高并发下缓存失效问题--(缓存穿透,缓存雪崩,缓存击穿)
1 缓存穿透
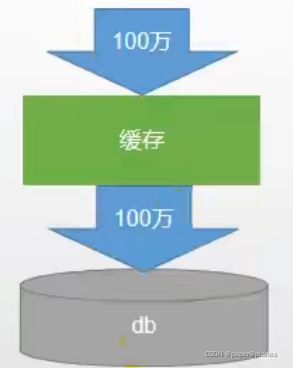
指查询一个一定不存在的数据,由于缓存是不命中,将去查询数据库,但是数据库也无此记录,我们没有将这次查询的null写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存的意义
1.1 风险
利用不存在的数据进行攻击,数据库瞬时压力增大,最终导致崩溃
1.2 解决
null结果缓存,并加入短暂过期时间
set(String key, String value, long timeout, TimeUnit unit)2 缓存雪崩
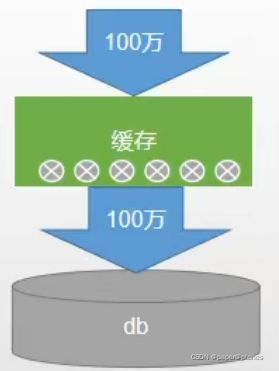
缓存雪崩是指在我们设置缓存时key采用了相同的过期时间,导致缓存在某一时刻同时失效,请求全部转发到DB,DB瞬时压力过重雪崩。
2. 1 解决
原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
3 缓存击穿
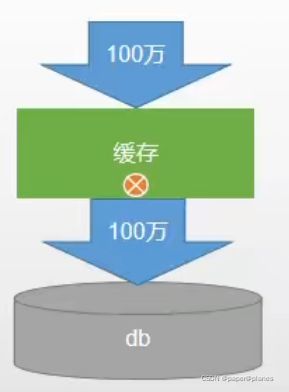
对于一些设置了过期时间的key,如果这些key可能会在某些时间点被超高并发地访问,是一种非常“热点”的数据。
如果这个key在大量请求同时进来前正好失效,那么所有对这个key的数据查询都落到db,我们称为缓存击穿。
3.1 解决
加锁:大量并发只让一个去查,其他人等待,查到以后释放锁,其他人获取到锁,先查缓存,就会有数据,不用去db
//加锁
//只要是同一把锁,就能锁住需要这个锁的所有线程
//1、synchronized(this): SpringBoot所有的组件在容器中都是单例的。
synchronized(this){
//得到锁以后,我们应该再去缓存中确定一次,如果没有才需要继续查询
}4 分布式锁
4.1 分布式下如何加锁:
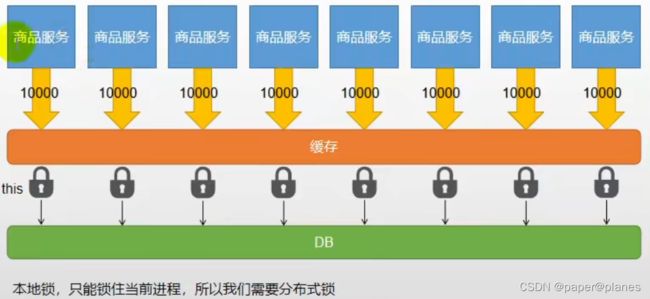
4.2 本地锁在分布式下的问题:
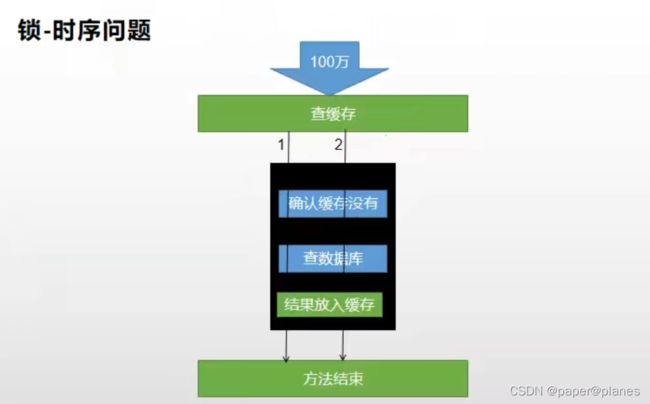
因此,在加本地锁后,当用户查询数据结束前,要将结果再查询放入到缓存中 ,这样可以解决穿透问题。
分布式下,本地锁只能锁住自己,不能锁住别人,在并发请求下会导致多个查询数据库。
4.3 分布式锁演进
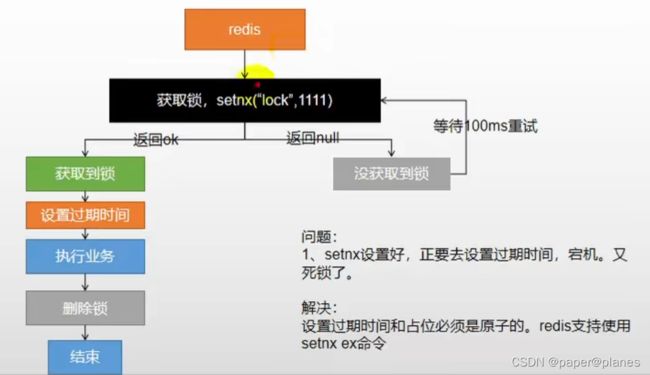
基本原理:
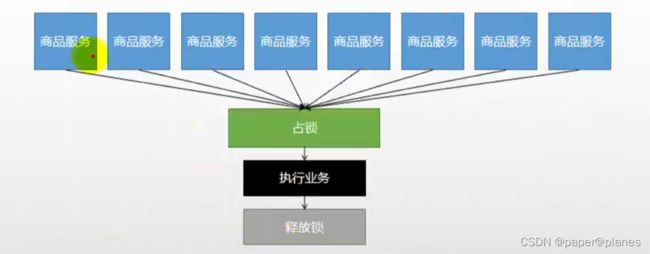
我们可以同时去一个地方“占坑”,如果占到,就执行逻辑。否则就必须等待,直到释放锁。
“占坑”可以去redis,可以去数据库,可以去任何大家都能访问的地方。
等待可以自旋的方式。
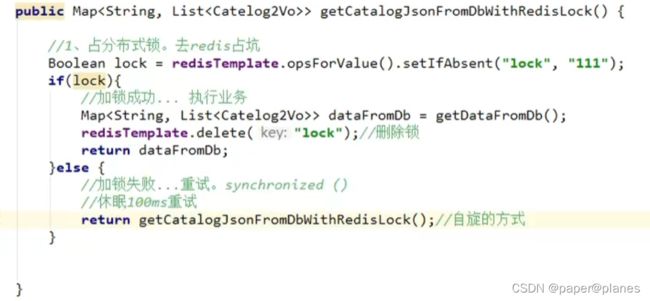
阶段一:
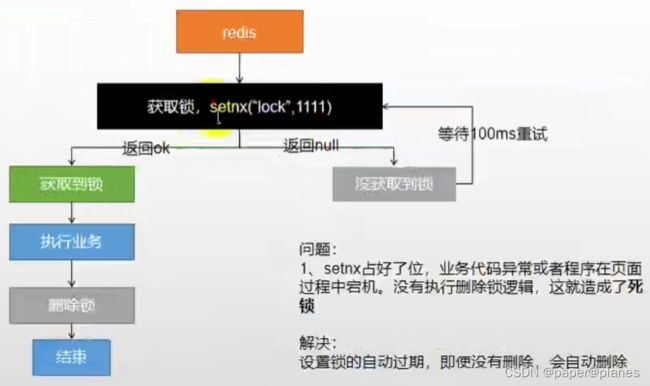
//1、占分布式锁。去redis占坑
redisTemplate.opsForValue().setIfAbsent(String key, String value);
if(lock){
//加锁成功... 执行业务
//删除锁
redisTemplate.delete(String key);
//返回方法
}else{
//加锁失败...重试。synchronized()
//休眠100ms重试
//返回(自旋的方式)
}示例代码:
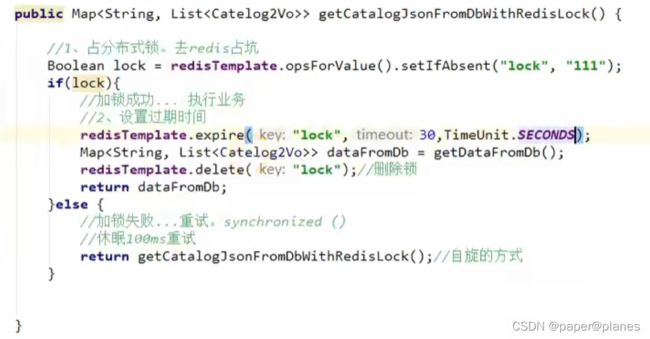
阶段二:
//1、占分布式锁。去redis占坑
redisTemplate.opsForValue().setIfAbsent(String key, String value);
if(lock){
//加锁成功... 执行业务
//2、设置过期时间
redisTemplate.expire(String Key, lopg timeout, TimeUnit unit);
//删除锁
redisTemplate.delete(String key);
//返回方法
}else{
//加锁失败...重试。synchronized()
//休眠100ms重试
//返回(自旋的方式)
}示例代码:
阶段三:
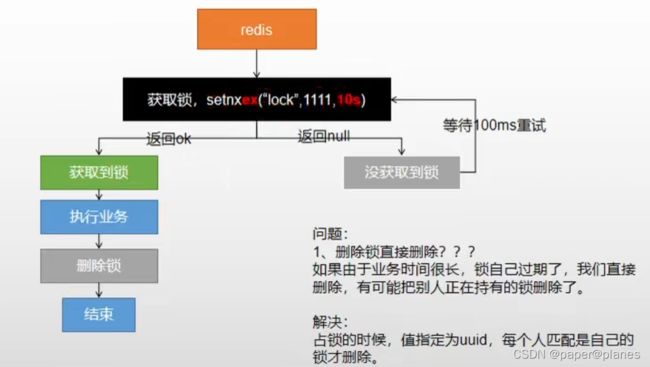
//1、占分布式锁。去redis占坑
redisTemplate.opsForValue().setIfAbsent(String key, String value, long timeout, TimeUnit unit);
if(lock){
//加锁成功... 执行业务
//2、设置过期时间,必须和加锁是同步的,原子的
redisTemplate.expire(String Key, lopg timeout, TimeUnit unit);
//删除锁
redisTemplate.delete(String key);
//返回方法
}else{
//加锁失败...重试。synchronized()
//休眠100ms重试
//返回(自旋的方式)
}示例代码:
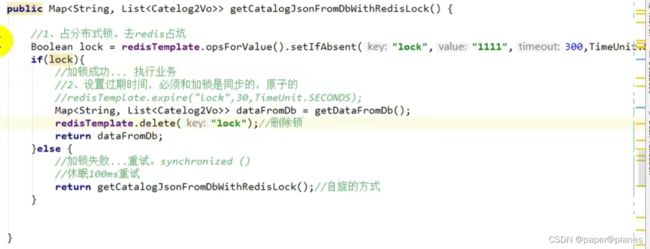
阶段四:
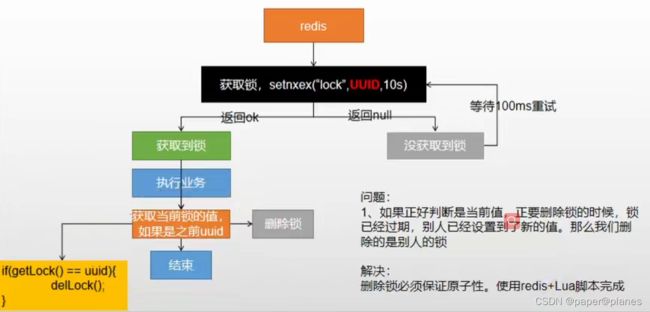
示例代码:
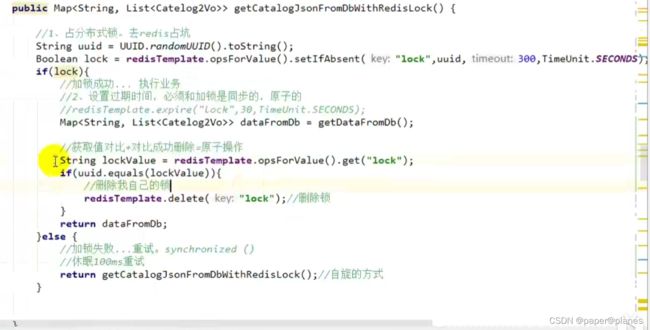
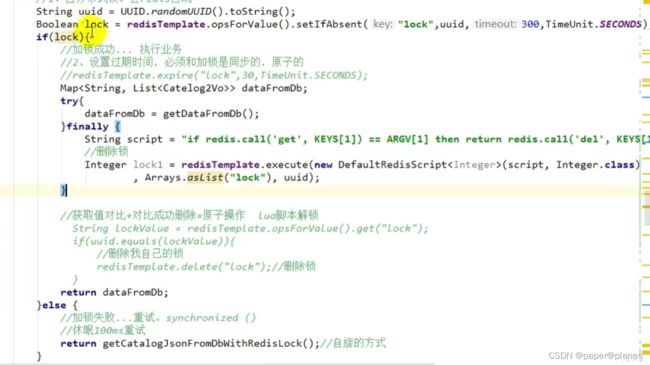
阶段五-最终形态:
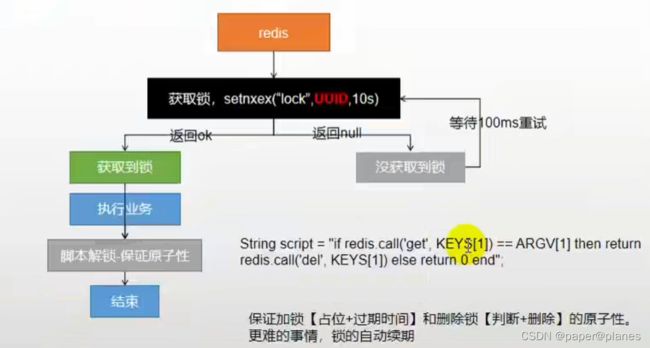
示例代码:
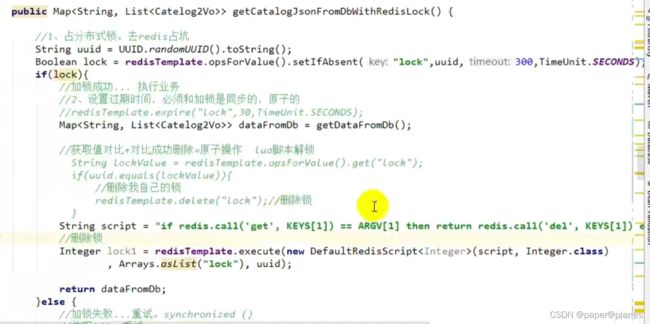
进一步优化:
try{}finally{} 无论业务是执行还是崩溃,最终还是全部进行解锁。