图解Redis中的9种数据结构
如图所示,Redis中提供了9种不同的数据操作类型,他们分别代表了不同的数据存储结构。

图2-17 数据类型
String类型
String类型是Redis用的较多的一个基本类型,也是最简单的一种类型,它和我们在Java中使用的字符类型什么太大区别,具体结构如图2-18所示。

图2-19
String常用操作指令
常用炒作指令如图2-20所示,更多的指令查询:http://doc.redisfans.com/

图2-20
String的实际存储结构
学过C++的同学都知道,C++中没有String类型,而Redis又是基于C++来实现的,那么它是如何存储String类型的呢?
Redis并没有采用C语言的传统字符串表示方式(char*或者char[]),在Redis内部,String类型以int/SDS(simple dynamic string)作为结构存储,int用来存放整型数据,sds存放字节/字符串和浮点型数据。
在C的标准字符串结构下进行了封装,用来提升基本操作的性能,同时充分利用以后的C的标准库,简化实现。我们可以在redis的源码中【sds.h】中看到sds的结构如下;
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len;//表示当前sds的长度(单位是字节)
uint8_t alloc; //表示已为sds分配的内存大小(单位是字节)
unsigned char flags; //用一个字节表示当前sdshdr的类型,因为有sdshdr有五种类型,所以至少需要3位来表示000:sdshdr5,001:sdshdr8,010:sdshdr16,011:sdshdr32,100:sdshdr64。高5位用不到所以都为0。
char buf[];//sds实际存放的位置
};复制
也就是说实际上sds类型就是char*类型,那sds和char*有什么区别呢?
主要区别就是:sds一定有一个所属的结构(sdshdr),这个header结构在每次创建sds时被创建,用来存储sds以及sds的相关信息
对sds结构有一个简单认识以后,我们如果通过set创建一个字符串,那么也就是会创建一个sds来存储这个字符串信息,那么这个过程是怎么样的呢?
- 首先第一个要判断选择一个什么类型的sdshdr来存放信息?这就得根据要存储的sds的长度决定了,redis在创建一个sds之前会调用【sds.c文件】sdsReqType(size_t string_size)来判断用哪个sdshdr。该函数传递一个sds的长度作为参数,返回应该选用的sdshdr类型。
- 然后把数据保存到对应的sdshdr中。
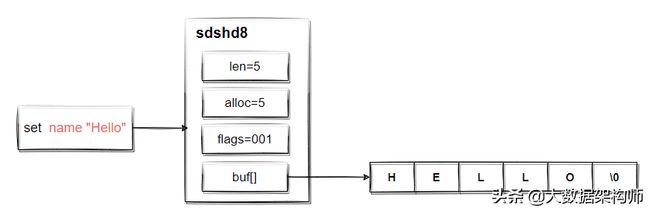
图2-19
Redis采用类似C的做法存储字符串,也就是以’\0’结尾,’\0’只作为字符串的定界符,不计入alloc或者len
key命名小技巧
- a) redis并没有规定我们对key应该怎么命名,但是最好的实践是“对象类型:对象id:对象属性.子属性”
- b) key不要设置得太长,太长的key不仅仅消耗内存,而且在数据中查找这类键值计算成本很高
- c) key不要设置得太短,比如u:1000:pwd 来代替user:1000:password, 虽然没什么问题,但是后者的可读性更好
- d) 为了更好的管理你的key,对key进行业务上的分类;同时建议有一个wiki统一管理所有的key,通过查询这个文档知道redis中的key的作用
String类型的应用场景
String类型使用比较多,一般来说,不太了解Redis的人,几乎所有场景都是用String类型来存储数据。
分布式缓存
首先最基本的就是用来做业务数据的缓存,如图2-20,Redis中会缓存一些常用的热点数据,可以提升数据查询的性能。

如图2-20
分布式全局ID
使用String类型的incr命令,实现原子递增
限流
使用计数器实现手机验证码频率限流。
分布式session
基于登录场景中,保存token信息。
List类型
列表类型(list)可以存储一个有序且可重复的字符串列表,常用的操作是向列表两端添加元素或者获得列表的某一个片段,List的存储结构如图2-20所示
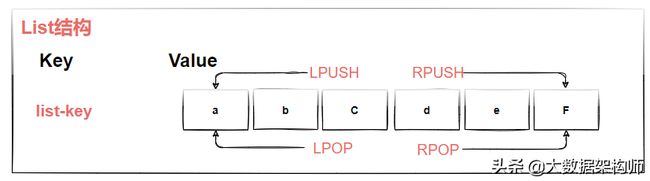
图2-20
常用操作命令
图2-21表示list类型的常用操作命令,具体命令的操作,可以参考: http://doc.redisfans.com/
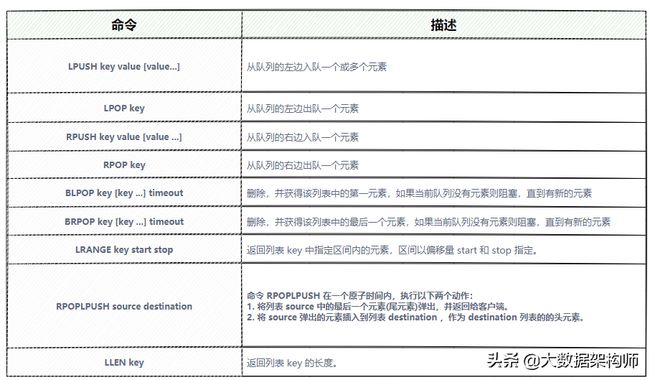
图2-21
数据存储结构
如图2-22所示,在redis6.0中,List采用了QuickList这样一种结构来存储数据,QuickList是一个双向链表,链表的每个节点保存一个ziplist,所有的数据实际上是存储在ziplist中,ziplist是一个压缩列表,它可以节省内存空间。
听到“压缩”两个字,直观的反应就是节省内存。之所以说这种存储结构节省内存,是相较于数组的存储思路而言的。我们知道,数组要求每个元素的大小相同,如果我们要存储不同长度的字符串,那我们就需要用最大长度的字符串大小作为元素的大小(假设是5个字节)。存储小于5个字节长度的字符串的时候,便会浪费部分存储空间,比如下面这个图所示。 所以,ziplist就是根据每个节点的长度来决定占用内存大小,然后每个元素保存时同步记录当前数据的长度,这样每次添加元素是就可以计算下一个节点在内存中的存储位置,从而形成一个压缩列表。 另外,数据的方式存储数据有一个很好的优势,就是它存储的是在一个连续的内存空间,它可以很好的利用CPU的缓存来访问数据,从而提升访问性能。

图2-22
其中,QuickList中的每个节点称为QuickListNode,具体的定义在quicklist.h文件中。
typedef struct quicklistNode {
struct quicklistNode *prev; //链表的上一个node节点
struct quicklistNode *next; //链表的下一个node节点
unsigned char *zl; //数据指针,如果当前节点数据没有压缩,它指向一个ziplist,否则,指向一个quicklistLZF
unsigned int sz; /* 指向的ziplist的总大小 */
unsigned int count : 16; /* ziplist中的元素个数 */
unsigned int encoding : 2; /* 表示ziplist是否压缩了,1表示没压缩,2表示压缩 */
unsigned int container : 2; /* 预留字段 */
unsigned int recompress : 1; /* 当使用类似lindex命令查看某一个本压缩的数据时,需要先解压,这个用来存储标记,等有机会再把数据重新压缩 */
unsigned int attempted_compress : 1; /* node can't compress; too small */
unsigned int extra : 10; /* more bits to steal for future usage */
} quicklistNode;复制
quickList是list类型的存储结构,其定义如下。
typedef struct quicklist {
quicklistNode *head; //指向quicklistNode头节点
quicklistNode *tail; //指向quicklistNode的尾节点
unsigned long count; /* 所有ziplist数据项的个数综合 */
unsigned long len; /* quicklist节点个数*/
int fill : QL_FILL_BITS; /* ziplist大小设置 */
unsigned int compress : QL_COMP_BITS; /* 节点压缩深度设置 */
unsigned int bookmark_count: QL_BM_BITS;
quicklistBookmark bookmarks[];
} quicklist;复制
如图2-23所示,当向list中添加元素时,会直接保存到某个QuickListNode中的ziplist中,不过不管是从头部插入数据,还是从尾部插入数据,都包含两种情况
- 如果头节点(尾部节点)上的ziplist大小没有超过限制,新数据会直接插入到ziplist中
- 如果头节点上的ziplist达到阈值,则创建一个新的quicklistNode节点,该节点中会创建一个ziplist,然后把这个新创建的节点插入到quicklist双向链表中。
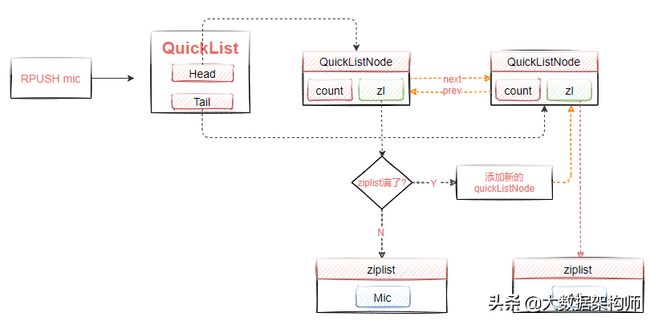
图2-23
实际使用场景
列表类型可以使用 rpush 实现先进先出的功能,同时又可以使用 lpop 轻松的弹出(查询并删除)第一个元素,所以列表类型可以用来实现消息队列,如图2-24所示。
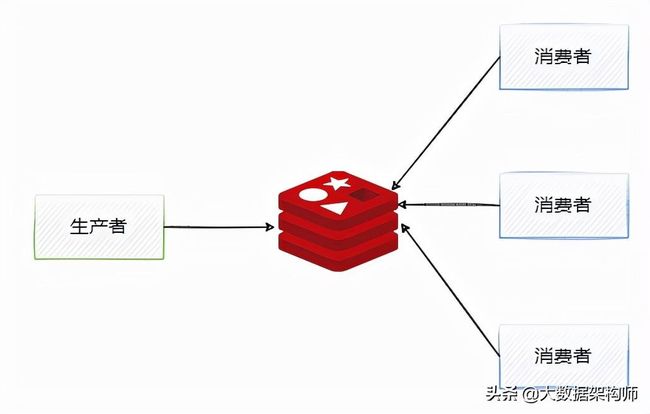
图2-24
发红包的场景
在发红包的场景中,假设发一个10元,10个红包,需要保证抢红包的人不会多抢到,也不会少抢到,这种情况下,可以根据图2-25所示去实现。

图2-25
Hash类型
Hash类型大家应该都不陌生,他就是一个键值对集合,如图2-26所示。Hash相当于一个 string 类型的 key和 value 的映射表,key 还是key,但是value是一个键值对(key-value),类比于 Java里面的 Map

图2-26
Hash常用操作命令
Hash结构的常用操作命令如图2-27所示,其他的指令可以参考:http://doc.redisfans.com/
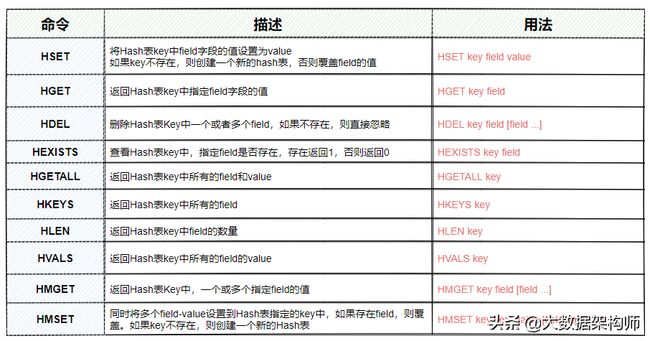
图2-27
Hash实际存储结构
如图2-28所示,哈希类型的内部编码有两种:ziplist压缩列表,hashtable哈希表。只有当存储的数据量比较小的情况下,Redis 才使用压缩列表来实现字典类型。具体需要满足两个条件:
- 当哈希类型元素个数小于hash-max-ziplist-entries配置(默认512个)
- 所有值都小于hash-max-ziplist-value配置(默认64字节) ziplist使用更加紧凑的结构实现多个元素的连续存储,所以在节省内存方面比hashtable更加优秀。当哈希类型无法满足ziplist的条件时,Redis会使用hashtable作为哈希的内部实现,因为此时ziplist的读写效率会下降,而hashtable的读写时间复杂度为O(1)。


图2-28
Hash实际应用场景
Hash表使用用来存储对象数据,比如用户信息,相对于通过将对象转化为json存储到String类型中,Hash结构的灵活性更大,它可以任何添加和删除对象中的某些字段。
购物车功能
- 1.以用户ID作为key
- 2.以商品id作为field
- 3.以商品的数量作为value
对象类型数据
比如优化之后的用户信息存储,减少数据库的关联查询导致的性能慢的问题。
- 用户信息
- 商品信息
- 计数器
Set类型
如图2-29所示,集合类型 (Set) 是一个无序并唯一的键值集合。它的存储顺序不会按照插入的先后顺序进行存储。
集合类型和列表类型的区别如下:
- 列表可以存储重复元素,集合只能存储非重复元素;
- 列表是按照元素的先后顺序存储元素的,而集合则是无序方式存储元素的。

图2-29
set类型的常用操作
Set类型的常用操作指令如下。
| 命令 |
说明 |
时间复杂度 |
|---|---|---|
| SADD key member [member ...] |
添加一个或者多个元素到集合(set)里 |
O(N) |
| SCARD key |
获取集合里面的元素数量 |
O(1) |
| SDIFF key [key ...] |
获得队列不存在的元素 |
O(N) |
| SDIFFSTORE destination key [key ...]] |
获得队列不存在的元素,并存储在一个关键的结果集 |
O(N) |
| SINTER key [key ...] |
获得两个集合的交集 |
O(N*M) |
| SINTERSTORE destination key [key ...] |
获得两个集合的交集,并存储在一个关键的结果集 |
O(N*M) |
| SISMEMBER key member |
确定一个给定的值是一个集合的成员 |
O(1) |
| SMEMBERS key |
获取集合里面的所有元素 |
O(N) |
| SMOVE source destination member |
移动集合里面的一个元素到另一个集合 |
O(1) |
| SPOP key [count] |
删除并获取一个集合里面的元素 |
O(1) |
| SRANDMEMBER key [count] |
从集合里面随机获取一个元素 |
|
| SREM key member [member ...]] |
从集合里删除一个或多个元素 |
O(N) |
| SUNION key [key ...]] |
添加多个set元素 |
O(N) |
| SUNIONSTORE destination key [key ...] |
合并set元素,并将结果存入新的set里面 |
O(N) |
Set类型实际存储结构
Set在的底层数据结构以intset或者hashtable来存储。当set中只包含整数型的元素时,采用intset来存储,否则,采用hashtable存储,但是对于set来说,该hashtable的value值用于为NULL,通过key来存储元素。
typedef struct intset {
uint32_t encoding;
uint32_t length;
int8_t contents[];
} intset;复制
intset将整数元素按顺序存储在数组里,并通过二分法降低查找元素的时间复杂度。数据量大时,
依赖于“查找”的命令(如SISMEMBER)就会由于O(logn)的时间复杂度而遇到一定的瓶颈,所以数据量大时会用dict来代替intset。
但是intset的优势就在于比dict更省内存,而且数据量小的时候O(logn)未必会慢于O(1)的hash function,这也是intset存在的原因。
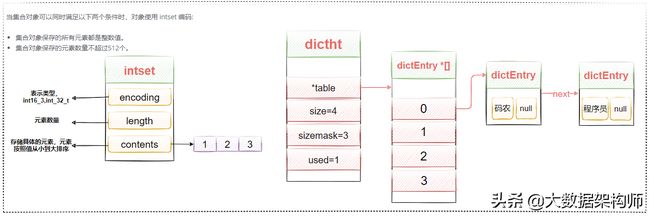
图2-30
set类型的实际应用场景
标签管理功能
- 给用户添加标签。sadd user:1:basketball game coding swing sadd user:2:sing coding sleep basketball ... sadd user:k:tags tag1 tag2 tag4 ...
- 使用sinter命令,可以来计算用户共同感兴趣的标签sinter user:1 user:2
这种标签系统在电商系统、社交系统、视频网站,图书网站,旅游网站等都有着广泛的应用。例如一个用户可能对娱乐、体育比较感兴趣,另一个用户可能对历史、新闻比较感兴趣,
这些兴趣点就是标签。有了这些数据就可以得到喜欢同一个标签的人,以及用户的共同喜好的标签,这些数据对于用户体验以及增强用户黏度比较重要。
例如一个社交系统可以根据用户的标签进行好友的推荐,已经用户感兴趣的新闻的推荐等,一个电子商务的网站会对不同标签的用户做不同类型的推荐,比如对数码产品比较感兴趣的人,
在各个页面或者通过邮件的形式给他们推荐最新的数码产品,通常会为网站带来更多的利益
相关商品信息展示
比如在电商系统中,当用户查看某个商品时,可以推荐和这个商品标签有关的商品信息。
ZSet类型
有序集合类型,顾名思义,和前面讲的集合类型的区别就是多了有序的功能。
如图2-31所示,在集合类型的基础上,有序集合类型为集合中的每个元素都关联了一个分数(浮点型),这使得我们不仅可以完成插入、删除和判断元素是否存在等集合类型支持的操作,还能获得分数最高(或最低)的前N个元素、获得指定分数范围内的元素等与分数有关的操作。

图2-31
ZSet常用操作命令
ZSet的常用命令如图2-32所示,完整的操作命令,详见:http://doc.redisfans.com/
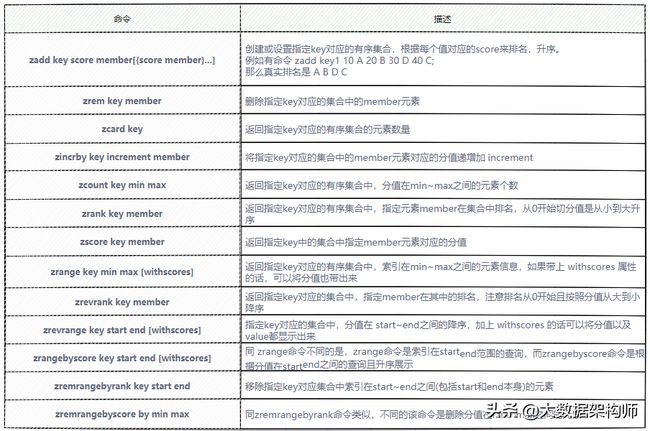
图2-32
ZSet的数据存储结构
ZSet的底层数据结构采用了zipList(压缩表)和skiplist(跳跃表)组成,当同时满足以下两个条件时,有序集合采用的是ziplist存储。
- 有序集合保存的元素个数要小于128个
- 有序集合保存的所有元素成员的长度必须小于64个字节
如果不能满足以上任意一个条件,有序集合会采用skiplist(跳跃表)结构进行存储,如图2-33所示,zSet不只是用skiplist,实际上,它使用了dict(字典表)和zskiplist(跳跃表)同时进行数据存储。
- dict,字典类型, 其中key表示zset的成员数据,value表示zset的分值,用来支持O(1)复杂度的按照成员取分值的操作
- zskiplist,跳跃表,按分值排序成员,用来支持平均复杂度为O(logn)的按照分值定位成员的操作,以及范围查找操作。
其中zskiplistNode中*obj和Dic中*key指向同一个具体元素,所以不会存在多余的内存消耗问题。另外,backward表示后退指针,方便进行回溯。

图2-33
关于跳跃表
跳表(skip list) 对标的是平衡树(AVL Tree),是一种 插入/删除/搜索 都是 O(log n) 的数据结构。它最大的优势是原理简单、容易实现、方便扩展、效率更高。因此在一些热门的项目里用来替代平衡树,如 redis, leveldb 等。
跳表的基本思想
首先,跳表处理的是有序的链表(一般是双向链表,下图未表示双向),如下:
![]()
这个链表中,如果要搜索一个数,需要从头到尾比较每个元素是否匹配,直到找到匹配的数为止,即时间复杂度是 O(n)O(n)。同理,插入一个数并保持链表有序,需要先找到合适的插入位置,再执行插入,总计也是 O(n)O(n) 的时间。
那么如何提高搜索的速度呢?很简单,做个索引:

如上图,我们新创建一个链表,它包含的元素为前一个链表的偶数个元素。这样在搜索一个元素时,我们先在上层链表进行搜索,当元素未找到时再到下层链表中搜索。例如搜索数字 19 时的路径如下图:

先在上层中搜索,到达节点 17 时发现下一个节点为 21,已经大于 19,于是转到下一层搜索,找到的目标数字 19。
我们知道上层的节点数目为 n/2n/2,因此,有了这层索引,我们搜索的时间复杂度降为了:O(n/2)O(n/2)。同理,我们可以不断地增加层数,来减少搜索的时间:

在上面的 4 层链表中搜索 25,在最上层搜索时就可以直接跳过 21 之前的所有节点,因此十分高效。
更一般地,如果有 kk 层,我们需要的搜索次数会小于 ⌈n2k⌉+k⌈n2k⌉+k ,这样当层数 kk 增加到 ⌈log2n⌉⌈log2n⌉ 时,搜索的时间复杂度就变成了 lognlogn。其实这背后的原理和二叉搜索树或二分查找很类似,通过索引来跳过大量的节点,从而提高搜索效率。
动态跳表
上节的结构是“静态”的,即我们先拥有了一个链表,再在之上建了多层的索引。但是在实际使用中,我们的链表是通过多次插入/删除形成的,换句话说是“动态”的。上节的结构要求上层相邻节点与对应下层节点间的个数比是 1:2,随意插入/删除一个节点,这个要求就被被破坏了。
因此跳表(skip list)表示,我们就不强制要求 1:2 了,一个节点要不要被索引,建几层的索引,都在节点插入时由抛硬币决定。当然,虽然索引的节点、索引的层数是随机的,为了保证搜索的效率,要大致保证每层的节点数目与上节的结构相当。下面是一个随机生成的跳表:

可以看到它每层的节点数还和上节的结构差不多,但是上下层的节点的对应关系已经完全被打破了。
现在假设节点 17 是最后插入的,在插入之前,我们需要搜索得到插入的位置:

接着,抛硬币决定要建立几层的索引,伪代码如下:
randomLevel()
lvl := 1
-- random() that returns a random value in [0...1)
while random() < p and lvl < MaxLevel do
lvl := lvl + 1
return lvl复制
上面的伪代码相当于抛硬币,如果是正面(random() < p)则层数加一,直到抛出反面为止。其中的 MaxLevel 是防止如果运气太好,层数就会太高,而太高的层数往往并不会提供额外的性能,
一般 MaxLevel=log1/pnMaxLevel=log1/pn。现在假设 randomLevel 返回的结果是 2,那么就得到下面的结果。

如果要删除节点,则把节点和对应的所有索引节点全部删除即可。当然,要删除节点时需要先搜索得到该节点,搜索过程中可以把路径记录下来,这样删除索引层节点的时候就不需要多次搜索了
ZSet的使用场景
- 排行榜系统有序集合比较典型的使用场景就是排行榜系统。例如学生成绩的排名。某视频(博客等)网站的用户点赞、播放排名、电商系统中商品的销量排名等。我们以博客点赞为例。添加用户赞数例如小编Tom发表了一篇博文,并且获得了10个赞。zadd user:ranking article1 10 取消用户赞数这个时候有一个读者又觉得Tom写的不好,又取消了赞,此时需要将文章的赞数从榜单中减去1,可以使用zincrby。zincrby user:ranking -1 article1 查看某篇文章的赞数ZSCORE user:ranking arcticle1 展示获取赞数最多的十篇文章此功能使用zrevrange命令实现:zrevrange user:ranking 0 10 #0 到 10表示元素个数索引 zrevrangebyscore user:ranking 99 0 # 按照分数从高到低排名,99,0表示score
- 热点话题排名比如想微博的热搜,就可以使用ZSet来实现。
其他数据类型介绍
在Redis中,还有一些使用得非常少的数据类型,简单给大家普及一下。
Geospatial
Geo是Redis3.2推出的一个类型,它提供了地理位置的计算功能,也就是可以计算出两个地理位置的距离。
文档:https://www.redis.net.cn/order/3687.html
下面演示一下Geo的基本使用,其中需要用到经纬度信息,可以从 http://www.jsons.cn/lngcode/查询。
- 添加模拟数据geoadd china:city 116.40 39.90 beijing geoadd china:city 121.47 31.23 shanghai geoadd china:city 114.05 22.52 shengzhen geoadd china:city 113.28 23.12 guangzhou
- 获取当前位置的坐标值geopos china:city beijing geopos china:city shanghai
- 获取两个位置之间的距离:m-表示米/km-表示千米/mi-表示英里/ft表示英尺# 查看北京到上海的直线距离 geodist china:city beijing shanghai km # 查看北京到深圳的直线距离 geodist china:city beijing shenzhen km
- 给定一个经纬度,找出该经纬度某一半径内的元素# 以110 30这个点为中心,寻找方圆1000km的城市 georadius china:city 110 30 1000 km
- 找出指定位置周围的其他元素georadiusbymember china:city shanghai 1000 km
比如现在比较火的直播业务,我们需要检索附近的主播,那么GEO就可以很好的实现这个功能。
- 一是主播开播的时候写入主播Id的经纬度,
- 二是主播关播的时候删除主播Id元素,这样就维护了一个具有位置信息的在线主播集合提供给线上检索。
HyperLogLog
HyperLogLog是Redis2.8.9提供的一种数据结构,他提供了一种基数统计方法。什么是基数统计呢?简单来说就是一个集合中不重复元素的个数,比如有一个集合{1,2,3,1,2},那么它的基数就是3。
HyperLogLog提供了三种指令。
- pfadd ,Redis Pfadd 命令将所有元素参数添加到 HyperLogLog 数据结构中。
- pfcount,Redis Pfcount 命令返回给定 HyperLogLog 的基数估算值。
- pgmerge,Redis Pgmerge 命令将多个 HyperLogLog 合并为一个 HyperLogLog ,合并后的 HyperLogLog 的基数估算值是通过对所有 给定 HyperLogLog 进行并集计算得出的。
使用方法如下。
pfadd uv a b c a c d e f # 创建一组元素
pfcount uv # 统计基数复制
有同学会问了,这个功能,我用String类型、或者Set类型都可以实现,为什么要用HyperLogLog呢?
最大的特性就是: HyperLogLog在数据量非常大的情况下,占用的存储空间非常小,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64(2的64次方) 个不同元素的基数,这个是一个非常庞大的数字,为什么能够用这么小的空间来存储这么大的数据呢?
不知道大家是否注意到,HyperLogLog并没有提供数据查询的命令,只提供了数据添加和数据统计。这是因为HyperLogLog并没有存储每个元素的值,它使用的是概率算法,通过存储元素的hash值的第一个1的位置,来计算元素数量,这块在这里就不做过多展开。
应用场景:
- HyperLogLog更适合做一些统计类的工作,比如统计一个网站的UV。
- 计算日活、7日活、月活数据.如果我们通过解析日志,把 ip 信息(或用户 id)放到集合中,例如:HashSet。如果数量不多则还好,但是假如每天访问的用户有几百万。无疑会占用大量的存储空间。且计算月活时,还需要将一个整月的数据放到一个 Set 中,这随时可能导致我们的程序 OOM。有了 HyperLogLog,这件事就变得很简单了。因为存储日活数据所需要的内存只有 12K,例如。# 使用日来存储每天的ip地址 pfadd ip_20190301 192.168.8.1 pfadd ip_20190302 xxx pfadd ip_20190303 xxx ... pfadd ip_20190331 xxx 计算某一天的日活,只需要执行 PFCOUNT ip_201903XX 就可以了。每个月的第一天,执行 PFMERGE 将上一个月的所有数据合并成一个 HyperLogLog,例如:ip_201903。再去执行 PFCOUNT ip_201903,就得到了 3 月的月活。
Bit
Bit,其实是String类型中提供的一个功能,他可以设置key对应存储的值指定偏移量上的bit位的值,可能大家理解起来比较抽象,举个例子
- 使用string类型保存一个keyset key m
- 通过getbit命令获取 key的bit位的值getbit key 0 getbit key 1 getbit key 2 getbit key 3 getbit key 4 getbit key 5 getbit key 6 getbit key 7 getbit key 8 打印上面的所有输出,会发现得到一个0 1 1 0 1 1 0 1的二进制数据,这个二进制拼接得到的结果。 m的ascII码对应的是109, 109的二进制正好是0 1 1 0 1 1 0 1。所以从这里可以看出来,bit其实就是针对一个String类型的value值的bit位进行操作。
- 对key进行修改,修改第6位的值变成1, 第7位的值编程0.setbit key 6 1 setbit key 7 0 在此使用 get key命令,会发现得到的结果是n。因为n的二进制是1101110,(十进制是110)。把上面的指定位修改之后,自然就得到了这样的结果。
bit操作在实际应用中,可以怎么使用呢?
比如学习打卡功能就可以使用setbit操作,比如记录一周的打卡记录。
# 设置用户id 1001的打卡记录
set sign:1001 0 1 # 已打卡
set sign:1001 1 0 # 未打卡
set sign:1001 2 1
set sign:1001 3 1
set sign:1001 4 1复制
查看某天是否已打卡
getbit sign 3复制
统计当前用户总的打卡天数
bitcount sign:1001复制
除了这个场景之外,还有很多类似的场景都可以使用,
- 统计活跃用户
- 记录用户在线状态
bit最大的好处在于,它通过bit位来存储0/1表示特定含义,我们知道一个int类型是8个字节,占32个bit位,意味着一个int类型的数字就可以存储32个有意义的场景,大大压缩了存储空间。