Python高阶---数据分析和网络爬虫
1、Anaconda介绍
Anaconda 是专门为了方便使用 Python 进行数据科学研究而建立的一组软件包,涵盖了数据科学领域常见的 Python 库,并且自带了专门用来解决软件环境依赖问题的 conda 包管理系统。
anaconda主要是提供了包管理与环境管理的功能,可以很方便地解决多版本python并存、切换以及各种第三方包安装问题。pip也是python的一个包管理工具,可以和anaconda一样来管理包和下载第三方包。anaconda主要用于创建虚拟环境和包管理。
Anaconda利用工具/命令conda来进行package和environment的管理,并且已经包含了Python和相关的配套工具。
conda可以理解为一个工具,也是一个可执行命令,其核心功能是包管理与环境管理。包管理与pip的使用类似,环境管理则允许用户方便地安装不同版本的python并可以快速切换。
Anaconda则是一个打包的集合,里面预装好了conda、某个版本的python、众多packages、科学计算工具等等,所以也称为Python的一种发行版。其实还有Miniconda,它只包含最基本的内容——python与conda,以及相关的必须依赖项,对于空间要求严格的用户,Miniconda是一种选择。
conda将几乎所有的工具、第三方包都当做package对待,甚至包括python和conda自身!因此,conda打破了包管理与环境管理的约束,能非常方便地安装各种版本python、各种package并方便地切换。
2、Jupyter
Jupyter Notebook是基于网页的用于交互计算的应用程序。其可被应用于全过程计算:开发、文档编写、运行代码和展示结果。
简而言之,Jupyter Notebook是以网页的形式打开,可以在网页页面中直接编写代码和运行代码,代码的运行结果也会直接在代码块下显示的程序。如在编程过程中需要编写说明文档,可在同一个页面中直接编写,便于作及时的说明和解释。
jupyter和pycharm区别是什么?
1、Python是一种广泛使用的高级的、通用的、解释的、动态编程语言;Python是一种相当古老且流行的语言,是开源的,常被应用于网站开发、科学统计计算、软件开发等甚至更多,Jupyter项目开始于2014年,在所有编程语言中,是一种用于支撑科学计算和交互式计算科学的衍生式IPython。
2、Pycharm它能对类、对象、关键字的补全和自动缩进,能格式化代码,定制代码片段和格式;jupyter允许用户创建和共享文件,文件中可以包括公式、图像以及重要的代码。
3、jupyter拥有交互式组件,可以编程输出视频、图像、LaTaX;不仅如此,交互式组件能够用来实时可视化和操作数据;Pycharm支持错误的突出显示,同时也包含PEP-8,能帮助写出整洁的代码,易于支撑其他语言。
3、Spyder
Spyder (前身是 Pydee) 是一个强大的交互式 Python 语言开发环境,提供高级的代码编辑、交互测试、调试等特性,支持包括 Windows、Linux 和 OS X 系统。
总结:spyder是python的一个集成开发环境(IDE)
爬虫
通过编写程序,模拟浏览器上网,然后让其去互联网上抓取数据的过程
爬虫分类:
1.通用爬虫
抓取系统重要组成部分,抓取的是一整张页面数据
2.聚焦爬虫
是建立在通用爬虫的基础上,抓取的是页面中特定的局部内容
3.增量式爬虫
检测网站中数据更新的情况,只会抓取网站中最新更新出来的数据
4.robots.txt协议
规定了网站中哪些数据可以被爬虫爬取,哪些数据不可以被爬取。使用时候在网址后+robots.txt即可
5.http协议
服务器端和客户端进行交互时要遵守的协议。
**常用的请求头信息:**
- User-Agent:请求载体的身份标识
- Connection:请求完毕后,是断开连接还是保持连接
**常用的响应头信息:**
- Content-Type:服务器响应客户端的数据类型
https协议
安全的超文本传输协议
加密方式:
- 对称秘钥加密
客户端在传输数据的时候将数据进行加密,并且之后将数据和解密方式一并发送给服务器端
- 非对称秘钥加密
服务器端制定客户端加密方式,之后发送给客户端,客户端按照这种加密方式对数据进行加密,加密完成之后发送给服务器端,服务器端对其进行解密
引入公钥(服务器端发送给客户端的加密方式) 私钥(服务器端自己保留的解密方式)的概念,弥补了对称加密方式中解密方式被泄露的危险
- 证书秘钥加密
在非对称加密方式的基础上,对公钥进行证书认证
引入了证书的概念,是https使用的加密方式,弥补了非对称加密中公钥被泄露,掉包或篡改的危险
requests模块
python中基于网络请求的模块,功能强大,简单便捷,效率极高。
作用:模拟浏览器发送请求
如何使用:(requests模块的编码流程)
- 指定URL
- 发起请求
- 获取响应数据
- 持久化存储
环境安装:
pip install requests或pycharm解释器中直接搜索安装
实战编码:
爬取搜狗首页的页面数据
代码:
#导入包
import requests
if __name__ == '__main__':
#step01:指定URL
url="https://www.sogou.com/"
#step02:发起请求,get方法会返回一个响应对象
response=requests.get(url=url)
#step03:获取响应对象中的响应数据.text返回的是字符串形式的响应数据
page_txt=response.text
#持久化存储
with open("sogou.html","w",encoding="UTF-8") as fp:
fp.write(page_txt)
print("爬取数据结束!!!")
案例一:制作简易的网页采集器
![]()
网址为红色框内的内容
**
UA(UserAgent:请求载体身份标识):
门户网站的服务器会检测对应请求的载体的身份标识,如果检测到的请求的载体身份为某一款浏览 器,说明该请求是一个正常的请求,但是如果检测到的请求的载体身份不是基于某一款浏览器的,则 表示该请求为不正常的请求(爬虫)
UA伪装:让爬虫对应的请求载体身份标识伪装成某一款浏览器
**
获取某款浏览器的User-Agent,通过抓包获取
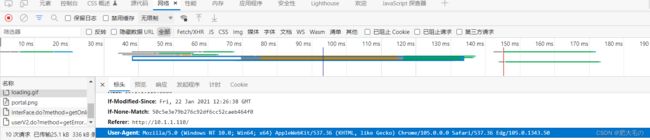
代码如下:
import requests
if __name__ == '__main__':
#UA伪装:将对应的User-Agent(某一款浏览器的标识)封装到一个字典中
headers={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36 Edg/105.0.1343.50"
}
#指定url
url="https://www.sogou.com/web?"
#处理url携带的参数(设置为动态参数):封装到字典中
kw=input("请输入要搜索的事物:")
param={"query":kw}
#发送请求,获取响应对象
response=requests.get(url=url,params=param,headers=headers)
#获取响应内容
page_txt=response.text
#持久化存储
#动态化存储名称
fileName=kw+".html"
with open(fileName,"w",encoding="UTF-8") as fp:
fp.write(page_txt)
print(fileName+"保存成功!!!")
案列二:百度翻译破解
如果数据是json,则返回字典
如果数据是text,则返回字符串
#数据是json格式
response=requests.get(url=url,headers=header,params=param)
dict_data=response.json()
#数据是text格式
response=requests.get(url=url,headers=header,params=param)
str_data=response.text()
Header中的Referer
Referer 是 HTTP 请求header 的一部分,当浏览器(或者模拟浏览器行为)向web 服务器发送 请求的时候,头信息里有包含 Referer 。
Referer的作用?
1.防盗链
将这个http请求发给服务器后,如果服务器要求必须是某个地址或者某几个地址才能访问,而你发送的referer不符合他的要求,就会拦截或者跳转到他要求的地址,然后再通过这个地址进行访问。
2.防止恶意请求
比如静态请求是*.html结尾的,动态请求是*.shtml,那么由此可以这么用,所有的*.shtml请求,必须 Referer 为我自己的网站。
Referer=http://www.google.com
允许 Referer 为空,意味着你允许比如浏览器直接访问,就是空。
案例三
#爬取豆瓣电影
import requests
import json
#UA伪装
header={
#请求标识载体
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36"
}
#指定url
url="https://movie.douban.com/j/chart/top_list"
#处理参数
param={
"type":"24",
"interval_id":"100:90",
"action":"",
"start":0,
"limit":20
}
#获取响应对象
response=requests.get(url=url,params=param,headers=header)
print(response.json())
response.close()
数据解析
1.re(正则) Regular Expression
元字符
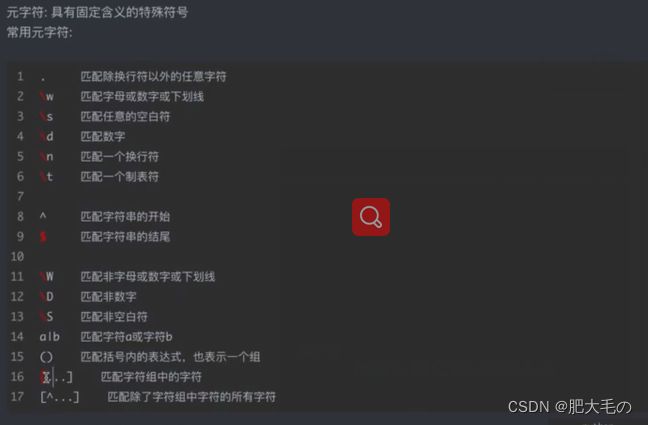
量词
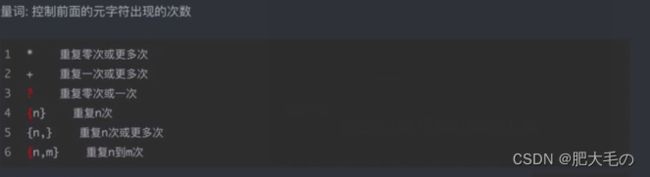

贪婪匹配:匹配字符多的
惰性匹配:匹配字符少的
re模块
2.bs4解析
3.xpath解析
爬取淘宝数据+数据解析
#导入包
import csv
import json
import requests
import re
#设置url
url="https://s.taobao.com/search?q=手机&imgfile=&js=1&stats_click=search_radio_all:1&initiative_id=staobaoz_20220929&ie=utf8"
#设置请求头
headers={
'cookie':'cna=Lui5G1j3TWgCAXxd+EIDtH8T; sgcookie=E100vxvQoorHf6%2FlqRI0LHI5B03U5MC11KRm1Jcak1Iwh%2B1475w46PnDeo81M7FjBzhA32P3C0FUbW0eykTwsYPciG%2Fxvd2orx4VrnrXzT1X9II%3D; uc3=id2=UNGXFRPtNcIWBw%3D%3D&lg2=UtASsssmOIJ0bQ%3D%3D&nk2=sEVjCV4oG1fwQI%2BVa%2BA%3D&vt3=F8dCv4U9ZnOxw3xX0xQ%3D; lgc=%5Cu4F18%5Cu70B9%5Cu4E2D%5Cu7684%5Cu4E0D%5Cu4E00%5Cu6837; uc4=id4=0%40UgbvC8RkTs24%2BY%2BPA5lh8nAeXm2s&nk4=0%40sr1wD2bwUU7ET%2B3Rg2vODdGJpCgTIidLAQ%3D%3D; tracknick=%5Cu4F18%5Cu70B9%5Cu4E2D%5Cu7684%5Cu4E0D%5Cu4E00%5Cu6837; _cc_=WqG3DMC9EA%3D%3D; enc=axuCtPZuy2IKvvyPbZia3ikIEmjBlWC0Si07%2BzzaBeQRyfsl1By1RqrZFsfvypxiXga%2FIgvb97xp3tfhtLKVog%3D%3D; mt=ci=-1_0; thw=cn; _m_h5_tk=31cd87bf813bfa1108c93ea71d22f793_1664445685330; _m_h5_tk_enc=03b672c6dea306c97ee802a93a7fc64f; uc1=cookie14=UoeyChYX4riVFg%3D%3D; cookie2=19bd55fb1fb30246f9cab9d7feed49c2; t=4f91f7992d0deae3445bd869e6f20a68; _tb_token_=fa536e6531e65; alitrackid=www.taobao.com; lastalitrackid=www.taobao.com; xlly_s=1; JSESSIONID=35B4B9F66F17EFC57F9871006BFD2C87; tfstk=cFuVBRTIqELqUqc9pz4Zzv8AyeUAZ9wgdaPUmpCi1kIWNSqci56TZwCza55PIof..; l=eBQAj38RT_E6iK8kBOfZnurza77TsIRAguPzaNbMiOCPO35p5i3PW6u7A1Y9CnGVh6J9R3rp2umHBeYBqIv4n5U62j-la6Dmn; isg=BPz8CUWss7qKj4dnhkPhfGUczZqu9aAfMxHg79Z9AefKoZwr_gX1r3oTgcnZ6dh3',
'referer':'https://s.taobao.com/search?q=iphone+14&commend=all&ssid=s5-e&search_type=item&sourceId=tb.index&spm=a21bo.jianhua.201856-taobao-item.2&ie=utf8&initiative_id=tbindexz_20170306',
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36'
}
#获取响应数据
response=requests.get(url=url,headers=headers)
#response.text得到的是html代码
html_data=response.text
# print(html_data)
#正则匹配,获取html代码中g_page_config,因为g_page_config中存储的数据才包含商品数据
json_str=re.findall("g_page_config=(.*);",html_data)[0]
print(json_str)
#将json数据转换python字典数据
dict_data=json.loads(json_str)
#取出商品列表
com_data=dict_data["mods"]["itemlist"]["data"]["auctions"]
#遍历各个商品得到其数据
for elements in com_data:
# 商品标题
raw_title = elements["raw_title"]
# 图片链接
pic_url = elements["pic_url"]
# 详情链接
detail_url = elements["detail_url"]
# 价格
view_price = elements["view_price"]
# 地点
item_loc = elements["item_loc"]
# 付款人数
try:
view_sales = elements["view_sales"]
except Exception as e:
print(e)
# 商品公司
nick = elements["nick"]
#持久化数据
with open("exciser.csv","a",encoding="utf-8") as f:
csv_wr=csv.writer(f)
csv_wr.writerow([raw_title,pic_url,detail_url,view_price,item_loc,view_sales,nick])