Elasticsearch基础2——es配置文件、jvm配置文件、log4j2.properties配置文件详解
文章目录
- 一、配置文件详解
-
- 1.1 elasticsearch.yml文件
-
- 1.1. 1 基础参数
-
- 1.1.1.1 自定义数据/日志目录
- 1.1.1.2 锁定物理内存
- 1.1.1.3 跨域设置
- 1.1.1.4 其他参数
- 1.1.2 集群类
- 1.1.3 分片类
- 1.1.4 IP绑定类
- 1.1.5 端口类
- 1.1.6 交互类
- 1.1.5 Xpcak安全认证
-
- 1.1.5.1 xpack内置用户
- 1.1.5.2 xpack功能使用
- 1.1.5.3 安全功能核心参数
-
- 1.1.5.3.1 开启安全验证功能,密码访问
- 1.1.5.3.2 开启ssl证书认证,https访问
- 1.1.5.3.3 开启传输层认证
- 1.2 jvm.options文件
-
- 1.2.1 jvm.option文件参数释义
-
- 1.2.1.1 jvm日志配置
- 1.2.1.2 jvm其他参数
- 1.2.2 设置jvm大小
- 1.2.2.1 自定义选项文件设置
- 1.2.2.2 环境变量设置
- 1.3 log4j2.properties文件
-
- 1.3.1 基本参数
- 1.3.2 日志滚动策略
- 1.3.3 日志删除策略
- 二、调试报错积累
-
- 2.1 调整默认虚拟内存大小
- 2.2 调整文件描述符大小
- 2.3 UUID不一致
- 2.4 进程重复启动
- 2.5 客户端不信任证书日志刷频
一、配置文件详解
- 配置文件参数非常多,尤其是集群设置,本篇只先了解基础参数使用,涉及集群相关的后面专门讲集群时再学习。
- 三大核心配置文件:
- Elasticsearch 有三个重要配置文件需要了解,elasticsearch.yml、jvm.options 和log4j2.properties,默认位于 config 目录下。
- elasticsearch.yml文件:配置 Elasticsearch。
- jvm.options文件: 配置 Elasticsearch 依赖的JVM 信息。
- log4j2.properties文件:配置 Elasticsearch 日志记录中的各个属性。
注:上述文件位于 config 目录下,这是默认位置。默认位置取决于我们安装Elasticsearch 时是否基于下载的 tar.gz 包或 zip 包,如果是,则配置目录默认位置为Ses home/config。如果用户想自定义配置目录的位置,则可以通过 es path conf 环境变量进行更改,如下所示:
1.1 elasticsearch.yml文件
1.1. 1 基础参数
1.1.1.1 自定义数据/日志目录
配置参数:
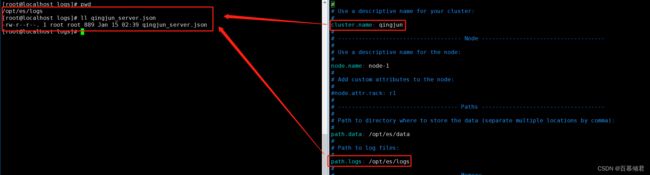
- path.data:数据目录
- path.logs:日志目录
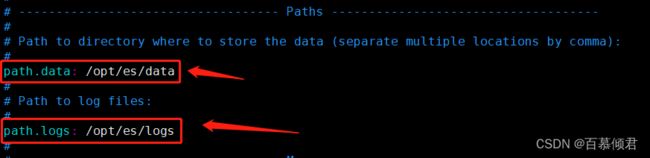
1.默认情况下,数据、日志目录都在安装目录下。
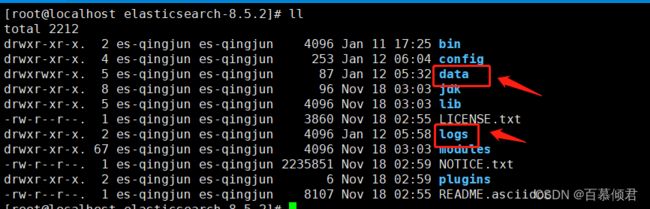
2.我们也可以自定义数据、日志存放位置。使用root用户创建数据、日志存在目录、并修改这两个目录的属主、属组为es用户。
[root@localhost opt]# mkdir -pv /opt/es/data
[root@localhost opt]# mkdir -pv /opt/es/logs
[root@localhost opt]# chown -R es-qingjun:es-qingjun /opt/es/
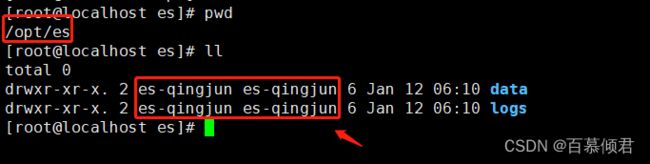
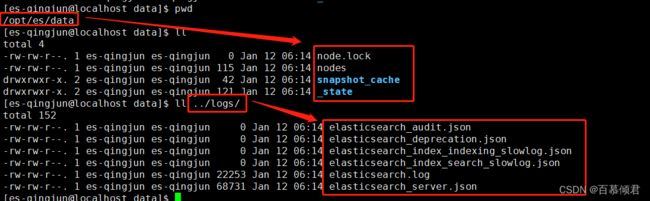
3.切换至es用户,再次启动es服务,数据和日志将会写入这两个目录。
[root@localhost es]# su - es-qingjun
[es-qingjun@localhost ~]$ cd /opt/elasticsearch-8.5.2/
#启动es
[es-qingjun@localhost elasticsearch-8.5.2]$ ./bin/elasticsearch -d
1.1.1.2 锁定物理内存
配置参数:
- bootstrap.memory_lock
释义:
- 锁定物理内存,在es运行后锁定使用的内存大小,锁定大小一本为服务器内存的一半。当系统物理内存空间不足,es不会使用交换分区,避免频繁的交换导致的IOPS升高,属于性能上的优化。
* 默认是不打开,第一次打开时,会有个报错,需要使用root用户设置一些参数。报错处理:
- 需要修改操作系统资源配置文件/etc/security/limits.conf参数:
- soft参数:代表警告的设定,可以超过这个设定值,但是超过后会有警告。一般soft的值比hard小,也可相等。
- hard参数:代表严格的设定,不允许超过这个设定的值。
- nproc参数:是操作系统级别对每个用户创建的进程数的限制。
- nofile参数:表示 max open file,是每个进程可以打开的文件数的限制。
- memlock参数:表示 max locked memory,对应用程序来说,可以将内存中一些对程序性能影响较大的数据lock起来,避免非预期的页面回收或者换入/换出引起性能波动。
![]()
1.切换至root用户,修改Linux资源限制配置文件参数。
#添加如下几行,重新连接服务器才能生效。
[root@localhost ~]# vim /etc/security/limits.conf
* hard nofile 65536
* soft nofile 65536
* hard nproc 32000
* soft nproc 32000
* hard memlock unlimited
* soft memlock unlimited
#取消注释,配置数值。
[root@localhost ~]# vim /etc/systemd/system.conf
DefaultLimitNOFILE=65536
DefaultLimitNPROC=32000
DefaultLimitMEMLOCK=infinity
#重新读取配置文件。
[root@localhost ~]# /bin/systemctl daemon-reload
2.重新连接服务器才能生效以上配置,切换es用户启动服务。
1.1.1.3 跨域设置
配置参数:
- http.cors.enabled: true 【是否开启跨域访问】
- http.cors.allow-origin: “*” 【开启跨域后,能访问es的地址限制,*号表示无限制】
参数释义:
- 8.x版本的配置文件中没有该参数,但是在搭建实测过程,官方并没有默认开启,需要我们手动添加启动。
1.1.1.4 其他参数
| 参数 | 释义 |
|---|---|
| node.name | 配置ES集群内的节点名称,同一个集群内的节点名称要具备唯一性。 |
| path.work:/path/to/work | 设置临时文件的存储路径,默认是es根目录下的work文件夹。(老版本) |
| node.data:true | 指定该节点是否存储索引数据,默认为true。 |
| node.master:true | 指定该节点是否有资格被选举成为node,一定要注意只是设置成有资格, 不代表该node一定就是master,默认是true。es是默认集群中的第一台机器为master,如果这台机挂了就会重新选举master。 |
| node.attr.rack: r1 | 集群个性化调优设置,用于后期集群进行分片分配时的过滤 |
| discovery.seed_hosts | 当节点启动时,传递一个初始主机列表来执行发现 |
| cluster.initial_master_nodes | 写入候选主节点的设备地址,来开启服务时就可以被选为主节点 |
| ingest.geoip.downloader.enabled | 是否开启es启动时更新地图相关的数据库。 |
1.1.2 集群类
| 参数 | 释义 |
|---|---|
| cluster.name | 配置ES集群名称,同一个集群内的所有节点集群名称必须一致。 |
| cluster.routing.allocation.same_shard.host:true | 防止同一个shard的主副本存在同一个物理机上。 |
| cluster.routing.allocation.node_initial_primaries_recoveries: 4 | 设置一个节点的并发数量,两种情况,第一种是在初始复苏过程中,默认是4个。 |
| cluster.routing.allocation.node_concurrent_recoveries: 4 | 设置一个节点的并发数量的第二种情况,在添加、删除节点及调整时。默认是4个。 |
| discovery.zen.minimum_master_nodes: 1 | 设置一个集群中主节点的数量,当多于三个节点时,该值可在2-4之间。 |
| discovery.zen.ping.timeout: 3s | 设置ping其他节点时的超时时间,网络比较慢时可将该值设大 |
| discovery.zen.ping.multicast.enabled: false | 禁止当前节点发现多个集群节点,默认值为true |
| cluster.fault_detection.leader_check.interval:2s | 设置每个节点在选中的主节点的检查之间等待的时间。默认为1秒 |
| discovery.cluster_formation_warning_timeout: 30s | 启动后30秒内,如果集群未形成,那么将会记录一条警告信息,警告信息未master not fount开始,默认为10秒 |
| cluster.join.timeout: 30s | 点发送请求加入集群后,在认为请求失败后,再次发送请求的等待时间,默认为60秒 |
| cluster.publish.timeout: 90s | 设置主节点等待每个集群状态完全更新后发布到所有节点的时间,默认为30秒。 |
| luster.routing.allocation.cluster_concurrent_rebalance:32 | 集群内同时启动的数据任务个数,默认是2个。 |
1.1.3 分片类
| 参数 | 释义 |
|---|---|
| index.number_of_shards:5 | 设置默认索引分片个数,默认为5片。主分片一经分配则无法更改。 |
| index.number_of_replicas:1 | 设置默认索引副本个数,默认为1个副本。 |
| indices.recovery.max_size_per_sec:0 | 设置数据恢复时限制的带宽,默认0及不限制,代表是无限的。 |
| indices.recovery.concurrent_streams: 5 | 限制从其它分片恢复数据时最大同时打开并发流的个数,默认为5。 |
| action.destructive_requires_name: false | 是否允许通配符删除索引 |
1.1.4 IP绑定类
| 参数 | 释义 |
|---|---|
| network.host:192.168.130.140 | 为es实例绑定特定的IP地址。 |
| network.bind_host:192.168.130.140 | 设置绑定的ip地址,可以是ipv4或ipv6的,默认为0.0.0.0,绑定这台机器的任何一个ip。 |
| network.publish_host:192.168.130.140 | 设置其他节点连接此节点的地址,若不设置,则自动获取,值必须是个真实的ip地址,也可以用不配。 |
1.1.5 端口类
| 参数 | 释义 |
|---|---|
| http.port:9200 | 设置对外服务的http端口,默认为9200。 |
| transport.tcp.port:9300 | 设置集群节点之间交互的tcp端口,默认是9300。 |
| transport.host: 0.0.0.0 | 允许任何人连接HTTP API |
1.1.6 交互类
| 参数 | 释义 |
|---|---|
| transport.tcp.compress:true | 设置是否压缩tcp传输时的数据,默认为false,不压缩。 |
| http.max_content_length:100mb | 设置内容的最大容量,默认100mb |
| http.enabled:false | 是否使用http协议对外提供服务,默认为true,开启。 |
| gateway.type: local | 设置gateway的类型,默认为本地文件系统,也可以设置分布式文件系统、Hadoop的HDFS或者AWS的都可以。 |
| gateway.recover_after_nodes: 3 | 在完全重新启动集群之后阻塞初始恢复,直到启动N个节点为止。 |
| gateway.recover_after_time: 5m | 设置初始化数据恢复进程的超时时间。默认是5分钟。 |
| gateway.expected_nodes: 2 | 设置该集群中节点的数量,默认为2个,一旦这N个节点启动,就会立即进行数据恢复。 |
1.1.5 Xpcak安全认证
- es的安全认证方式有很多,比如http-basic,search guard,shield等,这里主要讲Xpack安全认证功能。
- Xpack是什么?
- X-Pack是Elastic Stack扩展功能,提供了多项高级功能,例如安全性,警报,监视,报告,机器学习和许多其他功能。
- ES6.3之后的版本已经集成一起发布,不需要单独安装,并且基础基础级安全功能永久免费。
- xpack功能有很多,高级功能还是要收费的,这里不展开讲。



1.1.5.1 xpack内置用户
| 用户 | 角色 |
|---|---|
| elastic | 超级管理员 |
| apm_system | 为apm创建的用户 |
| kibana | 为kibana创建的用户 |
| logstash_system | 为logstash创建的用户 |
| beats_system | 为beats创建的用户 |
| kiremote_monitoring_userana | 为 monitoring 创建的用户 |
1.1.5.2 xpack功能使用
| 功能名称 | 配置参数 | 适用组件 | 配置文件 |
|---|---|---|---|
| 图形展示 | xpack.graph.enabled | 只使用于kibana组件 | kibana.yml |
| 报表统计 | pack.reporting.enabled | 只使用于kibana组件 | kibana.yml |
| 报警通知 | xpack.watcher.enabled | 只适用于elasticsearch组件 | elasticsearch.yml |
| 安全认证 | xpack.security.enabled | 适用于elk的三个组件 | 各组件配置文件 |
| 监控跟踪 | xpack.monitoring.enabled | 适用于elk的三个组件 | 各组件配置文件 |
| 设备资源分配 | xpack.ml.enabled | 适用于elasticsearch和kibana组件 | kibana.yml、elasticsearch.yml |
1.1.5.3 安全功能核心参数
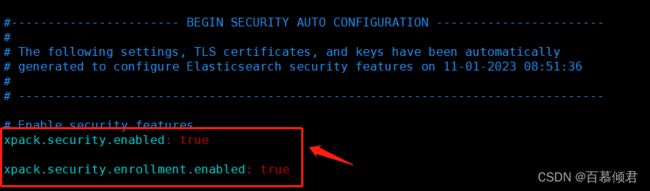
- es8.x版本默认开启了安全验证功能,有些核心参数需要了解一下。
1.1.5.3.1 开启安全验证功能,密码访问
配置参数:
- xpack.security.enabled: true,是总开关。
- xpack.security.enrollment.enabled: false
参数释义:
- 继6.8版本之后,es是默认开启了密码访问来提高安全性。
- 关闭则修成成false。
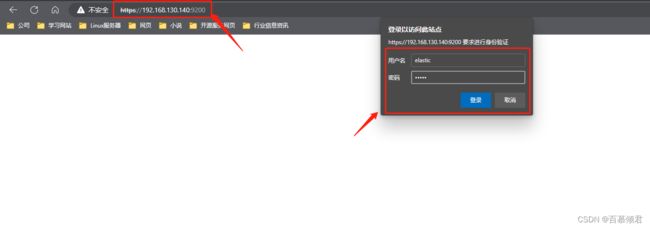

1.1.5.3.2 开启ssl证书认证,https访问
配置参数:
- xpack.security.http.ssl
参数释义:
- enabled:true。【开启,还是关闭】
- keystore.path:certs/http.p12【密钥存储库文件的存放位置】
老版本额外参数释义:
- truststore.path:certs/http.p12 【信任存储库文件的存放位置】
- verification_mode:full /certificate /none
- full:它验证所提供的证书是否由受信任的权威机构(CA)签名,并验证服务器的主机名(或IP地址)是否与证书中识别的名称匹配。
- certificate:它验证所提供的证书是否由受信任的机构(CA)签名,但不执行任何主机名验证。
- none:它不执行服务器证书的验证。
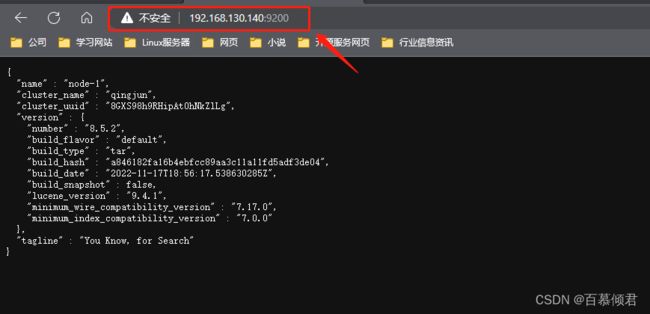
1.关闭状态,http访问。

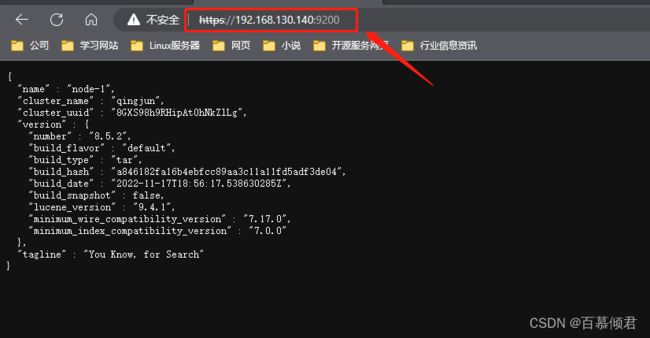
2.开启状态,https访问。

1.1.5.3.3 开启传输层认证
配置参数:
- xpack.security.transport.ssl
参数释义:
- enabled:true。【开启,还是关闭】
- keystore.path:certs/transport.p12【密钥存储库文件的存放位置】
- truststore.path:certs/transport.p12 【信任存储库文件的存放位置】
- verification_mode:full /certificate /none
- full:它验证所提供的证书是否由受信任的权威机构(CA)签名,并验证服务器的主机名(或IP地址)是否与证书中识别的名称匹配。
- certificate:它验证所提供的证书是否由受信任的机构(CA)签名,但不执行任何主机名验证。
- none:它不执行服务器证书的验证。

1.2 jvm.options文件
- jvm.option文件是一些程序运行依赖java环境,对这个java环境进行设置参数的配置文件,比如es依赖java环境,这里也就有个jvm文件,一些参数需要了解一下。
注意事项:
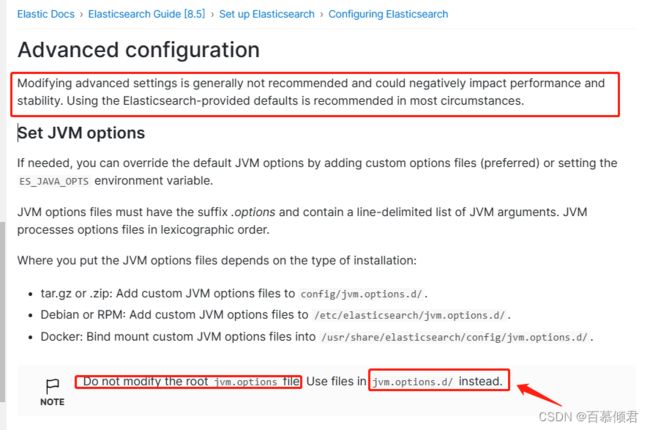
- jvm.option文件属高级配置,若需要自定义设置JVM选项,可以通过添加自定义选项文件或设置ES_JAVA_OPTS环境变量来重写默认JVM选项。不要直接修改jvm.option文件本身。
- 自定义JVM选项文件必须具有后缀options,并包含一个行分隔的JVM参数列表。JVM按字典顺序处理选项文件。
- JVM选项文件的放置位置取决于安装类型:
- tar.gz或zip安装:将自定义JVM选项文件添加到config/ivm.optionsd/目录下。
- Debian或RPM安装:将自定义JVM选项文件添加到/etc/elasticsearch/ivm.options.d/目录下。
- Docker安装:将挂载自定义JVM选项文件绑定到/usr/share/elasticsearch/config/ivmoptionsd/目录下。
- jvm.option文件使用官网
1.2.1 jvm.option文件参数释义
JVM参数定义标准:
- 以-开头的是标准JVM选项,JVM规范的选项;
- 以-X开头的都是非标准的,这种参数并不能保证在所有的JVM上都能实现,而且如果在新版本有什么改动也不会发布通知。
- 以-XX开头的都是不稳定的并且不推荐在生产环境中使用。这些参数的改动也不会发布通知。
- 布尔型(Bool)参数选项:
- “-XX:+”,表示打开启用该参数功能。比如-XX:+HeapDumpOnOutOfMemoryError,表示启用HeapDumpOnOutOfMemoryError功能。
- ”-XX:-" ,表示关闭停用该参数功能。比如-XX:-HeapDumpOnOutOfMemoryError,表示停用HeapDumpOnOutOfMemoryError功能。
- 数字型参数选项:
- “-XX:参数=数值”,数字可以是 m/M(兆字节),k/K(千字节),g/G(G字节)。
- 比如-XX:MaxPermSize=64m,表示给永久代最大值设置为64兆。
- String参数选项:
- “-XX:参数=设定”,通常用来指定一个文件,路径,或者一个命令列表。
- 比如-XX:HeapDumpPath=./java_pid.hprof,表示设置输出OOM dump文件路径为./java_pid.hprof。
| 参数名称 | 释义 | 备注 | 学习 |
|---|---|---|---|
| -Xms | 程序启动初始占用内存大小 | 若未配置此参数,则使用默认值。默认值是服务器物理内存的1/64。当然这个1/64值也可以通过MinHeapFreeRatio参数调整。当空余堆内存小于40%时,JVM就会增大堆直到-Xmx的最大限制。 | 重点,必须掌握 |
| -Xmx | 程序运行期间最大可占用的内存大小 | 若未配置此参数,则使用默认值。默认值是服务器物理内存的1/4。当然这个1/64值也可以通过MinHeapFreeRatio参数调整。.当空余堆内存大于70%时,JVM会减少堆直到 -Xms的最小限制。 | 重点,必须掌握 |
| -Xmn | 新生代大小(jdk 1.4或以上版本) | 增大新生代后,将会减小老年代大小。此值对系统性能影响较大。Sun官方推荐配置为整个堆的3/8。 | 了解即可 |
| -Xss | 每个线程的堆栈大小 | JDK5.0以后每个线程堆栈大小为1M,以前每个线程堆栈大小为256K,可以带 K, M 或 G单位。 | 重点,必须掌握 |
| -XX:+UseG1GC | 手动指定使用 G1 垃圾收集器执行内存回收任务。 | 跟G1垃圾收集器有关。 | 了解即可 |
| -Djava.io.tmpdir=${ES_TMPDIR} | JVM临时目录 | 默认就是在es安装家目录下。 | 了解即可 |
| -XX:+HeapDumpOnOutOfMemoryError | 使用该参数表示,当触发OOM时, 就会自动生成HeapDump文件,方便我们精确定位分析Java内存使用情况。 | 默认输出在存放类文件的根文件夹。 | 重点,必须掌握 |
| -XX:HeapDumpPath=data | 指定 dump 文件存储路径。 | 配合-XX:+HeapDumpOnOutOfMemoryError使用 | 重点,必须掌握 |
| -XX:+ExitOnOutOfMemoryError | 使用该参数时,当抛出OutOfMemoryError信息,则JVM将立即退出。属于调优参数 | 配合-XX:+HeapDumpOnOutOfMemoryError使用 | 了解即可 |
| -XX:ErrorFile=logs/hs_err_pid%p.log | 当JVM出现致命错误时,指定错误日志路径。 | 常规使用 | 了解即可 |
| -Xlog | GC 日志记录 | 如下图每个逗号为一个定义标签 | 了解即可。 |
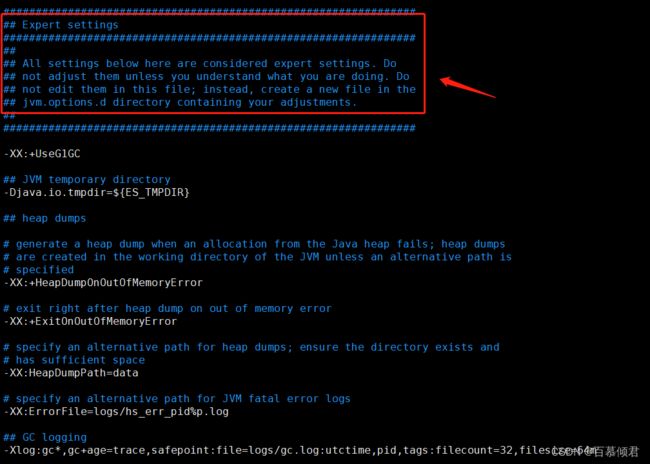
1.2.1.1 jvm日志配置
配置格式:
- -Xlog:[what],[output],[decorators][output-options[,…]]]]]
- 【what部分】:包含标签和日志级别。
- 【日志级别】:
- off:关闭。
- trace:包含trace,debug,info,warning,error所有日志。
- debug:包含debug,info,warning,error。
- info:包含info,warning,error。
- warning:包含warning,error。
- error:仅包含error。
- 【output部分】:包含三种输出。
- stdout: 标准输出。
- stderr: 标准错误输出。
- file=filename 输出到文件。
- 输出到文件可以配置output-options:filecount=50,filesize=100M。表示保留50个文件,每个文件100M。
- 【decorators部分】:可以使用的标记。
- 标记含义time 或者 t当前时间,ISO-8601格式utctime 或者 utcUTC时间uptime 或者 u启动到现在经过的时间,精确到毫秒timemillis 或者 tm毫秒时间戳。
示例:
-Xlog:gc* ,gc+age=trace,safepoint:file=logs/gc.log:utctime,pid,tags:filecount=32,filesize=64m
- gc* :gc* 等于gc*=info。若没定义日志级别,默认为info级别。
- gc+age=trace:输出同时包含且仅包含 gc 和 age 这两个标签的trace级别日志。
- filecount=32,filesize=64m:表示保留32个文件,每个文件64M。
其他示例:
- -Xlog:gc=info,表示仅包含 gc 一个标签的所有日志,info 级别的都会输出。
- -Xlog:gc*=info,表示包含 gc 标签的所有日志,info 级别的都会输出,就是上面说的 gc 相关的所有标签。
- -Xlog:gc+age=debug,表示同时包含且仅包含 gc 和 age 这两个标签的,debug 级别的才会输出。
- -Xlog:gc*=info,gc+heap=debug,gc+heap+region=debug,同时设置包含且仅包含 gc 和 heap 这两个标签的为 debug,包含且仅包含 gc 和 heap 和 region 这三个标签的设置为 debug ,剩下的包含 gc 标签的日志级别为 info 。
注意事项:
- 标签如果打错了,就会报错并退出
- 如果没有这种标签的组合(或者这个标签不能单独出现),则会报警,但是继续运行。
1.2.1.2 jvm其他参数
| 参数名称 | 释义 | 备注 |
|---|---|---|
| -XX:PermSize | 设置永久代初始值。 | 物理内存的1/64 |
| -XX:MaxPermSize | 设置永久代最大值 | 物理内存的1/4 |
| -XX:NewRatio | 新生代(包括Eden和两个Survivor区)与老年代的比值(除去永久代) | -XX:NewRatio=4表示新生代与老年代所占比值为1:4,新生代占整个堆栈的1/5,Xms=Xmx并且设置了Xmn的情况下,该参数不需要进行设置。 |
| -XX:SurvivorRatio | Eden区与Survivor区的大小比值 | 设置为8,则两个Survivor区与一个Eden区的比值为2:8,一个Survivor区占整个新生代的1/10 |
| -XX:LargePageSizeInBytes | 内存页的大小不可设置过大, 会影响Perm的大小 | =128m |
| -XX:+UseFastAccessorMethods | 原始类型的快速优化 | / |
| -XX:+DisableExplicitGC | 关闭System.gc() | / |
| -XX:MaxTenuringThreshold | 垃圾最大年龄 | 如果设置为0的话,则新生代对象不经过Survivor区,直接进入老年代。对于老年代比较多的应用,可以提高效率。如果将此值设置为一个较大值,则新生代对象会在Survivor区进行多次复制,这样可以增加对象再新生代的存活时间,增加在新生代即被回收的概率,该参数只有在串行GC时才有效。 |
| -XX:+AggressiveOpts | 加快编译 | / |
| -XX:+UseBiasedLocking | 锁机制的性能改善 | / |
| -Xnoclassgc | 禁用垃圾回收 | / |
| -XX:SoftRefLRUPolicyMSPerMB | 每兆堆空闲空间中SoftReference的存活时间 | 1S |
| -XX:PretenureSizeThreshold | 对象超过多大是直接在老年代分配 | 新生代采用Parallel Scavenge GC时无效,另一种直接在老年代分配的情况是大的数组对象,且数组中无外部引用对象。 |
| -XX:TLABWasteTargetPercent | TLAB占eden区的百分比 | 1% |
| -XX:+CollectGen0First | FullGC时是否先YGC | false |
| -XX:+UseParallelGC | Full GC采用parallel MSC | 参考GC参数 |
| -XX:+UseParNewGC | 设置新生代为并行收集 | 可与CMS收集同时使用,JDK 5.0以上,JVM会根据系统配置自行设置,所以无需再设置此值。 |
| -XX:ParallelGCThreads | 并行收集器的线程数 | 此值最好配置与处理器数目相等,同样适用于CMS |
| -XX:+UseParallelOldGC | 老年代垃圾收集方式为并行收集(Parallel Compacting) | JAVA 6出现的参数选项 |
| -XX:MaxGCPauseMillis | 每次新生代垃圾回收的最长时间(最大暂停时间) | 如果无法满足此时间,JVM会自动调整新生代大小,以满足此值. |
| -XX:+UseAdaptiveSizePolicy | 自动选择新生代区大小和相应的Survivor区比例 | 设置此选项后,并行收集器会自动选择新生代区大小和相应的Survivor区比例,以达到目标系统规定的最低相应时间或者收集频率等,此值建议使用并行收集器时,一直打开。 |
| -XX:GCTimeRatio | 设置垃圾回收时间占程序运行时间的百分比 | 公式为1/(1+n) |
| -XX:+ScavengeBeforeFullGC | Full GC前调用YGC | true |
| -XX:+UseConcMarkSweepGC | 使用CMS内存收集 | 测试中配置这个以后, -XX:NewRatio=4的配置失效了,原因不明,所以此时新生代大小最好用-Xmn设置 |
| -XX:+AggressiveHeap | 试图是使用大量的物理内存 | 长时间大内存使用的优化,能检查计算资源(内存, 处理器数量,至少需要256MB内存 |
| -XX:CMSFullGCsBeforeCompaction | 多少次后进行内存压缩 | 由于并发收集器不对内存空间进行压缩,整理,所以运行一段时间以后会产生“碎片”,使得运行效率降低 |
| -XX:+CMSParallelRemarkEnabled | 降低标记停顿 | / |
| -XX+UseCMSCompactAtFullCollection | 在FullGC的时候对老年代的压缩 | CMS是不会移动内存的, 因此这个非常容易产生碎片,导致内存不够用,因此内存的压缩这个时候就会被启用。增加这个参数是个好习惯。可能会影响性能,但是可以消除碎片。 |
| -XX:+UseCMSInitiatingOccupancyOnly | 使用手动定义初始化定义开始CMS收集 | 禁止hostspot自行触发CMS GC |
| -XX:CMSInitiatingOccupancyFraction=70 | 使用cms作为垃圾回收使用70%后开始CMS收集 | 该值的设置需要满足以下公式CMSInitiatingOccupancyFraction计算公式 |
| -XX:CMSInitiatingPermOccupancyFraction | 设置Perm Gen使用到达多少比率时触发 | 92 |
| -XX:+CMSIncrementalMode | 设置为增量模式 | 用于单CPU情况 |
| -XX:+CMSClassUnloadingEnabled | 永久代CMS方式GC | / |
| -XX:+PrintGC | GC日志输出 | 和-verbose:gc一样 |
| -XX:+PrintGCDetails | GC日志输出 | 日志更加详细 |
| -XX:+PrintGCTimeStamps | 输出GC的时间戳 | 配合上述PrintGC参数使用,或者写成-XX:+PrintGC:PrintGCTimeStamps类似的 |
| -XX:+PrintGC:PrintGCTimeStamps | / | 可与-XX:+PrintGC -XX:+PrintGCDetails混合使用 |
| -XX:+PrintGCApplicationStoppedTime | 打印垃圾回收期间程序暂停的时间。可与上面混合使用 | 输出形式:Total time for which application threads were stopped: 0.0468229 seconds |
| -XX:+PrintGCApplicationConcurrentTime | 打印每次垃圾回收前,程序未中断的执行时间 | 可与上面混合使用,输出形式:Application time: 0.5291524 seconds |
| -XX:+PrintHeapAtGC | 打印GC前后的详细堆栈信息 | / |
| -Xloggc:filename | 把相关日志信息记录到文件以便分析 | 与上面几个配合使用 |
| -XX:+PrintClassHistogram | 在控制台按下Ctrl+Break后,打印类的信息 | / |
| -XX:+PrintClassHistogramBeforeFullGC | FullGC前打印类信息 | |
| -XX:+PrintTLAB | 查看TLAB空间的使用情况 | / |
| XX:+PrintTenuringDistribution | 查看每次minor GC后新的存活周期的阈值 | / |
| -ea | 开启assert断言 | / |
| -Xprof | 性能诊断 | / |
| -Xrunhprof | 性能诊断 | / |
| -XX:+TraceClassLoading | 打印类加载过程的信息 | 类似 [Loaded java.util.AbstractList$Itr from /Library/Java/JavaVirtualMachines/jdk1.8.0_111.jdk/Contents/Home/jre/lib/rt.jar] |
| -XX:+TraceClassUnloading | 打印类卸载的过程信息 | / |
| Xbootclasspath | 指定加载不需要校验的类 | 跳过必要的类加载前的校验,能够减少加载时间,但是不安全 |
| -XX:+PrintCompilation | 打印Hotspot使用JIT 编译的方法名称 | / |
1.2.2 设置jvm大小
1.2.2.1 自定义选项文件设置
- JVM选项文件必须是以.options为后缀的,并包含以行分隔的JVM参数列表。
- 最简单的办法就是,查看jvm.options文件里的配置参数,将其复制到jvm.options.d目录下新建的xx.options文件,按照其格式进行修改。
注意事项:
- “-Xmx2g”:表示应用设置到所有版本。
- “17:-Xmx2g”:设置应用到17版本。
- “17-18:-Xmx2g”:设置应用到17到18之间的所有版本。
- “17-:-Xmx2g”:设置适用于Java 18及更高版本。
- 若配置文件配置格式错误未识别,es会启动失败。
- 使用JVM选项文件会覆盖默认设置。
1.修改之前的默认大小。
![]()
2.在jvm.options.d目录下创建一个文件qingjun.options,添加我想自定义的参数,这里就是自定义的JVM内存值,并修改其权限。
[root@localhost jvm.options.d]# vim qingjun.options
-Xms2g
-Xmx2g
[root@localhost jvm.options.d]# chown es-qingjun:es-qingjun qingjun.options

3.重启es,在查看日志,此时就是修改后的大小了。

1.2.2.2 环境变量设置
1.配置环境变量。
[root@localhost elasticsearch-8.5.2]# tail -n 4 /etc/profile
export PATH=$node_home/bin:$PATH
export es_home=/opt/elasticsearch-8.5.2
export PATH=$es_home/bin:$PATH
export ES_JAVA_OPTS="$ES_JAVA_OPTS -Djava.io.tmpdir=/opt/elasticsearch-8.5.2"
[root@localhost ~]# source /etc/profile
2.启动es,验证。

1.3 log4j2.properties文件
- 在es中,是使用 log4j2 来记录日志。我们可以使用 log4j2.properties 文件配置log4j2的相关参数,从而控制es日志的输出方式、配置方法、日志按类型输出到不同的文件中、慢查询日志配置方法等诸多指标。参数引用极多且复杂,日常使用只需要知道核心参数作用即可。
文件位置:
- 在es服务安装路径$HOME/config/ log4j2.properties
log4j2是什么?
- Apache Log4j2 是 Apache 软件基金会下的一个开源的基于 Java 的日志记录工具。Log4j2 是一个 Log4j 1.x 的重写,就是升级版,具备更多特性。
- 这里面的东西特别多,不展开讲,我们只需要了解它在es中是个什么角色就可以了。
es日志的输出位置配置信息:
- ${sys;es.logs.base_path}:解析为日志文件目录地址。
- ${sys:es.logs.cluster_name}:解析为群集名称(在默认配置中,用作日志文件名的前缀)。
- ${sys:es.logs.node_name}:解析为节点名称(如果显式地设置了节点名称)。
- ${sys:file.separator}:将被解析为路径分隔符。
- 我们可以在es主配置文件中引用这些属性来确定日志文件的存放位置。如下图所示:
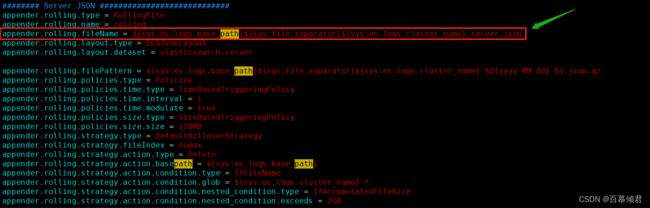
1.3.1 基本参数
[es-qingjun@localhost config]$ cat log4j2.properties
######## Server JSON ############################
##配置 RollingFile 的appender 属性。
appender.rolling.type = RollingFile
##集群日志的appender标签名称。
appender.rolling.name = rolling
##日志输出路径。(重点)
appender.rolling.fileName = ${sys:es.logs.base_path}${sys:file.separator}${sys:es.logs.cluster_name}_server.json
##使用JSON格式输出。(重点)
appender.rolling.layout.type = ECSJsonLayout
#Dataset是填充事件的标志。ECSJsonLayout中的dataset字段。在解析日志时,可以使用它更容易地区分不同类型的日志。
appender.rolling.layout.dataset = elasticsearch.server
#将日志滚动输出到/opt/es/logs/qingjun-2023-01-13-1.json.gz文件。日志文件会被压缩处理,i呈递增状态。(重点)
appender.rolling.filePattern = ${sys:es.logs.base_path}${sys:file.separator}${sys:es.logs.cluster_name}-%d{yyyy-MM-dd}-%i.json.gz
#使用基于时间戳的新增日志滚动策略。(重点)
appender.rolling.policies.time.type = TimeBasedTriggeringPolicy
#按天滚动新增日志。(重点)
appender.rolling.policies.time.interval = 1
#在日期时间上对齐标准,而不是按每 24 小时来新增一次滚动日志文件。
appender.rolling.policies.time.modulate = true
#按日志文件大小的策略来滚动新增日志文件。(重点)
appender.rolling.policies.size.type = SizeBasedTriggeringPolicy
#每生成256MB 的日志文件,就滚动新增日志一次。(重点)
appender.rolling.policies.size.size = 128MB
#每次新增滚动日志时执行删除日志文件动作。(重点)
appender.rolling.strategy.action.type = Delete
#仅当文件匹配时才删除日志文件。
appender.rolling.strategy.action.condition.type = IfFileName
#该配置仅用于删除日志文件。
appender.rolling.strategy.action.condition.glob = ${sys:es.logs.cluster_name}-*
#只有当日志目录下积累了较多日志时才删除。
appender.rolling.strategy.action.condition.nested_condition.type = IfAccumulatedFileSize
#压缩日志的条件是日志文件大小达到2 GB。(重点)
appender.rolling.strategy.action.condition.nested_condition.exceeds = 2GB
#以下参数官方没有给解释,可忽略直接使用默认就行。
appender.rolling.policies.type = Policies
appender.rolling.strategy.type = DefaultRolloverStrategy
appender.rolling.strategy.fileIndex = nomax
appender.rolling.strategy.action.basepath = ${sys:es.logs.base_path}
1.3.2 日志滚动策略
appender.rolling.policies.type = Policies
appender.rolling.policies.time.type = TimeBasedTriggeringPolicy
appender.rolling.policies.time.interval = 1
appender.rolling.policies.time.modulate = true
appender.rolling.policies.size.type = SizeBasedTriggeringPolicy
appender.rolling.policies.size.size = 128MB
1.3.3 日志删除策略
appender.rolling.strategy.type = DefaultRolloverStrategy
appender.rolling.strategy.fileIndex = nomax
appender.rolling.strategy.action.type = Delete
appender.rolling.strategy.action.basepath = ${sys:es.logs.base_path}
appender.rolling.strategy.action.condition.type = IfFileName
appender.rolling.strategy.action.condition.glob = ${sys:es.logs.cluster_name}-*
appender.rolling.strategy.action.condition.nested_condition.type = IfAccumulatedFileSize
appender.rolling.strategy.action.condition.nested_condition.exceeds = 2GB
二、调试报错积累
2.1 调整默认虚拟内存大小
- 系统虚拟内存默认最大映射数为65530,无法满足ES系统要求,需要调整为262144以上。

1.使用root用户在/etc/sysctl.conf文件添加如下一行,重新读取该文件。
[root@localhost ~]# vim /etc/sysctl.conf
[root@localhost ~]# sysctl -p /etc/sysctl.conf
vm.max_map_count = 262144
2.切换至es用户,再次启动服务,解决。
2.2 调整文件描述符大小
- es程序组要的最小文件描述符值是65536,但默认值是4096。

1.查看大小。
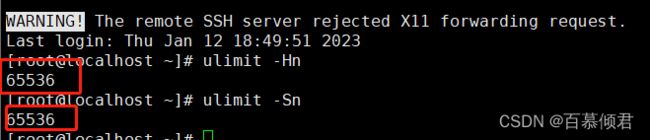
- ulimit -Hn: 是max number of open file descriptors的hard限制
- ulimit -Sn: 是max number of open file descriptors的soft限制

2.修改配置文件,添加如下两行,重启登录才能生效,使用bash命令不行。
- 星号:表示所有用户。
- hard与soft:表示限制的类型。
- nofile:表示max number of open file descriptors。
- 65536:表示设置的大小。
[root@localhost ~]# tail -n 2 /etc/security/limits.conf
* hard nofile 65536
* soft nofile 65536
#也可以指定特定用户设置,例如:
es-qingjun hard nofile 65536
es-qingjun soft nofile 65536
3.切换至es用户,重启服务,解决。
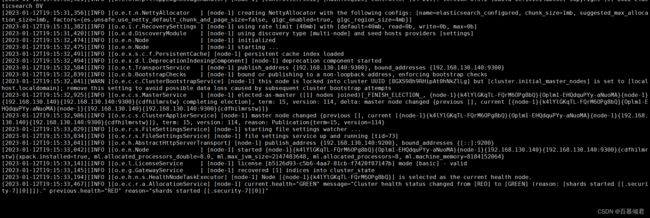
2.3 UUID不一致
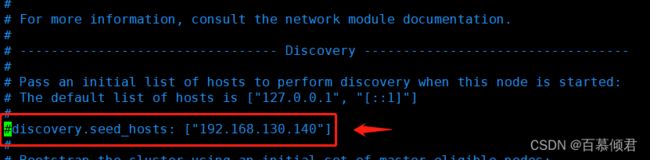
- 这个问题一般都是出在集群里,但是我这里是单节点会出现这个问题是因为我的uuid发生改变了,直接把这个参数注释掉就可以了。

1.修改配置文件,注释这个参数,单节点不需要使用。
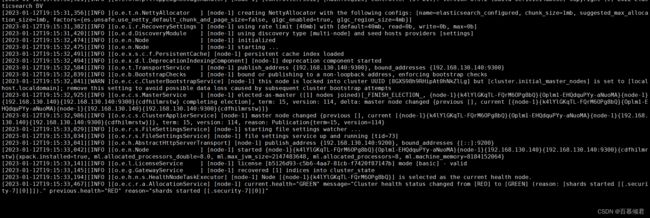
2.重启es,解决。
2.4 进程重复启动
1.es服务已经后台运行,再次启动就会报错。
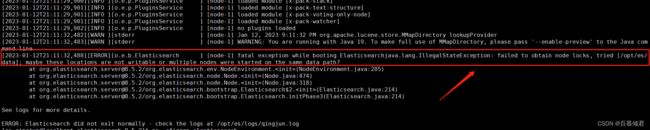
2.查看es进程。

2.5 客户端不信任证书日志刷频
- 报错是因为es集群配置xpack认证,需要检查各个节点config目录下的elastic-certificates.p12 文件,属主是否是es的运行用户,并且每个节点需要用同一个elastic-certificates.p12文件。
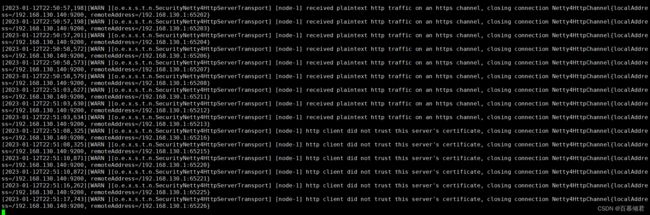
1.关闭ssl证书。或者重新生成证书。

2.此时密码访问就是http的了。