数据结构和算法--排序
数据结构和算法–排序
希尔排序
一、概念及其介绍
希尔排序(Shell Sort)是插入排序的一种,它是针对直接插入排序算法的改进。
希尔排序又称缩小增量排序,因 DL.Shell 于 1959 年提出而得名。
它通过比较相距一定间隔的元素来进行,各趟比较所用的距离随着算法的进行而减小,直到只比较相邻元素的最后一趟排序为止。
二、适用说明
希尔排序时间复杂度是 O(n^(1.3-2)),空间复杂度为常数阶 O(1)。希尔排序没有时间复杂度为 O(n(logn)) 的快速排序算法快 ,因此对中等大小规模表现良好,但对规模非常大的数据排序不是最优选择,总之比一般 O(n^2 ) 复杂度的算法快得多。
三、基本思想
现将整个待排记录序列分割成若干子序列,分别进行 直接插入排序,待整个序列中的记录“基本有序‘,时,再对全体记录进行一次直接插入排序。
四、希尔排序算法,特点
- 缩小增量
- 多遍插入排序

五、思路
定义增量序列Dk:DM>DM-1>…>D1=1
- 刚才的例子中:D3=5,D2=3,D3=1
对每个Dk进行“DK-间隔” 插入排序(k=M,M-1,…1)
-
一次移动,移动位置较大,跳跃式地接近排序后的最终位置
-
最后一次只需少量移动
-
增量序列必须是递减的,最后一个必须是1
-
增量序列应该是互质的、
package main import ( "fmt" "math/rand" "time" ) func ShellSort(arr *[]int) { // 分块 for gap := len(*arr) / 2; gap > 0; gap = gap / 2 { // i是待排序的元素 for i := gap; i < len(*arr); i++ { // 待排元素的位置&&左边元素大于右边元素 for j := i; j >= gap && (*arr)[j-gap] > (*arr)[j]; j = j - gap { // 交换 (*arr)[j], (*arr)[j-gap] = (*arr)[j-gap], (*arr)[j] } } } } func main() { r := rand.New(rand.NewSource(time.Now().UnixNano())) arr := make([]int, 0) for i := 0; i < 100; i++ { arr = append(arr, r.Intn(100)) } fmt.Println(arr) ShellSort(&arr) fmt.Println(arr) }希尔排序算法效率与增量序列的取值有关

希尔排序法是一种不稳定的排序算法

交换排序
基本思想:两两比较,如果发生逆序则交换,知道所有的记录都排好序为止。
常见的交换排序方法:
- 冒泡排序O(n^2)
- 快速排序O(nlog2n)
冒泡排序
每趟将不断记录两两比较,并按照“前小后大” 规则交换
优点:每趟结束时,不仅能挤出一个最大值到最后面位置,还能同时部分理顺其他元素;
如何提高效率?
一旦某趟比较时不出现交换记录,说明已经排好序了,就可以技术算法了
package main
import (
"fmt"
"math/rand"
"time"
)
func BubbleSort(arr *[]int) {
for i := 0; i < len(*arr); i++ {
for j := 0; j < len(*arr)-1; j++ {
if (*arr)[j] > (*arr)[j+1] {
(*arr)[j], (*arr)[j+1] = (*arr)[j+1], (*arr)[j]
}
}
}
}
func main() {
r := rand.New(rand.NewSource(time.Now().UnixNano()))
arr := make([]int, 0)
for i := 0; i < 100; i++ {
arr = append(arr, r.Intn(100))
}
fmt.Println(arr)
BubbleSort(&arr)
fmt.Println(arr)
}
优点:每趟结束,不仅能挤出一个最大值到最后面位置,还能同时部分理顺其他元素
如何提高效率?
一旦某一趟比较时不出现记录交换,说明已排好序了,就可以技术本算法。
时间复杂度
- 最好情况(正序)
- 比较次数:n-1
- 移动次数:0
- 最坏情况(逆序)
- 比较次数:
- 移动次数

快速排序
基本思想
- 任取一个元素(如:第一个)为中心
- 所有比他小的元素一律前放,比他大的元素一律后放,形成左右两个子表
- 对各子表重新选择中心元素并依次规则调整
- 知道每个子表的元素只剩一个
通过一趟排序,将待排序记录分割成独立的两部分,其中一部分记录的关键字均比林一部分记录的关键字小,则可分贝对这两部分记录进行排序,已达到整个序列有序
具体实现
选定一个中间数作为参考,所有元素与之比较,小的调到其左边,大的调到其右边。
中间数
可以是第一个数、最后一个数、中间一个数、任选一个数等
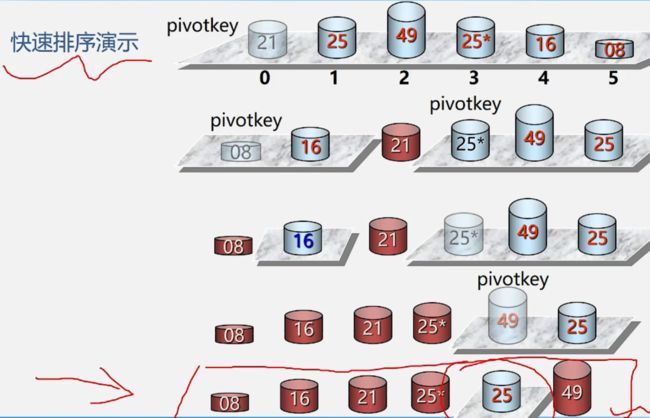
package main
import (
"fmt"
"math/rand"
"time"
)
func Quicksort(arr *[]int, low int, high int) {
if low > high {
return
}
//中心位置
q := Partition(arr, low, high)
//递归分区
Quicksort(arr, low, q-1)
Quicksort(arr, q+1, high)
}
//定义pivot
func Partition(arr *[]int, low int, high int) int {
//以当前数据最后一个作为出事中心
pivot := (*arr)[high]
//下标初始化
i := low
for j := low; j < high; j++ {
if (*arr)[j] < pivot {
//比中心值小的去左边a[p, i-1],剩下的在b[i...j]
(*arr)[i], (*arr)[j] = (*arr)[j], (*arr)[i]
//将i下标后移一位
i++
}
}
// 最后将 pivot 与 i 下标对应数据值互换
// 这样一来,pivot 就位于当前数据序列中间,i 也就是 pivot 值对应的下标
(*arr)[i], (*arr)[high] = pivot, (*arr)[i]
// 返回 i 作为 pivot 分区位置
return i
}
func main() {
r := rand.New(rand.NewSource(time.Now().UnixNano()))
arr := make([]int, 0)
for i := 1; i < 10000; i++ {
arr = append(arr, r.Intn(10000))
}
fmt.Println(arr)
Quicksort(&arr, 0, len(arr)-1)
fmt.Println(arr)
}
时间复杂度
可以证明,平均计算时间是O(nlog2n)
- Qsort()(log2n)
- Partitin()(n)
实验结果表明、:就平均计算时间而言,快速排序是我们所讨论的所有内排序方法中最好的一个
空间复杂度
快速排序不是原地排序
由于程序中使用了递归,需要递归调用栈,而栈的长度取决于递归调用的深度。(即使不使用地柜,也需要用用户栈)
在平均情况下:需要O(logn)的栈空间
最坏情况下:栈空间可达O(n)
稳定性
快速排序是一种不稳定的排序方法


分析
- 划分元素的选取是影响时间性能的关键
- 输入数据次序越乱,所选划分元素值的随机性越好,排序速度越快,快速排序于不是自然排序方法
取决于递归调用的深度。(即使不使用地柜,也需要用用户栈)
在平均情况下:需要O(logn)的栈空间
最坏情况下:栈空间可达O(n)
稳定性
快速排序是一种不稳定的排序方法
[外链图片转存中…(img-vdGrX3gr-1655264880333)]
[外链图片转存中…(img-1jEIxYvR-1655264880337)]
分析
- 划分元素的选取是影响时间性能的关键
- 输入数据次序越乱,所选划分元素值的随机性越好,排序速度越快,快速排序于不是自然排序方法
- 改变划分元素的选取方法,之多只能改变算法平均情况的时间性能,无法改变最坏情况下的时间性能。即最坏情况下,快速排序的时间复杂性总是O(n^2)