【MHA】之 Attention Mask (with back & forward trace) / Causal Mask (with back trace)
文章目录
- 1. Attention Mask or Causal Mask
- 2. Causal Mask (with n_backtrce)
- 3. Attention Mask with backstrace and forwardtrace
- 4. Customized Mask
在multihead attention 中可添加attention mask,对输入进行范围限定,如
因果mask (causal mask):即可限定只看当前点前面的数据,不可看该点之后的数据。从矩阵上看,causal mask类似一个倒三角,下半部分为1,上半部分为0;因果mask带n_backtrace:即可限定每一点尽可最多向前看n_backtrace帧。从矩阵上看,即在上面的倒三角中,再在最左侧截去一部分,使得其为宽度为n_backtrace的斜带1;前后向N帧:即在上述带有n_backtrace的causal mask上,再以同样方式,向前即向右扩展一个宽度为n_backtrace的斜带1;- 类似的,可根据自定义需求,
自行设定mask。
ref:
MHA TFA 的 实现: https://github.com/tensorflow/addons/blob/v0.15.0/tensorflow_addons/layers/multihead_attention.py#L23-L298
1. Attention Mask or Causal Mask
可指定causal参数,来生成普通的attention mask 还是causal mask:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
from tensorflow.keras.layers import Layer, Masking
import tensorflow as tf
class AttentionMask(Layer):
"""
Computes attention mask.
"""
def __init__(self, causal, mask_value=-1e9):
"""
Argument/s:
causal - causal attention mask flag.
mask_value - value used to mask components that aren't to be attended
to (typically -1e9).
"""
super(AttentionMask, self).__init__()
self.causal = causal
self.mask_value = mask_value
if not isinstance(mask_value, float): raise ValueError("Mask value must be a float.")
def call(self, inp):
"""
Compute attention mask.
Argument/s:
inp - used to compute sequence mask.
Returns:
Attention mask.
"""
batch_size = tf.shape(inp)[0]
max_seq_len = tf.shape(inp)[1]
flat_seq_mask = Masking(mask_value=0.0).compute_mask(inp)
seq_mask = self.merge_masks(tf.expand_dims(flat_seq_mask, axis=1), tf.expand_dims(flat_seq_mask, axis=2))
### HERE !!! ###
causal_mask = self.lower_triangular_mask([1, max_seq_len, max_seq_len]) if self.causal else None
################
logical_mask = self.merge_masks(causal_mask, seq_mask)
unmasked = tf.zeros([batch_size, max_seq_len, max_seq_len])
masked = tf.fill([batch_size, max_seq_len, max_seq_len], self.mask_value)
att_mask = tf.where(logical_mask, unmasked, masked)
seq_mask = tf.cast(seq_mask, tf.float32)
return att_mask, seq_mask
def lower_triangular_mask(self, shape):
"""
Creates a lower-triangular boolean mask over the last 2 dimensions.
Argument/s:
shape - shape of mask.
Returns:
causal mask.
"""
row_index = tf.math.cumsum(
tf.ones(shape=shape, dtype=tf.int32, name="row"), axis=-2)
col_index = tf.math.cumsum(
tf.ones(shape=shape, dtype=tf.int32, name="col"), axis=-1)
return tf.math.greater_equal(row_index, col_index)
def merge_masks(self, x, y):
"""
Merges a sequence mask and a causal mask to make an attantion mask.
Argument/s:
x - mask.
y - mask.
Returns:
Attention mask.
"""
if x is None: return y
if y is None: return x
return tf.math.logical_and(x, y)
测试:
if __name__ == '__main__':
input = tf.ones([64, 526, 40])
attention_mask = AttentionMask(causal=0)(input)
causal_mask = AttentionMask(causal=1)(input)
print('done')
实验结果为:

其中attention mask为:
causal mask为:

2. Causal Mask (with n_backtrce)
即带有n_backtrce的因果mask,继承上面的AttentionMask:
from tensorflow.keras.layers import Masking
import tensorflow as tf
from AttentionMask import AttentionMask
class AttentionMask_Causal_Backtrace(AttentionMask):
"""
Computes attention mask appropriate for tf.keras.layers.MultiHeadAttention.
"""
def __init__(self, causal, n_backtrace=None):
"""
Argument/s:
causal - causal attention mask flag.
n_backtrace - (int) number of backtrace
"""
super().__init__(causal)
self.causal = causal
self.n_backtrace = n_backtrace
def call(self, inp):
"""
Compute attention mask.
Argument/s:
inp - used to compute sequence mask.
Returns:
Attention mask.
"""
batch_size = tf.shape(inp)[0]
max_seq_len = tf.shape(inp)[1]
flat_seq_mask = Masking(mask_value=0.0).compute_mask(inp)
seq_mask = self.merge_masks(tf.expand_dims(flat_seq_mask, axis=1), tf.expand_dims(flat_seq_mask, axis=2))
### HERE !!! ###
causal_mask = self.lower_triangular_mask([batch_size, max_seq_len, max_seq_len]) if self.causal else None
bt_mask = self.backtrace_mask([1, max_seq_len, max_seq_len]) \
if self.causal and self.n_backtrace else None
################
logical_mask = self.merge_masks(causal_mask, seq_mask)
logical_mask = self.merge_masks(logical_mask, bt_mask)
att_mask = tf.cast(logical_mask, tf.float32)
att_mask = tf.reshape(att_mask, [batch_size, 1, max_seq_len, max_seq_len])
return att_mask
def backtrace_mask(self, shape):
"""
Creates a lower-triangular boolean mask over the last 2 dimensions.
Argument/s:
shape - shape of mask.
Returns:
causal mask.
"""
row_index = tf.math.cumsum(
tf.ones(shape=shape, dtype=tf.int32, name="row"), axis=-2)
col_index = tf.math.cumsum(
tf.ones(shape=shape, dtype=tf.int32, name="col"), axis=-1)
return tf.math.less_equal(row_index, col_index + self.n_backtrace)
测试:
if __name__ == '__main__':
input = tf.ones([64, 526, 40])
causal_mask = AttentionMask_Causal_Backtrace(causal=1, n_backtrace=None)(input)
causal_mask_backtrace = AttentionMask_Causal_Backtrace(causal=1, n_backtrace=50)(input)
print('done')
实验结果:
其中causal_mask为:


causal_mask_backtrace为:



测试样例2:
causal_mask_backtrace = AttentionMask_Causal_Backtrace(causal=1, n_backtrace=5)(input)
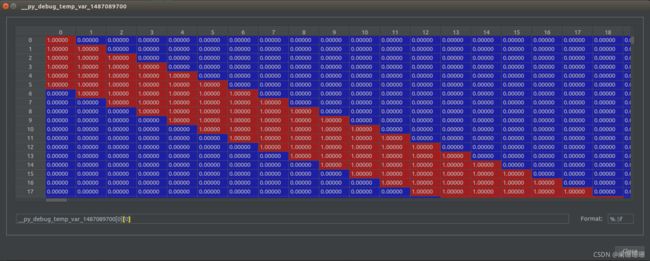
3. Attention Mask with backstrace and forwardtrace
from tensorflow.keras.layers import Masking
import tensorflow as tf
from AttentionMask import AttentionMask
class AttentionMask_Backtrace_Forwardtrace(AttentionMask):
"""
Computes attention mask appropriate for tf.keras.layers.MultiHeadAttention.
"""
def __init__(self, causal, n_backtrace=None, n_forwardtrace=None):
"""
Argument/s:
causal - causal attention mask flag.
n_backtrace - (int) number of backtrace
"""
super().__init__(causal)
self.causal = causal
self.n_backtrace = n_backtrace
self.n_forwardtrace = n_forwardtrace
def call(self, inp):
"""
Compute attention mask.
Argument/s:
inp - used to compute sequence mask.
Returns:
Attention mask.
"""
batch_size = tf.shape(inp)[0]
max_seq_len = tf.shape(inp)[1]
flat_seq_mask = Masking(mask_value=0.0).compute_mask(inp)
seq_mask = self.merge_masks(tf.expand_dims(flat_seq_mask, axis=1), tf.expand_dims(flat_seq_mask, axis=2))
### HERE !!! ###
bt_ft_mask = self.backtrace_forwardtrace_mask([1, max_seq_len, max_seq_len]) \
if self.n_backtrace and self.n_forwardtrace else None
################
logical_mask = self.merge_masks(bt_ft_mask, seq_mask)
att_mask = tf.cast(logical_mask, tf.float32)
att_mask = tf.reshape(att_mask, [batch_size, 1, max_seq_len, max_seq_len])
return att_mask
def backtrace_forwardtrace_mask(self, shape):
"""
Creates a lower-triangular boolean mask over the last 2 dimensions.
Argument/s:
shape - shape of mask.
Returns:
causal mask.
"""
row_index = tf.math.cumsum(
tf.ones(shape=shape, dtype=tf.int32, name="row"), axis=-2)
col_index = tf.math.cumsum(
tf.ones(shape=shape, dtype=tf.int32, name="col"), axis=-1)
bt_mask = tf.math.less_equal(row_index, col_index + self.n_backtrace)
ft_mask = tf.math.greater_equal(row_index + self.n_forwardtrace, col_index)
bt_ft_mask = self.merge_masks(bt_mask, ft_mask)
return bt_ft_mask
测试:
if __name__ == '__main__':
input = tf.ones([64, 526, 40])
bt_ft_mask = AttentionMask_Backtrace_Forwardtrace(causal=0, n_backtrace=2, n_forwardtrace=5)(input)
print('done')
实验结果:

bt_ft_mask为:

4. Customized Mask
class AttentionMask_Customization(AttentionMask):
"""
Computes attention mask appropriate for tf.keras.layers.MultiHeadAttention.
"""
def __init__(self, causal, trace=None):
"""
Argument/s:
causal - causal attention mask flag.
n_backtrace - (int) number of backtrace
"""
super().__init__(causal)
self.causal = causal
self.trace = trace
def call(self, inp):
"""
Compute attention mask.
Argument/s:
inp - used to compute sequence mask.
Returns:
Attention mask.
"""
batch_size = tf.shape(inp)[0]
max_seq_len = tf.shape(inp)[1]
flat_seq_mask = Masking(mask_value=0.0).compute_mask(inp)
seq_mask = self.merge_masks(tf.expand_dims(flat_seq_mask, axis=1), tf.expand_dims(flat_seq_mask, axis=2))
### HERE !!! ###
customized_mask = self.customized_mask(batch_size, max_seq_len, self.trace)
################
logical_mask = self.merge_masks(customized_mask, seq_mask)
att_mask = tf.cast(logical_mask, tf.float32)
att_mask = tf.reshape(att_mask, [batch_size, 1, max_seq_len, max_seq_len])
return att_mask
@tf.function
def customized_mask(self, batchsize, max_length, trace):
mask = tf.ones(shape=[batchsize, trace, trace], dtype=tf.int32, name="row")
shape_pad = int(max_length - trace)
mask = tf.pad(mask, paddings=[[0, 0], [shape_pad, 0], [shape_pad, 0]])
mask = tf.cast(mask, dtype=bool)
return mask
测试:
if __name__ == '__main__':
input = tf.ones([64, 526, 40])
customized_mask = AttentionMask_Customization(causal=1, trace=5)(input)
print('done')
实验结果:
