DataX
文章目录
- 1、概述
-
- 1.1 什么是DataX
- 1.2 DataX的设计
- 1.3 支持的数据源
- 1.4 框架设计
- 1.5 运行原理
- 1.6 与Sqoop对比
- 2、快速入门
-
- 2.1 官方地址
- 2.2 前置要求
- 2.3 安装
- 3、使用案例
-
- 3.1 从 stream 流读取数据并打印到控制台
- 3.2 读取 MySQL 中的数据存放到 HDFS
-
- 3.2.1 查看官方模板
- 3.2.2 数据准备
- 3.2.3 编写配置文件
- 3.2.4 执行任务
- 3.2.5 查看hdfs
- 3.2.6 关于HA的支持
- 3.3 读取HDFS数据写入MySQL
- 4、Oracle数据库
-
- 4.1 oracle 数据库简介
- 4.2 安装前的准备
-
- 4.2.1 安装依赖
- 4.2.2 配置用户组
- 4.2.3 上传安装包并解压
- 4.2.4 修改配置文件 sysctl.conf
- 4.2.5 修改配置文件 limits.conf
- 4.2.6
- 4.3 安装Oracle数据库
-
- 4.3.1 设置环境变量
- 4.3.2 进入虚拟机图像化页面操作
- 4.3.3 安装数据库
- 4.4 设置Oracle监听
-
- 4.4.1 命令行输入以下命令
- 4.4.2 选择添加
- 4.4.3 设置监听名,默认即可
- 4.4.4 选择协议,默认即可
- 4.4.5 设置端口号,默认即可
- 4.4.6 配置更多监听,默认
- 4.4.7 完成
- 4.5 创建数据库
-
- 4.5.1 进入创建页面
- 4.5.2 选择创建数据库
- 4.5.3 选择高级配置
- 4.5.4 选择数据仓库
- 4.5.5 将图中所示对勾去掉
- 4.5.6 存储选项
- 4.5.7 快速恢复选项
- 4.5.8 选择监听程序
- 4.5.9 如图设置
- 4.5.10 使用自动内存管理
- 4.5.11 管理选项,默认
- 4.5.12 设置统一密码
- 4.5.13 创建选项,选择创建数据库
- 4.5.14 概要,点击完成
- 4.5.15 等待安装
- 4.6 简单使用
-
- 4.6.1 开启,关闭监听服务
- 4.6.2 进入命令行
- 4.6.3 创建用户并授权
- 4.6.4 进入 lln 账号,创建表
- 4.7 Oracle 与 MySQL 的 SQL 区别
- 4.8 DataX 案例
-
- 4.8.1 从 Oracle 中读取数据存到 MySQL
- 4.8.2 读取 Oracle 的数据存入 HDFS 中
- 5、MongoDB
-
- 5.1 什么是 MongoDB
- 5.2 MongoDB 优缺点
- 5.3 基础概念解析
- 5.4 安装
-
- 5.4.1 下载地址
- 5.4.2 安装
- 5.5 基础概念详解
-
- 5.5.1 数据库
- 5.5.2 集合
- 5.5.3 文档
- 5.6 读取MongoDB的数据导入到HDFS
-
- 5.6.1 查看官方模板
- 5.6.2 编写配置文件
- 5.6.3 mongodbreader 参数解析
- 5.6.4 执行
- 5.7 读取MongoDB的数据导入MySQL
-
- 5.7.1 在mysql中创建表
- 5.7.2 查看模板
- 5.7.3 编写配置文件
- 5.7.4 执行
- 6、SQLServer
-
- 6.1 什么是 SQLServer
- 6.2 安装
-
- 6.2.1 安装要求
- 6.2.2 安装步骤
- 6.2.3 安装配置
- 6.2.4 安装命令行工具
- 6.3 简单实用
-
- 6.3.1 启停命令
- 6.3.2 创建数据库
- 6.4 DataX导入导出案例
-
- 6.4.1 数据准备
- 6.4.2 读取 SQLServer 的数据导入到 HDFS
- 6.4.2 读取 SQLServer 的数据导入 MySQL
- 7、DB2
-
- 7.1 什么是db2
- 7.2 db2 数据库对象关系
- 7.3 安装前的准备
-
- 7.3.1 安装依赖
- 7.3.2 修改配置文件 sysctl.conf
- 7.3.3 修改配置文件 limits.conf
- 7.3.4 上传安装包并解压
- 7.4 安装
- 7.5 DataX 导入导出案例
-
- 7.5.1 注册 db2 驱动
- 7.5.2 读取 DB2 的数据导入到 HDFS
- 7.5.3 读取 DB2 的数据导入 MySQL
1、概述
1.1 什么是DataX
DataX 是阿里巴巴开源的一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle 等)、HDFS、Hive、ODPS、HBase、FTP 等各种异构数据源之间稳定高效的数据同步功能。

1.2 DataX的设计
为了解决异构数据源同步问题,DataX 将复杂的网状的同步链路变成了星型数据链路,DataX 作为中间传输载体负责连接各种数据源。当需要接入一个新的数据源的时候,只需要将此数据源对接到 DataX,便能跟已有的数据源做到无缝数据同步。

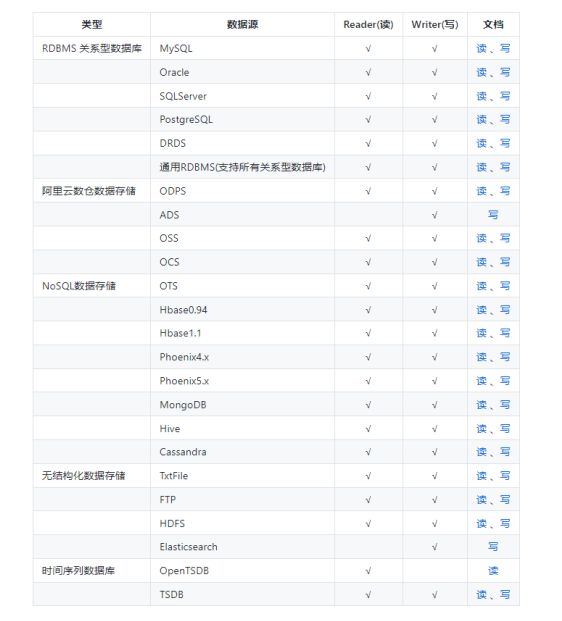
1.3 支持的数据源
DataX 目前已经有了比较全面的插件体系,主流的 RDBMS 数据库、NOSQL、大数据计算系统都已经接入。
1.4 框架设计

1.5 运行原理


1.6 与Sqoop对比

2、快速入门
2.1 官方地址
下载地址:http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz
源码地址:https://github.com/alibaba/DataX
2.2 前置要求
- Linux
- JDK(1.8 以上,推荐 1.8)
- Python(推荐 Python2.6.X)
2.3 安装
1)将下载好的 datax.tar.gz 上传到 hadoop102 的/opt/software
2)解压 datax.tar.gz 到/opt/module
[atguigu@hadoop102 software]$ tar -zxvf datax.tar.gz -C /opt/module/
3)运行自检脚本
[atguigu@hadoop102 bin]$ cd /opt/module/datax/bin/
[atguigu@hadoop102 bin]$ python datax.py /opt/module/datax/job/job.json
3、使用案例
3.1 从 stream 流读取数据并打印到控制台
1)查看配置模板
[lln@hadoop102 bin]$ python datax.py -r streamreader -w streamwriter
DataX (DATAX-OPENSOURCE-3.0), From Alibaba !
Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved.
Please refer to the streamreader document:
https://github.com/alibaba/DataX/blob/master/streamreader/doc/streamreader.md
Please refer to the streamwriter document:
https://github.com/alibaba/DataX/blob/master/streamwriter/doc/streamwriter.md
Please save the following configuration as a json file and use
python {DATAX_HOME}/bin/datax.py {JSON_FILE_NAME}.json
to run the job.
{
"job": {
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"column": [],
"sliceRecordCount": ""
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"encoding": "",
"print": true
}
}
}
],
"setting": {
"speed": {
"channel": ""
}
}
}
}
2)根据模板编写配置文件
[lln@hadoop102 job]$ vim stream2stream.json
填写以下内容:
{
"job": {
"content": [{
"reader": {
"name": "streamreader",
"parameter": {
"sliceRecordCount": 10,
"column": [{
"type": "long",
"value": "10"
},
{
"type": "string",
"value": "hello,DataX"
}
]
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"encoding": "UTF-8",
"print": true
}
}
}],
"setting": {
"speed": {
"channel": 1
}
}
}
}
3)运行
[lln@hadoop102 job]$ /opt/module/datax/bin/datax.py /opt/module/datax/job/stream2stream.json
DataX (DATAX-OPENSOURCE-3.0), From Alibaba !
Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved.
2023-06-05 14:06:00.124 [main] INFO VMInfo - VMInfo# operatingSystem class => sun.management.OperatingSystemImpl
2023-06-05 14:06:00.139 [main] INFO Engine - the machine info =>
osInfo: Oracle Corporation 1.8 25.212-b10
jvmInfo: Linux amd64 3.10.0-862.el7.x86_64
cpu num: 2
totalPhysicalMemory: -0.00G
freePhysicalMemory: -0.00G
maxFileDescriptorCount: -1
currentOpenFileDescriptorCount: -1
GC Names [PS MarkSweep, PS Scavenge]
MEMORY_NAME | allocation_size | init_size
PS Eden Space | 256.00MB | 256.00MB
Code Cache | 240.00MB | 2.44MB
Compressed Class Space | 1,024.00MB | 0.00MB
PS Survivor Space | 42.50MB | 42.50MB
PS Old Gen | 683.00MB | 683.00MB
Metaspace | -0.00MB | 0.00MB
2023-06-05 14:06:00.164 [main] INFO Engine -
{
"content":[
{
"reader":{
"name":"streamreader",
"parameter":{
"column":[
{
"type":"long",
"value":"10"
},
{
"type":"string",
"value":"hello,DataX"
}
],
"sliceRecordCount":10
}
},
"writer":{
"name":"streamwriter",
"parameter":{
"encoding":"UTF-8",
"print":true
}
}
}
],
"setting":{
"speed":{
"channel":1
}
}
}
2023-06-05 14:06:00.209 [main] WARN Engine - prioriy set to 0, because NumberFormatException, the value is: null
2023-06-05 14:06:00.212 [main] INFO PerfTrace - PerfTrace traceId=job_-1, isEnable=false, priority=0
2023-06-05 14:06:00.213 [main] INFO JobContainer - DataX jobContainer starts job.
2023-06-05 14:06:00.214 [main] INFO JobContainer - Set jobId = 0
2023-06-05 14:06:00.244 [job-0] INFO JobContainer - jobContainer starts to do prepare ...
2023-06-05 14:06:00.245 [job-0] INFO JobContainer - DataX Reader.Job [streamreader] do prepare work .
2023-06-05 14:06:00.245 [job-0] INFO JobContainer - DataX Writer.Job [streamwriter] do prepare work .
2023-06-05 14:06:00.245 [job-0] INFO JobContainer - jobContainer starts to do split ...
2023-06-05 14:06:00.245 [job-0] INFO JobContainer - Job set Channel-Number to 1 channels.
2023-06-05 14:06:00.246 [job-0] INFO JobContainer - DataX Reader.Job [streamreader] splits to [1] tasks.
2023-06-05 14:06:00.246 [job-0] INFO JobContainer - DataX Writer.Job [streamwriter] splits to [1] tasks.
2023-06-05 14:06:00.274 [job-0] INFO JobContainer - jobContainer starts to do schedule ...
2023-06-05 14:06:00.280 [job-0] INFO JobContainer - Scheduler starts [1] taskGroups.
2023-06-05 14:06:00.284 [job-0] INFO JobContainer - Running by standalone Mode.
2023-06-05 14:06:00.307 [taskGroup-0] INFO TaskGroupContainer - taskGroupId=[0] start [1] channels for [1] tasks.
2023-06-05 14:06:00.316 [taskGroup-0] INFO Channel - Channel set byte_speed_limit to -1, No bps activated.
2023-06-05 14:06:00.316 [taskGroup-0] INFO Channel - Channel set record_speed_limit to -1, No tps activated.
2023-06-05 14:06:00.345 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[0] attemptCount[1] is started
10 hello,DataX
10 hello,DataX
10 hello,DataX
10 hello,DataX
10 hello,DataX
10 hello,DataX
10 hello,DataX
10 hello,DataX
10 hello,DataX
10 hello,DataX
2023-06-05 14:06:00.446 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[0] is successed, used[109]ms
2023-06-05 14:06:00.447 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] completed it's tasks.
2023-06-05 14:06:10.325 [job-0] INFO StandAloneJobContainerCommunicator - Total 10 records, 130 bytes | Speed 13B/s, 1 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.000s | All Task WaitReaderTime 0.000s | Percentage 100.00%
2023-06-05 14:06:10.326 [job-0] INFO AbstractScheduler - Scheduler accomplished all tasks.
2023-06-05 14:06:10.327 [job-0] INFO JobContainer - DataX Writer.Job [streamwriter] do post work.
2023-06-05 14:06:10.327 [job-0] INFO JobContainer - DataX Reader.Job [streamreader] do post work.
2023-06-05 14:06:10.328 [job-0] INFO JobContainer - DataX jobId [0] completed successfully.
2023-06-05 14:06:10.329 [job-0] INFO HookInvoker - No hook invoked, because base dir not exists or is a file: /opt/module/datax/hook
2023-06-05 14:06:10.337 [job-0] INFO JobContainer -
[total cpu info] =>
averageCpu | maxDeltaCpu | minDeltaCpu
-1.00% | -1.00% | -1.00%
[total gc info] =>
NAME | totalGCCount | maxDeltaGCCount | minDeltaGCCount | totalGCTime | maxDeltaGCTime | minDeltaGCTime
PS MarkSweep | 0 | 0 | 0 | 0.000s | 0.000s | 0.000s
PS Scavenge | 0 | 0 | 0 | 0.000s | 0.000s | 0.000s
2023-06-05 14:06:10.337 [job-0] INFO JobContainer - PerfTrace not enable!
2023-06-05 14:06:10.337 [job-0] INFO StandAloneJobContainerCommunicator - Total 10 records, 130 bytes | Speed 13B/s, 1 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.000s | All Task WaitReaderTime 0.000s | Percentage 100.00%
2023-06-05 14:06:10.342 [job-0] INFO JobContainer -
任务启动时刻 : 2023-06-05 14:06:00
任务结束时刻 : 2023-06-05 14:06:10
任务总计耗时 : 10s
任务平均流量 : 13B/s
记录写入速度 : 1rec/s
读出记录总数 : 10
读写失败总数 : 0
3.2 读取 MySQL 中的数据存放到 HDFS
3.2.1 查看官方模板
[lln@hadoop102 job]$ python /opt/module/datax/bin/datax.py -r mysqlreader -w hdfswriter
DataX (DATAX-OPENSOURCE-3.0), From Alibaba !
Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved.
Please refer to the mysqlreader document:
https://github.com/alibaba/DataX/blob/master/mysqlreader/doc/mysqlreader.md
Please refer to the hdfswriter document:
https://github.com/alibaba/DataX/blob/master/hdfswriter/doc/hdfswriter.md
Please save the following configuration as a json file and use
python {DATAX_HOME}/bin/datax.py {JSON_FILE_NAME}.json
to run the job.
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [],
"connection": [
{
"jdbcUrl": [],
"table": []
}
],
"password": "",
"username": "",
"where": ""
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [],
"compress": "",
"defaultFS": "",
"fieldDelimiter": "",
"fileName": "",
"fileType": "",
"path": "",
"writeMode": ""
}
}
}
],
"setting": {
"speed": {
"channel": ""
}
}
}
}
mysqlreader 参数解析:

hdfswriter 参数解析:

3.2.2 数据准备
1)创建 student 表
mysql> create database datax;
mysql> use datax;
mysql> create table student(id int,name varchar(20));
2)插入数据
mysql> insert into student values(1001,'zhangsan'),(1002,'lisi'),(1003,'wangwu');
3.2.3 编写配置文件
[lln@hadoop102 job]$ vim /opt/module/datax/job/mysql2hdfs.json
{
"job": {
"content": [{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [
"id",
"name"
],
"connection": [{
"jdbcUrl": ["jdbc:mysql://hadoop102:3306/datax"],
"table": ["student"]
}],
"password": "root",
"username": "root",
"where": ""
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [{
"name": "id",
"type": "int"
},
{
"name": "name",
"type": "string"
}
],
"compress": "",
"defaultFS": "hdfs://hadoop102:8020",
"fieldDelimiter": "\t",
"fileName": "student.txt",
"fileType": "text",
"path": "/",
"writeMode": "append"
}
}
}],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
3.2.4 执行任务
[lln@hadoop102 datax]$ bin/datax.py job/mysql2hdfs.json
DataX (DATAX-OPENSOURCE-3.0), From Alibaba !
Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved.
2023-06-05 23:11:47.265 [main] INFO VMInfo - VMInfo# operatingSystem class => sun.management.OperatingSystemImpl
2023-06-05 23:11:47.332 [main] INFO Engine - the machine info =>
osInfo: Oracle Corporation 1.8 25.212-b10
jvmInfo: Linux amd64 3.10.0-862.el7.x86_64
cpu num: 2
totalPhysicalMemory: -0.00G
freePhysicalMemory: -0.00G
maxFileDescriptorCount: -1
currentOpenFileDescriptorCount: -1
GC Names [PS MarkSweep, PS Scavenge]
MEMORY_NAME | allocation_size | init_size
PS Eden Space | 256.00MB | 256.00MB
Code Cache | 240.00MB | 2.44MB
Compressed Class Space | 1,024.00MB | 0.00MB
PS Survivor Space | 42.50MB | 42.50MB
PS Old Gen | 683.00MB | 683.00MB
Metaspace | -0.00MB | 0.00MB
2023-06-05 23:11:47.384 [main] INFO Engine -
{
"content":[
{
"reader":{
"name":"mysqlreader",
"parameter":{
"column":[
"id",
"name"
],
"connection":[
{
"jdbcUrl":[
"jdbc:mysql://hadoop102:3306/datax"
],
"table":[
"student"
]
}
],
"password":"****",
"username":"root",
"where":""
}
},
"writer":{
"name":"hdfswriter",
"parameter":{
"column":[
{
"name":"id",
"type":"int"
},
{
"name":"name",
"type":"string"
}
],
"compress":"",
"defaultFS":"hdfs://hadoop102:8020",
"fieldDelimiter":"\t",
"fileName":"student.txt",
"fileType":"text",
"path":"/",
"writeMode":"append"
}
}
}
],
"setting":{
"speed":{
"channel":"1"
}
}
}
2023-06-05 23:11:47.467 [main] WARN Engine - prioriy set to 0, because NumberFormatException, the value is: null
2023-06-05 23:11:47.473 [main] INFO PerfTrace - PerfTrace traceId=job_-1, isEnable=false, priority=0
2023-06-05 23:11:47.474 [main] INFO JobContainer - DataX jobContainer starts job.
2023-06-05 23:11:47.477 [main] INFO JobContainer - Set jobId = 0
2023-06-05 23:11:48.471 [job-0] INFO OriginalConfPretreatmentUtil - Available jdbcUrl:jdbc:mysql://hadoop102:3306/datax?yearIsDateType=false&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false&rewriteBatchedStatements=true.
2023-06-05 23:11:48.664 [job-0] INFO OriginalConfPretreatmentUtil - table:[student] has columns:[id,name].
六月 05, 2023 11:11:49 下午 org.apache.hadoop.util.NativeCodeLoader
警告: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2023-06-05 23:11:51.886 [job-0] INFO JobContainer - jobContainer starts to do prepare ...
2023-06-05 23:11:51.887 [job-0] INFO JobContainer - DataX Reader.Job [mysqlreader] do prepare work .
2023-06-05 23:11:51.887 [job-0] INFO JobContainer - DataX Writer.Job [hdfswriter] do prepare work .
2023-06-05 23:11:52.168 [job-0] INFO HdfsWriter$Job - 由于您配置了writeMode append, 写入前不做清理工作, [/] 目录下写入相应文件名前缀 [student.txt] 的文件
2023-06-05 23:11:52.168 [job-0] INFO JobContainer - jobContainer starts to do split ...
2023-06-05 23:11:52.169 [job-0] INFO JobContainer - Job set Channel-Number to 1 channels.
2023-06-05 23:11:52.180 [job-0] INFO JobContainer - DataX Reader.Job [mysqlreader] splits to [1] tasks.
2023-06-05 23:11:52.181 [job-0] INFO HdfsWriter$Job - begin do split...
2023-06-05 23:11:52.213 [job-0] INFO HdfsWriter$Job - splited write file name:[hdfs://hadoop102:8020/__26c0b063_cefe_404e_9c95_a5573dfb7c59/student.txt__b1928b9a_946d_49e3_b4cc_1929c8d7d761]
2023-06-05 23:11:52.213 [job-0] INFO HdfsWriter$Job - end do split.
2023-06-05 23:11:52.213 [job-0] INFO JobContainer - DataX Writer.Job [hdfswriter] splits to [1] tasks.
2023-06-05 23:11:52.239 [job-0] INFO JobContainer - jobContainer starts to do schedule ...
2023-06-05 23:11:52.242 [job-0] INFO JobContainer - Scheduler starts [1] taskGroups.
2023-06-05 23:11:52.246 [job-0] INFO JobContainer - Running by standalone Mode.
2023-06-05 23:11:52.255 [taskGroup-0] INFO TaskGroupContainer - taskGroupId=[0] start [1] channels for [1] tasks.
2023-06-05 23:11:52.262 [taskGroup-0] INFO Channel - Channel set byte_speed_limit to -1, No bps activated.
2023-06-05 23:11:52.262 [taskGroup-0] INFO Channel - Channel set record_speed_limit to -1, No tps activated.
2023-06-05 23:11:52.287 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[0] attemptCount[1] is started
2023-06-05 23:11:52.293 [0-0-0-reader] INFO CommonRdbmsReader$Task - Begin to read record by Sql: [select id,name from student
] jdbcUrl:[jdbc:mysql://hadoop102:3306/datax?yearIsDateType=false&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false&rewriteBatchedStatements=true].
2023-06-05 23:11:52.484 [0-0-0-writer] INFO HdfsWriter$Task - begin do write...
2023-06-05 23:11:52.485 [0-0-0-writer] INFO HdfsWriter$Task - write to file : [hdfs://hadoop102:8020/__26c0b063_cefe_404e_9c95_a5573dfb7c59/student.txt__b1928b9a_946d_49e3_b4cc_1929c8d7d761]
2023-06-05 23:11:52.538 [0-0-0-reader] INFO CommonRdbmsReader$Task - Finished read record by Sql: [select id,name from student
] jdbcUrl:[jdbc:mysql://hadoop102:3306/datax?yearIsDateType=false&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false&rewriteBatchedStatements=true].
2023-06-05 23:11:53.426 [0-0-0-writer] INFO HdfsWriter$Task - end do write
2023-06-05 23:11:53.510 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[0] is successed, used[1225]ms
2023-06-05 23:11:53.510 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] completed it's tasks.
2023-06-05 23:12:02.278 [job-0] INFO StandAloneJobContainerCommunicator - Total 3 records, 30 bytes | Speed 3B/s, 0 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.000s | All Task WaitReaderTime 0.000s | Percentage 100.00%
2023-06-05 23:12:02.279 [job-0] INFO AbstractScheduler - Scheduler accomplished all tasks.
2023-06-05 23:12:02.280 [job-0] INFO JobContainer - DataX Writer.Job [hdfswriter] do post work.
2023-06-05 23:12:02.280 [job-0] INFO HdfsWriter$Job - start rename file [hdfs://hadoop102:8020/__26c0b063_cefe_404e_9c95_a5573dfb7c59/student.txt__b1928b9a_946d_49e3_b4cc_1929c8d7d761] to file [hdfs://hadoop102:8020/student.txt__b1928b9a_946d_49e3_b4cc_1929c8d7d761].
2023-06-05 23:12:02.330 [job-0] INFO HdfsWriter$Job - finish rename file [hdfs://hadoop102:8020/__26c0b063_cefe_404e_9c95_a5573dfb7c59/student.txt__b1928b9a_946d_49e3_b4cc_1929c8d7d761] to file [hdfs://hadoop102:8020/student.txt__b1928b9a_946d_49e3_b4cc_1929c8d7d761].
2023-06-05 23:12:02.330 [job-0] INFO HdfsWriter$Job - start delete tmp dir [hdfs://hadoop102:8020/__26c0b063_cefe_404e_9c95_a5573dfb7c59] .
2023-06-05 23:12:02.362 [job-0] INFO HdfsWriter$Job - finish delete tmp dir [hdfs://hadoop102:8020/__26c0b063_cefe_404e_9c95_a5573dfb7c59] .
2023-06-05 23:12:02.363 [job-0] INFO JobContainer - DataX Reader.Job [mysqlreader] do post work.
2023-06-05 23:12:02.363 [job-0] INFO JobContainer - DataX jobId [0] completed successfully.
2023-06-05 23:12:02.364 [job-0] INFO HookInvoker - No hook invoked, because base dir not exists or is a file: /opt/module/datax/hook
2023-06-05 23:12:02.477 [job-0] INFO JobContainer -
[total cpu info] =>
averageCpu | maxDeltaCpu | minDeltaCpu
-1.00% | -1.00% | -1.00%
[total gc info] =>
NAME | totalGCCount | maxDeltaGCCount | minDeltaGCCount | totalGCTime | maxDeltaGCTime | minDeltaGCTime
PS MarkSweep | 1 | 1 | 1 | 0.142s | 0.142s | 0.142s
PS Scavenge | 1 | 1 | 1 | 0.060s | 0.060s | 0.060s
2023-06-05 23:12:02.477 [job-0] INFO JobContainer - PerfTrace not enable!
2023-06-05 23:12:02.477 [job-0] INFO StandAloneJobContainerCommunicator - Total 3 records, 30 bytes | Speed 3B/s, 0 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.000s | All Task WaitReaderTime 0.000s | Percentage 100.00%
2023-06-05 23:12:02.483 [job-0] INFO JobContainer -
任务启动时刻 : 2023-06-05 23:11:47
任务结束时刻 : 2023-06-05 23:12:02
任务总计耗时 : 14s
任务平均流量 : 3B/s
记录写入速度 : 0rec/s
读出记录总数 : 3
读写失败总数 : 0
3.2.5 查看hdfs

3.2.6 关于HA的支持
在配置文件后追加
"hadoopConfig": {
"dfs.nameservices": "ns",
"dfs.ha.namenodes.ns": "nn1,nn2",
"dfs.namenode.rpc-address.ns.nn1": "主机名:端口",
"dfs.namenode.rpc-address.ns.nn2": "主机名:端口",
"dfs.client.failover.proxy.provider.ns": "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider"
}
3.3 读取HDFS数据写入MySQL
1)将上个案例上传的文件改名
[lln@hadoop102 datax]$ hadoop fs -mv /student.txt__b1928b9a_946d_49e3_b4cc_1929c8d7d761 /student.txt
2)查看官方模板
[lln@hadoop102 datax]$ python bin/datax.py -r hdfsreader -w mysqlwriter
DataX (DATAX-OPENSOURCE-3.0), From Alibaba !
Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved.
Please refer to the hdfsreader document:
https://github.com/alibaba/DataX/blob/master/hdfsreader/doc/hdfsreader.md
Please refer to the mysqlwriter document:
https://github.com/alibaba/DataX/blob/master/mysqlwriter/doc/mysqlwriter.md
Please save the following configuration as a json file and use
python {DATAX_HOME}/bin/datax.py {JSON_FILE_NAME}.json
to run the job.
{
"job": {
"content": [
{
"reader": {
"name": "hdfsreader",
"parameter": {
"column": [],
"defaultFS": "",
"encoding": "UTF-8",
"fieldDelimiter": ",",
"fileType": "orc",
"path": ""
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": [],
"connection": [
{
"jdbcUrl": "",
"table": []
}
],
"password": "",
"preSql": [],
"session": [],
"username": "",
"writeMode": ""
}
}
}
],
"setting": {
"speed": {
"channel": ""
}
}
}
}
3)创建配置文件
[lln@hadoop102 datax]$ vim job/hdfs2mysql.json
{
"job": {
"content": [{
"reader": {
"name": "hdfsreader",
"parameter": {
"column": ["*"],
"defaultFS": "hdfs://hadoop102:8020",
"encoding": "UTF-8",
"fieldDelimiter": "\t",
"fileType": "text",
"path": "/student.txt"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": [
"id",
"name"
],
"connection": [{
"jdbcUrl": "jdbc:mysql://hadoop102:3306/datax",
"table": ["student2"]
}],
"password": "root",
"preSql": [],
"session": [],
"username": "root",
"writeMode": "insert"
}
}
}],
"setting": {
"speed": {
"channel": ""
}
}
}
}
4)在 MySQL 的 datax 数据库中创建 student2
mysql> use datax;
mysql> create table student2(id int,name varchar(20));
5)执行任务
[atguigu@hadoop102 datax]$ bin/datax.py job/hdfs2mysql.json
[lln@hadoop102 datax]$ bin/datax.py job/hdfs2mysql.json
DataX (DATAX-OPENSOURCE-3.0), From Alibaba !
Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved.
2023-06-05 23:44:06.188 [main] INFO VMInfo - VMInfo# operatingSystem class => sun.management.OperatingSystemImpl
2023-06-05 23:44:06.201 [main] INFO Engine - the machine info =>
osInfo: Oracle Corporation 1.8 25.212-b10
jvmInfo: Linux amd64 3.10.0-862.el7.x86_64
cpu num: 2
totalPhysicalMemory: -0.00G
freePhysicalMemory: -0.00G
maxFileDescriptorCount: -1
currentOpenFileDescriptorCount: -1
GC Names [PS MarkSweep, PS Scavenge]
MEMORY_NAME | allocation_size | init_size
PS Eden Space | 256.00MB | 256.00MB
Code Cache | 240.00MB | 2.44MB
Compressed Class Space | 1,024.00MB | 0.00MB
PS Survivor Space | 42.50MB | 42.50MB
PS Old Gen | 683.00MB | 683.00MB
Metaspace | -0.00MB | 0.00MB
2023-06-05 23:44:06.224 [main] INFO Engine -
{
"content":[
{
"reader":{
"name":"hdfsreader",
"parameter":{
"column":[
"*"
],
"defaultFS":"hdfs://hadoop102:8020",
"encoding":"UTF-8",
"fieldDelimiter":"\t",
"fileType":"text",
"path":"/student.txt"
}
},
"writer":{
"name":"mysqlwriter",
"parameter":{
"column":[
"id",
"name"
],
"connection":[
{
"jdbcUrl":"jdbc:mysql://hadoop102:3306/datax",
"table":[
"student2"
]
}
],
"password":"****",
"preSql":[],
"session":[],
"username":"root",
"writeMode":"insert"
}
}
}
],
"setting":{
"speed":{
"channel":"1"
}
}
}
2023-06-05 23:44:06.254 [main] WARN Engine - prioriy set to 0, because NumberFormatException, the value is: null
2023-06-05 23:44:06.257 [main] INFO PerfTrace - PerfTrace traceId=job_-1, isEnable=false, priority=0
2023-06-05 23:44:06.257 [main] INFO JobContainer - DataX jobContainer starts job.
2023-06-05 23:44:06.258 [main] INFO JobContainer - Set jobId = 0
2023-06-05 23:44:06.271 [job-0] INFO HdfsReader$Job - init() begin...
2023-06-05 23:44:06.814 [job-0] INFO HdfsReader$Job - hadoopConfig details:{"finalParameters":[]}
2023-06-05 23:44:06.814 [job-0] INFO HdfsReader$Job - init() ok and end...
2023-06-05 23:44:07.212 [job-0] INFO OriginalConfPretreatmentUtil - table:[student2] all columns:[
id,name
].
2023-06-05 23:44:07.232 [job-0] INFO OriginalConfPretreatmentUtil - Write data [
insert INTO %s (id,name) VALUES(?,?)
], which jdbcUrl like:[jdbc:mysql://hadoop102:3306/datax?yearIsDateType=false&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false&rewriteBatchedStatements=true]
2023-06-05 23:44:07.233 [job-0] INFO JobContainer - jobContainer starts to do prepare ...
2023-06-05 23:44:07.233 [job-0] INFO JobContainer - DataX Reader.Job [hdfsreader] do prepare work .
2023-06-05 23:44:07.233 [job-0] INFO HdfsReader$Job - prepare(), start to getAllFiles...
2023-06-05 23:44:07.233 [job-0] INFO HdfsReader$Job - get HDFS all files in path = [/student.txt]
六月 05, 2023 11:44:07 下午 org.apache.hadoop.util.NativeCodeLoader
警告: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2023-06-05 23:44:08.786 [job-0] INFO HdfsReader$Job - [hdfs://hadoop102:8020/student.txt]是[text]类型的文件, 将该文件加入source files列表
2023-06-05 23:44:08.790 [job-0] INFO HdfsReader$Job - 您即将读取的文件数为: [1], 列表为: [hdfs://hadoop102:8020/student.txt]
2023-06-05 23:44:08.791 [job-0] INFO JobContainer - DataX Writer.Job [mysqlwriter] do prepare work .
2023-06-05 23:44:08.791 [job-0] INFO JobContainer - jobContainer starts to do split ...
2023-06-05 23:44:08.791 [job-0] INFO JobContainer - Job set Channel-Number to 1 channels.
2023-06-05 23:44:08.791 [job-0] INFO HdfsReader$Job - split() begin...
2023-06-05 23:44:08.792 [job-0] INFO JobContainer - DataX Reader.Job [hdfsreader] splits to [1] tasks.
2023-06-05 23:44:08.792 [job-0] INFO JobContainer - DataX Writer.Job [mysqlwriter] splits to [1] tasks.
2023-06-05 23:44:08.804 [job-0] INFO JobContainer - jobContainer starts to do schedule ...
2023-06-05 23:44:08.815 [job-0] INFO JobContainer - Scheduler starts [1] taskGroups.
2023-06-05 23:44:08.819 [job-0] INFO JobContainer - Running by standalone Mode.
2023-06-05 23:44:08.828 [taskGroup-0] INFO TaskGroupContainer - taskGroupId=[0] start [1] channels for [1] tasks.
2023-06-05 23:44:08.836 [taskGroup-0] INFO Channel - Channel set byte_speed_limit to -1, No bps activated.
2023-06-05 23:44:08.836 [taskGroup-0] INFO Channel - Channel set record_speed_limit to -1, No tps activated.
2023-06-05 23:44:08.862 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[0] attemptCount[1] is started
2023-06-05 23:44:08.974 [0-0-0-reader] INFO HdfsReader$Job - hadoopConfig details:{"finalParameters":["mapreduce.job.end-notification.max.retry.interval","mapreduce.job.end-notification.max.attempts"]}
2023-06-05 23:44:08.980 [0-0-0-reader] INFO Reader$Task - read start
2023-06-05 23:44:08.981 [0-0-0-reader] INFO Reader$Task - reading file : [hdfs://hadoop102:8020/student.txt]
2023-06-05 23:44:09.020 [0-0-0-reader] INFO UnstructuredStorageReaderUtil - CsvReader使用默认值[{"captureRawRecord":true,"columnCount":0,"comment":"#","currentRecord":-1,"delimiter":"\t","escapeMode":1,"headerCount":0,"rawRecord":"","recordDelimiter":"\u0000","safetySwitch":false,"skipEmptyRecords":true,"textQualifier":"\"","trimWhitespace":true,"useComments":false,"useTextQualifier":true,"values":[]}],csvReaderConfig值为[null]
2023-06-05 23:44:09.030 [0-0-0-reader] INFO Reader$Task - end read source files...
2023-06-05 23:44:09.179 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[0] is successed, used[324]ms
2023-06-05 23:44:09.180 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] completed it's tasks.
2023-06-05 23:44:18.846 [job-0] INFO StandAloneJobContainerCommunicator - Total 3 records, 30 bytes | Speed 3B/s, 0 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.000s | All Task WaitReaderTime 0.000s | Percentage 100.00%
2023-06-05 23:44:18.847 [job-0] INFO AbstractScheduler - Scheduler accomplished all tasks.
2023-06-05 23:44:18.847 [job-0] INFO JobContainer - DataX Writer.Job [mysqlwriter] do post work.
2023-06-05 23:44:18.847 [job-0] INFO JobContainer - DataX Reader.Job [hdfsreader] do post work.
2023-06-05 23:44:18.847 [job-0] INFO JobContainer - DataX jobId [0] completed successfully.
2023-06-05 23:44:18.848 [job-0] INFO HookInvoker - No hook invoked, because base dir not exists or is a file: /opt/module/datax/hook
2023-06-05 23:44:18.849 [job-0] INFO JobContainer -
[total cpu info] =>
averageCpu | maxDeltaCpu | minDeltaCpu
-1.00% | -1.00% | -1.00%
[total gc info] =>
NAME | totalGCCount | maxDeltaGCCount | minDeltaGCCount | totalGCTime | maxDeltaGCTime | minDeltaGCTime
PS MarkSweep | 1 | 1 | 1 | 0.100s | 0.100s | 0.100s
PS Scavenge | 1 | 1 | 1 | 0.025s | 0.025s | 0.025s
2023-06-05 23:44:18.851 [job-0] INFO JobContainer - PerfTrace not enable!
2023-06-05 23:44:18.851 [job-0] INFO StandAloneJobContainerCommunicator - Total 3 records, 30 bytes | Speed 3B/s, 0 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.000s | All Task WaitReaderTime 0.000s | Percentage 100.00%
2023-06-05 23:44:18.855 [job-0] INFO JobContainer -
任务启动时刻 : 2023-06-05 23:44:06
任务结束时刻 : 2023-06-05 23:44:18
任务总计耗时 : 12s
任务平均流量 : 3B/s
记录写入速度 : 0rec/s
读出记录总数 : 3
读写失败总数 : 0
6)查看 student2 表
mysql> select * from student2;
+------+----------+
| id | name |
+------+----------+
| 1001 | zhangsan |
| 1002 | lisi |
| 1003 | wangwu |
+------+----------+
3 rows in set (0.00 sec)
4、Oracle数据库
以下操作使用roor账号
4.1 oracle 数据库简介
Oracle Database,又名 Oracle RDBMS,或简称 Oracle。是甲骨文公司的一款关系数据库管理系统。它是在数据库领域一直处于领先地位的产品。可以说 Oracle 数据库系统是目前世界上流行的关系数据库管理系统,系统可移植性好、使用方便、功能强,适用于各类大、中、小、微机环境。它是一种高效率、可靠性好的、适应高吞吐量的数据库解决方案。
4.2 安装前的准备
4.2.1 安装依赖
yum install -y bc binutils compat-libcap1 compat-libstdc++33 elfutils-libelf elfutils-libelf-devel fontconfig-devel glibc glibc-devel ksh libaio libaio-devel libX11 libXau libXi libXtst libXrender libXrender-devel libgcc libstdc++ libstdc++-devel libxcb make smartmontools sysstat kmod* gcc-c++ compat-libstdc++-33
4.2.2 配置用户组
Oracle 安装文件不允许通过 root 用户启动,需要为 oracle 配置一个专门的用户。
1)创建 sql 用户组
[root@hadoop102 software]#groupadd sql
2)创建 oracle 用户并放入 sql 组中
[root@hadoop102 software]#useradd oracle -g sql
3)修改 oracle 用户登录密码,输入密码后即可使用 oracle 用户登录系统
[root@hadoop102 software]#passwd oracle
4.2.3 上传安装包并解压
注意:19c 需要把软件包直接解压到 /opt/module/oracle 的目录下
[lln@hadoop102 software]# mkdir oracle
[lln@hadoop102 software]# unzip LINUX.X64_193000_db_home.zip -d /opt/module/oracle
修改所属用户和组
[root@hadoop102 module]$ chown -R oracle:sql /opt/module/oracle/
4.2.4 修改配置文件 sysctl.conf
[root@hadoop102 module]# vim /etc/sysctl.conf
删除里面的内容,添加如下内容:
net.ipv4.ip_local_port_range = 9000 65500
fs.file-max = 6815744
kernel.shmall = 10523004
kernel.shmmax = 6465333657
kernel.shmmni = 4096
kernel.sem = 250 32000 100 128
net.core.rmem_default=262144
net.core.wmem_default=262144
net.core.rmem_max=4194304
net.core.wmem_max=1048576
fs.aio-max-nr = 1048576
参数解析:
net.ipv4.ip_local_port_range :可使用的 IPv4 端口范围
fs.file-max :该参数表示文件句柄的最大数量。文件句柄设置表示在 linux 系统中可以
打开的文件数量。
kernel.shmall :该参数表示系统一次可以使用的共享内存总量(以页为单位)
kernel.shmmax :该参数定义了共享内存段的最大尺寸(以字节为单位)
kernel.shmmni :这个内核参数用于设置系统范围内共享内存段的最大数量
kernel.sem : 该参数表示设置的信号量。
net.core.rmem_default:默认的 TCP 数据接收窗口大小(字节)。
net.core.wmem_default:默认的 TCP 数据发送窗口大小(字节)。
net.core.rmem_max:最大的 TCP 数据接收窗口(字节)。
net.core.wmem_max:最大的 TCP 数据发送窗口(字节)。
fs.aio-max-nr :同时可以拥有的的异步 IO 请求数目。
4.2.5 修改配置文件 limits.conf
[root@hadoop102 module]# vim /etc/security/limits.conf
在文件末尾添加:
oracle soft nproc 2047
oracle hard nproc 16384
oracle soft nofile 1024
oracle hard nofile 65536
重启机器生效。
4.2.6
注意:19c 需要把软件包直接解压到 ORACLE_HOME 的目录下
[lln@hadoop102 ~]$ sudo mkdir -p /home/oracle/app/oracle/product/19.3.0/dbhome_1
[lln@hadoop102 software]$ sudo unzip LINUX.X64_193000_db_home.zip -d /home/oracle/app/oracle/product/19.3.0/dbhome_1
[lln@hadoop102 dbhome_1]$ sudo chown -R oracle:sql /home/oracle/app/oracle/product/19.3.0/dbhome_1
[root@hadoop102 dbhome_1]# chown -R oracle:sql /home/oracle/app/
4.3 安装Oracle数据库
4.3.1 设置环境变量
[oracle@hadoop102 dbhome_1]# vim /home/oracle/.bash_profile
添加:
#ORACLE_HOME
export ORACLE_BASE=/home/oracle/app/oracle
export ORACLE_HOME=/home/oracle/app/oracle/product/19.3.0/dbhome_1
export PATH=$PATH:$ORACLE_HOME/bin
export ORACLE_SID=orcl
export NLS_LANG=AMERICAN_AMERICA.ZHS16GBK
[oracle@hadoop102 ~]$ source /home/oracle/.bash_profile
4.3.2 进入虚拟机图像化页面操作
[oracle@hadoop102 ~]# cd /opt/module/oracle
[oracle@hadoop102 database]# ./runInstaller
4.3.3 安装数据库
[oracle@hadoop102 dbhome_1]$ pwd
/home/oracle/app/oracle/product/19.3.0/dbhome_1
[oracle@hadoop102 dbhome_1]$ ./runInstaller
1)选择仅安装数据库软件

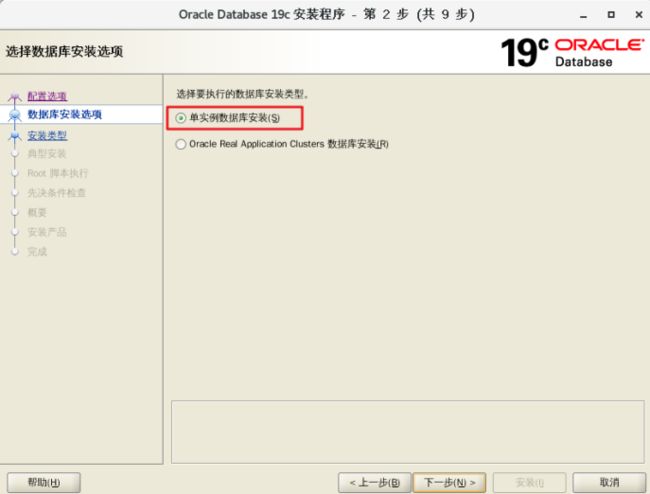
2)选择单实例数据库安装
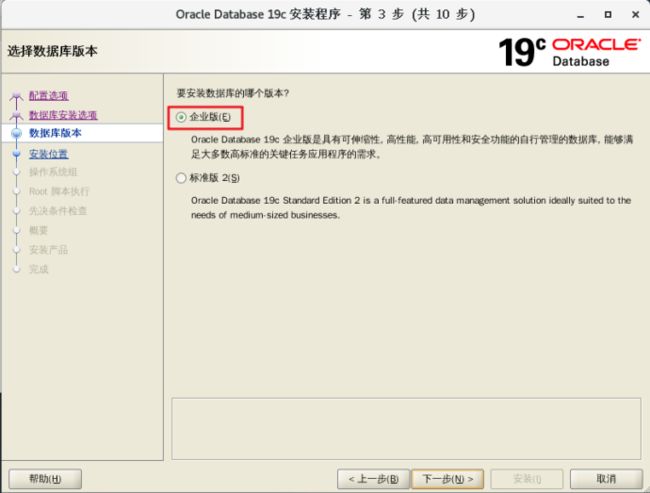
3)选择企业版,默认
4)设置安装位置

5)操作系统组设置

6)配置 root 脚本自动执行

7)条件检查通过后,选择开始安装

8)运行 root 脚本

9)安装完成

4.4 设置Oracle监听
4.4.1 命令行输入以下命令

4.4.2 选择添加

4.4.3 设置监听名,默认即可
4.4.4 选择协议,默认即可

4.4.5 设置端口号,默认即可
4.4.6 配置更多监听,默认

4.4.7 完成


4.5 创建数据库
4.5.1 进入创建页面
[oracle@hadoop2 ~]$ dbca
4.5.2 选择创建数据库

4.5.3 选择高级配置

4.5.4 选择数据仓库

4.5.5 将图中所示对勾去掉
4.5.6 存储选项
4.5.7 快速恢复选项
4.5.8 选择监听程序

4.5.9 如图设置

4.5.10 使用自动内存管理

4.5.11 管理选项,默认
4.5.12 设置统一密码
4.5.13 创建选项,选择创建数据库

4.5.14 概要,点击完成

4.5.15 等待安装


4.6 简单使用
4.6.1 开启,关闭监听服务
开启服务:
[oracle@hadoop102 ~]$ lsnrctl start
关闭服务:
[oracle@hadoop102 ~]$ lsnrctl stop
4.6.2 进入命令行
[oracle@hadoop102 ~]$ sqlplus
SQL*Plus: Release 19.0.0.0.0 - Production on Fri Sep 3 01:44:30 2021
Version 19.3.0.0.0
Copyright (c) 1982, 2019, Oracle. All rights reserved.
Enter user-name: system
Enter password: (这里输入之前配置的统一密码)
Connected to:
Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production
Version 19.3.0.0.0
SQL>
4.6.3 创建用户并授权
SQL> create user lln identified by 000000;
User created.
SQL> grant create session,create table,create view,create sequence,unlimited tablespace to lln;
Grant succeeded.
4.6.4 进入 lln 账号,创建表
SQL>create TABLE student(id INTEGER,name VARCHAR2(20));
SQL>insert into student values (1,'zhangsan');
SQL> select * from student;
ID NAME
---------- ----------------------------------------
1 zhangsan
注意:安装完成后重启机器可能出现 ORACLE not available 错误,解决方法如下:
[oracle@hadoop102 ~]$ sqlplus / as sysdba
SQL>startup
SQL>conn atguigu
Enter password:
4.7 Oracle 与 MySQL 的 SQL 区别

4.8 DataX 案例
4.8.1 从 Oracle 中读取数据存到 MySQL
1)MySQL 中创建表
[oracle@hadoop102 ~]$ mysql -uroot -p000000
mysql> create database oracle;
mysql> use oracle;
mysql> create table student(id int,name varchar(20));
2)查看模板
[oracle@hadoop102 datax]$ bin/datax.py -r oraclereader -w mysqlwriter
DataX (DATAX-OPENSOURCE-3.0), From Alibaba !
Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved.
Please refer to the oraclereader document:
https://github.com/alibaba/DataX/blob/master/oraclereader/doc/oraclereader.md
Please refer to the mysqlwriter document:
https://github.com/alibaba/DataX/blob/master/mysqlwriter/doc/mysqlwriter.md
Please save the following configuration as a json file and use
python {DATAX_HOME}/bin/datax.py {JSON_FILE_NAME}.json
to run the job.
{
"job": {
"content": [
{
"reader": {
"name": "oraclereader",
"parameter": {
"column": [],
"connection": [
{
"jdbcUrl": [],
"table": []
}
],
"password": "",
"username": ""
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": [],
"connection": [
{
"jdbcUrl": "",
"table": []
}
],
"password": "",
"preSql": [],
"session": [],
"username": "",
"writeMode": ""
}
}
}
],
"setting": {
"speed": {
"channel": ""
}
}
}
}
3)编写 datax 配置文件
[lln@hadoop102 datax]$ vim job/oracle2mysql.json
{
"job": {
"content": [{
"reader": {
"name": "oraclereader",
"parameter": {
"column": [
"id",
"name"
],
"connection": [{
"jdbcUrl": ["jdbc:oracle:thin:@hadoop102:1521:orcl"],
"table": ["student"]
}],
"password": "000000",
"username": "lln"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": [
"id",
"name"
],
"connection": [{
"jdbcUrl": "jdbc:mysql://hadoop102:3306/datax",
"table": ["student"]
}],
"password": "root",
"preSql": [],
"session": [],
"username": "root",
"writeMode": "insert"
}
}
}],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
执行结果:
[lln@hadoop102 datax]$ bin/datax.py job/oracle2mysql.json
DataX (DATAX-OPENSOURCE-3.0), From Alibaba !
Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved.
2023-06-07 11:30:22.067 [main] INFO VMInfo - VMInfo# operatingSystem class => sun.management.OperatingSystemImpl
2023-06-07 11:30:22.072 [main] INFO Engine - the machine info =>
osInfo: Oracle Corporation 1.8 25.212-b10
jvmInfo: Linux amd64 3.10.0-1160.90.1.el7.x86_64
cpu num: 1
totalPhysicalMemory: -0.00G
freePhysicalMemory: -0.00G
maxFileDescriptorCount: -1
currentOpenFileDescriptorCount: -1
GC Names [Copy, MarkSweepCompact]
MEMORY_NAME | allocation_size | init_size
Eden Space | 273.06MB | 273.06MB
Code Cache | 240.00MB | 2.44MB
Survivor Space | 34.13MB | 34.13MB
Compressed Class Space | 1,024.00MB | 0.00MB
Metaspace | -0.00MB | 0.00MB
Tenured Gen | 682.69MB | 682.69MB
2023-06-07 11:30:22.093 [main] INFO Engine -
{
"content":[
{
"reader":{
"name":"oraclereader",
"parameter":{
"column":[
"id",
"name"
],
"connection":[
{
"jdbcUrl":[
"jdbc:oracle:thin:@hadoop102:1521:orcl"
],
"table":[
"student"
]
}
],
"password":"******",
"username":"lln"
}
},
"writer":{
"name":"mysqlwriter",
"parameter":{
"column":[
"id",
"name"
],
"connection":[
{
"jdbcUrl":"jdbc:mysql://hadoop102:3306/datax",
"table":[
"student"
]
}
],
"password":"****",
"preSql":[],
"session":[],
"username":"root",
"writeMode":"insert"
}
}
}
],
"setting":{
"speed":{
"channel":"1"
}
}
}
2023-06-07 11:30:22.103 [main] WARN Engine - prioriy set to 0, because NumberFormatException, the value is: null
2023-06-07 11:30:22.105 [main] INFO PerfTrace - PerfTrace traceId=job_-1, isEnable=false, priority=0
2023-06-07 11:30:22.105 [main] INFO JobContainer - DataX jobContainer starts job.
2023-06-07 11:30:22.107 [main] INFO JobContainer - Set jobId = 0
2023-06-07 11:30:22.462 [job-0] INFO OriginalConfPretreatmentUtil - Available jdbcUrl:jdbc:oracle:thin:@hadoop102:1521:orcl.
2023-06-07 11:30:22.576 [job-0] INFO OriginalConfPretreatmentUtil - table:[student] has columns:[ID,NAME].
2023-06-07 11:30:22.757 [job-0] INFO OriginalConfPretreatmentUtil - table:[student] all columns:[
id,name
].
2023-06-07 11:30:22.772 [job-0] INFO OriginalConfPretreatmentUtil - Write data [
insert INTO %s (id,name) VALUES(?,?)
], which jdbcUrl like:[jdbc:mysql://hadoop102:3306/datax?yearIsDateType=false&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false&rewriteBatchedStatements=true]
2023-06-07 11:30:22.773 [job-0] INFO JobContainer - jobContainer starts to do prepare ...
2023-06-07 11:30:22.774 [job-0] INFO JobContainer - DataX Reader.Job [oraclereader] do prepare work .
2023-06-07 11:30:22.774 [job-0] INFO JobContainer - DataX Writer.Job [mysqlwriter] do prepare work .
2023-06-07 11:30:22.775 [job-0] INFO JobContainer - jobContainer starts to do split ...
2023-06-07 11:30:22.776 [job-0] INFO JobContainer - Job set Channel-Number to 1 channels.
2023-06-07 11:30:22.783 [job-0] INFO JobContainer - DataX Reader.Job [oraclereader] splits to [1] tasks.
2023-06-07 11:30:22.783 [job-0] INFO JobContainer - DataX Writer.Job [mysqlwriter] splits to [1] tasks.
2023-06-07 11:30:22.797 [job-0] INFO JobContainer - jobContainer starts to do schedule ...
2023-06-07 11:30:22.803 [job-0] INFO JobContainer - Scheduler starts [1] taskGroups.
2023-06-07 11:30:22.807 [job-0] INFO JobContainer - Running by standalone Mode.
2023-06-07 11:30:22.822 [taskGroup-0] INFO TaskGroupContainer - taskGroupId=[0] start [1] channels for [1] tasks.
2023-06-07 11:30:22.830 [taskGroup-0] INFO Channel - Channel set byte_speed_limit to -1, No bps activated.
2023-06-07 11:30:22.830 [taskGroup-0] INFO Channel - Channel set record_speed_limit to -1, No tps activated.
2023-06-07 11:30:22.859 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[0] attemptCount[1] is started
2023-06-07 11:30:22.861 [0-0-0-reader] INFO CommonRdbmsReader$Task - Begin to read record by Sql: [select id,name from student
] jdbcUrl:[jdbc:oracle:thin:@hadoop102:1521:orcl].
2023-06-07 11:30:22.926 [0-0-0-reader] INFO CommonRdbmsReader$Task - Finished read record by Sql: [select id,name from student
] jdbcUrl:[jdbc:oracle:thin:@hadoop102:1521:orcl].
2023-06-07 11:30:23.161 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[0] is successed, used[319]ms
2023-06-07 11:30:23.161 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] completed it's tasks.
2023-06-07 11:30:32.831 [job-0] INFO StandAloneJobContainerCommunicator - Total 1 records, 9 bytes | Speed 0B/s, 0 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.000s | All Task WaitReaderTime 0.000s | Percentage 100.00%
2023-06-07 11:30:32.831 [job-0] INFO AbstractScheduler - Scheduler accomplished all tasks.
2023-06-07 11:30:32.832 [job-0] INFO JobContainer - DataX Writer.Job [mysqlwriter] do post work.
2023-06-07 11:30:32.833 [job-0] INFO JobContainer - DataX Reader.Job [oraclereader] do post work.
2023-06-07 11:30:32.834 [job-0] INFO JobContainer - DataX jobId [0] completed successfully.
2023-06-07 11:30:32.834 [job-0] INFO HookInvoker - No hook invoked, because base dir not exists or is a file: /opt/module/datax/hook
2023-06-07 11:30:32.840 [job-0] INFO JobContainer -
[total cpu info] =>
averageCpu | maxDeltaCpu | minDeltaCpu
-1.00% | -1.00% | -1.00%
[total gc info] =>
NAME | totalGCCount | maxDeltaGCCount | minDeltaGCCount | totalGCTime | maxDeltaGCTime | minDeltaGCTime
Copy | 0 | 0 | 0 | 0.000s | 0.000s | 0.000s
MarkSweepCompact | 0 | 0 | 0 | 0.000s | 0.000s | 0.000s
2023-06-07 11:30:32.841 [job-0] INFO JobContainer - PerfTrace not enable!
2023-06-07 11:30:32.841 [job-0] INFO StandAloneJobContainerCommunicator - Total 1 records, 9 bytes | Speed 0B/s, 0 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.000s | All Task WaitReaderTime 0.000s | Percentage 100.00%
2023-06-07 11:30:32.842 [job-0] INFO JobContainer -
任务启动时刻 : 2023-06-07 11:30:22
任务结束时刻 : 2023-06-07 11:30:32
任务总计耗时 : 10s
任务平均流量 : 0B/s
记录写入速度 : 0rec/s
读出记录总数 : 1
读写失败总数 : 0
mysql> use datax;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> select * from student;
+------+----------+
| id | name |
+------+----------+
| 1 | zhangsan |
+------+----------+
1 row in set (0.00 sec)
4.8.2 读取 Oracle 的数据存入 HDFS 中
查看模板
[lln@hadoop102 datax]$ bin/datax.py -r oraclereader -w hdfswriter
DataX (DATAX-OPENSOURCE-3.0), From Alibaba !
Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved.
Please refer to the oraclereader document:
https://github.com/alibaba/DataX/blob/master/oraclereader/doc/oraclereader.md
Please refer to the hdfswriter document:
https://github.com/alibaba/DataX/blob/master/hdfswriter/doc/hdfswriter.md
Please save the following configuration as a json file and use
python {DATAX_HOME}/bin/datax.py {JSON_FILE_NAME}.json
to run the job.
{
"job": {
"content": [
{
"reader": {
"name": "oraclereader",
"parameter": {
"column": [],
"connection": [
{
"jdbcUrl": [],
"table": []
}
],
"password": "",
"username": ""
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [],
"compress": "",
"defaultFS": "",
"fieldDelimiter": "",
"fileName": "",
"fileType": "",
"path": "",
"writeMode": ""
}
}
}
],
"setting": {
"speed": {
"channel": ""
}
}
}
}
编写配置文件
{
"job": {
"content": [{
"reader": {
"name": "oraclereader",
"parameter": {
"column": [
"id",
"name"
],
"connection": [{
"jdbcUrl": ["jdbc:oracle:thin:@hadoop102:1521:orcl"],
"table": ["student"]
}],
"password": "000000",
"username": "lln"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [{
"name": "id",
"type": "int"
},
{
"name": "name",
"type": "string"
}
],
"compress": "",
"defaultFS": "hdfs://hadoop102:8020",
"fieldDelimiter": "\t",
"fileName": "oracle.txt",
"fileType": "text",
"path": "/",
"writeMode": "append"
}
}
}],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
执行结果
[lln@hadoop102 datax]$ bin/datax.py job/oracle2hdfs.json
DataX (DATAX-OPENSOURCE-3.0), From Alibaba !
Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved.
2023-06-07 11:43:23.178 [main] INFO VMInfo - VMInfo# operatingSystem class => sun.management.OperatingSystemImpl
2023-06-07 11:43:23.184 [main] INFO Engine - the machine info =>
osInfo: Oracle Corporation 1.8 25.212-b10
jvmInfo: Linux amd64 3.10.0-1160.90.1.el7.x86_64
cpu num: 1
totalPhysicalMemory: -0.00G
freePhysicalMemory: -0.00G
maxFileDescriptorCount: -1
currentOpenFileDescriptorCount: -1
GC Names [Copy, MarkSweepCompact]
MEMORY_NAME | allocation_size | init_size
Eden Space | 273.06MB | 273.06MB
Code Cache | 240.00MB | 2.44MB
Survivor Space | 34.13MB | 34.13MB
Compressed Class Space | 1,024.00MB | 0.00MB
Metaspace | -0.00MB | 0.00MB
Tenured Gen | 682.69MB | 682.69MB
2023-06-07 11:43:23.199 [main] INFO Engine -
{
"content":[
{
"reader":{
"name":"oraclereader",
"parameter":{
"column":[
"id",
"name"
],
"connection":[
{
"jdbcUrl":[
"jdbc:oracle:thin:@hadoop102:1521:orcl"
],
"table":[
"student"
]
}
],
"password":"******",
"username":"lln"
}
},
"writer":{
"name":"hdfswriter",
"parameter":{
"column":[
{
"name":"id",
"type":"int"
},
{
"name":"name",
"type":"string"
}
],
"compress":"",
"defaultFS":"hdfs://hadoop102:8020",
"fieldDelimiter":"\t",
"fileName":"oracle.txt",
"fileType":"text",
"path":"/",
"writeMode":"append"
}
}
}
],
"setting":{
"speed":{
"channel":"1"
}
}
}
2023-06-07 11:43:23.222 [main] WARN Engine - prioriy set to 0, because NumberFormatException, the value is: null
2023-06-07 11:43:23.223 [main] INFO PerfTrace - PerfTrace traceId=job_-1, isEnable=false, priority=0
2023-06-07 11:43:23.223 [main] INFO JobContainer - DataX jobContainer starts job.
2023-06-07 11:43:23.225 [main] INFO JobContainer - Set jobId = 0
2023-06-07 11:43:23.537 [job-0] INFO OriginalConfPretreatmentUtil - Available jdbcUrl:jdbc:oracle:thin:@hadoop102:1521:orcl.
2023-06-07 11:43:23.647 [job-0] INFO OriginalConfPretreatmentUtil - table:[student] has columns:[ID,NAME].
六月 07, 2023 11:43:24 上午 org.apache.hadoop.util.NativeCodeLoader
警告: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2023-06-07 11:43:24.662 [job-0] INFO JobContainer - jobContainer starts to do prepare ...
2023-06-07 11:43:24.662 [job-0] INFO JobContainer - DataX Reader.Job [oraclereader] do prepare work .
2023-06-07 11:43:24.662 [job-0] INFO JobContainer - DataX Writer.Job [hdfswriter] do prepare work .
2023-06-07 11:43:24.736 [job-0] INFO HdfsWriter$Job - 由于您配置了writeMode append, 写入前不做清理工作, [/] 目录下写入相应文件名前缀 [oracle.txt] 的文件
2023-06-07 11:43:24.737 [job-0] INFO JobContainer - jobContainer starts to do split ...
2023-06-07 11:43:24.737 [job-0] INFO JobContainer - Job set Channel-Number to 1 channels.
2023-06-07 11:43:24.742 [job-0] INFO JobContainer - DataX Reader.Job [oraclereader] splits to [1] tasks.
2023-06-07 11:43:24.742 [job-0] INFO HdfsWriter$Job - begin do split...
2023-06-07 11:43:24.751 [job-0] INFO HdfsWriter$Job - splited write file name:[hdfs://hadoop102:8020/__6da5b507_48ec_4298_a0ef_06b6a2a35c4e/oracle.txt__bb01dd02_3f14_41c4_b205_2d11ac626fec]
2023-06-07 11:43:24.751 [job-0] INFO HdfsWriter$Job - end do split.
2023-06-07 11:43:24.751 [job-0] INFO JobContainer - DataX Writer.Job [hdfswriter] splits to [1] tasks.
2023-06-07 11:43:24.767 [job-0] INFO JobContainer - jobContainer starts to do schedule ...
2023-06-07 11:43:24.775 [job-0] INFO JobContainer - Scheduler starts [1] taskGroups.
2023-06-07 11:43:24.778 [job-0] INFO JobContainer - Running by standalone Mode.
2023-06-07 11:43:24.788 [taskGroup-0] INFO TaskGroupContainer - taskGroupId=[0] start [1] channels for [1] tasks.
2023-06-07 11:43:24.797 [taskGroup-0] INFO Channel - Channel set byte_speed_limit to -1, No bps activated.
2023-06-07 11:43:24.797 [taskGroup-0] INFO Channel - Channel set record_speed_limit to -1, No tps activated.
2023-06-07 11:43:24.845 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[0] attemptCount[1] is started
2023-06-07 11:43:24.856 [0-0-0-reader] INFO CommonRdbmsReader$Task - Begin to read record by Sql: [select id,name from student
] jdbcUrl:[jdbc:oracle:thin:@hadoop102:1521:orcl].
2023-06-07 11:43:24.879 [0-0-0-writer] INFO HdfsWriter$Task - begin do write...
2023-06-07 11:43:24.879 [0-0-0-writer] INFO HdfsWriter$Task - write to file : [hdfs://hadoop102:8020/__6da5b507_48ec_4298_a0ef_06b6a2a35c4e/oracle.txt__bb01dd02_3f14_41c4_b205_2d11ac626fec]
2023-06-07 11:43:24.998 [0-0-0-reader] INFO CommonRdbmsReader$Task - Finished read record by Sql: [select id,name from student
] jdbcUrl:[jdbc:oracle:thin:@hadoop102:1521:orcl].
2023-06-07 11:43:25.656 [0-0-0-writer] INFO HdfsWriter$Task - end do write
2023-06-07 11:43:25.749 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[0] is successed, used[936]ms
2023-06-07 11:43:25.749 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] completed it's tasks.
2023-06-07 11:43:34.798 [job-0] INFO StandAloneJobContainerCommunicator - Total 1 records, 9 bytes | Speed 0B/s, 0 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.000s | All Task WaitReaderTime 0.000s | Percentage 100.00%
2023-06-07 11:43:34.798 [job-0] INFO AbstractScheduler - Scheduler accomplished all tasks.
2023-06-07 11:43:34.798 [job-0] INFO JobContainer - DataX Writer.Job [hdfswriter] do post work.
2023-06-07 11:43:34.799 [job-0] INFO HdfsWriter$Job - start rename file [hdfs://hadoop102:8020/__6da5b507_48ec_4298_a0ef_06b6a2a35c4e/oracle.txt__bb01dd02_3f14_41c4_b205_2d11ac626fec] to file [hdfs://hadoop102:8020/oracle.txt__bb01dd02_3f14_41c4_b205_2d11ac626fec].
2023-06-07 11:43:34.815 [job-0] INFO HdfsWriter$Job - finish rename file [hdfs://hadoop102:8020/__6da5b507_48ec_4298_a0ef_06b6a2a35c4e/oracle.txt__bb01dd02_3f14_41c4_b205_2d11ac626fec] to file [hdfs://hadoop102:8020/oracle.txt__bb01dd02_3f14_41c4_b205_2d11ac626fec].
2023-06-07 11:43:34.815 [job-0] INFO HdfsWriter$Job - start delete tmp dir [hdfs://hadoop102:8020/__6da5b507_48ec_4298_a0ef_06b6a2a35c4e] .
2023-06-07 11:43:34.832 [job-0] INFO HdfsWriter$Job - finish delete tmp dir [hdfs://hadoop102:8020/__6da5b507_48ec_4298_a0ef_06b6a2a35c4e] .
2023-06-07 11:43:34.832 [job-0] INFO JobContainer - DataX Reader.Job [oraclereader] do post work.
2023-06-07 11:43:34.832 [job-0] INFO JobContainer - DataX jobId [0] completed successfully.
2023-06-07 11:43:34.834 [job-0] INFO HookInvoker - No hook invoked, because base dir not exists or is a file: /opt/module/datax/hook
2023-06-07 11:43:34.938 [job-0] INFO JobContainer -
[total cpu info] =>
averageCpu | maxDeltaCpu | minDeltaCpu
-1.00% | -1.00% | -1.00%
[total gc info] =>
NAME | totalGCCount | maxDeltaGCCount | minDeltaGCCount | totalGCTime | maxDeltaGCTime | minDeltaGCTime
Copy | 0 | 0 | 0 | 0.000s | 0.000s | 0.000s
MarkSweepCompact | 1 | 1 | 1 | 0.047s | 0.047s | 0.047s
2023-06-07 11:43:34.939 [job-0] INFO JobContainer - PerfTrace not enable!
2023-06-07 11:43:34.940 [job-0] INFO StandAloneJobContainerCommunicator - Total 1 records, 9 bytes | Speed 0B/s, 0 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.000s | All Task WaitReaderTime 0.000s | Percentage 100.00%
2023-06-07 11:43:34.941 [job-0] INFO JobContainer -
任务启动时刻 : 2023-06-07 11:43:23
任务结束时刻 : 2023-06-07 11:43:34
任务总计耗时 : 11s
任务平均流量 : 0B/s
记录写入速度 : 0rec/s
读出记录总数 : 1
读写失败总数 : 0

5、MongoDB
5.1 什么是 MongoDB
MongoDB 是由 C++语言编写的,是一个基于分布式文件存储的开源数据库系统。MongoDB 旨在为 WEB 应用提供可扩展的高性能数据存储解决方案。MongoDB 将数据存储为一个文档,数据结构由键值(key=>value)对组成。MongoDB 文档类似于 JSON 对象。字段值可以包含其他文档,数组及文档数组。

5.2 MongoDB 优缺点

5.3 基础概念解析
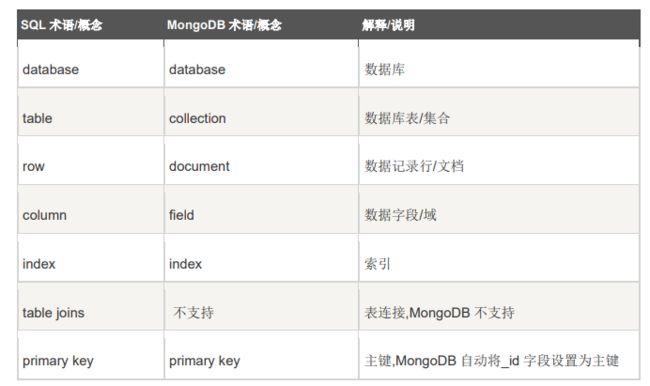
通过下图实例,我们也可以更直观的了解 Mongo 中的一些概念:

5.4 安装
5.4.1 下载地址
https://www.mongodb.com/download-center#community
5.4.2 安装
1)上传压缩包到虚拟机中,解压
[atguigu@hadoop102 software]$ tar -zxvf mongodb-linux-x86_64-rhel70-5.0.2.tgz -C /opt/module/
2)重命名
[atguigu@hadoop102 module]$ mv mongodb-linux-x86_64- rhel70-5.0.2/ mongodb
3)创建数据库目录
MongoDB 的数据存储在 data 目录的 db 目录下,但是这个目录在安装过程不会自动创
建,所以需要手动创建 data 目录,并在 data 目录中创建 db 目录。
[atguigu@hadoop102 module]$ sudo mkdir -p /data/db
[atguigu@hadoop102 mongodb]$ sudo chmod 777 -R /data/db/
5)启动 MongoDB 服务
[lln@hadoop102 mongodb]$ bin/mongod --bind_ip 0.0.0.0
6)进入 shell 页面
[atguigu@hadoop102 mongodb]$ bin/mongo
5.5 基础概念详解
5.5.1 数据库
一个 mongodb 中可以建立多个数据库。MongoDB 的默认数据库为"db",该数据库存储在 data 目录中。MongoDB 的单个实例可以容纳多个独立的数据库,每一个都有自己的集合和权限,不同的数据库也放置在不同的文件中。

5.5.2 集合


案例 1:在 test 库中创建一个 atguigu 的集合
> use test
switched to db test
> db.createCollection("atguigu")
{ "ok" : 1 }
> show collections
Atguigu
//插入数据
> db.atguigu.insert({"name":"atguigu","url":"www.atguigu.com"})
WriteResult({ "nInserted" : 1 })
//查看数据
> db.atguigu.find()
{ "_id" : ObjectId("5d0314ceecb77ee2fb2d7566"), "name" : "atguigu", "url" :
"www.atguigu.com" }
说明:
ObjectId 类似唯一主键,可以很快的去生成和排序,包含 12 bytes,由 24 个 16 进制数
字组成的字符串(每个字节可以存储两个 16 进制数字),含义是:
➢ 前 4 个字节表示创建 unix 时间戳
➢ 接下来的 3 个字节是机器标识码
➢ 紧接的两个字节由进程 id 组成 PID
➢ 最后三个字节是随机数
案例 2:创建一个固定集合 mycol
> db.createCollection("mycol",{ capped : true,autoIndexId : true,size : 6142800, max :
1000})
> show tables;
atguigu
mycol
案例 3:自动创建集合
在 MongoDB 中,你不需要创建集合。当你插入一些文档时,MongoDB 会自动创建集合。
> db.mycol2.insert({"name":"atguigu"})
WriteResult({ "nInserted" : 1 })
> show collections
atguigu
mycol
mycol2
案例 4:删除集合
> db.mycol2.drop()
True
> show tables;
atguigu
mycol
5.5.3 文档

5.6 读取MongoDB的数据导入到HDFS
5.6.1 查看官方模板
[lln@hadoop102 datax]$ bin/datax.py -r mongodbreader -w hdfswriter
DataX (DATAX-OPENSOURCE-3.0), From Alibaba !
Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved.
Please refer to the mongodbreader document:
https://github.com/alibaba/DataX/blob/master/mongodbreader/doc/mongodbreader.md
Please refer to the hdfswriter document:
https://github.com/alibaba/DataX/blob/master/hdfswriter/doc/hdfswriter.md
Please save the following configuration as a json file and use
python {DATAX_HOME}/bin/datax.py {JSON_FILE_NAME}.json
to run the job.
{
"job": {
"content": [
{
"reader": {
"name": "mongodbreader",
"parameter": {
"address": [],
"collectionName": "",
"column": [],
"dbName": "",
"userName": "",
"userPassword": ""
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [],
"compress": "",
"defaultFS": "",
"fieldDelimiter": "",
"fileName": "",
"fileType": "",
"path": "",
"writeMode": ""
}
}
}
],
"setting": {
"speed": {
"channel": ""
}
}
}
}
5.6.2 编写配置文件
[lln@hadoop102 datax]$ vim job/mongodb2hdfs.json
{
"job": {
"content": [{
"reader": {
"name": "mongodbreader",
"parameter": {
"address": ["hadoop102:27017"],
"collectionName": "atguigu",
"column": [
{
"name": "name",
"type": "string"
},
{
"name": "url",
"type": "string"
}
],
"dbName": "test"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{
"name": "name",
"type": "string"
},
{
"name": "url",
"type": "string"
}
],
"compress": "",
"defaultFS": "hdfs://hadoop102:8020",
"fieldDelimiter": "\t",
"fileName": "mongo.txt",
"fileType": "text",
"path": "/",
"writeMode": "append"
}
}
}],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
5.6.3 mongodbreader 参数解析
➢ address: MongoDB 的数据地址信息,因为 MonogDB 可能是个集群,则 ip 端口信息需
要以 Json 数组的形式给出。【必填】
➢ userName:MongoDB 的用户名。【选填】
➢ userPassword: MongoDB 的密码。【选填】
➢ collectionName: MonogoDB 的集合名。【必填】
➢ column:MongoDB 的文档列名。【必填】
➢ name:Column 的名字。【必填】
➢ type:Column 的类型。【选填】
➢ splitter:因为 MongoDB 支持数组类型,但是 Datax 框架本身不支持数组类型,所以
mongoDB 读出来的数组类型要通过这个分隔符合并成字符串。【选填】
5.6.4 执行
[lln@hadoop102 datax]$ bin/datax.py job/mongodb2hdfs.json
DataX (DATAX-OPENSOURCE-3.0), From Alibaba !
Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved.
2023-06-07 14:19:13.842 [main] INFO VMInfo - VMInfo# operatingSystem class => sun.management.OperatingSystemImpl
2023-06-07 14:19:13.848 [main] INFO Engine - the machine info =>
osInfo: Oracle Corporation 1.8 25.212-b10
jvmInfo: Linux amd64 3.10.0-1160.90.1.el7.x86_64
cpu num: 1
totalPhysicalMemory: -0.00G
freePhysicalMemory: -0.00G
maxFileDescriptorCount: -1
currentOpenFileDescriptorCount: -1
GC Names [Copy, MarkSweepCompact]
MEMORY_NAME | allocation_size | init_size
Eden Space | 273.06MB | 273.06MB
Code Cache | 240.00MB | 2.44MB
Survivor Space | 34.13MB | 34.13MB
Compressed Class Space | 1,024.00MB | 0.00MB
Metaspace | -0.00MB | 0.00MB
Tenured Gen | 682.69MB | 682.69MB
2023-06-07 14:19:13.862 [main] INFO Engine -
{
"content":[
{
"reader":{
"name":"mongodbreader",
"parameter":{
"address":[
"hadoop102:27017"
],
"collectionName":"atguigu",
"column":[
{
"name":"name",
"type":"string"
},
{
"name":"url",
"type":"string"
}
],
"dbName":"test"
}
},
"writer":{
"name":"hdfswriter",
"parameter":{
"column":[
{
"name":"name",
"type":"string"
},
{
"name":"url",
"type":"string"
}
],
"compress":"",
"defaultFS":"hdfs://hadoop102:8020",
"fieldDelimiter":"\t",
"fileName":"mongo.txt",
"fileType":"text",
"path":"/",
"writeMode":"append"
}
}
}
],
"setting":{
"speed":{
"channel":"1"
}
}
}
2023-06-07 14:19:13.873 [main] WARN Engine - prioriy set to 0, because NumberFormatException, the value is: null
2023-06-07 14:19:13.874 [main] INFO PerfTrace - PerfTrace traceId=job_-1, isEnable=false, priority=0
2023-06-07 14:19:13.874 [main] INFO JobContainer - DataX jobContainer starts job.
2023-06-07 14:19:13.877 [main] INFO JobContainer - Set jobId = 0
2023-06-07 14:19:13.999 [job-0] INFO cluster - Cluster created with settings {hosts=[hadoop102:27017], mode=MULTIPLE, requiredClusterType=UNKNOWN, serverSelectionTimeout='30000 ms', maxWaitQueueSize=500}
2023-06-07 14:19:13.999 [job-0] INFO cluster - Adding discovered server hadoop102:27017 to client view of cluster
2023-06-07 14:19:14.128 [cluster-ClusterId{value='648021614560c8a4203327da', description='null'}-hadoop102:27017] INFO connection - Opened connection [connectionId{localValue:1, serverValue:1}] to hadoop102:27017
2023-06-07 14:19:14.132 [cluster-ClusterId{value='648021614560c8a4203327da', description='null'}-hadoop102:27017] INFO cluster - Monitor thread successfully connected to server with description ServerDescription{address=hadoop102:27017, type=STANDALONE, state=CONNECTED, ok=true, version=ServerVersion{versionList=[5, 0, 2]}, minWireVersion=0, maxWireVersion=13, maxDocumentSize=16777216, roundTripTimeNanos=849005}
2023-06-07 14:19:14.133 [cluster-ClusterId{value='648021614560c8a4203327da', description='null'}-hadoop102:27017] INFO cluster - Discovered cluster type of STANDALONE
六月 07, 2023 2:19:14 下午 org.apache.hadoop.util.NativeCodeLoader
警告: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2023-06-07 14:19:15.069 [job-0] INFO JobContainer - jobContainer starts to do prepare ...
2023-06-07 14:19:15.070 [job-0] INFO JobContainer - DataX Reader.Job [mongodbreader] do prepare work .
2023-06-07 14:19:15.070 [job-0] INFO JobContainer - DataX Writer.Job [hdfswriter] do prepare work .
2023-06-07 14:19:15.180 [job-0] INFO HdfsWriter$Job - 由于您配置了writeMode append, 写入前不做清理工作, [/] 目录下写入相应文件名前缀 [mongo.txt] 的文件
2023-06-07 14:19:15.180 [job-0] INFO JobContainer - jobContainer starts to do split ...
2023-06-07 14:19:15.180 [job-0] INFO JobContainer - Job set Channel-Number to 1 channels.
2023-06-07 14:19:15.200 [job-0] INFO connection - Opened connection [connectionId{localValue:2, serverValue:2}] to hadoop102:27017
2023-06-07 14:19:15.206 [job-0] INFO JobContainer - DataX Reader.Job [mongodbreader] splits to [1] tasks.
2023-06-07 14:19:15.207 [job-0] INFO HdfsWriter$Job - begin do split...
2023-06-07 14:19:15.214 [job-0] INFO HdfsWriter$Job - splited write file name:[hdfs://hadoop102:8020/__7ea2824b_0c95_40ba_916a_12f6a9f34093/mongo.txt__dd3506c8_21a9_481c_aa2a_1bf709106a1b]
2023-06-07 14:19:15.214 [job-0] INFO HdfsWriter$Job - end do split.
2023-06-07 14:19:15.214 [job-0] INFO JobContainer - DataX Writer.Job [hdfswriter] splits to [1] tasks.
2023-06-07 14:19:15.229 [job-0] INFO JobContainer - jobContainer starts to do schedule ...
2023-06-07 14:19:15.241 [job-0] INFO JobContainer - Scheduler starts [1] taskGroups.
2023-06-07 14:19:15.245 [job-0] INFO JobContainer - Running by standalone Mode.
2023-06-07 14:19:15.268 [taskGroup-0] INFO TaskGroupContainer - taskGroupId=[0] start [1] channels for [1] tasks.
2023-06-07 14:19:15.277 [taskGroup-0] INFO Channel - Channel set byte_speed_limit to -1, No bps activated.
2023-06-07 14:19:15.277 [taskGroup-0] INFO Channel - Channel set record_speed_limit to -1, No tps activated.
2023-06-07 14:19:15.330 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[0] attemptCount[1] is started
2023-06-07 14:19:15.331 [0-0-0-reader] INFO cluster - Cluster created with settings {hosts=[hadoop102:27017], mode=MULTIPLE, requiredClusterType=UNKNOWN, serverSelectionTimeout='30000 ms', maxWaitQueueSize=500}
2023-06-07 14:19:15.331 [0-0-0-reader] INFO cluster - Adding discovered server hadoop102:27017 to client view of cluster
2023-06-07 14:19:15.341 [0-0-0-writer] INFO HdfsWriter$Task - begin do write...
2023-06-07 14:19:15.341 [0-0-0-writer] INFO HdfsWriter$Task - write to file : [hdfs://hadoop102:8020/__7ea2824b_0c95_40ba_916a_12f6a9f34093/mongo.txt__dd3506c8_21a9_481c_aa2a_1bf709106a1b]
2023-06-07 14:19:15.383 [0-0-0-reader] INFO cluster - No server chosen by ReadPreferenceServerSelector{readPreference=primary} from cluster description ClusterDescription{type=UNKNOWN, connectionMode=MULTIPLE, all=[ServerDescription{address=hadoop102:27017, type=UNKNOWN, state=CONNECTING}]}. Waiting for 30000 ms before timing out
2023-06-07 14:19:15.403 [cluster-ClusterId{value='648021634560c8a4203327db', description='null'}-hadoop102:27017] INFO connection - Opened connection [connectionId{localValue:3, serverValue:3}] to hadoop102:27017
2023-06-07 14:19:15.410 [cluster-ClusterId{value='648021634560c8a4203327db', description='null'}-hadoop102:27017] INFO cluster - Monitor thread successfully connected to server with description ServerDescription{address=hadoop102:27017, type=STANDALONE, state=CONNECTED, ok=true, version=ServerVersion{versionList=[5, 0, 2]}, minWireVersion=0, maxWireVersion=13, maxDocumentSize=16777216, roundTripTimeNanos=6894326}
2023-06-07 14:19:15.411 [cluster-ClusterId{value='648021634560c8a4203327db', description='null'}-hadoop102:27017] INFO cluster - Discovered cluster type of STANDALONE
2023-06-07 14:19:15.417 [0-0-0-reader] INFO connection - Opened connection [connectionId{localValue:4, serverValue:4}] to hadoop102:27017
2023-06-07 14:19:15.572 [0-0-0-writer] INFO HdfsWriter$Task - end do write
2023-06-07 14:19:15.632 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[0] is successed, used[342]ms
2023-06-07 14:19:15.633 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] completed it's tasks.
2023-06-07 14:19:25.279 [job-0] INFO StandAloneJobContainerCommunicator - Total 1 records, 22 bytes | Speed 2B/s, 0 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.000s | All Task WaitReaderTime 0.000s | Percentage 100.00%
2023-06-07 14:19:25.279 [job-0] INFO AbstractScheduler - Scheduler accomplished all tasks.
2023-06-07 14:19:25.280 [job-0] INFO JobContainer - DataX Writer.Job [hdfswriter] do post work.
2023-06-07 14:19:25.280 [job-0] INFO HdfsWriter$Job - start rename file [hdfs://hadoop102:8020/__7ea2824b_0c95_40ba_916a_12f6a9f34093/mongo.txt__dd3506c8_21a9_481c_aa2a_1bf709106a1b] to file [hdfs://hadoop102:8020/mongo.txt__dd3506c8_21a9_481c_aa2a_1bf709106a1b].
2023-06-07 14:19:25.292 [job-0] INFO HdfsWriter$Job - finish rename file [hdfs://hadoop102:8020/__7ea2824b_0c95_40ba_916a_12f6a9f34093/mongo.txt__dd3506c8_21a9_481c_aa2a_1bf709106a1b] to file [hdfs://hadoop102:8020/mongo.txt__dd3506c8_21a9_481c_aa2a_1bf709106a1b].
2023-06-07 14:19:25.293 [job-0] INFO HdfsWriter$Job - start delete tmp dir [hdfs://hadoop102:8020/__7ea2824b_0c95_40ba_916a_12f6a9f34093] .
2023-06-07 14:19:25.300 [job-0] INFO HdfsWriter$Job - finish delete tmp dir [hdfs://hadoop102:8020/__7ea2824b_0c95_40ba_916a_12f6a9f34093] .
2023-06-07 14:19:25.300 [job-0] INFO JobContainer - DataX Reader.Job [mongodbreader] do post work.
2023-06-07 14:19:25.300 [job-0] INFO JobContainer - DataX jobId [0] completed successfully.
2023-06-07 14:19:25.300 [job-0] INFO HookInvoker - No hook invoked, because base dir not exists or is a file: /opt/module/datax/hook
2023-06-07 14:19:25.402 [job-0] INFO JobContainer -
[total cpu info] =>
averageCpu | maxDeltaCpu | minDeltaCpu
-1.00% | -1.00% | -1.00%
[total gc info] =>
NAME | totalGCCount | maxDeltaGCCount | minDeltaGCCount | totalGCTime | maxDeltaGCTime | minDeltaGCTime
Copy | 0 | 0 | 0 | 0.000s | 0.000s | 0.000s
MarkSweepCompact | 1 | 1 | 1 | 0.034s | 0.034s | 0.034s
2023-06-07 14:19:25.402 [job-0] INFO JobContainer - PerfTrace not enable!
2023-06-07 14:19:25.402 [job-0] INFO StandAloneJobContainerCommunicator - Total 1 records, 22 bytes | Speed 2B/s, 0 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.000s | All Task WaitReaderTime 0.000s | Percentage 100.00%
2023-06-07 14:19:25.403 [job-0] INFO JobContainer -
任务启动时刻 : 2023-06-07 14:19:13
任务结束时刻 : 2023-06-07 14:19:25
任务总计耗时 : 11s
任务平均流量 : 2B/s
记录写入速度 : 0rec/s
读出记录总数 : 1
读写失败总数 : 0
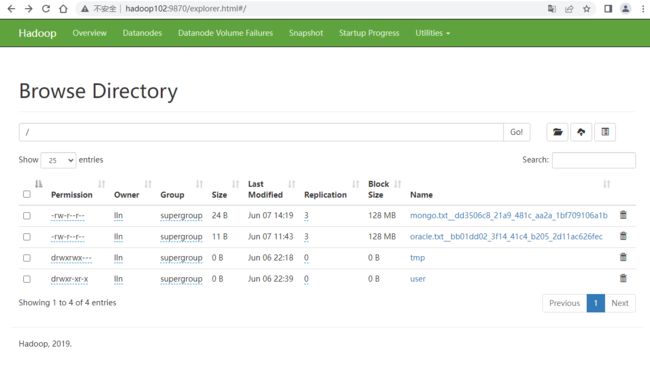
5.7 读取MongoDB的数据导入MySQL
5.7.1 在mysql中创建表
mysql> create table atguigu(name varchar(20),url varchar(20));
5.7.2 查看模板
[lln@hadoop102 datax]$ bin/datax.py -r mongodbreader -w mysqlwriter
DataX (DATAX-OPENSOURCE-3.0), From Alibaba !
Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved.
Please refer to the mongodbreader document:
https://github.com/alibaba/DataX/blob/master/mongodbreader/doc/mongodbreader.md
Please refer to the mysqlwriter document:
https://github.com/alibaba/DataX/blob/master/mysqlwriter/doc/mysqlwriter.md
Please save the following configuration as a json file and use
python {DATAX_HOME}/bin/datax.py {JSON_FILE_NAME}.json
to run the job.
{
"job": {
"content": [
{
"reader": {
"name": "mongodbreader",
"parameter": {
"address": [],
"collectionName": "",
"column": [],
"dbName": "",
"userName": "",
"userPassword": ""
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": [],
"connection": [
{
"jdbcUrl": "",
"table": []
}
],
"password": "",
"preSql": [],
"session": [],
"username": "",
"writeMode": ""
}
}
}
],
"setting": {
"speed": {
"channel": ""
}
}
}
}
5.7.3 编写配置文件
[lln@hadoop102 datax]$ vim job/mongodb2mysql.json
{
"job": {
"content": [{
"reader": {
"name": "mongodbreader",
"parameter": {
"address": ["hadoop102:27017"],
"collectionName": "atguigu",
"column": [{
"name": "name",
"type": "string"
},
{
"name": "url",
"type": "string"
}
],
"dbName": "test"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": [
"name",
"url"
],
"connection": [{
"jdbcUrl": "jdbc:mysql://hadoop102:3306/datax",
"table": ["atguigu"]
}],
"password": "root",
"preSql": [],
"session": [],
"username": "root",
"writeMode": "insert"
}
}
}],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
5.7.4 执行
[lln@hadoop102 datax]$ bin/datax.py job/mongodb2mysql.json
DataX (DATAX-OPENSOURCE-3.0), From Alibaba !
Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved.
2023-06-07 14:46:13.058 [main] INFO VMInfo - VMInfo# operatingSystem class => sun.management.OperatingSystemImpl
2023-06-07 14:46:13.066 [main] INFO Engine - the machine info =>
osInfo: Oracle Corporation 1.8 25.212-b10
jvmInfo: Linux amd64 3.10.0-1160.90.1.el7.x86_64
cpu num: 1
totalPhysicalMemory: -0.00G
freePhysicalMemory: -0.00G
maxFileDescriptorCount: -1
currentOpenFileDescriptorCount: -1
GC Names [Copy, MarkSweepCompact]
MEMORY_NAME | allocation_size | init_size
Eden Space | 273.06MB | 273.06MB
Code Cache | 240.00MB | 2.44MB
Survivor Space | 34.13MB | 34.13MB
Compressed Class Space | 1,024.00MB | 0.00MB
Metaspace | -0.00MB | 0.00MB
Tenured Gen | 682.69MB | 682.69MB
2023-06-07 14:46:13.081 [main] INFO Engine -
{
"content":[
{
"reader":{
"name":"mongodbreader",
"parameter":{
"address":[
"hadoop102:27017"
],
"collectionName":"atguigu",
"column":[
{
"name":"name",
"type":"string"
},
{
"name":"url",
"type":"string"
}
],
"dbName":"test"
}
},
"writer":{
"name":"mysqlwriter",
"parameter":{
"column":[
"name",
"url"
],
"connection":[
{
"jdbcUrl":"jdbc:mysql://hadoop102:3306/datax",
"table":[
"atguigu"
]
}
],
"password":"****",
"preSql":[],
"session":[],
"username":"root",
"writeMode":"insert"
}
}
}
],
"setting":{
"speed":{
"channel":"1"
}
}
}
2023-06-07 14:46:13.099 [main] WARN Engine - prioriy set to 0, because NumberFormatException, the value is: null
2023-06-07 14:46:13.101 [main] INFO PerfTrace - PerfTrace traceId=job_-1, isEnable=false, priority=0
2023-06-07 14:46:13.101 [main] INFO JobContainer - DataX jobContainer starts job.
2023-06-07 14:46:13.102 [main] INFO JobContainer - Set jobId = 0
2023-06-07 14:46:13.225 [job-0] INFO cluster - Cluster created with settings {hosts=[hadoop102:27017], mode=MULTIPLE, requiredClusterType=UNKNOWN, serverSelectionTimeout='30000 ms', maxWaitQueueSize=500}
2023-06-07 14:46:13.225 [job-0] INFO cluster - Adding discovered server hadoop102:27017 to client view of cluster
2023-06-07 14:46:13.367 [cluster-ClusterId{value='648027b54560c8ab003f382c', description='null'}-hadoop102:27017] INFO connection - Opened connection [connectionId{localValue:1, serverValue:8}] to hadoop102:27017
2023-06-07 14:46:13.369 [cluster-ClusterId{value='648027b54560c8ab003f382c', description='null'}-hadoop102:27017] INFO cluster - Monitor thread successfully connected to server with description ServerDescription{address=hadoop102:27017, type=STANDALONE, state=CONNECTED, ok=true, version=ServerVersion{versionList=[5, 0, 2]}, minWireVersion=0, maxWireVersion=13, maxDocumentSize=16777216, roundTripTimeNanos=1200252}
2023-06-07 14:46:13.370 [cluster-ClusterId{value='648027b54560c8ab003f382c', description='null'}-hadoop102:27017] INFO cluster - Discovered cluster type of STANDALONE
2023-06-07 14:46:13.598 [job-0] INFO OriginalConfPretreatmentUtil - table:[atguigu] all columns:[
name,url
].
2023-06-07 14:46:13.609 [job-0] INFO OriginalConfPretreatmentUtil - Write data [
insert INTO %s (name,url) VALUES(?,?)
], which jdbcUrl like:[jdbc:mysql://hadoop102:3306/datax?yearIsDateType=false&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false&rewriteBatchedStatements=true]
2023-06-07 14:46:13.609 [job-0] INFO JobContainer - jobContainer starts to do prepare ...
2023-06-07 14:46:13.609 [job-0] INFO JobContainer - DataX Reader.Job [mongodbreader] do prepare work .
2023-06-07 14:46:13.610 [job-0] INFO JobContainer - DataX Writer.Job [mysqlwriter] do prepare work .
2023-06-07 14:46:13.610 [job-0] INFO JobContainer - jobContainer starts to do split ...
2023-06-07 14:46:13.610 [job-0] INFO JobContainer - Job set Channel-Number to 1 channels.
2023-06-07 14:46:13.631 [job-0] INFO connection - Opened connection [connectionId{localValue:2, serverValue:9}] to hadoop102:27017
2023-06-07 14:46:13.644 [job-0] INFO JobContainer - DataX Reader.Job [mongodbreader] splits to [1] tasks.
2023-06-07 14:46:13.647 [job-0] INFO JobContainer - DataX Writer.Job [mysqlwriter] splits to [1] tasks.
2023-06-07 14:46:13.665 [job-0] INFO JobContainer - jobContainer starts to do schedule ...
2023-06-07 14:46:13.669 [job-0] INFO JobContainer - Scheduler starts [1] taskGroups.
2023-06-07 14:46:13.677 [job-0] INFO JobContainer - Running by standalone Mode.
2023-06-07 14:46:13.684 [taskGroup-0] INFO TaskGroupContainer - taskGroupId=[0] start [1] channels for [1] tasks.
2023-06-07 14:46:13.696 [taskGroup-0] INFO Channel - Channel set byte_speed_limit to -1, No bps activated.
2023-06-07 14:46:13.696 [taskGroup-0] INFO Channel - Channel set record_speed_limit to -1, No tps activated.
2023-06-07 14:46:13.723 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[0] attemptCount[1] is started
2023-06-07 14:46:13.725 [0-0-0-reader] INFO cluster - Cluster created with settings {hosts=[hadoop102:27017], mode=MULTIPLE, requiredClusterType=UNKNOWN, serverSelectionTimeout='30000 ms', maxWaitQueueSize=500}
2023-06-07 14:46:13.725 [0-0-0-reader] INFO cluster - Adding discovered server hadoop102:27017 to client view of cluster
2023-06-07 14:46:13.738 [0-0-0-reader] INFO cluster - No server chosen by ReadPreferenceServerSelector{readPreference=primary} from cluster description ClusterDescription{type=UNKNOWN, connectionMode=MULTIPLE, all=[ServerDescription{address=hadoop102:27017, type=UNKNOWN, state=CONNECTING}]}. Waiting for 30000 ms before timing out
2023-06-07 14:46:13.742 [cluster-ClusterId{value='648027b54560c8ab003f382d', description='null'}-hadoop102:27017] INFO connection - Opened connection [connectionId{localValue:3, serverValue:10}] to hadoop102:27017
2023-06-07 14:46:13.743 [cluster-ClusterId{value='648027b54560c8ab003f382d', description='null'}-hadoop102:27017] INFO cluster - Monitor thread successfully connected to server with description ServerDescription{address=hadoop102:27017, type=STANDALONE, state=CONNECTED, ok=true, version=ServerVersion{versionList=[5, 0, 2]}, minWireVersion=0, maxWireVersion=13, maxDocumentSize=16777216, roundTripTimeNanos=774444}
2023-06-07 14:46:13.743 [cluster-ClusterId{value='648027b54560c8ab003f382d', description='null'}-hadoop102:27017] INFO cluster - Discovered cluster type of STANDALONE
2023-06-07 14:46:13.747 [0-0-0-reader] INFO connection - Opened connection [connectionId{localValue:4, serverValue:11}] to hadoop102:27017
2023-06-07 14:46:13.824 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[0] is successed, used[117]ms
2023-06-07 14:46:13.824 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] completed it's tasks.
2023-06-07 14:46:23.694 [job-0] INFO StandAloneJobContainerCommunicator - Total 1 records, 22 bytes | Speed 2B/s, 0 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.000s | All Task WaitReaderTime 0.000s | Percentage 100.00%
2023-06-07 14:46:23.694 [job-0] INFO AbstractScheduler - Scheduler accomplished all tasks.
2023-06-07 14:46:23.694 [job-0] INFO JobContainer - DataX Writer.Job [mysqlwriter] do post work.
2023-06-07 14:46:23.695 [job-0] INFO JobContainer - DataX Reader.Job [mongodbreader] do post work.
2023-06-07 14:46:23.695 [job-0] INFO JobContainer - DataX jobId [0] completed successfully.
2023-06-07 14:46:23.695 [job-0] INFO HookInvoker - No hook invoked, because base dir not exists or is a file: /opt/module/datax/hook
2023-06-07 14:46:23.700 [job-0] INFO JobContainer -
[total cpu info] =>
averageCpu | maxDeltaCpu | minDeltaCpu
-1.00% | -1.00% | -1.00%
[total gc info] =>
NAME | totalGCCount | maxDeltaGCCount | minDeltaGCCount | totalGCTime | maxDeltaGCTime | minDeltaGCTime
Copy | 0 | 0 | 0 | 0.000s | 0.000s | 0.000s
MarkSweepCompact | 0 | 0 | 0 | 0.000s | 0.000s | 0.000s
2023-06-07 14:46:23.700 [job-0] INFO JobContainer - PerfTrace not enable!
2023-06-07 14:46:23.701 [job-0] INFO StandAloneJobContainerCommunicator - Total 1 records, 22 bytes | Speed 2B/s, 0 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.000s | All Task WaitReaderTime 0.000s | Percentage 100.00%
2023-06-07 14:46:23.702 [job-0] INFO JobContainer -
任务启动时刻 : 2023-06-07 14:46:13
任务结束时刻 : 2023-06-07 14:46:23
任务总计耗时 : 10s
任务平均流量 : 2B/s
记录写入速度 : 0rec/s
读出记录总数 : 1
读写失败总数 : 0

6、SQLServer
6.1 什么是 SQLServer
美国 Microsoft 公司推出的一种关系型数据库系统。SQL Server 是一个可扩展的、高性能的、为分布式客户机/服务器计算所设计的数据库管理系统,实现了与 WindowsNT 的有机结合,提供了基于事务的企业级信息管理系统方案。SQL Server 的基本语法和 MySQL 基本相同。
(1)高性能设计,可充分利用 WindowsNT 的优势。
(2)系统管理先进,支持 Windows 图形化管理工具,支持本地和远程的系统管理和配置。
(3)强壮的事务处理功能,采用各种方法保证数据的完整性。
(4)支持对称多处理器结构、存储过程、ODBC,并具有自主的 SQL 语言。 SQLServer
以其内置的数据复制功能、强大的管理工具、与 Internet 的紧密集成和开放的系统结构为广大的用户、开发人员和系统集成商提供了一个出众的数据库平台。
6.2 安装
6.2.1 安装要求

6.2.2 安装步骤
1)下载 Microsoft SQL Server 2017 Red Hat 存储库配置文件
sudo curl -o /etc/yum.repos.d/mssql-server.repo https://packages.microsoft.com/config/rhel/7/mssql-server-2017.repo
2)执行安装
yum install -y mssql-server
3)完毕之后运行做相关配置
sudo /opt/mssql/bin/mssql-conf setup
6.2.3 安装配置

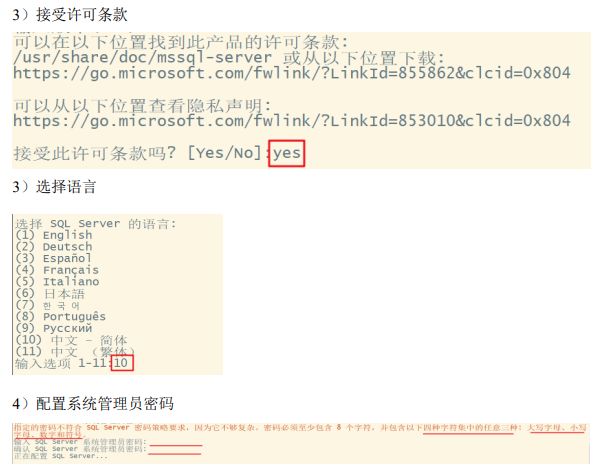

6.2.4 安装命令行工具
1)下载存储库配置文件
sudo curl -o /etc/yum.repos.d/msprod.repo
https://packages.microsoft.com/config/rhel/7/prod.repo
2)执行安装
sudo yum remove mssql-tools unixODBC-utf16-devel
sudo yum install mssql-tools unixODBC-devel
3)配置环境变量
sudo vim /etc/profile.d/my_env.sh
#添加环境变量
export PATH="$PATH:/opt/mssql-tools/bin
source /etc/profile.d/my_env.sh
4)进入命令行
sqlcmd -S localhost -U SA -P 密码 # 用命令行连接
6.3 简单实用
6.3.1 启停命令
#启动
systemctl start mssql-server
#重启
systemctl restart mssql-server
#停止
systemctl stop mssql-server
#查看状态
systemctl status mssql-server
#具体配置路径
/opt/mssql/bin/mssql-conf
6.3.2 创建数据库

6.4 DataX导入导出案例
6.4.1 数据准备
创建表并插入数据
create table student(id int,name varchar(25))
go
insert into student values(1,'zhangsan')
go
6.4.2 读取 SQLServer 的数据导入到 HDFS
1)编写配置文件
[atguigu@hadoop102 datax]$ vim job/sqlserver2hdfs.json
{
"job": {
"content": [{
"reader": {
"name": "sqlserverreader",
"parameter": {
"column": [
"id",
"name"
],
"connection": [{
"jdbcUrl": [
"jdbc:sqlserver://hadoop2:1433;DatabaseName=datax"
],
"table": [
"student"
]
}],
"username": "root",
"password": "000000"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [{
"name": "id",
"type": "int"
},
{
"name": "name",
"type": "string"
}
],
"defaultFS": "hdfs://hadoop102:9000",
"fieldDelimiter": "\t",
"fileName": "sqlserver.txt",
"fileType": "text",
"path": "/",
"writeMode": "append"
}
}
}],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
6.4.2 读取 SQLServer 的数据导入 MySQL
[atguigu@hadoop102 datax]$ vim job/sqlserver2mysql.json
{
"job": {
"content": [{
"reader": {
"name": "sqlserverreader",
"parameter": {
"column": [
"id",
"name"
],
"connection": [{
"jdbcUrl": [
"jdbc:sqlserver://hadoop2:1433;DatabaseName=datax"
],
"table": [
"student"
]
}],
"username": "root",
"password": "000000"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": ["*"],
"connection": [{
"jdbcUrl": "jdbc:mysql://hadoop102:3306/datax",
"table": ["student"]
}],
"password": "000000",
"username": "root",
"writeMode": "insert"
}
}
}],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
7、DB2
7.1 什么是db2

7.2 db2 数据库对象关系

7.3 安装前的准备
7.3.1 安装依赖
um install -y bc binutils compat-libcap1 compat-libstdc++33 elfutils-libelf elfutils-libelf-devel fontconfig-devel glibc glibc-devel ksh libaio libaio-devel libX11 libXau libXi libXtst libXrender libXrender-devel libgcc libstdc++ libstdc++-devel libxcb make smartmontools sysstat kmod* gcc-c++ compat-libstdc++-33 libstdc++.so.6 kernel-devel pam-devel.i686 pam.i686 pam32*
7.3.2 修改配置文件 sysctl.conf
[root@hadoop102 module]# vim /etc/sysctl.conf
删除里面的内容,添加如下内容:
net.ipv4.ip_local_port_range = 9000 65500
fs.file-max = 6815744
kernel.shmall = 10523004
kernel.shmmax = 6465333657
kernel.shmmni = 4096
kernel.sem = 250 32000 100 128
net.core.rmem_default=262144
net.core.wmem_default=262144
net.core.rmem_max=4194304
net.core.wmem_max=1048576
fs.aio-max-nr = 1048576
7.3.3 修改配置文件 limits.conf
[root@hadoop102 module]# vim /etc/security/limits.conf
在文件末尾添加:
* soft nproc 65536
* hard nproc 65536
* soft nofile 65536
* hard nofile 65536
重启机器生效。
7.3.4 上传安装包并解压
[root@hadoop102 software]# tar -zxvf v11.5.4_linuxx64_server_dec.tar.gz -C /opt/module/
[root@hadoop102 module]# chmod 777 server_dec
7.4 安装




7.5 DataX 导入导出案例
7.5.1 注册 db2 驱动
datax 暂时没有独立插件支持 db2,需要使用通用的使用 rdbmsreader 或 rdbmswriter。
1)注册 reader 的 db2 驱动
[atguigu@hadoop102 datax]$ vim /opt/module/datax/plugin/reader/rdbmsreader/plugin.json
#在 drivers 里添加 db2 的驱动类
"drivers":["dm.jdbc.driver.DmDriver", "com.sybase.jdbc3.jdbc.SybDriver",
"com.edb.Driver","com.ibm.db2.jcc.DB2Driver"]
2)注册 writer 的 db2 驱动
[atguigu@hadoop102 datax]$ vim /opt/module/datax/plugin/writer/rdbmswriter/plugin.json
#在 drivers 里添加 db2 的驱动类
"drivers":["dm.jdbc.driver.DmDriver", "com.sybase.jdbc3.jdbc.SybDriver",
"com.edb.Driver","com.ibm.db2.jcc.DB2Driver"]
7.5.2 读取 DB2 的数据导入到 HDFS
[atguigu@hadoop102 datax]$ vim job/db2-2-hdfs.json
{
"job": {
"content": [{
"reader": {
"name": "rdbmsreader",
"parameter": {
"column": [
"ID",
"NAME"
],
"connection": [{
"jdbcUrl": [
"jdbc:db2://hadoop2:50000/sample"
],
"table": [
"STUDENT"
]
}],
"username": "db2inst1",
"password": "atguigu"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [{
"name": "id",
"type": "int"
},
{
"name": "name",
"type": "string"
}
],
"defaultFS": "hdfs://hadoop102:9000",
"fieldDelimiter": "\t",
"fileName": "db2.txt",
"fileType": "text",
"path": "/",
"writeMode": "append"
}
}
}],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
7.5.3 读取 DB2 的数据导入 MySQL
[atguigu@hadoop102 datax]$ vim job/db2-2-mysql.json
{
"job": {
"content": [{
"reader": {
"name": "rdbmsreader",
"parameter": {
"column": [
"ID",
"NAME"
],
"connection": [{
"jdbcUrl": [
"jdbc:db2://hadoop2:50000/sample"
],
"table": [
"STUDENT"
]
}],
"username": "db2inst1",
"password": "atguigu"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": ["*"],
"connection": [{
"jdbcUrl": "jdbc:mysql://hadoop102:3306/datax",
"table": ["student"]
}],
"password": "000000",
"username": "root",
"writeMode": "insert"
}
}
}],
"setting": {
"speed": {
"channel": "1"
}
}
}
}