pandas数据处理实例(箱线图)
需求如下:
绘制每个公司的月度箱线图(其中需要满足排放量>1),并给出简要的描述统计结果
思路
- 将数据按月度循环,绘制散点图
难点:
- 不同站点的时间跨度不相同
- 同时存在2022年和2023年,且月度中存在着缺失的情况
- 需要提前对大规模的缺失数据进行预处理
代码
- 首先导入必要的库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
- 读取数据
path1 = r'D:\Desktop\data.xlsx'
path2 = r'D:\Desktop\name.xlsx'
data_all = pd.read_excel(path1)
name_list = pd.read_excel(path2)
将数据分为两个部分,一个是全体数据集data, 另一个是站点名称

通过读取站点名称,可以与数据集中的样本相对应,从而区别出不同站点的箱线图
- 识别时间
data_all = data_all.loc[data_all['折算值'] > 1.0]
data_all['year'] = data_all['时间'].dt.year
data_all['month'] = data_all['时间'].dt.month
因为要按月绘制图像,所以我们将月份和年份提取出来,作为时间标识。接下来就可以通过循环来绘制箱线图,其中需要注意的是,每个站点存在数据的月份可能不同,这时就可以通过已经提取出来的月份标识来识别包含数据的最大月份
plt.style.use('ggplot')
for k in range(len(name_list['企业名称'])):
plt.figure(figsize=(12, 8))
plot = data_all[data_all['排口'] == name_list['企业名称'][k]]
year = 2022
month = max(plot['month']) + 1
#month = 12
print(month)
list_all2022 = []
for i in range(1, month):
list_all2022.append(
plot[(plot.year == year) & (plot.month == i)]['折算值'])
plt.subplot(1, 2, 1)
plt.boxplot(list_all2022)
plt.xlabel('月份', fontsize=15, fontdict={
"family": "SimSun", "size": 15, "color": "k"})
plt.ylabel(name_list['企业名称'][k], fontsize=15, fontdict={
"family": "SimSun", "size": 15, "color": "k"})
plt.title(str(year)+'年', fontsize=15, fontdict={
"family": "SimSun", "size": 15, "color": "k"})
year = 2023
month = 4
list_all2023 = []
for i in range(1, month):
list_all2023.append(
plot[(plot.year == year) & (plot.month == i)]['折算值'])
plt.subplot(1, 2, 2)
plt.boxplot(list_all2023)
plt.xlabel('月份', fontsize=15, fontdict={
"family": "SimSun", "size": 15, "color": "k"})
plt.ylabel(name_list['企业名称'][k], fontsize=15, fontdict={
"family": "SimSun", "size": 15, "color": "k"})
plt.title(str(year)+'年', fontsize=15, fontdict={
"family": "SimSun", "size": 15, "color": "k"})
#plt.savefig("D:\\Desktop\\plot"+ "\\" + name_list['企业名称'][k] + '.png', dpi=200)
plt.show()
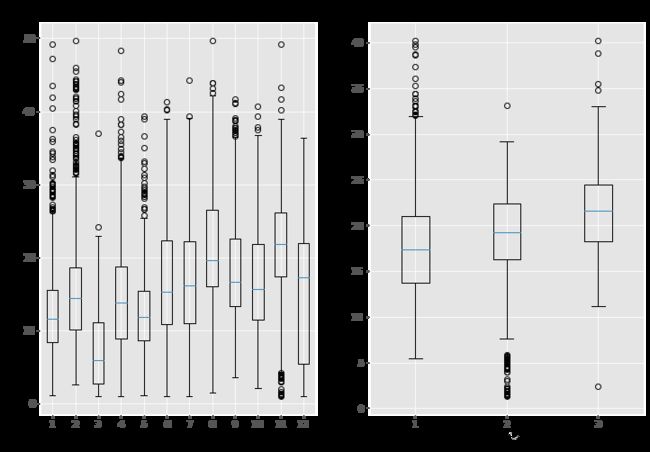
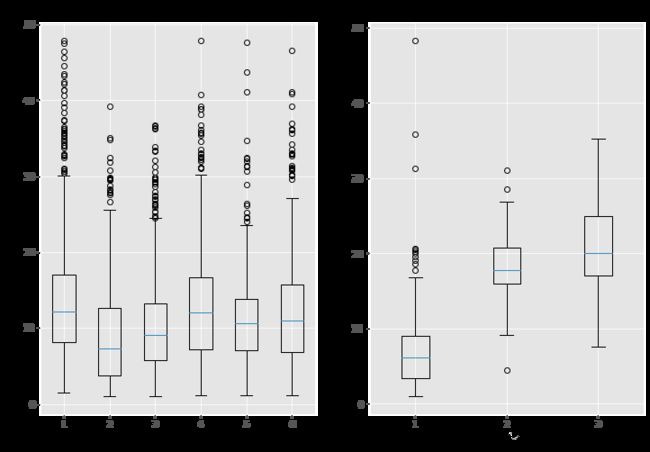
- 最后,同理对每个站点给出简要描述统计
Max = []
u1q = []
u2q = []
med = []
l1q = []
l2q = []
Min = []
for k in range(len(name_list['企业名称'])):
plot = data_all[data_all['排口'] == name_list['企业名称'][k]]
data_max = np.max(plot['折算值'])
Max.append(data_max)
data_u1q = np.quantile(plot['折算值'], 0.95)
u1q.append(data_u1q)
data_u2q = np.quantile(plot['折算值'], 0.90)
u2q.append(data_u2q)
data_med = np.median(plot['折算值'])
med.append(data_med)
data_l1q = np.quantile(plot['折算值'], 0.10)
l1q.append(data_l1q)
data_l2q = np.quantile(plot['折算值'], 0.05)
l2q.append(data_l2q)
data_min = np.min(plot['折算值'])
Min.append(data_min)
summary = {"最大值":Max, '最小值':Min, '90':u2q, "10":l1q,'95':u1q, '5':l2q,'中位数':med}
df = pd.DataFrame(summary)