LINUX系统编程-----上
文章目录
- 第一章 linux系统介绍(属于扯闲篇)
-
- linux的概况
- linux的历史
-
- 起源unix
- Posix标准和其他标准
- 开源运动
- linux的诞生
- linux使用
-
- 使用范围
- linux的登录
- 第二章 linux常用命令
-
- linux的shell使用
-
- 切换用户
- 显示所有用户
- 退出当前用户
- 添加用户
- 删除用户
- 当前工作目录
- 当前工作目录下的所有文件
- 改变当前工作目录
- 创建目录
- 删除目录
- 拷贝文件或者目录
- 移动文件或者目录
- 书目录结构显示
- 修改权限
- 掩码
- 这里仅仅做linux的部分介绍所以不详细,详细需要学习linux相关教程
- 安装相应的帮助手册
- 第三章 文件操作
-
- 基于文件指针的文件操作
- linux文件的打开与关闭
- 关闭文件
- fread和fwrite函数
- 格式化读写
- 目录操作
- 修改目录
- 创建和删除文件夹
- stat获取文件信息
- 基于文件描述符的文件操作
-
- 文件描述符
- 读写文件
- 改变文件大小
- mmap
- 文件定位
- 获取文件信息
- 文件描述符的复制
- 管道
-
- 堵塞状态
- 全双工通信和半双工通信
- select的使用
- 第四章 进程
-
- 进程的产生
-
- 什么是进程?
- 虚拟
- 优先级
- 进程的管理
-
- 进程标识符
- 父子进程
- 进程的用户ID和组ID
- 有效用户ID和有效组ID通过函数 geteuid() 和getegid() 获得。
- 进程的构成
-
- 虚拟内存
- 进程地址空间
- 内核态和用户态
- linux的优先级
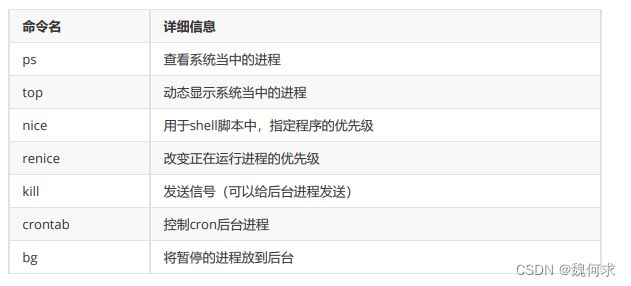
- kill命令
- 系统调用
-
- fork函数
- exec函数族
- 进程控制
-
- 孤儿进程
- 僵尸进程
- wait和waitpid
- 进程终止
- 守护进程
-
- 进程组
- 守护进程的创建流程
- 未完待续
第一章 linux系统介绍(属于扯闲篇)
linux的概况
Linux是一种免费、开源的操作系统,最初由芬兰的Linus Torvalds在1991年开发。它是Unix-like操作系统的一种,具有高度的可定制性和灵活性。Linux操作系统包括内核和一组用户空间程序,可以运行在各种硬件平台上。
Linux的特点包括安全性高、稳定性强、性能卓越、可移植性好、多用户多任务支持等。Linux也支持多种桌面环境,如GNOME、KDE、XFCE等,用户可以根据自己的需要进行选择。
目前,Linux已经成为服务器领域的主流操作系统,被广泛用于Web服务器、数据库服务器、云计算等领域。同时,Linux也被越来越多的个人用户所使用,如开发人员、科学家、艺术家等。
linux的历史

起源unix
Unix 是一种操作系统,它最初由贝尔实验室开发并于 1970 年代初开始使用。Unix 系统是多用户、多任务和支持网络的操作系统,被广泛地用于服务器、工作站和移动设备等各种场合。
Unix 操作系统有许多不同版本,包括商业版本(如 Solaris、HP-UX、AIX 和 macOS)和自由软件版本(如 Linux 和 FreeBSD)。Unix 系统采用了分层的设计方式,其中核心(kernel)是操作系统的核心部分,负责管理硬件和提供基本服务。其他组件则往往是一些标准工具和应用程序,如 shell、编辑器、编译器和数据库等。Unix 系统也提供了强大的命令行界面和脚本语言,使得用户能够方便地进行自动化和批处理操作。
Unix 系统的优点包括稳定性、安全性、可靠性、灵活性和可定制性。这些特点使得 Unix 系统在服务器领域得到了广泛的应用,而且也为开发者提供了一个极好的开发平台。
Posix标准和其他标准
POSIX(可移植操作系统接口)是一个被 IEEE 组织标准化的接口规范,旨在使得不同 Unix 系统间的软件可以互通。POSIX 标准定义了许多基本操作、文件系统、进程管理、线程和 IPC 等方面的 API,以及各种环境变量和配置参数,这些都是 Unix 操作系统中常用的功能。
除了 POSIX 标准外,还有一些其他标准对于操作系统也非常重要。其中最重要的标准之一是 C 语言的 ANSI C 标准和 ISO C 标准,它们定义了 C 语言的语法、语义、库函数等方面的规范。由于许多操作系统都使用 C 语言编写,因此这些标准为开发者提供了一个统一的编程接口。
另一个重要的标准是 TCP/IP 协议族,它是 Internet 上应用最广泛的协议族,定义了数据传输的各个层次的协议。操作系统需要支持 TCP/IP 协议族才能进行网络通信和 Internet 访问。
此外,还有许多其他标准与操作系统相关,如编译器前端和后端的标准、文件格式的标准、安全性标准等等。这些标准都是操作系统开发者需要知道和掌握的内容。
开源运动
开源运动的兴起可以追溯到二十世纪九十年代,当时一些软件开发者开始将自己编写的代码公开发布,并使用自由软件许可证授权他人使用、修改和分发这些代码。这样做的目的是为了推广自由软件的理念,鼓励更多的人贡献自己的力量,同时也为了避免专有软件的限制和不公平。
随着互联网的普及,开源运动逐渐得到了越来越多的支持者和参与者。开源模式具有高度的灵活性和适应性,它可以在全球范围内进行协作,吸引了大量的开发者和用户参与其中。同时,开源软件的质量也受到了广泛认同,很多开源软件已经成为商业系统中不可或缺的组成部分。
开源运动的兴起还促进了知识共享和技术创新的发展。开源社区提倡合作和交流,使得参与者可以共同学习和解决问题。通过开放的合作模式,开源项目能够在更短的时间内获得更多的创意和想法,这对于技术创新来说非常重要。
总的来说,开源运动的兴起是一个重要的历史事件,它推动了软件行业的变革,促进了自由和开放的文化氛围,同时也为技术创新提供了更广阔的空间。
linux的诞生
Linux的历史可以追溯到1991年,当时一个名为Linus Torvalds的芬兰大学生开始编写一个新的操作系统内核。他的目标是开发一种类Unix的操作系统内核,能够在他的个人计算机上运行。
最初,Linus发布了这个内核的版本0.01,并将其上传到互联网上供其他人试用和改进。随着时间的推移,越来越多的程序员参与到Linux内核的开发中,帮助完善它的功能和性能。
Linux很快就成为了自由软件运动的一部分,因为它是开源的并且许可证允许用户自由地使用、修改和传播它。随着Linux的不断发展,许多组织和公司开始支持和使用它。例如,Red Hat和SUSE等公司提供商业版的Linux发行版,并获得了商业成功。
现在,Linux已经成为世界上最流行的操作系统之一,被广泛应用于服务器、桌面、嵌入式系统、移动设备等领域。同时,Linux社区也非常活跃,开发出了众多优秀的开源软件和工具,为用户提供了无限的可能。
成功原因
Linux 之所以能够成功,有以下几个方面的原因:
-
开源:Linux 是一款开源操作系统,这意味着任何人都可以查看其代码、修改和分发,这种开放性吸引了大量技术人员参与到 Linux 的开发中来。同时,开源模式还促进了知识共享和技术创新的发展。
-
自由软件许可证:Linux 使用自由软件许可证(GPL),这使得用户可以自由地使用、修改和分发 Linux 系统,而不需要支付任何费用。这种免费的授权方式吸引了大量用户和企业采用 Linux 系统。
-
可定制性:Linux 拥有高度的可定制性,用户可以根据自己的需求选择适合自己的组件和配置参数,这使得 Linux 能够在不同的场景下得到广泛的应用。
-
多平台支持:Linux 可以运行在多种硬件平台上,包括 PC、服务器、嵌入式设备等等。这使得 Linux 成为了一种非常灵活和通用的操作系统。
-
社区支持:Linux 拥有庞大的用户和开发者社区。这些社区成员提供了丰富的技术资源和支持,使得 Linux 用户可以得到及时的帮助和解决方案。
总的来说,Linux 之所以能够成功,是因为它具有强大的可定制性、开放的开发模式、自由软件许可证、多平台支持和庞大的社区支持。这些因素使得 Linux 成为了一款非常灵活、强大和受欢迎的操作系统。
linux的版本
Linux 是一种开放源代码的操作系统,可以基于其内核构建各种不同版本的 Linux 操作系统。这些不同版本的 Linux 被称为“发行版”(Distribution,缩写为 Distro),它们通常根据用户的需求和偏好,或特定领域的应用进行优化和定制。
以下是几个知名的 Linux 发行版:
- Ubuntu:由 Canonical 公司开发和维护的基于 Debian 的 Linux 发行版,以易用性和稳定性著称,广泛应用于桌面、服务器和云平台等场景。
- Red Hat Enterprise Linux:由 Red Hat 公司开发和维护的商业 Linux 发行版,主要用于企业级服务器和工作站,提供高可靠性和安全性。
- Fedora:由社区驱动的 Linux 发行版,由 Red Hat 公司支持,以最新的软件包和技术为特点。
- CentOS:由社区维护的免费 Linux 发行版,以稳定性和安全性闻名,主要用于企业级服务器和工作站。
- Debian:由社区开发和维护的免费 Linux 发行版,以稳定性和可靠性著称,广泛应用于服务器和桌面环境。
- Arch Linux:由社区维护的适合高级用户的 Linux 发行版,具有高度的灵活性和可定制性,提供了最新的软件包和最新的功能。
此外,还有很多其他的 Linux 发行版,它们都根据特定的需求或目标进行优化和定制,如 Kali Linux 用于网络安全、Raspbian 用于树莓派等。
linux使用
使用范围
Linux 是一种功能强大、灵活并且免费的操作系统,可以应用于各种场景和用途。以下是 Linux 的一些常见使用场景:
- 服务器:Linux 在服务器领域得到了广泛应用,因为它具有高可靠性、安全性和稳定性。许多互联网公司、数据中心和云计算服务提供商都在使用 Linux 系统。
- 桌面:Linux 可以作为桌面操作系统来使用,提供和其他桌面操作系统相同的功能和应用。这些桌面环境包括 GNOME、KDE Plasma、Cinnamon 等。
- 移动设备:Android 是基于 Linux 内核构建的移动操作系统,广泛应用于智能手机、平板电脑等移动设备上。
- 嵌入式系统:Linux 还被广泛用于嵌入式设备的控制系统、网络设备等方面。
- 开发平台:Linux 提供了丰富的开发工具和编程环境,可以作为软件开发平台使用,支持多种编程语言和开发框架。
总的来说,Linux 是一种非常灵活、强大的操作系统,它可以应用于各种场景和用途。无论是在服务器、桌面、移动设备、嵌入式系统还是开发平台,Linux 都提供了高度的可定制性和灵活性,使得用户能够根据自己的需求选择适合自己的发行版和应用程序。
linux的登录
在 Linux 操作系统中,登录通常有两种方式:本地登录和远程登录。
-
本地登录:本地登录是指用户直接使用计算机进行登录。通常在启动或重新启动后,Linux 系统会进入命令行界面或图形化界面,用户需要输入对应的用户名和密码进行登录。
-
远程登录:远程登录是指用户通过网络连接到远程 Linux 计算机进行登录。可以使用 SSH(Secure Shell)协议来实现远程登录。首先确保目标计算机已安装并启动了 SSH 服务,在本地计算机上打开一个可用的终端窗口,输入以下命令:
ssh username@ip_address
其中,username 是目标计算机上的有效用户账户名,ip_address 是目标计算机的 IP 地址。然后输入相应的密码即可登录到远程 Linux 计算机。
在登录后,用户可以执行各种命令来管理文件、安装软件和配置系统等操作。为了保证系统的安全性,用户登录后应该避免使用 root 账户直接操作系统,而是使用普通用户账户进行常规操作,必要时再使用 sudo 或 su 命令获取 root 权限。同时,用户也应该定期更改密码,并且只使用合法来源的软件和命令。
cat /etc/passwd
cat /etc/shadow
uname -a # 查看内核版本
Linux jonaton-linux 5.15.0-60-generic #66-Ubuntu SMP Fri Jan 20 14:29:49 UTC 2023 x86_64 x86_64 x86_64 GNU/Linux
第二章 linux常用命令
由于linux基本上都是远程链接使用所以要试一下网络连接。
ifconfig #可以看到网络信息
ping alibaba.com
#注意没有被墙的网站可以访问,而clash等软件是在应用层所以并不能被ping通
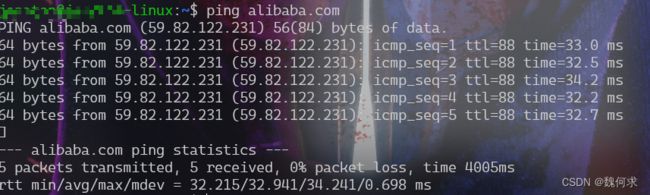
一般情况下默认安装了ssh,所以可以pass掉安装过程
linux的shell使用
由于使用ubuntu所以所有的使用,基于Ubuntu
sudo passwd root
切换用户
su user_name
当嵌套使用su指令来依次进入多个用户时候,多个用户是使用 栈结构 来管理的。执行su指令相当于将
新用户压入栈顶,执行exit指令相当于弹出栈顶
显示所有用户
$cat /etc/passwd
退出当前用户
exit
添加用户
useradd 用户名
只有root用户或者拥有sudo权限的用户使用sudo命令后才能添加用户
#给useradd命令添加参数,在用户名之前使用-m,可以为用户添加默认家目录(如果不添加家目录,这个用户将无法创建文件)。
# 添加用户并指定家目录
$ useradd -m 用户名 -s /bin/bash
#执行完命令,先使用pwd命令获取当前工作目录,使用cd命令进入/home目录,再使用ls命令显示当前
#目录下的所有文件。就会发现home的下面新建了一个新的目录,目录的名字就是用户名,这里就是新用户的家目录
pwd
cd /home
![]()

删除用户
$userdel 用户名
如果用户正在使用中,那么这个用户就不能被删除
如果用户在su命令和exit命令构成的用户 栈结构 当中的时候,那么这个用户也不能被删除
在userdel后面添加-r选项,可以删除用户家目录下的文件
$userdel -r 用户名
当前工作目录
pwd
当前工作目录下的所有文件
ls
ls 工作路径
改变当前工作目录
cd
创建目录
mkdir 目录名
删除目录
rmdir 目录名
如果文件夹中由文件
rmdir -r 目录名
拷贝文件或者目录
cp [选项] 源文件 目标路径|目标文件
cp -r dir1 path
移动文件或者目录
mv [选项] 源文件 目标路径|目标文件
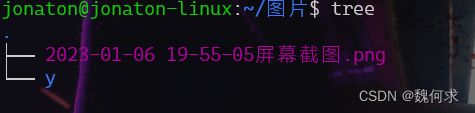
书目录结构显示
一般情况下没有安装tree
所以
sudo apt install tree
使用tree命令就可以显示目录的树状结构
$tree 路径名
修改权限
在 Linux 中,可以使用命令 chmod 来修改文件或目录的权限。 chmod 命令需要指定三个数字参数来表示文件的权限:用户权限、组权限和其他人权限。
每个数字参数都是由三个数字组成的,分别代表读(r)、**写(w)和执行(x)**这三种权限。每种权限用一个二进制位表示,读权限用1表示,写权限用2表示,执行权限用4表示。因此,一个数字参数就是将这三种权限对应的二进制位相加得到的。
例如,数字参数为 7 表示所有权限都被打开,即 rwx;数字参数为 6 表示读和写权限被打开,即 rw-。
在 Linux 中,可以使用两种方式来修改文件或目录的权限:文字设定法和数字设定法。
文字设定法是指通过符号来表示权限。具体地说,可以使用 u、g 和 o 分别表示用户、组和其他人,并且可以用 +、- 和 = 来分别表示添加、删除和设置权限。例如:
# 将 file.txt 的执行权限授予当前用户
chmod u+x file.txt
# 将 dir 目录及其所有子目录和文件的读取、写入和执行权限授予用户和组,但不授予其他人
chmod g+rwx,u+rwx,o-rwx -R dir/
数字设定法是指通过数字来表示权限。具体地说,可以使用三个八进制数来表示用户、组和其他人的权限,其中每个八进制数由三个二进制位来表示读、写和执行权限。例如:
# 将 file.txt 的所有权限都授予用户和组,但不授予其他人
chmod 660 file.txt
# 将 dir 目录及其所有子目录和文件的读取、写入和执行权限授予所有用户
chmod 777 -R dir/
注意,在数字设定法中,每个八进制数所代表的权限是固定的,无法灵活地进行单独的权限修改。因此,相对来说,文字设定法更加直观和易于理解。
掩码
在 Linux 中,还有一种与文件和目录权限相关的概念叫做掩码(umask)。掩码是一个八进制数字,用来指定新创建的文件或目录应该限制哪些权限。具体地说,掩码中每个二进制位代表一个特定的文件权限(读、写、执行),如果对应位上的数值为 0,则表示新文件或目录会保留该权限,反之则表示该权限会被限制。
例如,如果掩码设置为 022,则新创建的文件的权限为 rw-r--r--,新创建的目录权限为 rwxr-xr-x。这是因为在 Linux 中,新建的文件会自动继承创建它的目录的权限,但同时会受到掩码的限制,即默认会关闭掉执行权限。同样地,新建的目录也会继承创建它的目录的权限,并且默认会开启所有权限。
要查看当前系统的掩码设置,可以使用 umask 命令。要修改掩码设置,可以直接使用 umask 命令加上合适的参数,例如:
# 将掩码设置为 027,即新建的文件只有用户有读取和执行权限,组和其他人无任何权限
umask 027
需要注意的是,掩码不影响已经存在的文件和目录的权限,只会影响新创建的文件和目录。如果需要修改已有文件或目录的权限,需要使用 chmod 命令进行修改。
这里仅仅做linux的部分介绍所以不详细,详细需要学习linux相关教程
安装相应的帮助手册
$ sudo apt install manpages-posix-dev
第三章 文件操作
基于文件指针的文件操作
Linux 是一个基于 Unix 的操作系统,它使用一种树形目录结构来组织文件。在 Linux 中,所有的文件都位于根目录下的一个文件系统中,并且可以通过路径名来访问。
Linux 中的文件可以分为几类:
-
普通文件:这是最常见的一种文件类型,包括文本文件、二进制文件等。
-
目录文件:目录文件是一种特殊的文件类型,它包含了其他文件或目录的列表。
-
设备文件:设备文件是用于访问硬件设备的文件,例如磁盘驱动器、打印机等。
-
符号链接文件:符号链接文件是指向其他文件或目录的文件,类似于 Windows 中的快捷方式。
-
套接字文件:套接字文件用于进行进程间通信。
-
管道文件:管道文件也用于进程间通信,但只能支持单向通信。
除了以上文件类型之外,Linux 中还有一些其他的特殊文件类型,例如权限文件、FIFO 文件等。
linux文件的打开与关闭
//所需头文件和相应的参数
SYNOPSIS
SYNOPSIS
#include mode的模式

打开成功时候返回一个文件指针
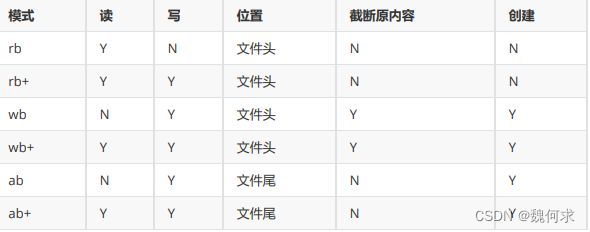
函数fopen()中的mode参数用于指定文件的打开模式。以下是常见的模式选项:
- “r” 只读方式打开文件,该文件必须已经存在。
- “w” 写入方式打开文件,如果文件不存在则会创建该文件,如果文件已经存在则将文件内容清空。
- “a” 追加方式打开文件,如果文件不存在则会创建该文件,如果文件已经存在则在文件末尾追加内容。
- “r+” 读写方式打开文件,该文件必须已经存在。
- “w+” 读写方式打开文件,如果文件不存在则会创建该文件,如果文件已经存在则将文件内容清空。
- “a+” 读写方式打开文件,如果文件不存在则会创建该文件,如果文件已经存在则在文件末尾追加内容。
在这些模式选项后面还可以添加“b”字符,以表示二进制模式。例如,“rb”表示以只读方式打开一个二进制文件。
关闭文件
//关闭文件需要的头文件和参数
SYNOPSIS
#include fread和fwrite函数
SYNOPSIS
#include - 第一个参数是一个指向要写入数据的内存块的指针。
- 第二个参数是每个数据项的字节数。
- 第三个参数是要写入的数据项数。
- 第四个参数是指向FILE结构体的指针,表示要写入的文件。
格式化读写
#include fprintf将格式化后的字符串写入到文件流stream中
sprintf将格式化后的字符串写入到字符串str中
char *fgets(char *s, int size, FILE *stream);
int fputs(const char *s, FILE *stream);
int puts(const char *s);//等同于 fputs(const char *s,stdout);
char *gets(char *s);//等同于 fgets(const char *s, int size, stdin);
- fgets和fputs从文件流stream中读写一行数据;
- puts和gets从标准输入输出流中读写一行数据。
- fgets可以指定目标缓冲区的大小,所以相对于gets安全,但是fgets调用时,如果文件中当前行的
- 字符个数大于size,则下一次fgets调用时,将继续读取该行剩下的字符,fgets读取一行字符时,保留行尾的换行符。
- fputs不会在行尾自动添加换行符,但是puts会在标准输出流中自动添加一换行符。
- 文件定位:文件定位指读取或设置文件当前读写点,所有的通过文件指针读写数据的函数,都是从文件的当前
读写点读写数据的。常用的函数有:
#include #include 目录操作
获取、改变当前目录
//获取当前目录
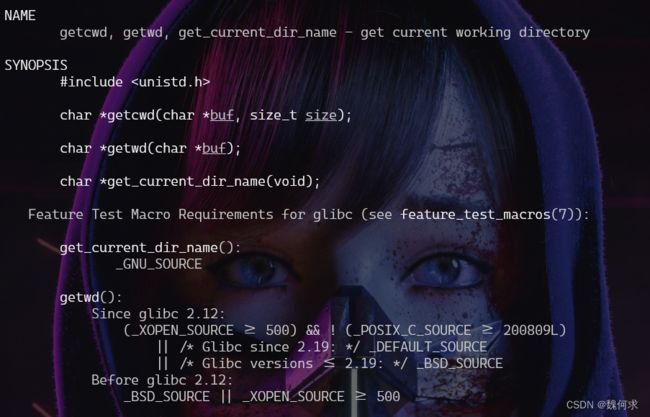
char *getcwd(char *buf, size_t size);
char *getwd(char *buf);
char *get_current_dir_name(void);
-
getcwd()` 是一个函数,它的作用是获取当前工作目录(Current Working Directory),即程序当前所在的目录路径。
在使用
getcwd()函数时,需要包含头文件Copy Codechar *getcwd(char *buf, size_t size);其中,
buf参数是一个指向存储路径名的缓冲区的指针,size参数表示缓冲区大小。如果buf参数为 NULL,则getcwd()会自动分配一个适当大小的缓冲区。调用成功后,buf指向包含当前工作目录的字符串,返回值为buf。
#include 修改目录
#include 
创建和删除文件夹
#include 目录的存储原理
-
Linux的文件系统采用了一种树形结构,称为“目录树”或者“文件系统层次结构”,它由许多的目录和文件组成,每个目录都可以包含其他目录和文件,形成了一个分层的结构。
在Linux中,所有的目录和文件都存储在虚拟文件系统(Virtual File System,VFS)中。这个虚拟文件系统将硬件和文件系统之间进行了抽象,使得不同的文件系统可以使用相同的接口操作。
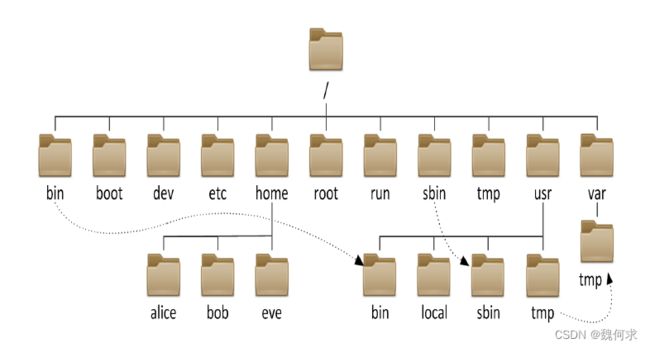
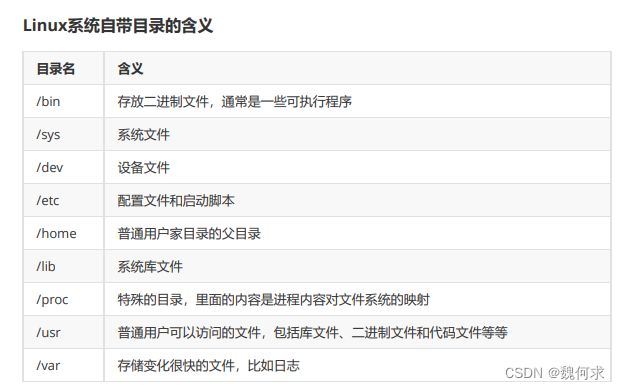
Linux文件系统的目录结构是以根目录(/)作为起点的,所有的目录都是从根目录开始展开的。例如,/usr/bin表示usr目录下的bin子目录。在Linux中有一些特殊的目录,如下:
- /:根目录,所有的文件和目录都是从这里开始。
- /bin:存放系统命令(binary)的目录。
- /sbin:存放系统管理员使用的命令(system binary)。
- /etc:存放系统配置文件(configuration)的目录。
- /dev:存放设备文件(device)的目录。
- /proc:存放进程信息(process)的目录。
- /var:存放系统运行时需要变化的文件(variable)的目录。
- /home:存放用户主目录(homedir)的目录。
在Linux中,所有的目录和文件都有权限控制,可以设置哪些用户或组可以访问它们。此外,因为Linux是支持多用户的操作系统,每个用户都有自己的主目录,这样不同的用户之间可以互相隔离,保证了系统的安全性。
struct __dirstream
{
void *__fd;
char *__data;
int __entry_data;
char *__ptr;
int __entry_ptr;
size_t __allocation;
size_t __size;
__libc_lock_define (, __lock)
};
typedef struct __dirstream DIR;
在 Linux 中,你可以使用 C 语言标准库中的函数来管理和操作文件目录。以下是一些常见的函数及其参数:
-
opendir()函数:DIR *opendir(const char *name);参数:
name:要打开的目录的路径名。
返回值:
- 如果打开目录成功,则返回一个指向
DIR类型结构体的指针。 - 如果出错,则返回 NULL,并设置相应的错误码(通过
errno变量获取)。
-
readdir()函数:struct dirent *readdir(DIR *dirp);参数:
dirp:先前由opendir()打开的目录指针。
返回值:
- 如果读取下一个目录项成功,则返回一个指向
dirent类型结构体的指针。 - 如果已到达目录末尾或出现错误,则返回 NULL,并设置相应的错误码(通过
errno变量获取)。
-
closedir()函数:int closedir(DIR *dirp);参数:
dirp:先前由opendir()打开的目录指针。
返回值:
- 如果成功关闭目录,则返回 0。
- 如果出错,则返回 -1,并设置相应的错误码(通过
errno变量获取)。
-
mkdir()函数:int mkdir(const char *path, mode_t mode);参数:
path:要创建的目录路径名。mode:新目录的权限和属性。可以使用chmod()函数修改它。
返回值:
- 如果成功创建目录,则返回 0。
- 如果出错,则返回 -1,并设置相应的错误码(通过
errno变量获取)。
-
rmdir()函数:int rmdir(const char *pathname);参数:
pathname:要删除的目录路径名。
返回值:
- 如果成功删除目录,则返回 0。
- 如果出错,则返回 -1,并设置相应的错误码(通过
errno变量获取)。
-
chdir()函数:int chdir(const char *path);
参数:
- `path`:要更改为的目录路径名。
返回值:
- 如果成功更改当前工作目录,则返回 0。
- 如果出错,则返回 -1,并设置相应的错误码(通过 `errno` 变量获取)。
7. `getcwd()` 函数:
char *getcwd(char *buf, size_t size);
参数:
- `buf`:用于存储当前工作目录的缓冲区指针。
- `size`:缓冲区大小。
返回值:
- 如果成功获取当前工作目录,则返回指向缓冲区的指针。
- 如果出错,则返回 NULL,并设置相应的错误码(通过 `errno` 变量获取)。
8. `rename()` 函数:
rename(const char *oldpath, const char *newpath);
参数:
- `oldpath`:要重命名的文件或目录的路径名。
- `newpath`:新的文件或目录的路径名。
返回值:
- 如果成功重命名文件或目录,则返回 0。
- 如果出错,则返回 -1,并设置相应的错误码(通过 `errno` 变量获取)。
**下面例子是深度遍历访问目录的例子**
```c
//使用深度优先遍历访问目录的例子
#include
#include
#include
#include
void listdir(const char *name, int indent, int depth)
{
if (depth <= 0) {
printf("%*s[%s]\n", indent, "", "...");
return;
}
DIR *dir = opendir(name);
if (!dir) {
fprintf(stderr, "Error: Cannot open directory '%s'\n", name);
return;
}
struct dirent *entry;
while ((entry = readdir(dir)) != NULL) {
if (entry->d_type == DT_DIR) {
if (strcmp(entry->d_name, ".") == 0 || strcmp(entry->d_name, "..") == 0)
continue;
printf("%*s└─ %s/\n", indent, "", entry->d_name);
char path[1024];
snprintf(path, sizeof(path), "%s/%s", name, entry->d_name);
listdir(path, indent + 2, depth - 1);
} else {
printf("%*s└─ %s\n", indent, "", entry->d_name);
}
}
closedir(dir);
}
int main(int argc, char **argv)
{
if (argc != 2) {
fprintf(stderr, "Usage: %s \n", argv[0]);
return 1;
}
printf("目录:%s\n", argv[1]);
listdir(argv[1], 0, 3); // 限制递归深度为 3 层
return 0;
}
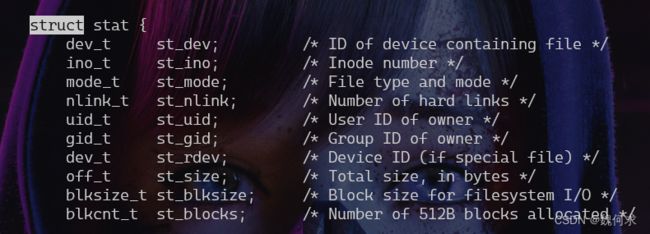
stat获取文件信息
#include 基于文件描述符的文件操作
文件描述符
文件描述符是一个用来标识打开的文件或者I/O设备的整数值。在Unix和类Unix操作系统中,所有的输入/输出设备都被看作是文件,包括终端、磁盘文件、网络套接字等等。当应用程序需要读取或写入这些设备时,它们会使用文件描述符来标识要读写的设备。文件描述符在应用程序中通常是通过open()、socket()等函数调用获得的。在程序读写设备完毕后,应该关闭文件描述符以释放资源。
在Unix和类Unix操作系统中,打开、创建和关闭文件通常是通过系统调用来完成的。下面是三个常用的系统调用:
- 打开文件:open()系统调用可以用于打开一个已经存在的文件或者创建一个新文件。它的原型如下:
int open(const char *pathname, int flags);
pathname参数指定了要打开的文件的路径名,flags参数指定了打开文件时的选项,比如是否只读、是否追加等。
- 创建文件:可以使用creat()系统调用来创建一个新的空文件。它的原型如下:
int creat(const char *pathname, mode_t mode);
pathname参数指定了要创建的文件的路径名,mode参数指定了文件权限。
- 关闭文件:关闭已经打开的文件可以使用close()系统调用。它的原型如下:
int close(int fd);
fd参数为要关闭的文件描述符。
下面是一个例子,演示如何打开、写入内容并关闭文件:
#include 在这个例子中,我们通过open()系统调用创建了一个名为test.txt的文件,并且以只写、创建和截断的方式打开它。然后我们使用write()函数向文件中写入了Hello, world!这个字符串,并最终使用close()关闭文件。
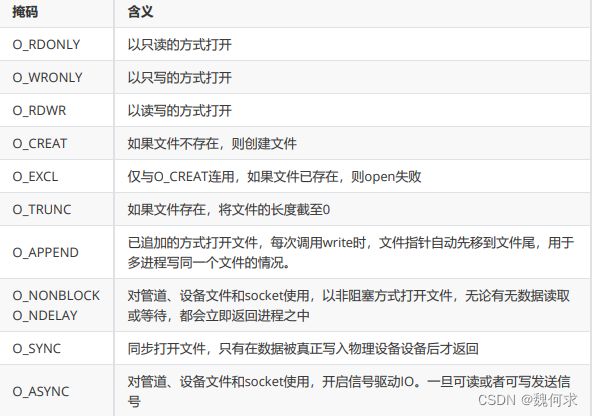
- 执行成功时,open函数返回一个文件描述符,表示已经打开的文件;执行失败是,open函数返回-1,并设置相应的errno
- flags和mode都是一组掩码的合成值,flags表示打开或创建的方式,mode表示文件的访问权限。
- flags的可选项有
读写文件
//用文件描述符
#include
//用read write函数的程序
#include 改变文件大小
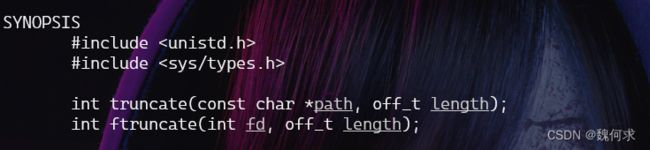
#include ftruncate() 是一个函数,用于截断文件大小为指定的长度。在使用 ftruncate() 函数时,需要指定一个文件描述符和希望将该文件截断至的新长度。如果新长度比文件的当前长度小,则文件内容将被截断到新长度为止。如果新长度比文件的当前长度大,则文件的大小将增加,并且新增部分将被清零。该函数通常用于缩小或清空日志文件等。
以下是 ftruncate() 函数的语法:
#include 其中,fd 是要操作的文件描述符,length 是要设置的新文件长度,off_t 类型表示长度的数据类型。
如果 ftruncate() 调用成功,则返回值为 0;否则返回 -1,并设置相应的错误代码
#include mmap
mmap是一种在内存映射文件和设备的Unix和Unix-like操作系统中使用的系统调用。它允许进程将一个文件或设备映射到它的虚拟地址空间中,从而使得进程可以像访问内存一样访问该文件或设备。
mmap函数可以将一个文件或设备映射到调用进程的地址空间中,并返回一个指向映射区域的指针。通过这个指针,进程可以直接访问这个文件或设备上的数据,就好像这些数据已经被读入内存一样。当进程访问映射区域时,操作系统会自动将所需的数据从文件或设备中读取到内存中,因此可以避免频繁的磁盘I/O操作。
此外,mmap还支持对映射区域进行读写锁定、设置访问权限、共享内存等操作,因此在实现多进程通信和共享数据时非常有用。
使用mmap函数经常配合函数ftruncate来扩大文件大小
#include \n" , argv[0]);
exit(EXIT_FAILURE);
}
// 打开文件
int fd = open(argv[1], O_RDWR);
if (fd == -1) {
perror("open");
exit(EXIT_FAILURE);
}
printf("fd = %d\n", fd);
// 设置文件大小为5字节
if (ftruncate(fd, 5) == -1) {
perror("ftruncate");
exit(EXIT_FAILURE);
}
// 将文件映射到内存中
char *p;
p = (char *)mmap(NULL, 5, PROT_READ|PROT_WRITE, MAP_SHARED, fd, 0);
if (p == MAP_FAILED) {
perror("mmap");
exit(EXIT_FAILURE);
}
// 在映射的内存中写入字符串结束符
p[5] = 0;
// 输出映射的内存中的内容
printf("%s\n", p);
// 修改映射的内存中的内容,将第一个字符改为'H'
p[0] = 'H';
// 取消内存映射
if (munmap(p, 5) == -1) {
perror("munmap");
exit(EXIT_FAILURE);
}
// 关闭文件描述符
if (close(fd) == -1) {
perror("close");
exit(EXIT_FAILURE);
}
return 0;
}
文件定位
文件定位是指在文件中准确定位到某个位置的过程。在计算机中,文件通常以二进制形式存储,并且可以通过文件指针来访问这些数据。文件指针是一个指向文件内部位置的变量,在读取或写入文件时,它会跟踪当前位置。
文件定位可以使用各种方法实现,其中最常用的方法是使用偏移量。偏移量是一个表示要移动多少字节的整数值,可以相对于当前位置或文件的开头或结尾。
文件定位还可以使用搜索方法来实现。搜索方法会在文件中查找特定的数据或字符串,并返回其位置。
文件定位在许多场合下都是非常重要的,如在读取大型文件时,需要准确地读取文件中的某一部分,或者在向文件中插入数据时,需要将指针定位到正确的位置。
lseek() 函数是用于在文件中进行定位的系统调用函数,它可以通过改变文件指针来实现文件定位。在 POSIX 标准中,lseek() 函数的原型定义如下:
#include 其中,参数 fd 是打开文件的文件描述符,offset 是要移动的偏移量,whence 则表示相对位置。其中 whence 可以取以下三个值之一:
- SEEK_SET: 从文件开始处计算偏移量。
- SEEK_CUR: 从当前位置计算偏移量。
- SEEK_END: 从文件末尾处计算偏移量。
如果操作成功,则返回新的文件指针位置,否则返回 -1 表示出错,并设置 errno 变量来指示错误类型。通常情况下,文件指针的起始位置为文件开头,也就是说,第一次调用 lseek() 函数时,whence 参数应该使用 SEEK_SET 值。
lseek() 函数一般用于处理大型文件,比如音频、视频和数据库等,可以快速跳过不需要的数据,或者精确地读取特定位置的数据。
#include \n" , argv[0]);
return 1;
}
int fd = open(argv[1], O_RDWR); // 打开指定文件,以读写模式打开
if (fd == -1) { // 错误检测和处理
perror("open");
return 1;
}
off_t ret = lseek(fd, 5, SEEK_SET); // 移动文件指针到第5个字节
printf("pos = %ld\n", ret); // 输出当前文件指针的位置
char buf[128] = {0}; // 定义缓冲区
ssize_t nread = read(fd, buf, sizeof(buf)); // 读取文件内容到缓冲区中
if (nread == -1) { // 错误检测和处理
perror("read");
return 1;
}
printf("buf = %s\n", buf); // 输出读取到的文件内容
close(fd); // 关闭文件
return 0; // 返回程序结束状态码
}
获取文件信息
#include 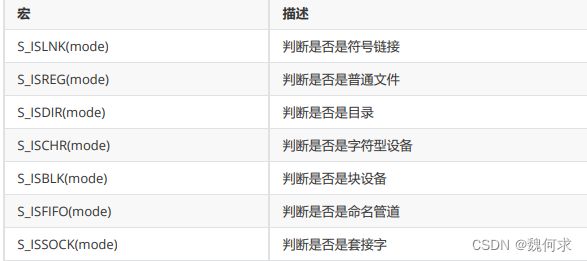
文件描述符的复制
#include dup()和dup2()是UNIX和类UNIX操作系统中的函数,用于复制文件描述符。这些函数允许进程将一个文件描述符复制到另一个文件描述符,以便在读取或写入文件时使用多个文件描述符。
dup()函数会复制指定的文件描述符,并返回一个新的文件描述符,该文件描述符与原始文件描述符引用相同的打开文件。如果成功,它将返回新的文件描述符,如果失败,则返回-1。下面是dup()函数的语法:
#include 其中,oldfd 是要复制的原始文件描述符。
而dup2()函数与dup()函数类似,但允许显式地指定新的文件描述符。如果新文件描述符已经打开,则会先关闭其对应的文件。下面是dup2()函数的语法:
#include 其中,oldfd 是要复制的原始文件描述符,newfd 是新的文件描述符。
总之,dup()和dup2()函数是UNIX和类UNIX操作系统中非常常用的系统调用,它们可用于实现各种不同类型的I/O操作,例如将数据从一个文件描述符发送到另一个文件描述符,或者在创建子进程时重定向标准输入/输出流。
fileno()函数
文件描述符(File Descriptor)和文件指针(File Pointer)都是用于在程序中进行文件操作的概念,但是它们有着不同的含义和作用。
文件描述符是一个整数,由操作系统内核分配给已打开的文件,并用于标识该文件。文件描述符通常是非负整数,其值与文件在操作系统中的位置相关联,可以用于在程序中进行底层的文件读写操作,如使用read、write等函数。在Linux系统中,0、1、2分别代表标准输入、标准输出和标准错误输出的文件描述符。
文件指针是一个指向FILE类型结构体的指针,由C标准库提供并维护。通过文件指针,我们可以对文件进行高层次的操作,如使用fread、fwrite等函数进行二进制文件的读写,或者使用fgets、fprintf等函数进行文本文件的读写。
因此,文件描述符和文件指针的区别在于,文件描述符是由操作系统内核维护的底层概念,而文件指针是由C标准库封装的高层概念。在进行文件操作时,需要根据具体的需求选择合适的方式。
fileno函数是一个C标准库函数,它的作用是获取文件流所对应的文件描述符。文件描述符是操作系统内核用于标识已打开文件的标识符,可以用于在程序中进行文件操作。
在本程序中,fp是使用fopen函数打开文件后返回的文件指针,类型为FILE *。而我们需要获取文件描述符,以便进行底层的文件读写操作,因此调用了fileno函数将其转换为文件描述符类型并存储在fd变量中。
具体的语句为int fd = fileno(fp);,其中fp表示要进行转换的文件指针,fileno(fp)表示将文件指针转换为文件描述符,并将结果赋值给fd变量。
管道
- (有名)管道文件是用来数据通信的一种文件,它是半双工通信,它在ls -l命令中显示为p,它不能存储数据

mkfifo p
写两个文件来读写
#include #include 堵塞状态
某个模式下,read函数如果不能从文件中读取内容,就将进程的状态切换到阻塞状态,不再继续执行
全双工通信和半双工通信
由于管道实现的是半双工通信,所以实现两个程序之间通信就需要两个管道。当多个实现通信时候,所需要的管道数目就需要集合倍增加。
I/O多路转接模型是一种基于事件驱动的网络编程模型,用于实现高效的I/O多路复用。它通过操作系统提供的API(如epoll、kqueue等)来同时监控多个文件描述符(如socket),并在有事件发生时通知应用程序进行相应的处理,从而避免了创建多个线程或进程的开销。
I/O多路复用是指在一个进程中,同时监听多个文件描述符上的I/O事件。当其中任意一个描述符就绪时,就可以对其进行读取或写入操作,从而实现高效的I/O处理。常见的I/O多路复用技术有select、poll和epoll等。
相对于select和poll,epoll具有更高的性能和可扩展性。其主要优势在于:
- 支持较大数量的文件描述符:epoll可以同时监听数以百万计的文件描述符,而且随着监听数目的增加,其性能不会随之下降;
- 高效:epoll使用回调函数机制,当有事件发生时,只需要将事件信息存储在内核空间,然后通知应用程序即可,无需像select或poll那样每次都去遍历所有文件描述符;
- 支持水平触发和边缘触发两种模式:水平触发模式下,只要缓冲区中还有数据,内核就会一直通知应用程序;边缘触发模式下,只有在缓冲区状态变化时才通知应用程序,可以减少不必要的通知。
总之,I/O多路转接模型是一种高效、可靠的网络编程方式,通过使用操作系统提供的API,可以实现同时监听多个文件描述符的I/O事件,从而优化系统性能。
select的使用
多路转接模型(Multiplexing)和select都是用于实现I/O多路复用的技术。
I/O多路复用是指通过一种机制,使得一个进程能同时监听多个文件描述符(socket或文件)。这样,在有多个连接需要处理时,就可以使用单线程处理它们,从而避免了创建多个线程或进程的开销。
其中,多路转接模型是一种基于事件驱动的模型,它利用操作系统提供的API(如epoll、kqueue等)来监控多个文件描述符,并在有事件发生时通知应用程序进行相应的处理。
而select则是一种比较早期的I/O多路复用技术,它通过轮询方式不断检查文件描述符是否就绪,如果有就绪的文件描述符,则立即返回。相对于多路转接模型,select存在效率低下、支持文件描述符数量受限等问题,但仍然广泛用于各种平台和语言的网络编程中。
总之,多路转接模型和select都是为了实现I/O多路复用而存在的技术,但多路转接模型通常被认为是更加高效和可靠的选择。
int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
nfds:需要监听的最大文件描述符加1;
readfds:读事件集合,包含要监听的读事件的文件描述符;
writefds:写事件集合,包含要监听的写事件的文件描述符;
exceptfds:异常事件集合,包含要监听的异常事件的文件描述符;
timeout:超时时间,如果在指定时间内没有事件发生,则退出select函数。

select函数的返回值为就绪文件描述符的数量(即上述三个集合中有事件发生的描述符数量)。如果在超时时间内没有事件发生,返回0;如果出错,返回-1。
使用select函数的主要缺点是其效率较低,因为每次调用select都需要遍历所有的文件描述符集合,检查是否有事件发生。另外,select支持的最大文件描述符数量存在限制,致使其不能很好地应对超大规模的高并发场景。
//readset、writeset、exceptionset都是fd_set集合
//集合的相关操作如下:
void FD_ZERO(fd_set *fdset); /* 将所有fd清零 */
void FD_SET(int fd, fd_set *fdset); /* 增加一个fd */
void FD_CLR(int fd, fd_set *fdset); /* 删除一个fd */
int FD_ISSET(int fd, fd_set *fdset); /* 判断一个fd是否有设置 *
//简单例子
#include 第四章 进程
进程的产生
单批次处理系统一次只能处理一个任务,例如打印一份文档或者运行一个程序。这种处理方式通常被用于早期的计算机系统中,因为那些计算机资源有限,不能同时处理多个任务。
多批次处理系统可以同时处理多个任务,但这些任务需要按照特定的顺序进行排队。这种处理方式通常用于大型计算机系统中,比如服务器和超级计算机等,它们可以同时处理多个任务,但仍然需要按照顺序进行排队。
分布式处理系统允许多台计算机在网络上共同协作处理任务,每台计算机都可以独立地执行部分任务,然后将结果合并。这种处理方式通常用于大规模计算、数据处理和存储等应用场景,因为它可以在不同的计算机之间进行负载均衡,提高整体性能和可靠性。
分时操作系统是一种多用户、多任务的计算机操作系统,它允许多个用户在同一时间共享一台计算机,并能够同时运行多个程序。
分时操作系统将计算机资源(如 CPU、内存、I/O 设备等)进行切片,每个用户都被分配到一定的资源,并且每个用户可以同时使用这些资源。这种方式不仅提高了计算机的利用率,还使得多个用户可以在同一时间内使用计算机,从而实现了多任务处理。
在分时操作系统中,每个用户都有一个独立的终端,用户可以通过终端与操作系统进行交互,执行各种命令和程序。操作系统会根据用户输入的命令和程序进行调度,并将执行结果返回给用户。
进程的产生是由于操作系统需要管理多个任务同时运行的需求。在早期的计算机系统中,一次只能执行一个程序,当一个程序正在运行时,其他程序必须等待直到它完成才能执行。这种方式效率低下且浪费计算资源。
为了提高计算机系统的资源利用率,研究人员开始探索如何实现并发执行多个程序的方法。最终,进程概念被提出,它可以让操作系统分配资源和控制多个任务的执行。
进程的概念最早由斯图尔特·F·博伊斯(Stuart F.Boyes)在1960年代初在他的博士论文中提出。随着计算机技术的不断发展,进程的概念得到了广泛的应用,成为了计算机操作系统中重要的概念之一。
什么是进程?
进程是指正在运行中的程序或应用程序的实例。一个进程由计算机系统分配给它的一定的系统资源和处理这些资源的线程组成,并且可以与其他进程进行通信和协作完成任务
从操作系统的角度来看,进程是资源分配的基本单位。
虚拟
利用进程机制,所有的现代操作系统都支持在同一个时间来完成多个任务。尽管某个时刻,真实的CPU只能运行一个进程,但是从进程自己的角度来看,它会认为自己在独享CPU(即虚拟CPU),而从用户的角度来看多个进程在一段时间内是同时执行的,即并发执行。在实际的实现中,操作系统会使用调度器来分配CPU资源。调度器会根据策略和优先级来给各个进程一定的时间来占用CPU,进程占用CPU时间的基本单位称为时间片,当进程不应该使用CPU资源时,调度器会抢占CPU的控制权,然后快速地切换CPU的使用进程。这种切换对于用户程序的设计毫无影响,可以认为是透明的。由于切换进程消耗的时间和每个进程实际执行的时间片是在非常小的,以至于用户无法分辨,所以在用户看起来,多个进程是在同时运行的
优先级
调度器是操作系统中的一个重要组成部分,它负责管理计算机系统中多个进程(或线程)之间的调度和执行。在多任务操作系统中,由于 CPU 只能同时执行一个进程,因此需要通过调度器来协调多个进程的执行。调度器根据一定的算法,分配给每个进程一段时间片,这样每个进程可以交替运行,并实现多任务处理。
调度器可以采用多种算法来进行进程调度,包括先来先服务(FCFS)、最短作业优先(SJF)、轮转调度(Round Robin)等等。每种算法都有特定的优缺点,适用于不同的场景和应用需求。
调度器还需要考虑进程的优先级、并发访问、死锁避免等问题。为了确保各个进程能够公平地获得 CPU 时间,调度器会根据不同的策略动态地调整进程的优先级和时间片大小,从而实现高效、公平、稳定的进程调度和管理。
进程的管理
Linux 内核使用进程描述符(Process Descriptor,简称 task_struct)来管理进程信息。每个进程都有一个唯一的进程 ID(PID),进程描述符中包含了该进程所需的各种信息,包括:
-
进程状态:进程可以处于运行、等待、停止或僵尸等不同的状态,内核会根据进程的状态动态调度和管理进程。
-
进程优先级:内核根据进程的优先级来决定给予进程多少 CPU 时间片,以及何时抢占其他进程。
-
进程资源:进程需要使用系统资源,如 CPU 时间、内存空间、文件句柄、I/O 设备等,内核会为每个进程分配一定的资源,并对其进行统一管理。
-
父子关系:在 Linux 中,每个进程都有一个父进程,同时也可以创建子进程。进程描述符中记录了进程之间的关系,以及进程创建和销毁的时间戳等信息。
-
进程上下文:进程上下文包括用户空间和内核空间,进程需要通过系统调用来切换上下文,从而完成与其他进程的交互和通信。
除此之外,进程描述符还包含了其他很多细节信息,如进程信号量、进程地址空间、进程间通信机制等等。这些信息都是 Linux 内核管理和调度进程的重要依据,保证了系统能够高效、稳定地运行。
进程标识符
为了方便普通用户定位每个进程,操作系统为每个进程分配了一个唯一的正整数标识符,称为进程ID。在Linux中,进程之间存在着亲缘关系,如果一个进程在执行过程中启动了另外一个进程,那么启动者就是父进程,被启动者就是子进程。
在Linux启动时,如果所有的硬件已经配置好的情况下,进程0会被bootloader程序启动起来,它会配置实时时钟,启动init进程(进程1)和页面守护进程(进程2)
父子进程
#include 进程的用户ID和组ID
#include 有效用户ID和有效组ID通过函数 geteuid() 和getegid() 获得。
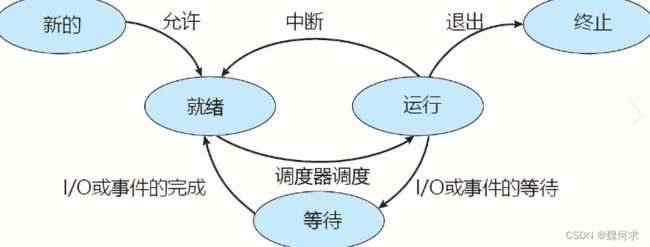
#include 进程状态是指操作系统中一个进程正在使用的资源和当前进程在执行过程中的状态。在操作系统中,通常有以下几种进程状态:
- 运行状态(Running):表示进程正在CPU上执行。
- 就绪状态(Ready):表示进程已经分配到了所需的资源,等待CPU的调度执行。
- 阻塞状态(Blocked):表示进程因为某些原因而暂时无法执行,例如等待输入/输出操作完成、等待某个信号等。
- 创建状态(New):表示操作系统已经创建了进程控制块但还没有分配资源。
- 终止状态(Terminated):表示进程已经运行结束并释放了所有资源。
这些状态可以根据不同的操作系统和实现方式略有不同,但以上五种状态是较为常见的状态类型。
进程状态图
$ps -elf
#找到第二列,也就是列首为S的一列
#R 运行中
#S 睡眠状态,可以被唤醒
#D 不可唤醒的睡眠状态,通常是在执行IO操作
#T 停止状态,可能是被暂停或者是被跟踪
#Z 僵尸状态,进程已经终止,但是无法回收资源
进程的构成
虚拟内存
在进程本身的视角中,它除了会认为CPU是独占的以外,它还会以为自己是内存空间的独占者,这种从进程视角看到的内存空间被称为虚拟内存空间。当操作系统中有多个进程同时运行时,为了避免真实的物理内存访问在不同进程之间发生冲突,操作系统需要提供一种机制在虚拟内存和真实的物理内存之间建立映射。
进程地址空间
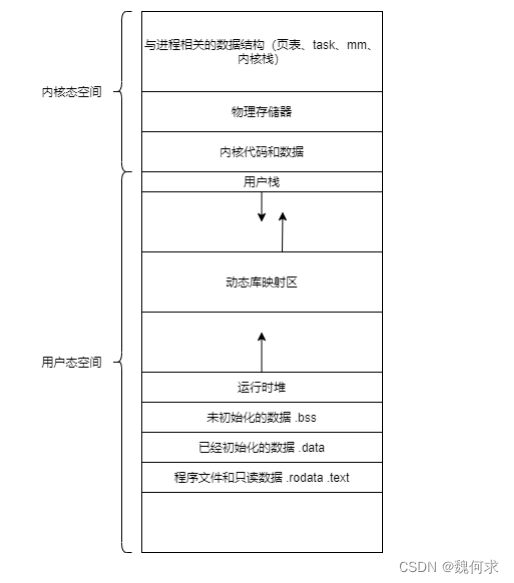
内核态和用户态
用户态和内核态是操作系统中的两个不同的运行级别,用于区分进程执行时所拥有的权限和能够访问的资源。
用户态(User Mode)是指进程在正常情况下的运行状态,此时进程只能访问自己的私有地址空间和一些受限制的系统资源,例如文件、网络等,但不能直接访问硬件设备。在用户态下,进程需要通过系统调用(system call)向操作系统请求更高权限的资源或服务。
内核态(Kernel Mode)是指进程在获得了操作系统授予的更高权限之后的运行状态,此时进程可以访问所有内存空间、硬件设备和系统资源,同时也具有更高的响应速度和处理能力。在内核态下,进程可以直接调用操作系统提供的各种服务,而不需要经过系统调用来进行间接访问。
操作系统将进程的运行状态分为用户态和内核态,是为了保证系统的稳定性、安全性和效率。在大多数情况下,操作系统会尽可能地将进程保持在用户态,只有在必要的时候才会切换到内核态,并且尽快返回用户
ps -elf //unix 风格
ps aux //bsd风格
top命令
top命令是一种常用的系统性能监控工具,可以显示当前系统中进程的运行状态、资源占用情况和系统负载等信息。
在终端中输入top命令后,会打开一个实时的进程监控界面,显示系统中所有进程的相关信息,包括进程ID、CPU占用率、内存占用率、虚拟内存使用情况、进程优先级等等。同时,也会显示系统的负载情况,包括CPU、内存和交换空间的使用率等指标。
top命令还提供了一些交互式功能,例如可以按照某个特定的指标(如CPU或内存占用率)对进程进行排序,或者查看某个具体进程的详细信息。此外,top命令还支持一些快捷键,例如H键可显示线程视图,M键可按内存使用量排序进程等。
总之,top命令是一款非常实用的系统监控工具,可以帮助管理员及时发现系统异常、诊断问题并优化系统性能。
linux的优先级
在Linux系统中,进程的优先级是通过一个称为“nice值”的整数来表示的。nice值越小,表示进程的优先级越高,反之则越低。
正常情况下,nice值的范围为-20到+19之间,其中-20表示最高优先级,+19表示最低优先级。通常情况下,大多数进程的nice值都是0,表示默认优先级。
除了nice值以外,Linux还提供了另外一个优先级概念,即实时优先级(real-time priority)。实时优先级通常用于对需要及时响应的进程进行特殊处理,例如音频、视频播放和实时控制等应用。
Linux系统中实时优先级的取值范围为0到99之间,数字越小表示优先级越高。不过,实时优先级只能由特权用户(例如root用户)进行设置,普通用户无法直接设置实时优先级。
总之,Linux系统中的优先级概念非常重要,可以帮助管理员合理分配系统资源,提高系统稳定性和性能。
renice
renice命令是一个用于调整进程优先级nice值的工具,可以改变已经运行的进程或者指定新创建的进程的优先级。
在Linux系统中,renice命令可以通过以下格式来使用:
renice priority [-p] pid [...]
其中,priority表示要设置的新的nice值,pid则表示要调整优先级的进程ID。如果省略-p参数,则表示对当前shell中所有进程进行调整。如果同时指定多个pid,则对这些进程同时进行优先级调整。
举个例子,假设我们希望将pid为1234的进程的nice值调整为10,可以使用如下命令:
renice 10 -p 1234
执行该命令后,操作系统会重新分配该进程的资源,提高它的运行优先级。
需要注意的是,renice命令只能降低进程优先级(即增加nice值),不能提高进程优先级。此外,只有具有足够权限的用户才能使用renice命令对进程进行优先级调整。
kill命令
kill命令是在Linux和其他类Unix操作系统上用来终止进程的命令。
kill命令一般有两种使用方式:
-
使用进程ID终止进程。可以使用如下格式的命令:kill PID,其中PID是指要终止的进程的进程ID。
-
使用信号终止进程。可以使用如下格式的命令:kill -SIGNAME PID,其中SIGNAME是指要发送的信号名称(例如TERM表示正常结束信号),PID是指要终止的进程的进程ID。
需要注意的是,通常情况下,使用kill命令终止进程会发送SIGTERM信号,这个信号告诉进程应该尽快退出,并进行资源清理工作。如果进程没有响应SIGTERM信号,可以考虑使用SIGKILL信号强制终止进程,这个信号会直接杀死进程并释放其占用的资源。
除了kill命令以外,Linux还提供了其他一些用于管理进程的工具,例如pkill、pgrep等命令,它们可以根据进程名或者其他属性来查找和终止进程。
kill命令常用的参数如下:
-SIGNAME:指定发送的信号类型,其中SIGNAME可以是信号名称或者对应的数字。例如,kill -9 PID表示发送SIGKILL信号,而kill -TERM PID表示发送SIGTERM信号。-l:列出所有可用的信号名称。-s:与-SIGNAME参数类似,也是用来指定信号类型的,不过-S参数需要紧跟在kill命令后面,而-SIGNAME则需要使用空格隔开。-p:指定要终止进程的进程ID列表,多个进程ID之间使用空格分隔。-a:与-p参数一起使用,表示同时终止该进程的子进程。-u:指定要终止进程的用户名称或者用户ID。
需要注意的是,如果没有指定任何信号类型,则默认发送SIGTERM信号。同时,只有拥有足够权限的用户才能使用kill命令终止其他进程。
系统调用
#include fork函数
在Linux系统中,fork()是一个非常重要的系统调用函数,它用于创建一个新进程。当进程调用fork()函数时,操作系统会创建一个与原进程几乎完全相同的新进程,包括代码、数据、堆栈、文件描述符等。
在调用fork()函数后,父进程和子进程都会继续执行下去。不过,由于操作系统为每个进程分配了独立的内存空间,因此父进程和子进程之间的数据是互相独立的,一个进程对数据的修改不会影响到另一个进程。
在fork()函数返回后,可以通过返回值来判断当前进程是父进程还是子进程。具体而言,fork()函数会返回两次。对于父进程,fork()函数返回新创建子进程的进程ID;而对于子进程,fork()函数返回0。因此,程序可以根据返回值来进行不同的处理。
使用fork()函数可以很方便地实现多进程并发编程。通常情况下,父进程主要负责协调和管理子进程,例如创建子进程、等待子进程结束以及收集子进程的运行结果等;而子进程则负责实际的计算和处理任务。
#include 在计算机科学中,fork() 是一个创建新进程的系统调用。它是操作系统中进程管理的核心功能之一。
具体实现原理如下:
- 当一个进程调用 fork() 系统调用时,操作系统会为其创建一个新的进程,这个新进程称为子进程。子进程是父进程的拷贝,包括代码段、数据段和堆栈等。
- 在创建子进程时,操作系统会复制整个父进程的地址空间,包括代码区、数据区、栈等,但不会复制文件描述符、信号处理器和一些其他的进程特有的属性。
- 子进程与父进程的唯一区别在于它们拥有不同的进程 ID(PID)和父进程 ID(PPID)。
- 在子进程创建完毕后,父进程和子进程开始并行运行。此时它们执行的程序代码相同,但是它们各自维护着自己的寄存器、程序计数器和内存等资源。
总之,fork() 的实现原理就是将父进程的地址空间复制一份给子进程,并为子进程分配新的进程 ID 和父进程 ID。通过这种方式,操作系统能够同时运行多个独立的进程,从而提高了计算机的利用率。
#include 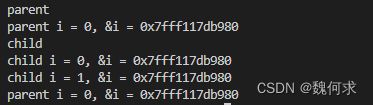
exec函数族
exec() 函数族是一组用于在进程中执行其他程序的函数,在 Linux 系统中,这个函数族包括以下六个函数:
int execl(const char *path, const char *arg0, ... /* (char *)0 */);int execv(const char *path, char *const argv[]);int execle(const char *path, const char *arg0, ... /*, (char *)0, char *const envp[] */);int execve(const char *path, char *const argv[], char *const envp[]);int execlp(const char *file, const char *arg0, ... /* (char *)0 */);int execvp(const char *file, char *const argv[]);
这些函数都可以用于执行一个新的程序文件,每个函数的参数略有不同,但核心作用都是相同的。其中,路径名参数指定了要执行的程序文件所在的路径和文件名;命令行参数数组则包含了要传递给新程序的参数;环境变量参数数组则包含了要设置的新程序的环境变量。
当成功调用这些函数时,当前进程的代码、数据和堆栈都会被新程序所替换,然后开始执行新程序的代码。因此,使用 exec() 函数族时通常需要先调用 fork() 创建一个子进程,然后在子进程中调用 exec() 执行新的程序,以避免当前进程被替换导致程序异常终止。
#include 进程控制
孤儿进程
如果父进程先于子进程退出,则子进程成为孤儿进程,此时将自动被PID为1的进程(即init)收养。
孤儿进程在系统资源方面不会有任何影响,但它们可能会占用一些系统资源,例如文件描述符、内存等等,如果没有及时处理,可能会造成资源浪费和系统性能下降。
通常,我们可以使用信号机制来避免孤儿进程的出现。在父进程中捕获 SIGCHLD 信号并处理子进程的退出状态,这样当子进程退出时,父进程会立即得到通知并对其进行处理。
以下是一个示例代码,演示了如何使用信号机制来避免孤儿进程:
#include 僵尸进程
在 Linux 中,当一个进程退出时,它并不会立即从系统中消失,而是留下一个称为“僵尸进程(Zombie Process)”的状态,这个状态只有在父进程回收子进程资源后才会被清除。如果父进程没有及时回收子进程资源,就会导致僵尸进程一直存在于系统中,并占用系统资源。
通常情况下,当一个子进程结束时,内核会向其父进程发送一个 SIGCHLD 信号,表示子进程已经退出,而父进程可以通过调用 wait() 或 waitpid() 函数来获取子进程的退出状态,并释放相应的资源。如果父进程不处理该信号,或者忽略该信号,那么子进程就会成为一个僵尸进程。
以下是一个示例代码,演示了如何创建一个僵尸进程:
#include 在这个例子中,我们使用 fork() 函数创建了一个子进程,并在该子进程中执行了一段简单的代码。在父进程中,我们没做任何处理就休眠了 20 秒钟后退出。
由于父进程并没有回收子进程资源,因此当子进程结束时,它会成为一个僵尸进程。可以通过执行 ps aux 命令查看系统中的进程状态,发现名为“
要避免产生僵尸进程,通常需要及时回收子进程资源。可以在父进程中捕获 SIGCHLD 信号并调用 wait() 或 waitpid() 函数来等待子进程退出,并释放其资源。
wait和waitpid
wait()和waitpid()` 都是用来等待子进程结束的函数,并且在子进程结束后获取其终止状态。它们的返回值都是子进程的 PID。
wait() 函数的原型如下:
#include 该函数会挂起调用进程,直到有一个子进程退出,或者收到一个信号,其中 status 参数用于存储子进程的退出信息,包括退出状态码和资源使用情况等。如果不需要获取这些信息,可以将 status 设置为 NULL。
waitpid() 函数的原型如下:
#include 该函数与 wait() 类似,但可以指定要等待的子进程。pid 参数为要等待的子进程的 PID,如果设置为 -1,则表示等待任何一个子进程。
options 参数可以用来指定一些附加选项,例如:
- WNOHANG:非阻塞模式,如果没有子进程退出,则立即返回 0。
- WUNTRACED:也等待被暂停的子进程,但不包括已经停止执行的子进程。
- WCONTINUED:等待之前被暂停的子进程继续执行。
waitpid() 函数还可以通过设置 __WALL 标志来等待所有子进程,包括被停止和被恢复执行的子进程。
需要注意的是,在使用 wait() 或 waitpid() 函数时,必须确保调用它们的进程是要等待的子进程的父进程。否则可能会导致获取到错误的子进程信息或者阻塞当前进程。
wait()函数是用来等待子进程结束并获取子进程的退出状态。如果在调用wait()时没有传入参数,则它会等待任何一个子进程结束,并返回该子进程的PID和退出状态信息。如果希望等待特定的子进程,可以将该子进程的PID作为wait()函数的参数传入。
#include #include 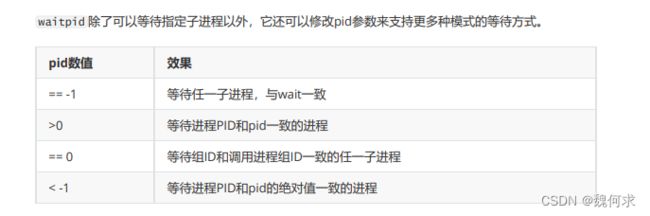
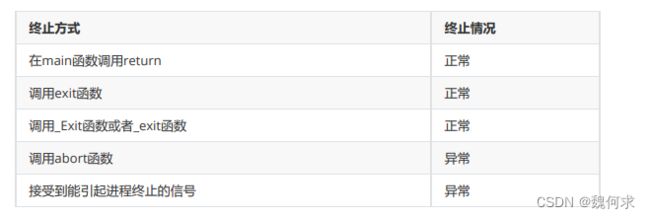
进程终止
守护进程
守护进程(daemon),就是在默默运行在后台的进程,也称作守护进程(daemon)是在操作系统后台运行的一种特殊进程,通常在系统启动时自动启动,并持续运行直到系统关闭。守护进程通常不会与用户直接交互,而是在后台执行某些特定任务,例如网络服务、系统监控、日志记录等。
守护进程的特点包括:
- 不受任何终端控制,无法通过键盘输入来操纵。
- 在系统启动时自动启动,并持续运行直到系统关闭。
- 通常由超级用户或系统管理员启动。
- 可以执行特定的任务,如网络服务、系统监控和日志记录等。
在Unix/Linux系统中,守护进程通常通过fork()函数创建子进程,然后让父进程退出,使子进程成为独立的进程。为了避免守护进程意外退出或死锁,通常需要编写相应的代码进行异常处理和安全性保障。
进程组
进程组(process group)是一组相关联的进程的集合,它们共享同一个进程组ID(PGID)。进程组可以用来协调和控制一组进程的行为。
在UNIX/Linux系统中,每个进程都有一个唯一的进程ID(PID),而进程组则是由一个或多个进程组成的。系统给每个进程组分配了一个唯一的PGID,每个进程也有一个PGID,通常与其所属进程组的PGID相同。进程组中的进程可以通过发送信号来相互通信。
使用setpgid()函数可以将一个进程加入到另一个进程组中,也可以创建新的进程组。常见的进程组管理命令包括:
- ps -o pid,ppid,pgid,args:列出当前所有进程及其父进程ID、进程组ID和命令行参数。
- kill -<信号名> <进程组ID>:向指定进程组中的所有进程发送信号。
- fg :将后台进程转移到前台,并使其成为当前作业。
- bg :将暂停的前台进程转换为后台进程。
进程组的主要作用是方便进程间的通信和协调。例如,在shell中启动的管道操作就是将若干个进程组合成一个管道进程组,使得这些进程之间可以进行数据传输。另外,进程组还可以使用作业控制功能来控制进程的运行状态,如在后台运行、暂停和恢复等。
#include setpgid()函数是用于设置进程组ID(PGID)的系统调用,其原型如下:
```c
int setpgid(pid_t pid, pid_t pgid);
参数pid指定要设置进程组ID的目标进程,参数pgid指定将要设置的进程组ID。如果pid和pgid的值都为0,则使用调用进程的PID作为目标进程,并且将调用进程的PID作为新的进程组ID。
使用setpgid()函数可以将一个进程加入到另一个进程组中,或者创建新的进程组,例如:
#include 在上面的示例中,子进程调用setpgid()函数将自己加入到父进程的进程组中,并打印出进程ID、父进程ID和进程组ID;而父进程则仅打印出自己的进程ID、父进程ID和进程组ID。
守护进程的创建流程
守护进程是一种在后台运行的长期运行的进程,通常被用来提供某种服务或者执行某些特定的任务。下面是一个简单的守护进程创建流程:
- 创建一个子进程,并通过调用setsid()函数使其成为一个新会话的首进程。
- 关闭所有文件描述符(stdin、stdout和stderr除外),这是为了避免意外的输入输出并且释放与父进程的连接。可以通过使用sysconf(_SC_OPEN_MAX)获取最大文件描述符数目,在之后循环关闭。
- 将当前工作目录切换到根目录,这是因为绝大多数守护进程需要脱离任何挂载点的依赖。
- 重设掩码,以屏蔽任何文件权限问题,以防影响守护进程的正常运行。
- 可选地,将标准输入、输出和错误输出重定向到/dev/null或者其他日志文件中,这是为了避免不必要的输出打印,同时保留有意义的错误日志记录。
- 守护进程完成初始化工作,开始执行其正常任务逻辑。
以下是一个简单的守护进程创建示例代码:
#include 这个示例代码中,守护进程创建后,首先通过setsid()函数来创建新的会话,然后关闭所有文件描述符,并将当前目录切换到根目录。接下来,重设掩码,并将stdin、stdout和stderr标准输入输出流重定向到/dev/null文件。最后,启动一个简单的任务循环,以使守护进程一直运行。