特征工程
特征工程(Feature Engineering):将数据在转换为能更好的表示潜在问题的特征,从而提高机器学习性能。
1. 数据理解
目的:探索数据,了解数据,主要在 EDA 阶段完成。
1.1. 定性数据:描述性质
-
a) 定类:按名称分类——血型、城市
-
b) 定序:有序分类——成绩(A B C)
1.2. 定量数据:描述数量
-
a) 定距:可以加减——温度、日期
-
b) 定比:可以乘除——价格、重量
2. 数据清洗
目的:提高数据质量,降低算法用错误数据建模的风险。
2.1. 特征变换:模型无法处理或不适合处理
-
a) 定性变量编码:Label Encoder;Onehot Encoder;Distribution coding;
-
b) 标准化和归一化:z分数标准化(标准正太分布)、min-max 归一化;
2.2 缺失值处理:增加不确定性,可能会导致不可靠输出
-
a) 不处理:少量样本缺失;
-
b) 删除:大量样本缺失;
-
c) 补全:(同类)均值/中位数/众数补全;高维映射(One-hot);模型预测;最邻近补全; 矩阵补全(R-SVD);
2.3. 异常值处理:减少脏数据
-
a) 简单统计:如 describe() 的统计描述;散点图等;
-
b) 3∂ 法则(正态分布)/箱型图截断;
-
c) 利用模型进行离群点检测:聚类、K近邻、One Class SVM、Isolation Forest;
2.4. 其他:删除无效列/更改dtypes/删除列中的字符串/将时间戳从字符串转换为日期时间格式等
3. 特征构造
目的:增强数据表达,添加先验知识。
3.1. 统计量特征: a) 计数、求和、比例、标准差;
3.2. 时间特征: a) 绝对时间、相对时间、节假日、双休日;
3.3. 地理信息: a) 分桶;
3. 4. 非线性变换: a) 取 log/平方/根号;
3. 5. 数据分桶: a) 等频/等距分桶、Best-KS 分桶、卡方分桶;
3. 6. 特征组合
4. 特征选择
目的:降低噪声,平滑预测能力和计算复杂度,增强模型预测性能。
4.1. 过滤式(Filter):先用特征选择方法对初识特征进行过滤然后再训练学习器,特征 选择过程与后续学习器无关。
a) Relief/方差选择/相关系数/卡方检验/互信息法
4.2. 包裹式(Wrapper):直接把最终将要使用的学习器的性能作为衡量特征子集的评价准则,其目的在于为给定学习器选择最有利于其性能的特征子集。
a) Las Vegas Wrapper(LVM)
4 3. 嵌入式(Embedding):结合过滤式和包裹式方法,将特征选择与学习器训练过程 融为一体,两者在同一优化过程中完成,即学习器训练过程中自动进行了特征选择。
a) LR+L1或决策树
5. 类别不平衡
缺点:少类别提供信息太少,使模型没有学会如何判别少数类。
5. 1. 扩充数据集;
5.2. 尝试其他评价指标:AUC等;
5.3. 调整θ值;
5. 4. 重采样:过采样/欠采样;
5.5. 合成样本:SMOTE;
5.6. 选择其他模型:决策树等;
5.7. 加权少类别让样本错分代价;
5.8. 创新: a) 将大类分解成多个小类; b) 将小类视为异常点,并用异常检测建模。
一、常见的特征工程包括:
1.异常处理:
- 通过箱线图(或 3-Sigma)分析删除异常值;
- BOX-COX 转换(处理有偏分布);
- 长尾截断;
2.特征归一化/标准化:
- 标准化(转换为标准正态分布);
- 归一化(换到 [0,1] 区间);
- 针对幂律分布,可以采用公式:

3.数据分桶:
- 等频分桶;
- 等距分桶;
- Best-KS 分桶(类似利用基尼指数进行二分类);
- 卡方分桶;
4.缺失值处理:
- 不处理(针对类似 XGBoost 等树模型);
- 删除(缺失数据太多);
- 插值补全,包括均值/中位数/众数/建模预测/多重插补/压缩感知补全/矩阵补全等;
- 分箱,缺失值一个箱;
5.特征构造:
- 构造统计量特征,报告计数、求和、比例、标准差等;
- 时间特征,包括相对时间和绝对时间,节假日,双休日等;
- 地理信息,包括分箱,分布编码等方法;
- 非线性变换,包括 log/ 平方/ 根号等;
- 特征组合,特征交叉;
6.特征筛选
- 过滤式(filter):先对数据进行特征选择,然后在训练学习器,常见的方法有 Relief/方差选择发/相关系数法/卡方检验法/互信息法;
- 包裹式(wrapper):直接把最终将要使用的学习器的性能作为特征子集的评价准则,常见方法有 LVM(Las Vegas Wrapper) ;
- 嵌入式(embedding):结合过滤式和包裹式,学习器训练过程中自动进行了特征选择,常见的有 lasso 回归;
7.降维
- PCA/ LDA/ ICA;
- 特征选择也是一种降维。
二、具体操作
删除异常值
# 这里我包装了一个异常值处理的代码,可以随便调用。
def outliers_proc(data, col_name, scale=3):
"""
用于截尾异常值, 默认用box_plot(scale=3)进行清洗
param:
data: 接收pandas数据格式
col_name: pandas列名
scale: 尺度
"""
data_col = data[col_name]
Q1 = data_col.quantile(0.25) # 0.25分位数
Q3 = data_col.quantile(0.75) # 0,75分位数
IQR = Q3 - Q1
data_col[data_col < Q1 - (scale * IQR)] = Q1 - (scale * IQR)
data_col[data_col > Q3 + (scale * IQR)] = Q3 + (scale * IQR)
return data[col_name]
num_data['power'] = outliers_proc(num_data, 'power')
特征构造
汽车的使用时间特征:createDate-regDate, 反应汽车使用时间,一般来说与价格成反比, 但是要注意这一块中的问题就是时间格式, regDateFalse这个字段有些是0月,如果忽略错误计算的话,使用时间有一些会是空值, 当然可以考虑删除这些空值


计算某品牌的销售统计量:

连续值经常离散化或者分离成“箱子”进行分析, 为什么要做数据分桶呢?
- 离散后稀疏向量内积乘法运算速度更快,计算结果也方便存储,容易扩展;
- 离散后的特征对异常值更具鲁棒性,如 age>30 为 1 否则为 0,对于年龄为 200 的也不会对模型造成很大的干扰;
- LR 属于广义线性模型,表达能力有限,经过离散化后,每个变量有单独的权重,这相当于引入了非线性,能够提升模型的表达能力,加大拟合;
- 离散后特征可以进行特征交叉,提升表达能力,由 M+N 个变量编程 M*N 个变量,进一步引入非线形,提升了表达能力;
- 特征离散后模型更稳定,如用户年龄区间,不会因为用户年龄长了一岁就变化
当然还有很多原因,LightGBM 在改进 XGBoost 时就增加了数据分桶,增强了模型的泛化性

归一化处理:
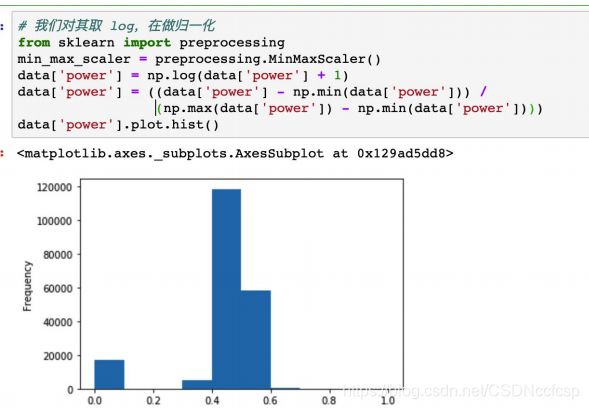
One-Hot 编码
特征选择:过滤式
Filter:过滤法,按照发散性或者相关性对各个特征进行评分,设定阈值或者待选择阈值的个数,选择特征。

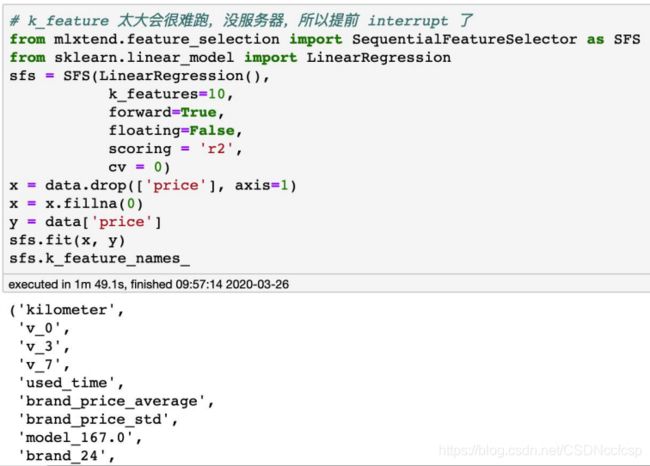
特征选择:包裹式
主要思想:包裹式从初始特征集合中不断的选择特征子集,训练学习器,根据学习器的性能来对子集进行评价,直到选择出最佳的子集。包裹式特征选择直接针对给定学习器进行优化。
主要方法:递归特征消除算法, 基于机器学习模型的特征排序
总结
这部分需要好好消化,好多方法都是第一次听说,后面还要补充笔记,小白要加油!datawhale大佬优秀~
特征工程是比赛中最至关重要的的一块,特别的传统的比赛,大家的模型可能都差不多,调参带来的效果增幅是非常有限的,但特征工程的好坏往往会决定了最终的排名和成绩。
特征工程的主要目的还是在于将数据转换为能更好地表示潜在问题的特征,从而提高机器学习的性能。比如,异常值处理是为了去除噪声,填补缺失值可以加入先验知识等。
特征构造也属于特征工程的一部分,其目的是为了增强数据的表达。
有些比赛的特征是匿名特征,这导致我们并不清楚特征相互直接的关联性,这时我们就只有单纯基于特征进行处理,比如装箱,groupby,agg 等这样一些操作进行一些特征统计,此外还可以对特征进行进一步的 log,exp 等变换,或者对多个特征进行四则运算(如上面我们算出的使用时长),多项式组合等然后进行筛选。由于特性的匿名性其实限制了很多对于特征的处理,当然有些时候用 NN 去提取一些特征也会达到意想不到的良好效果。
对于知道特征含义(非匿名)的特征工程,特别是在工业类型比赛中,会基于信号处理,频域提取,丰度,偏度等构建更为有实际意义的特征,这就是结合背景的特征构建,在推荐系统中也是这样的,各种类型点击率统计,各时段统计,加用户属性的统计等等,这样一种特征构建往往要深入分析背后的业务逻辑或者说物理原理,从而才能更好的找到 magic。
当然特征工程其实是和模型结合在一起的,这就是为什么要为 LR NN 做分桶和特征归一化的原因,而对于特征的处理效果和特征重要性等往往要通过模型来验证。
总的来说,特征工程是一个入门简单,但想精通非常难的一件事。