构体中的成员
单独操作结构体中成员必须遵循结构体本身的类型。
#include 输出:
请输入学号 姓名:101 tom
201 new tom
2.5、相同类型结构体变量之间的赋值
三个方式:
- 逐个成员赋值。
- 相同类型的结构体变量可以直接赋值(推荐)。
- 内存拷贝。
#include 三、结构体嵌套结构体
C++结构体嵌套结构体是一种将一个结构体作为另一个结构体的成员的方法。这种方式可以使程序更加模块化,同时也能够提高代码的可读性和可维护性。
示例程序演示如何使用C++结构体嵌套结构体:
#include 在上面的程序中,定义了两个结构体:Address和Person。Address包含三个字符串类型的成员变量:street、city和state;Person包含一个字符串类型的name、整型age和一个Address类型的address成员变量。
在main函数中,创建了一个Person对象person1,并初始化它的成员变量。然后,我们通过点运算符(.)访问person1对象的各个成员,并输出它们的值。
输出结果为:
Name: John Doe
Age: 30
Address: 123 Main St, Anytown, CA
通过这个示例,可以看到如何使用C++结构体嵌套结构体来创建复杂的数据结构,并访问它们的成员变量。
四、结构体数组
结构体数组本质是数组,只是数组的每个元素是结构体变量。
C++ 结构体数组是一种包含多个结构体变量的数据类型。每个结构体变量都可以包含多个属性,比如整型、浮点型、字符型等。
一个简单的例子:
struct student {
int id;
char name[20];
float score;
};
int main() {
// 定义一个有3个元素的结构体数组
student stu[3];
// 给每个学生赋值
stu[0].id = 1;
strcpy(stu[0].name, "Tom");
stu[0].score = 90;
stu[1].id = 2;
strcpy(stu[1].name, "Jerry");
stu[1].score = 80;
stu[2].id = 3;
strcpy(stu[2].name, "Bob");
stu[2].score = 85;
// 输出每个学生的信息
for (int i = 0; i < 3; i++) {
cout << "ID: " << stu[i].id << endl;
cout << "Name: " << stu[i].name << endl;
cout << "Score: " << stu[i].score << endl;
cout << endl;
}
return 0;
}
输出结果为:
ID: 1
Name: Tom
Score: 90
ID: 2
Name: Jerry
Score: 80
ID: 3
Name: Bob
Score: 85
在上面的例子中,首先定义了一个名为 student 的结构体,它包含三个属性:id、name 和 score。然后定义了一个名为 stu 的结构体数组,它包含三个元素。接着,给每个学生赋值,并输出了每个学生的信息。
需要注意的是,在使用结构体数组时,可以通过下标访问每个元素,比如 stu[0] 表示第一个学生,而且和普通数组一样,下标从 0 开始。同时,也可以使用循环来遍历整个数组。
五、结构体指针变量
结构体指针变量本质是变量,只是该变量保存的是结构体变量的地址。
简单的例子:
struct student {
int id;
char name[20];
float score;
};
int main() {
// 定义一个名为s的结构体变量
student s;
// 定义一个名为p的结构体指针变量,并将其指向s
student *p = &s;
// 通过指针访问结构体中的成员变量
p->id = 1;
strcpy(p->name, "Tom");
p->score = 90;
return 0;
}
在上面的例子中,首先定义了一个名为 student 的结构体,它包含三个属性:id、name 和 score。然后定义了一个名为 s 的结构体变量,并且定义了一个名为 p 的结构体指针变量,将其指向 s。接着,通过 p->id、p->name 和 p->score 访问了结构体中的成员变量,并给这些成员变量赋值。
需要注意的是,在使用结构体指针时,要使用箭头运算符(->)来访问成员变量。因为指针本身只存储了地址信息,而不是结构体本身,所以需要使用箭头运算符来指示指针所指向的结构体中的成员变量。
结构体数组元素的指针变量:
结构体数组元素的指针变量是一个指向结构体数组元素的指针。它可以用来访问结构体数组中的成员变量或者作为参数传递给函数。
struct student {
int id;
char name[20];
float score;
};
int main() {
// 定义一个名为students的结构体数组
student students[3];
// 定义一个名为p的结构体指针变量,并将其指向students[0]
student *p = &students[0];
// 通过指针访问结构体数组中的成员变量
p->id = 1;
strcpy(p->name, "Tom");
p->score = 90;
return 0;
}
定义了一个名为 student 的结构体,它包含三个属性:id、name 和 score。然后定义了一个大小为3的名为 students 的结构体数组,并且定义了一个名为 p 的结构体指针变量,将其指向 students[0]。接着,通过 p->id、p->name 和 p->score 访问了第一个元素(即 students[0])中的成员变量,并给这些成员变量赋值。
需要注意的是,在使用结构体数组元素的指针时,也要使用箭头运算符(->)来访问成员变量。因为指针本身只存储了地址信息,而不是结构体本身,所以需要使用箭头运算符来指示指针所指向的结构体数组元素中的成员变量。
六、结构体的指针成员
(1)指向文字常量区:
struct Stu{
int num;
char *name;
};
struct Stu lucy={101,"hello world"};

lucy.name保存的是“hello world”的首元素地址,而“hello world”字符串本身存储在文字常量区。
(2)指向堆区:
struct Stu{
int num;
char *name;
};
struct Stu lucy;
lucy.name=new char[32];
lucy.num=101;
strcpy(lucy.name,"lucy");
delete[] lucy.name;
6.1、结构体的浅拷贝
相同类型的结构体变量可以整体赋值,默认方式是浅拷贝(将结构体变量空间内容赋值一份到另一个相同类型的结构体变量空间中)。
浅拷贝是指仅仅将源结构体的成员变量的值复制给目标结构体,而不考虑成员变量所指向的动态内存区域。如果源结构体和目标结构体共享同一个动态内存区域,那么对于其中一个结构体进行修改操作就会影响另一个结构体。
如果结构体中没有指针成员,浅拷贝不会带来任何问题。如果结构体中有指针成员,浅拷贝会带来多次释放堆区空间的问题。
#include 上述代码中,两个Student类型的对象s1和s2通过赋值运算符进行浅拷贝。由于name成员变量是char*类型,实际上是指针类型,在进行浅拷贝时并没有考虑这个指针所指向的内存区域。
输出结果如下:
s1.name: 0x7ffde3e4b170
s2.name: 0x7ffde3e4b170
可以看到,s1和s2的name成员变量指向的内存区域是相同的。如果我们修改其中一个对象的name成员变量,另一个对象也会受到影响。
例如:
#include 输出结果如下:
s1.name: Jim
s2.name: Jim
可以看到,由于两个对象共享同一块内存区域,对其中一个对象的修改操作也同时影响了另一个对象。
因此,在进行结构体之间的赋值或传参时,应该谨慎考虑是否需要进行深拷贝(即复制指针所指向的动态内存区域)。
6.2、结构体的深拷贝
深拷贝是指复制一个新的对象,其中包含原始对象中所有成员变量的副本,而不是只简单地复制指向成员变量数据的指针。
如果结构体中有指针成员,尽量使用深拷贝。
例如:
#include C++结构体的另一种深拷贝写法:
#include 通过定义复制构造函数和赋值运算符重载来实现了Person结构体的深拷贝。在复制构造函数中,为新的name成员变量分配了一个新的内存空间,并将原有数据复制到其中。在赋值运算符重载中,首先判断是否为自我赋值,然后清空原有数据并重新分配内存空间进行复制。
需要注意的是,在使用动态内存分配时一定要记得释放内存(如上面代码中所示)。否则会出现内存泄漏等问题。
6.3、结构体变量在堆区则结构体的指针成员也指向堆区
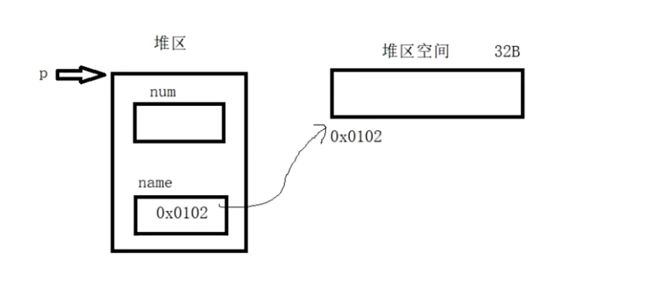
#include 七、结构体的对齐规则
7.1、背景知识
假设有这样一个结构体:
struct Data{
char a;
int b;
};
CPU一次读取4字节,当没有字节对齐时,内存状态:
- 访问a只需要一个周期,读取四个字节,只用第一个字节,其他字节丢弃。
- 访问b需要两个周期:第一个周期读取4字节,只要后三个字节;第二个周期读取4字节,只要第一个字节;然后将它们拼接成一个4字节的数据得到b。
CPU一次读取4字节,字节对齐时,内存状态:
- 访问a只需要一个周期,读取四个字节,只用第一个字节,其他字节丢弃。
- 访问b只需要一个周期,读取四个字节。
可以看到,字节对齐之后访问速度就变快了,而且不用进行字节拼接;只是需要浪费三个字节的空间(用空间换时间)。但是带来的好处是:提取快、方便、效率高。
7.2、结构体自动对齐规则
- 确定分配单位(一行分配多少字节)。由结构体中最大的基本类型长度决定。
- 确定成员的偏移量。成员偏移量=成员自身类型的整数倍。
- 收尾工作。结构体的总大小=分配单元整数倍。
举例,假设有如下的结构体:
struct Data{
char a;
int b;
};
则 最大的基本类型长度为4字节(int 类型变量);结构体的总大小为2 x 4=8字节。a的偏移量为0,b的偏移量为4 x 1=4。
再进阶一步,画出下面结构体的内存布局:
struct Data{
char a;
short b;
int c;
char d;
short e;
};
牢记上面的三个规则,就可以画出如下的内存布局:
7.3、强制对齐规则
#pragma pack(value)
指定对齐值value,value值一般为1、2、4、8、16等(2的n次幂)。
- 确定分配单位(一行分配多少字节)。由结构体中最大的基本类型长度和value中的最小值决定,即分配单位=min(结构体中最大的基本类型长度,value)。
- 确定成员的偏移量。成员偏移量=成员自身类型的整数倍。
- 收尾工作。结构体的总大小=分配单元整数倍。
例如:
#pragma pack(8)
struct data{
char a;
int b;
short c;
};
这个结构体的字节对齐是4字节。
再比如:
#pragma pack(2)
struct data{
char a;
int b;
short c;
};
这个结构体的字节对齐是2字节。
八、结构体的位域
8.1、结构体位域的概述
结构体位域是一种数据类型,它允许在一个字节中存储多个不同长度的字段。这些字段可以是布尔值、整数、字符或枚举类型。
使用结构体位域可以有效地减少内存占用,提高程序性能和效率。例如,在需要存储大量布尔值的情况下,使用结构体位域可以将每个布尔值压缩为一个二进制位,从而将所需内存减少到原来的八分之一。
结构体位域的语法如下:
struct bit_field {
unsigned int flag1: 1; // 1-bit field
unsigned int flag2: 2; // 2-bit field
unsigned int flag3: 3; // 3-bit field
};
在上面的示例中,bit_field 结构体包含三个不同长度的位域。每个位域都由 : 后面的数字表示其长度。默认情况下,位域采用无符号整数类型,并且长度不能超过该类型的总比特数。
注意:由于位域是按照机器字节顺序排列的,因此跨越两个字节边界的字段可能会导致不确定行为。
(1)没有非位域隔开的位域叫相邻位域。相同类型的相邻位域可以压缩,但是压缩的位数不能超过自身类型的大小。
struct data{
unsigned char a:2;
unsigned char b:3;
unsigned char c:3;
};
这个结构体就占一个字节。
(2)不能对位域取地址。因为位域是在二进制位,而系统是以字节为单位分配地址编号的。
struct data{
unsigned char a:2;
unsigned char b:3;
unsigned char c:3;
};
int main()
{
data m;
&m.b;//error,不允许
return 0;
}
(3)对位域赋值不要超过位域本身位的宽度。
#include 输出:
m.a=1;
溢出位被丢弃。
8.2、另起一个存储单元
#include 输出:
sizeof(m)=1;
sizeof(n)=2
8.3、无意义位段(重要)
无意义位段是可以压缩的,类似占位符,占着位置不允许其他使用。
struct data{
unsigned char a:4;
unsigned char : 2;// 无意义位段
unsigned char b:2;
};
示例:

如果不使用结构体位域,则:
REG reg;
// ...
reg=reg|(0x01<<0 | 0x01<<3|0x01<<7)&~(0x01<<1|0x01<<4|0x01<<6);
这样的位运算比较复杂,不易于理解。
如果使用结构体位域,则:
REG reg;
// ...
reg.addr=2;
reg.opt=1;
reg.data=1;
九、共用体union
共用体(union)是一种特殊的数据类型,它允许在同一个内存区域存储不同的数据类型。与结构体不同的是,共用体只能同时存储其中一个成员的值。
共用体的语法:
union my_union {
int i;
float f;
char str[10];
};
共用体和结构体的区别:
- 结构体所有成员拥有独立的内存空间。
- 共用体的所有成员共享同一块内存空间。
- 共用体的空间是由最大的成员类型决定的。
示例:
#include 输出:
90
成员虽然共享同一块内存空间,但是每个成员能操作的空间的范围是由成员自身类型长度决定的。

十、枚举enum
枚举(enum)是 C++ 中的一种数据类型,它允许将一组常量值定义为一个命名集合。枚举中的每个元素都有一个关联的整数值,默认情况下从 0 开始递增。枚举元素也可以显式地指定整数值。
C++ 中枚举的语法如下:
enum EnumName {
Element1,
Element2 = 10,
Element3
};
在上面的示例中,EnumName 是枚举类型名称,Element1、Element2 和 Element3 是该枚举类型包含的三个元素。其中,第一个元素 Element1 的默认整数值为 0,第二个元素 Element2 显式指定了整数值为 10,因此接下来的元素 Element3 的整数值为 11。
使用枚举可以方便地定义一组相关的常量,并增加代码可读性和可维护性。例如,在编写程序时需要用到颜色常量:
enum Color {
Red,
Green,
Blue
};
int main() {
Color c = Red;
if (c == Green) {
std::cout << "Green\n";
} else if (c == Blue) {
std::cout << "Blue\n";
} else if (c == Red) {
std::cout << "Red\n";
}
}
上面代码中,通过枚举定义了颜色常量,然后在主函数中使用了这些常量。通过枚举,可以清晰地表达颜色的概念,并避免使用无意义的数字常量。
需要注意的是,C++ 中枚举类型占用 4 字节空间,即使只定义了一个元素也是如此。因此,在定义枚举时应该根据实际情况考虑内存占用问题。
总结
-
结构体(struct)。结构体是一种用户自定义的复合数据类型,它由多个不同数据类型的成员组成。结构体中的每个成员可以具有不同的数据类型和长度,并且每个成员都可以单独访问。通过使用结构体,可以方便地表示一个对象或者实体,增加代码可读性和可维护性。
-
共用体(union)。共用体也是一种用户自定义的复合数据类型,它与结构体类似,但所有成员都共享同一个内存空间。也就是说,在任何时刻只能有一个成员被赋值或访问。共用体通常用于需要在不同情况下使用相同内存区域的场景。需要注意的是,由于共用体中所有成员都共享同一个内存空间,因此在使用时应该小心避免出现未定义行为。
-
枚举(enum)。枚举是一种用户自定义的基本数据类型,它由多个命名常量值组成。每个枚举元素都有一个关联的整数值,默认情况下从 0 开始递增。枚举元素也可以显式地指定整数值。使用枚举可以方便地定义一组相关的常量,并增加代码可读性和可维护性。
