基于 HTTP Range 实现文件分片并发下载!
目录
前言
基础下载功能
进阶下载功能
单片下载
多片下载
浏览器发送预检(preflight)请求
express 不支持多段 range
multipart/** 搭配 boundary=**
分片下载功能
“只读的” ArrayBuffer 对象
DataView 子类 Uint8Array 操作二进制数据
Blob + createObjectURL 创建 url
全部代码
通用的文件分片下载工具
拿到文件的大小 接口
分片函数
mergeArrayBuffer 函数
全部代码
总结
前言
技术都写在文档里了。有用的文章,值得看第二遍
基础下载功能
下载文件是一个常见的需求,只要服务端设置 Content-Disposition 为 attachment 就可以。
比如这样:
const express = require('express');
const app = express();
app.get('/aaa',(req, res, next) => {
res.setHeader('Content-Disposition','attachment; filename="guang.txt"')
res.end('guangguang');
})
app.listen(3000, () => {
console.log(`server is running at port 3000`)
})设置 Cotent-Disposition 为 attachment,指定 filename。
然后 html 里加一个 a 标签:
download
跑起静态服务器:

点击链接就可以下载:
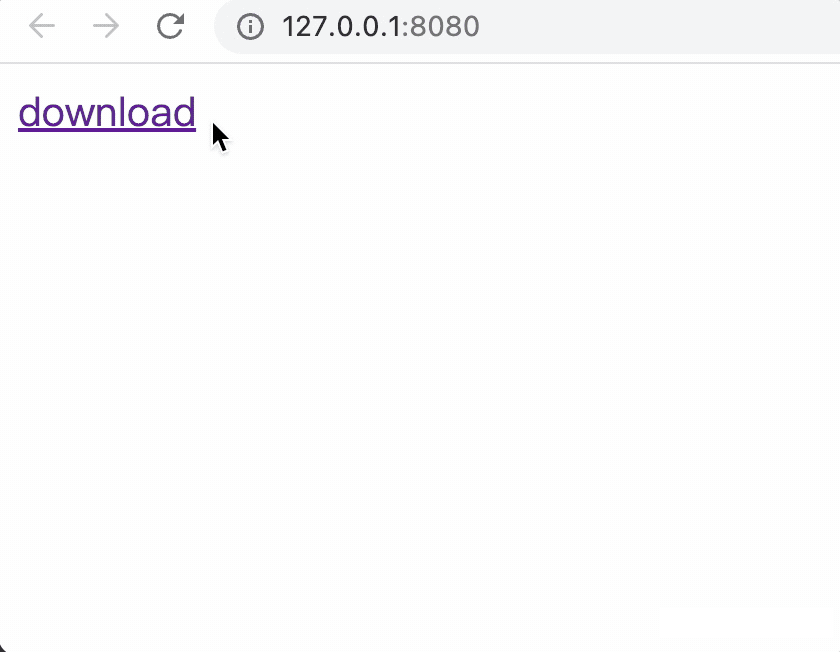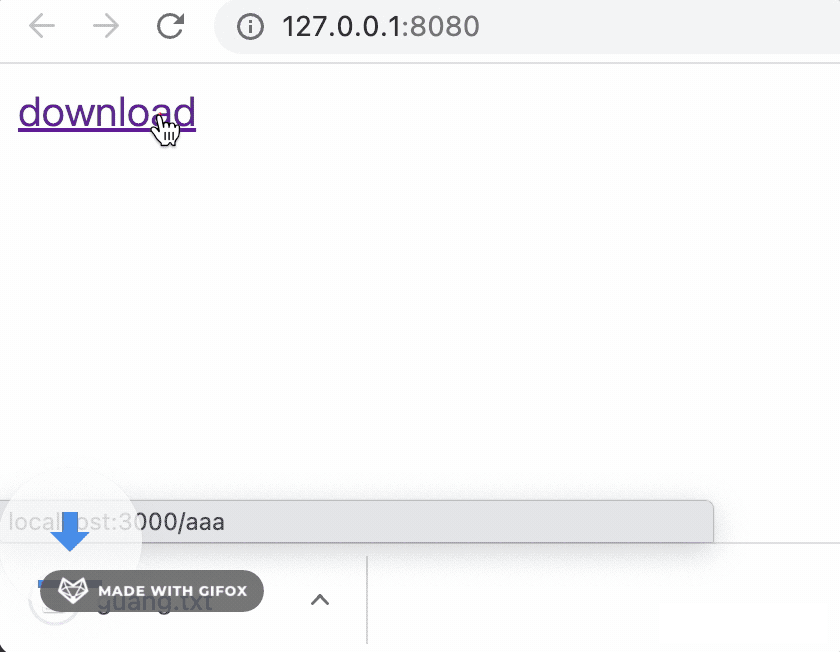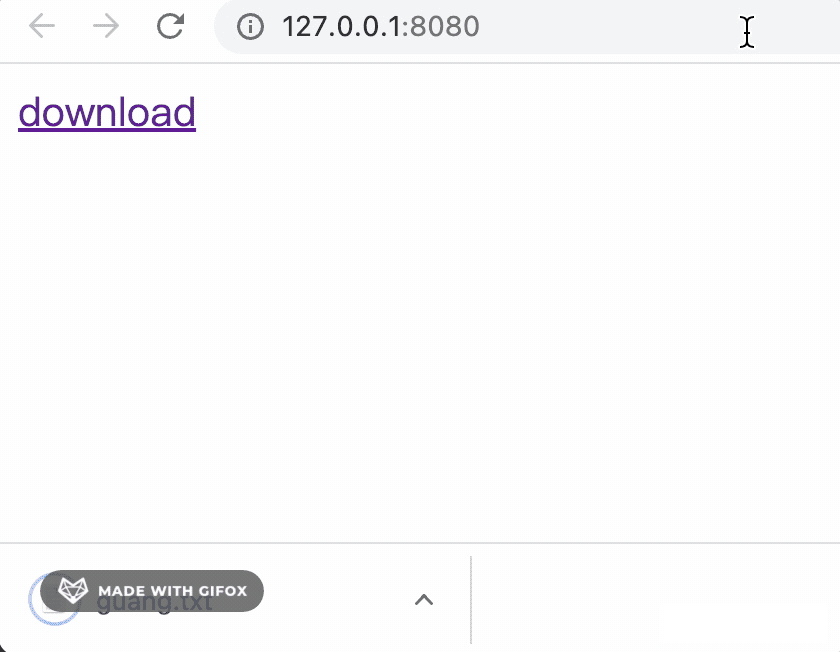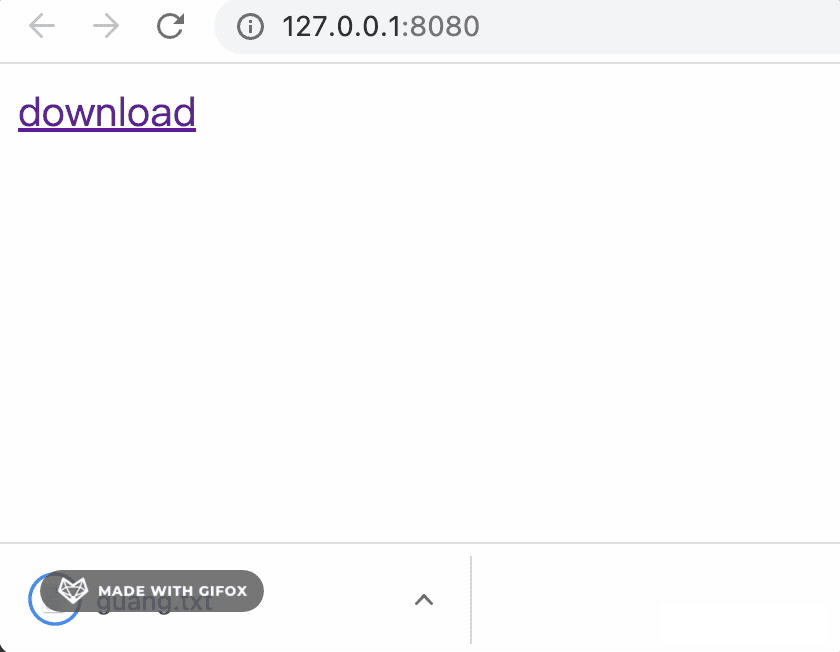

如果文件比较大,比如 500M,当你下载了 499M 的时候突然断网了,这时候下载就失败了,你就要从头再重新下载一次。体验就很不爽。
进阶下载功能
单片下载
能不能基于上次下载的地方接着下载,也就是断点续传呢?可以的,HTTP 里有这部分协议,就是 range 相关的 header。看下 MDN 对 range 的解释:
Range
The Range 是一个请求首部,告知服务器返回文件的哪一部分。在一个 Range 首部中,可以一次性请求多个部分,服务器会以 multipart 文件的形式将其返回。如果服务器返回的是范围响应,需要使用 206 Partial Content 状态码。假如所请求的范围不合法,那么服务器会返回 416 Range Not Satisfiable 状态码,表示客户端错误。服务器允许忽略 Range 首部,从而返回整个文件,状态码用 200 。
就是说你可以通过 Range 的 header 告诉服务端下载哪一部分内容。
比如这样:
Range: bytes=200-1000就是下载 200-1000 字节的内容(两边都是闭区间),服务端返回 206 的状态码,并带上这部分内容。
可以省略右边部分,代表一直到结束:
Range: bytes=200-也可以省略左边部分,代表从头开始:
Range: bytes=-1000而且可以请求多段 range,服务端会返回多段内容:
Range: bytes=200-1000, 2000-6576, 19000-知道了 Range header 的格式,我们来试一下吧!
添加这样一个路由:
app.get('/', (req, res, next) => {
res.setHeader('Access-Control-Allow-Origin', '*');
res.download('index.txt', {
acceptRanges: true
})
})设置允许跨域请求。res.download 是读取文件内容返回,acceptRanges 选项为 true 就是会处理 range 请求(其实默认就是 true)。文件 index.txt 的内容是这样的:

然后在 html 里访问一下这个接口:
访问页面,可以看到返回的是 206 的状态码!
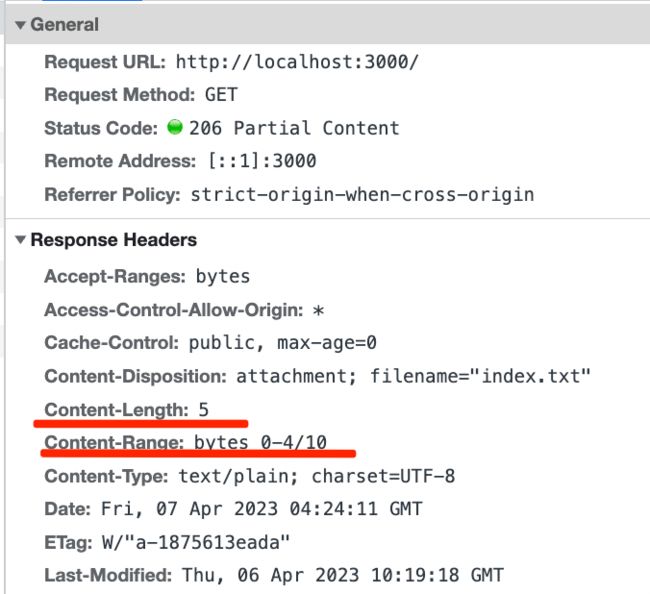
这时候 Content-Length 就代表返回的内容的长度。还有个 Content-Range 代表当前 range 的长度以及总长度。
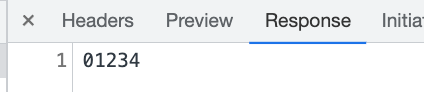
当然,你也可以访问 5 以后的内容
返回的是这样的:
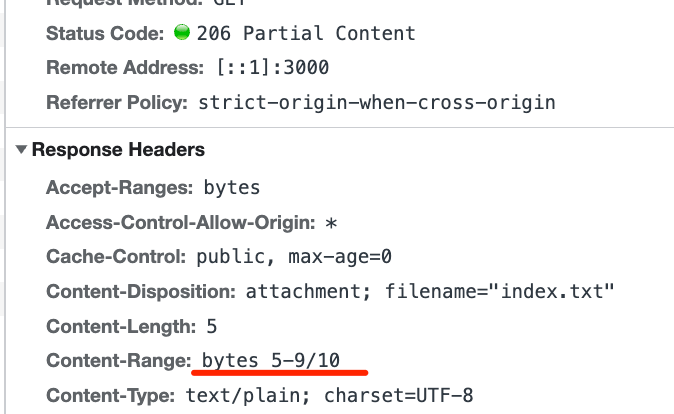

这俩连接起来不就是整个文件的内容么?这样就实现了断点续传!我们再来试试如果超出 range 会怎么样:
请求 500-600 字节的内容,这时候响应是这样的:

多片下载
返回的是 416 状态码,代表 range 不合法。Range 不是还可以设置多段么?多段内容是怎么返回的呢?我们来试一下:
我分了 0-2, 4-5, 7- 这三段 range。重新访问一下,这时候报了一个跨域的错误,说是发送预检请求失败。
![]()
浏览器发送预检(preflight)请求
浏览器会在三种情况下发送预检(preflight)请求:
-
·用到了非 GET、POST 的请求方法,比如 PUT、DELETE 等,会发预检请求看看服务端是否支持
-
·用到了一些非常规请求头,比如用到了 Content-Type,会发预检请求看看服务端是否支持
-
·用到了自定义 header,会发预检请求
为啥 Range 头单个 range 不会触发预检请求,而多个 range 就触发了呢?因为多个 range 的时候返回的 Content-Type 是不一样的,是 multipart/byteranges 类型,比较特殊。预检请求是 options 请求,那我们就支持一下:
app.options('/', (req, res, next) => {
res.setHeader('Access-Control-Allow-Origin', '*');
res.setHeader('Access-Control-Allow-Headers', 'Range')
res.end('');
});然后重新访问:这时候你会发现虽然是 206 状态码,但返回的是整个内容!

express 不支持多段 range
这是因为 express 只做了单 range 的支持,多段 range 可能它觉得没必要支持吧。毕竟你发多个单 range 请求就能达到一样的效果。MDN 官网的图片是支持多 range 请求的,我们用那个看看:

multipart/** 搭配 boundary=**
请求 3 个 range 的内容。可以看到返回的 Content-Type 确实是 multipart/byteranges,然后指定了 boundary 边界线:

响应内容是这样的:
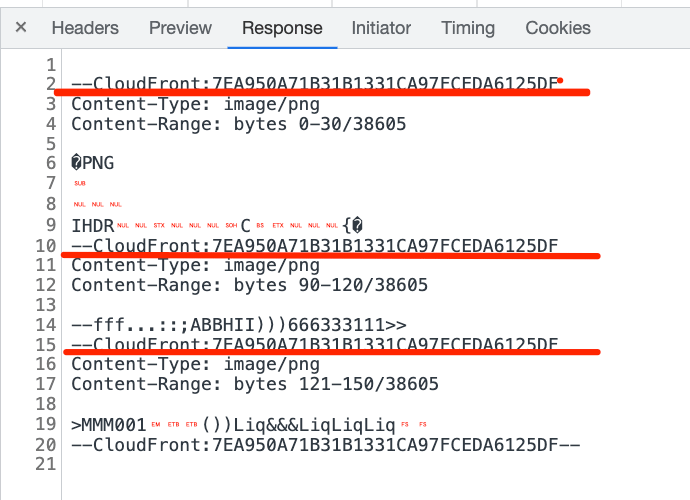
以这些 boundary 分界线隔开的每一段内容都包含 Content-Type、Content-Range 基于具体的那段 range 的内容。这就是 multipart/byteranges 的格式,和我们常用的 multipart/form-data 很类似,只不过具体每段包含的 header 不同:

话说回来,其实 express 只支持单段 range 问题也不大,不就是多发几个请求就能达到一样的效果。
分片下载功能
下面我们就用 range 来实现下文件的分片下载,最终合并成一个文件的功能。我们来下载一个图片吧,分成两块下载,然后下载完合并起来。就用这个图片好了:

app.get('/', (req, res, next) => {
res.setHeader('Access-Control-Allow-Origin', '*');
res.download('guangguang.png', {
acceptRanges: true
})
})我们写下分片下载的代码,就分两段:这个图片是 626k,也就是 626000 字节,那我们就分成 0-300000 和 300001- 两段:
试一下,两个响应分别是这样的:

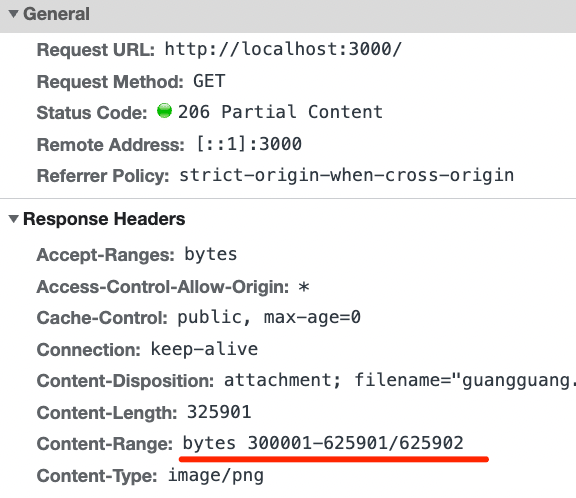
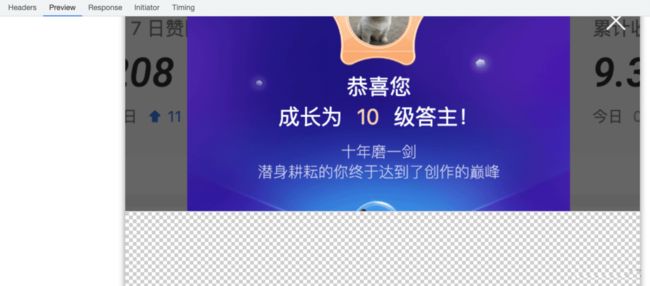
第一个响应还能看到图片的预览,确实只有一部分:
“只读的” ArrayBuffer 对象
然后我们要把两段给拼起来,怎么拼呢?操作二进制数据要用 JS 的 ArrayBuffer api 了:
ArrayBuffer
ArrayBuffer 对象用来表示通用的、固定长度的原始二进制数据缓冲区。
它是一个字节数组,通常在其他语言中称为 “byte array”。你不能直接操作 ArrayBuffer 中的内容;而是要通过类型化数组对象或 DataView 对象来操作,它们会将缓冲区中的数据表示为特定的格式,并通过这些格式来读写缓冲区的内容。
浏览器还有个特有的 Blob api 也是用于操作二进制数据的。我们指定下响应的类型为 arraybuffer:

DataView 子类 Uint8Array 操作二进制数据
两个 ArrayBuffer 怎么合并呢?ArrayBuffer 本身只是存储二进制数据的,要操作二进制数据要使用具体的 DataView 的子类。比如我们想以字节的方式操作,那就是 Uint8Array 的方式(Uint 是 unsigned integer,无符号整数):
Promise.all([p1, p2]).then(res => {
const [buffer1, buffer2] = res;
const arr = new Uint8Array(buffer1.byteLength + buffer2.byteLength);
const arr1 = new Uint8Array(buffer1);
arr.set(arr1, 0);
const arr2 = new Uint8Array(buffer2);
arr.set(arr2, arr1.byteLength);
console.log(arr.buffer)
})每个 arraybuffer 都创建一个对应的 Uint8Array 对象,然后创建一个长度为两者之和的 Uint8Array 对象,把两个 Uint8Array 设置到不同位置。最后输出合并的 Uint8Array 对象的 arraybuffer。这样就完成了合并:

合并之后就是整个图片了。那自然可以作为图片展示,也可以下载。
我添加一个 img 标签:
![]()
Blob + createObjectURL 创建 url
然后把 ArrayBuffer 转成 Blob 设置以对象形式设置为 img 的 url
const blob = new Blob([arr.buffer]);
const url = URL.createObjectURL(blob);
img.src =url;现在就可以看到完整的图片了:
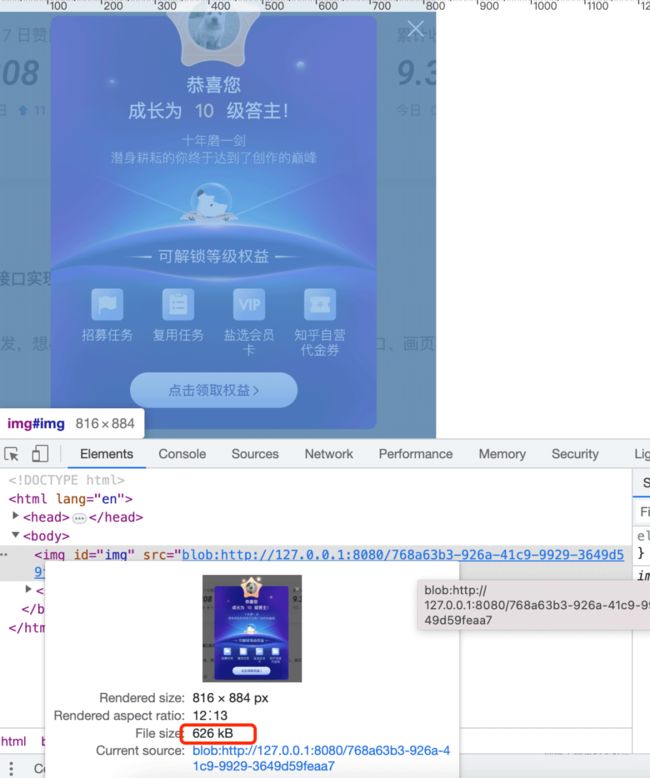
现在我们就实现了文件的分片下载再合并!甚至,你还可以再做一步下载:
const link = document.createElement('a');
link.href = url;
link.download = 'image.png';
document.body.appendChild(link);
link.click();
link.addEventListener('click', () => {
link.remove();
});
全部代码
现在的全部代码如下:
![]()
通用的文件分片下载工具
拿到文件的大小 接口
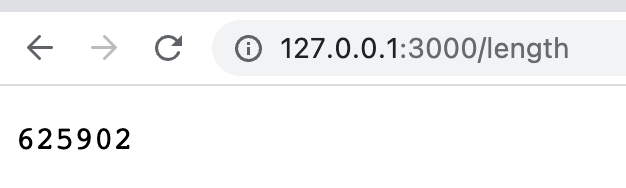
当然,一般不会这么写死来用,我们可以封装一个通用的文件分片下载工具。但分片之前需要拿到文件的大小,所以要增加一个接口:
app.get('/length',(req, res, next) => {
res.setHeader('Access-Control-Allow-Origin', '*');
res.end('' + fs.statSync('./guangguang.png').size);
})请求这个接口,返回文件大小:
分片函数
然后我们来做分片:
async function concurrencyDownload(path, size, chunkSize) {
let chunkNum = Math.ceil(size / chunkSize);
const downloadTask = [];
for(let i = 1; i <= chunkNum; i++) {
const rangeStart = chunkSize * (i - 1);
const rangeEnd = chunkSize * i - 1;
downloadTask.push(axios.get(path, {
headers: {
Range: `bytes=${rangeStart}-${rangeEnd}`,
},
responseType: 'arraybuffer'
}))
}
const arrayBuffers = await Promise.all(downloadTask.map(task => {
return task.then(res => res.data)
}))
return mergeArrayBuffer(arrayBuffers);
}这部分代码不难理解:
·首先根据 chunk 大小来计算一共几个 chunk,通过 Math.ceil 向上取整。
·然后计算每个 chunk 的 range,构造下载任务的 promise。
·Promise.all 等待所有下载完成,之后合并 arraybuffer。
mergeArrayBuffer 函数
这里 arraybuffer 合并也封装了一个 mergeArrayBuffer 的方法:
function mergeArrayBuffer(arrays) {
let totalLen = 0;
for (let arr of arrays) {
totalLen += arr.byteLength;
}
let res = new Uint8Array(totalLen)
let offset = 0
for (let arr of arrays) {
let uint8Arr = new Uint8Array(arr)
res.set(uint8Arr, offset)
offset += arr.byteLength
}
return res.buffer
}就是计算总长度,创建一个大的 Uint8Array,然后把每个 arraybuffer 转成 Uint8Array 设置到对应的位置,之后再转为 arraybuffer 就好了。
我们来测试下:
(async function() {
const { data: len } = await axios.get('http://localhost:3000/length');
const res = await concurrencyDownload('http://localhost:3000', len, 300000);
console.log(res)
const blob = new Blob([res]);
const url = URL.createObjectURL(blob);
img.src =url;
})();调用分片下载的方法,每 300000 字节分一片,应该是可以分 3 片,我们看下结果:



确实,3 个 range 都对了,最后合并的结果也是对的:
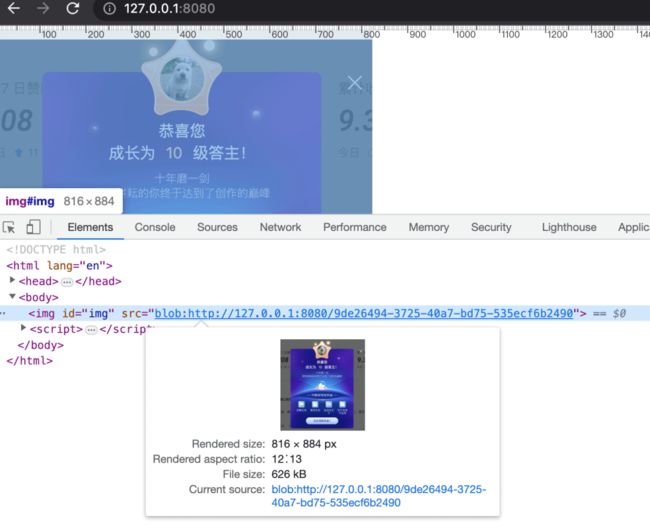
至此,我们就实现了通用的分片下载功能!
全部代码
全部前端代码如下:
![]()
全部后端代码如下:
const express = require('express');
const fs = require('fs');
const app = express();
app.get('/length',(req, res, next) => {
res.setHeader('Access-Control-Allow-Origin', '*');
res.end('' + fs.statSync('./guangguang.png').size);
})
app.options('/', (req, res, next) => {
res.setHeader('Access-Control-Allow-Origin', '*');
res.setHeader('Access-Control-Allow-Headers', 'Range')
res.end('');
});
app.get('/', (req, res, next) => {
res.setHeader('Access-Control-Allow-Origin', '*');
res.download('guangguang.png', {
acceptRanges: true
})
})
app.listen(3000, () => {
console.log(`server is running at port 3000`)
})总结
·文件下载是常见需求,只要设置 Content-Disposition 为 attachment 就可以。
·但大文件的时候,下载中断了再重新传体验不好,或者想实现分片下载再合并的功能,这时候就可以用 Range 了。
·在请求上带上 Range 的范围,如果服务器不支持,就会返回 200 加全部内容。
·如果服务器支持 Range,会返回 206 的状态码和 Content-Range 的 header,表示这段内容的范围和全部内容的总长度。
·如果 Range 超出了,会返回 416 的 状态码。
·多段 Range 的时候,会返回 multipart/byteranges 的格式,类似 multipart/form-data 一样,都是通过 boundary 分割的,每一段都包含 Content-Range 和内容。
·express 不支持多段 range,但我们可以通过发多个请求达到一样的效果。
·我们基于 Range 实现了文件的分片下载,浏览器通过 ArrayBuffer 接收。
·ArrayBuffer 只读,想要操作要通过 Uint8Array 来合并,之后再转为 ArrayBuffer。
·这样就可以通过 URL.createObjectURL 设置为 img 的 src 或者通过 a 标签的 download 属性实现下载了。
·其实分片下载用的还是挺多的,比如看视频的时候,是不是也是一段一段下载的呢?