第六章--ElasticSearch (ES)--面试题
01 ES 是什么
Elastic是一个基于Lucene的搜索引擎. 提供了具有HTTP Web和无架构JSON文档的分布式,多租户能力的全文搜索引擎.
- Elasticsearch是一款强大的开源搜索引擎,可帮助我们从海量数据中快速找到需要的内容.
- 开源分布式搜索引擎, 可用来实现搜索 日志统计 分析 系统监控等功能
Elasticsearch(负责存储 计算 搜索 分析数据)结合kibana(数据可视化) Logstash Beats(数据抓取),也就是elastic stack(ELK). 被广泛应用日志数据分析,实时监控
02 ES 特点
- 分布式实时文件存储,并将每一个字段都编入索引,使其可以被搜索。分发是实时的,被叫做”Push replication”
- 实时分析的分布式搜索引擎。
- 可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据。
- Elasticsearch 完全支持 Apache Lucene 的接近实时的搜索。
- 处理多租户(multitenancy)不需要特殊配置,而Solr则需要更多的高级设置。
- Elasticsearch 采用 Gateway 的概念,使得完备份更加简单。
- 各节点组成对等的网络结构,某些节点出现故障时会自动分配其他节点代替其进行工作。
03 分词 与 倒排索引 与字典树
分词是给检索用的. ( IK 分词器).
英文,一个单词一个词, 词之间空格分隔
汉字,有各种各样分词器,一个强调效率,一个强调准确率. 比如 ‘使用户放心’,使用,户vs使,用户
倒排索引 举例:从文档内容找文档(通过搜索引擎)
传统的我们的检索是通过文章,逐个遍历找到对应关键词的位置。
而倒排索引,是通过分词策略,形成了词和文章的映射关系表,这种词典+映射表即为倒排索引。
有了倒排索引,就能实现 o(1)时间复杂度 的效率检索文章了,极大的提高了检索效率。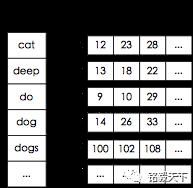
倒排索引,相反于一篇文章包含了哪些词,它从词出发,记载了这个词在哪些文档中出现过,由两部分组成——词典和倒排表。
加分项 :倒排索引的底层实现是基于:FST(Finite State Transducer)数据结构。
lucene 从 4+版本后开始大量使用的数据结构是 FST。FST 有两个优点:
1、空间占用小。通过对词典中单词前缀和后缀的重复利用,压缩了存储空间;
2、查询速度快。O(len(str))的查询时间复杂度。
:::info
**有限状态自动机(Finite State Transducer,FST)**是一种常见的字典数据结构,常用于NLP中。它可以表示一组字符串集合,并提供一种有效的方法来在这些字符串上执行查询操作。
FST 可以用于多种不同的任务,包括词形变化、拼写纠正、文本匹配和词义消歧等。
:::
| 数据结构 | 优缺点 | 相关代码 |
|---|---|---|
| ArrayList…… | 二分法查找,不平衡 | list.add(“”) |
| Map…… | 内存消耗大 | map.put(“”,“”) |
| Trie | 中文领域过于消耗内存 | TrieChineseTokenizer.java |
| Double Array Trie | 相比于Trie,更适合中文,缺点是无法动态增删 | darts-java扩展 |
| AhoCorasickDoubleArrayTrie | 存储大辞典时溢出 | AhoCorasickDoubleArrayTrie |
| Finite State Transducers (FST) | Lucene中大量应用,本文重点说明 | FST.java |
- 针对ArrayList、Map这两个基本数据结构,不做过多介绍,直接跳过。
- 针对Trie这个数据结构,他更适合于英文,并不适合应用于中文环境。
- 中文文本中的字符集非常大,超过了 ASCII 字符集。Trie 数据结构在处理大字符集时,需要存储大量的节点,这会导致空间消耗变得非常大。
- 中文文本中的词汇组合非常灵活。中文中的词汇不像英文那样明确定义,并且同一个词可以有多种不同的组合方式。
- Trie数据结构在中文文本中,由于其空间和时间效率的限制以及中文文本的复杂性,可能不是最佳选择。
- 双数组Trie树是一种基于Trie树的数据结构
- DAT 的静态构建是通过将 Trie 树转换为两个数组实现的。其中一个数组存储 Trie 树中的节点信息,另一个数组则存储节点的孩子节点信息。这种实现方式具有很好的压缩性和查找效率。
- 当需要删除 Trie 树中的一个节点时,需要将该节点从 Trie 树中删除,并且可能需要对其祖先节点进行修改,以确保删除后的 Trie 树仍然是一棵有效的树。因为 DAT 中的数组是静态分配的,因此删除节点和修改数组可能会破坏原始数据结构的完整性,导致无法保证查找的正确性。
- AhoCorasickDoubleArrayTrie
- 在实际的应用中,存储大辞典的话,会出现溢出情况,并且在issues中也有他人出现这种问题。
- 重点实现 FST 数据机构,详见下面代码
- 使用语料库分别加入 AhoCorasickDoubleArrayTrie 和 FST,前者出现溢出情况(400w数据量左右),后者正常使用。
- 可以动态增删关键词
import java.io.Serializable;
import java.util.HashMap;
/**
* FST
*/
public class FST implements Serializable {
private HashMap<Character, FST> transitions = new HashMap<>();
private boolean isFinalState = false;
public void addWord(String word) {
if (word.isEmpty()) {
isFinalState = true;
return;
}
char c = word.charAt(0);
FST nextState = transitions.get(c);
if (nextState == null) {
nextState = new FST();
transitions.put(c, nextState);
}
nextState.addWord(word.substring(1));
}
public boolean isWord(String word) {
if (word.isEmpty()) {
return isFinalState;
}
char c = word.charAt(0);
FST nextState = transitions.get(c);
if (nextState == null) {
return false;
}
return nextState.isWord(word.substring(1));
}
public boolean removeWord(String word) {
if (word.isEmpty()) {
boolean wasFinal = isFinalState;
isFinalState = false;
return wasFinal;
}
char c = word.charAt(0);
FST nextState = transitions.get(c);
if (nextState == null) {
return false;
}
boolean wasRemoved = nextState.removeWord(word.substring(1));
if (nextState.transitions.isEmpty() && !nextState.isFinalState) {
transitions.remove(c);
}
return wasRemoved;
}
}
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.ArrayList;
import java.util.List;
/**
* 工具类与测试方法
*/
public class FSTUtil {
/**
* 最大匹配,并且额外返回了字典在文本中所处的位置。
*
* @param text
* @param dict
* @return
*/
public static List<ValueLocationDTO> maxMatchLocation(String text, FST dict) {
List<ValueLocationDTO> result = new ArrayList<>();
int start = 0;
while (start < text.length()) {
int end = text.length();
while (end > start) {
String substr = text.substring(start, end);
if (dict.isWord(substr)) {
result.add(new ValueLocationDTO(substr, start, end));
start = end;
break;
}
end--;
}
if (end == start) {
start++;
}
}
return result;
}
public static void main(String[] args) throws Exception {
FST dict = new FST();
// 这里从字典表里面把数据取出来,数据来源: https://github.com/wainshine
List<String> names = Files.readAllLines(Paths.get("C:\\Users\\86181\\Desktop\\Chinese_Names_Corpus(120W).txt"));
for (String name : names) {
dict.addWord(name);
}
String text = "试一试分词效果,我得名字叫彭胜文,曾用名是彭胜利";
List<ValueLocationDTO> result = maxMatchLocation(text, dict);
System.out.println(result);
dict.removeWord("彭胜文");
dict.removeWord("彭胜");
String text2 = "试一试分词效果,我得名字叫彭胜文,曾用名是彭胜利";
List<ValueLocationDTO> result2 = maxMatchLocation(text2, dict);
System.out.println(result2);
}
}
public class ValueLocationDTO implements Serializable {
private String text;
private Integer start;
private Integer end;
public ValueLocationDTO(String text, Integer start, Integer end) {
this.text = text;
this.start = start;
this.end = end;
}
}
Trie 的核心思想是空间换时间,利用字符串的公共前缀来降低查询时间的开销以达到提高效率的目的。它有 3 个基本性质:
1、根节点不包含字符,除根节点外每一个节点都只包含一个字符。
2、从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串。
3、每个节点的所有子节点包含的字符都不相同。
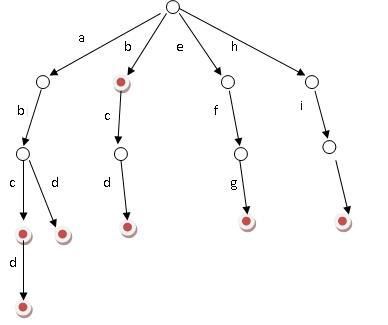
1、可以看到,trie 树每一层的节点数是 26^i 级别的。所以为了节省空间,我们还可以用动态链表,或者用数组来模拟动态。而空间的花费,不会超过单词数×单词长度。
2、实现:对每个结点开一个字母集大小的数组,每个结点挂一个链表,使用左儿子右兄弟表示法记录这棵树;
3、对于中文的字典树,每个节点的子节点用一个哈希表存储,这样就不用浪费太大的空间,而且查询速度上可以保留哈希的复杂度 O(1)。
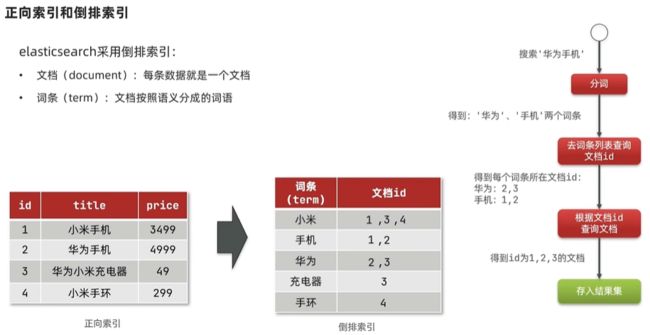
:::info
正向索引 : 基于文档id 建索引,查询词条必须先找到文档,而后判断是否包含词条
倒排索引 : 对文档内容分词,对词条建索引,记录词条所在文档的信息,查询时根据词条查询到文档id 然后获取文档
:::
04 分段存储
分段存储是 Lucene 的思想。ElasticSearch 和 Solr 底层用的都是它。
一个索引文件,拆分为多个子文件,每个子文件是段。修改的数据不影响的段不必做处理。
:::info
关于 Lucene 的 Segement:
1、Lucene 索引是由多个段组成,段本身是一个功能齐全的倒排索引。
2、段是不可变的,允许 Lucene 将新的文档增量地添加到索引中,而不用从头重建索引。
3、对于每一个搜索请求而言,索引中的所有段都会被搜索,并且每个段会消耗CPU 的时钟周、文件句柄和内存。这意味着段的数量越多,搜索性能会越低。
4、为解决这问题,Elasticsearch 会合并小段到一个较大的段,提交新的合并段到磁盘,并删除那些旧的小段。
:::
05 段合并的策略思想
检索过程:
- 查询所有段中满足条件的数据
- 对每个段的结果集合并
所以,定期的对段进行合并是很必要的
策略:将段按大小排列分组,大到一定程度的不参与合并。小的组内合并。整体维持在一个合理的大小范围。当然这个大到底应该是多少,是用户可配置的。这也符合设计的思想。
06 文本相似度 TF-IDF
匹配度的评分 TF-IDF = TF / IDF
① TF = Term Frequency 词频,一个词在这个文档中出现的频率。值越大,说明这文档越匹配,
正向指标。
② IDF = Inverse Document Frequency 反向文档频率,一个词在所有文档中都出现,那么这个词不重要。比如“的、了、我、好”这些词所有文档都出现,对检索毫无帮助。
反向指标。
07 ElasticSearch 写索引的逻辑
ElasticSearch 是集群的 = 主分片 + 副本分片
写索引只能写主分片,然后主分片同步到副本分片上。主分片不是固定的,可能网络原因,Node1 本来是主分片,后来 Node2 经过选举成了主分片;
客户端如何知道哪个是主分片呢? 看下面过程。
- 客户端向某个节点 NodeX 发送写请求
- NodeX 通过文档信息,请求会转发到主分片的节点上
- 主分片处理完,通知到副本分片同步数据,向 Nodex 发送成功信息。
- Nodex 将处理结果返回给客户端。
08 ElasticSearch 集群中搜索数据的过程
- 客户端向集群发送请求,集群随机选择一个 NodeX 处理这次请求。
- Nodex 先计算文档在哪个主分片上,比如是主分片 A,它有三个副本 A1,A2,A3。那么请求会轮询三个副本中的一个完成请求。
- 如果无法确认分片,比如检索的不是一个文档,就遍历所有分片。
补充一点,一个节点的存储量是有限的,于是有了分片的概念。但是分片可能有丢失,于是有了副本的概念。
09 ElasticSearch 深翻页的问题
深翻页:比如我们检索一次,轮询所有分片,汇集结果,根据 TF-IDF 等算法打分,排序后将前 10
条数据返回。用户感觉不错,说我看看下一页。ES 依然是轮询所有分片,汇集结果,根据 TF-IDF
等算法打分,排序后将前 11-20 条数据返回
对用户来说,翻页应该很快啊,但是实际上,第一次检索多复杂,下一次检索就多复杂
解决的话,可以把用户的检索结果,存入 Redis 中 10 分钟。这样分页就很快,超过 10 分钟,用户
不翻页,也就不会翻页了,数据就可以清除了。
10 ElasticSearch 性能优化
1. 批量提交
背景是大量的写操作,每次提交都是一次网络开销。网络永久是优化要考虑的重点。
2. 优化硬盘
索引文件需要落地硬盘,段的思想又带来了更多的小文件,磁盘 IO 是 ES 的性能瓶颈。一个固态硬
盘比普通硬盘好太多
3. 减少副本数量
副本可以保证集群的可用性,但是严重影响了 写索引的效率。写索引时不只完成写入索引,还要完
成索引到副本的同步。ES 不是存储引擎,不要考虑数据丢失,性能更重要。 如果是批量导入,建
议就关闭副本。
11. ElasticSearch 查询优化
设计阶段调优
(1)根据业务增量需求,采取基于日期模板创建索引,通过 roll over API 滚动索引;
(2)使用别名进行索引管理;
(3)每天凌晨定时对索引做 force_merge 操作,以释放空间;
(4)采取冷热分离机制,热数据存储到 SSD,提高检索效率;冷数据定期进行 shrink操作,缩减存储;
(5)采取 curator 进行索引的生命周期管理
(6)仅针对需要分词的字段,合理的设置分词器;
(7)Mapping 阶段充分结合各个字段的属性,是否需要检索、是否需要存储
写入调优 查询调优
(1)禁用 wildcard;
(2)禁用批量 terms(成百上千的场景);
(3)充分利用倒排索引机制,能 keyword 类型尽量 keyword;
(4)数据量大时候,可以先基于时间敲定索引再检索;
(5)设置合理的路由机制。
1、写入前副本数设置为 0;
2、写入前关闭 refresh_interval 设置为-1,禁用刷新机制;
3、写入过程中:采取 bulk 批量写入;
4、写入后恢复副本数和刷新间隔;
5、尽量使用自动生成的 id。
其他调优
部署调优,业务调优等。
部署时,对 Linux 的设置有哪些优化方法:
1、关闭缓存 swap;
2、堆内存设置为:Min(节点内存/2, 32GB);
3、设置最大文件句柄数;
4、线程池+队列大小根据业务需要做调整;
5、磁盘存储 raid 方式——存储有条件使用 RAID10,增加单节点性能以及避免单
节点存储故障。
12. es 的集群架构,索引数据大小,分片
比如:ES 集群架构 13 个节点,索引根据通道不同共 20+索引,根据日期,每日递增 20+,索引:
10 分片,每日递增 1 亿+数据,每个通道每天索引大小控制:150GB 之内。
13. Elasticsearch与关系型数据库对比

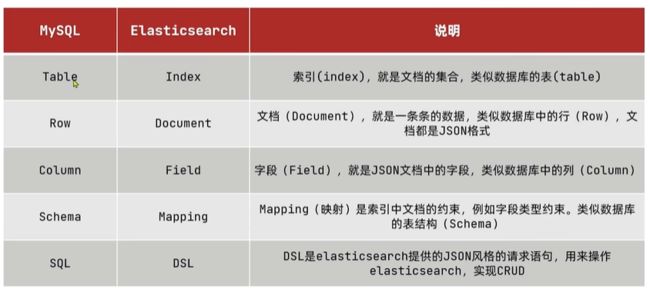
- 一个ES集群可以包含多个索引(数据库),每个索引又包含了很多类型(ES7中已作废),类型中包含了很多文档(行),每个文档又包含了很多字段(列)。
- 传统数据库为特定列增加一个索引,例如B-Tree索引来加速检索。Elasticsearch和Lucene使用一种叫做倒排索引(inverted index)的数据结构来达到相同目的。
- 倒排索引源于实际应用中需要根据属性的值来查找记录。这种索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而称为倒排索引(inverted index)。
- 群集是一个或多个节点(服务器)的集合,它们共同保存您的整个数据,并提供跨所有节点的联合索引和搜索功能。群集由唯一名称标识,默认情况下为“elasticsearch”。此名称很重要,因为如果节点设置为按名称加入群集,则该节点只能是群集的一部分。
- 节点是属于集群一部分的单个服务器。它存储数据并参与群集索引和搜索功能。
- 索引就像关系数据库中的“数据库”。它有一个定义多种类型的映射。索引是逻辑名称空间,映射到一个或多个主分片,并且可以有零个或多个副本分片。 MySQL =>数据库 ElasticSearch=>索引
- 文档类似于关系数据库中的一行。不同之处在于索引中的每个文档可以具有不同的结构(字段),但是对于通用字段应该具有相同的数据类型。 MySQL => Databases => Tables =>Columns / Rows ElasticSearch => Indices => Types =>具有属性的文档
- 类型是索引的逻辑类别/分区,其语义完全取决于用户。
14. ElasticSearch中的分片
- 索引 - 在Elasticsearch中,索引是文档的集合。
- 分片 -因为ES是一个分布式搜索引擎,所以索引通常被分割成分布在多个节点上的被称为分片的元素
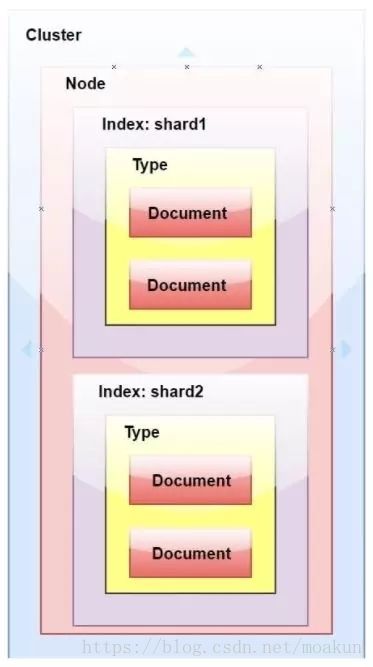
15. ElasticSearch中的副本
一个索引被分解成碎片以便于分发和扩展。副本是分片的副本。一个节点是一个属于一个集群的
ElasticSearch的运行实例。一个集群由一个或多个共享相同集群名称的节点组成。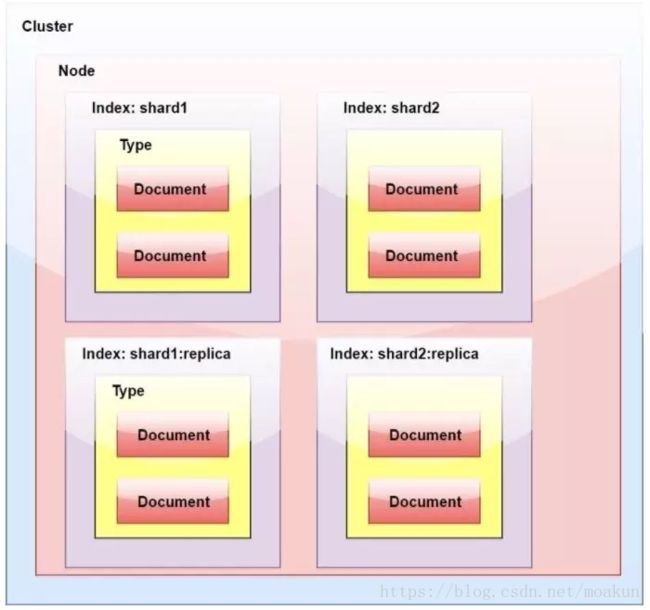
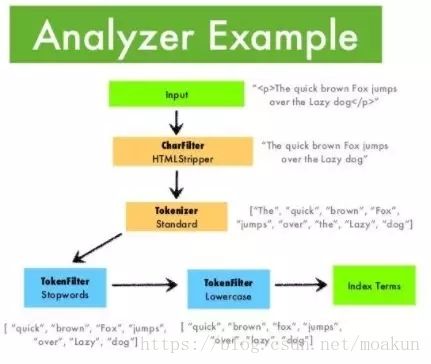
16. ElasticSearch中的分析器 | 编译器 | 过滤器 |
**分析器 **:在ElasticSearch中索引数据时,数据由为索引定义的Analyzer在内部进行转换。 分析器由一个
Tokenizer和零个或多个TokenFilter组成。编译器可以在一个或多个CharFilter之前。分析模块允许
您在逻辑名称下注册分析器,然后可以在映射定义或某些API中引用它们。
Elasticsearch附带了许多可以随时使用的预建分析器。或者,您可以组合内置的字符过滤器,编译
器和过滤器器来创建自定义分析器。
编译器 : 编译器用于将字符串分解为术语或标记流。一个简单的编译器可能会将字符串拆分为任何遇到空格
或标点的地方。Elasticsearch有许多内置标记器,可用于构建自定义分析器
**过滤器: **数据由Tokenizer处理后,在编制索引之前,过滤器会对其进行处理。
17. elasticsearch 了解,说说你们公司 es 的集群架构,索引数据大小,分片有多少,以及一些调优手段
比如:ES 集群架构 13 个节点,索引根据通道不同共 20+索引,根据日期,每日递增 20+,索引:10 分片,每日递增 1 亿+数据,每个通道每天索引大小控制:150GB 之内。
18. elasticsearch 是如何实现 master 选举的
前置前提:
1、只有候选主节点(master:true)的节点才能成为主节点。
2、最小主节点数(min_master_nodes)的目的是防止脑裂。
核心入口为 findMaster,选择主节点成功返回对应 Master,否则返回 null。选举流程大致描述如下:
第一步:确认候选主节点数达标,elasticsearch.yml 设置的值discovery.zen.minimum_master_nodes;
第二步:比较:先判定是否具备 master 资格,具备候选主节点资格的优先返回;
若两节点都为候选主节点,则 id 小的值会主节点。注意这里的 id 为 string 类型。
题外话:获取节点 id 的方法
1GET /_cat/nodes?v&h=ip,port,heapPercent,heapMax,id,name
2ip port heapPercent heapMax id name
1、Elasticsearch 的选主是 ZenDiscovery 模块负责的,主要包含 Ping(节点之间通过这个 RPC 来发现彼此)和 Unicast(单播模块包含一个主机列表以控制哪些节点需要 ping 通)这两部分;
2、对所有可以成为 master 的节点(node.master: true)根据 nodeId 字典排序,每次选举每个节点都把自己所知道节点排一次序,然后选出第一个(第 0 位)节点,暂且认为它是 master 节点。
3、如果对某个节点的投票数达到一定的值(可以成为 master 节点数 n/2+1)并且该节点自己也选举自己,那这个节点就是 master。否则重新选举一直到满足上述条件。
4、补充:master 节点的职责主要包括集群、节点和索引的管理,不负责文档级别的管理;data 节点可以关闭 http 功能*。
:::info
1、当集群 master 候选数量不小于 3 个时,可以通过设置最少投票通过数量(discovery.zen.minimum_master_nodes)超过所有候选节点一半以上来解决脑裂问题;
2、当候选数量为两个时,只能修改为唯一的一个 master 候选,其他作为 data节点,避免脑裂问题。
:::
19. 详细描述一下 Elasticsearch 索引文档的过程
这里的索引文档应该理解为文档写入 ES,创建索引的过程。
文档写入包含:单文档写入和批量 bulk 写入,这里只解释一下:单文档写入流程。官方文档中的这个图。
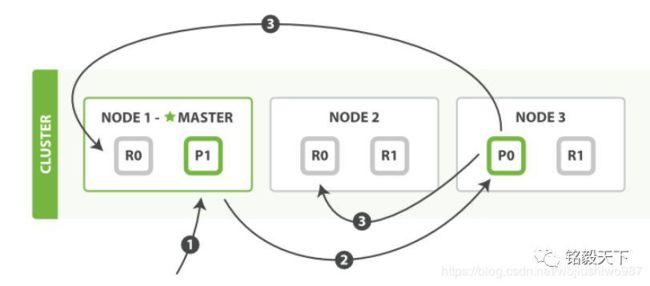
第一步:客户写集群某节点写入数据,发送请求。(如果没有指定路由/协调节点,请求的节点扮演 路由节点 的角色。)
第二步:节点 1 接受到请求后,使用文档_id 来确定文档属于分片 0。请求会被转到另外的节点,假定节点 3。因此分片 0 的主分片分配到节点 3 上。(文档获取分片的过程 : 借助路由算法获取,路由算法就是根据路由和文档 id 计算目标的分片 id 的过程 )
shard = hash(_routing) % (num_of_primary_shards)
shard = hash(document_id) % (num_of_primary_shards)
第三步:节点 3 在主分片上执行写操作,如果成功,则将请求并行转发到节点 1和节点 2 的副本分片上,等待结果返回。所有的副本分片都报告成功,节点 3 将向协调节点(节点 1)报告成功,节点 1 向请求客户端报告写入成功。
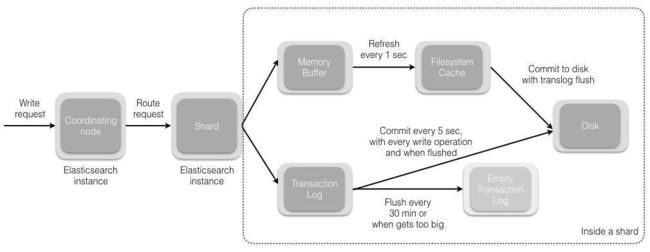
协调节点默认使用文档 ID 参与计算(也支持通过 routing),以便为路由提供合适的分片。
1、当分片所在的节点接收到来自协调节点的请求后,会将请求写入到 Memory Buffer,然后定时(默认是每隔 一 秒)写入到 Filesystem Cache,这个从 Momery Buffer 到 Filesystem Cache 的过程就叫做 refresh;
2、当然在某些情况下,存在 Momery Buffer 和 Filesystem Cache 的数据可能会丢失,ES 是通过 translog 的机制来保证数据的可靠性的。其实现机制是接收到请求后,同时也会写入到 translog 中,当 Filesystem cache 中的数据写入到磁盘中时,才会清除掉,这个过程叫做 flush;
3、在 flush 过程中,内存中的缓冲将被清除,内容被写入一个新段,段的 fsync将创建一个新的提交点,并将内容刷新到磁盘,旧的 translog 将被删除并开始一个新的 translog。
4、flush 触发的时机是定时触发(默认 30 分钟)或者 translog 变得太大(默认为 512M)时;
20 详细描述一下 Elasticsearch 搜索的过程?
搜索拆解为**“query then fetch”** 两个阶段。
query 阶段的目的:定位到位置,但不取。
步骤拆解如下:
1、假设一个索引数据有 5 主+1 副本 共 10 分片,一次请求会命中(主或者副本分片中)的一个。(在初始查询阶段时,查询会广播到索引中每一个分片拷贝(主分片或者副本分片)。 每个分片在本地执行搜索并构建一个匹配文档的大小为 from + size 的优先队列。)
:::info
PS:搜索时候会查询 Filesystem Cache 的,但是有部分数据还在 Memory Buffer,所以搜索是近实时的。
:::
2、每个分片在本地进行查询,结果返回到本地有序的优先队列中。(每个分片返回各自优先队列中 所有文档的 ID 和排序值 给协调节点,它合并这些值到自己的优先队列中来产生一个全局排序后的结果列表。)
3、第 二 步骤的结果发送到协调节点,协调节点产生一个全局的排序列表。
fetch 阶段的目的:取数据。
路由节点获取所有文档,返回给客户端。(协调节点辨别出哪些文档需要被取回并向相关的分片提交多个 GET 请求。每个分片加载并 丰富 文档,如果有需要的话,接着返回文档给协调节点。一旦所有的文档都被取回了,协调节点返回结果给客户端。)
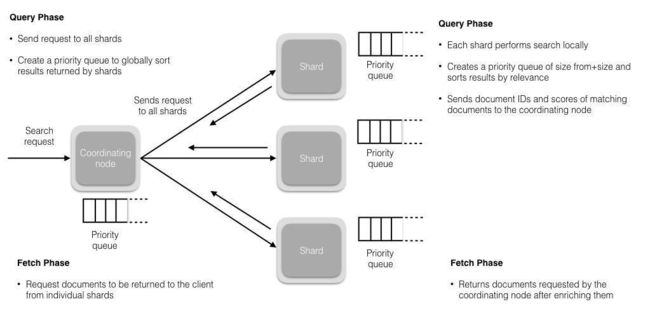
:::info
补充:Query Then Fetch 的搜索类型在文档相关性打分的时候参考的是本分片的数据,这样在文档数量较少的时候可能不够准确,DFS Query Then Fetch 增加了一个预查询的处理,询问 Term 和 Document frequency,这个评分更准确,但是性能会变差。
:::
21 lucence 内部结构是什么?
Lucene 是有索引和搜索的两个过程,包含索引创建,索引,搜索三个要点。可以基于这个脉络展开一些。
22 详细描述一下 Elasticsearch 更新和删除文档的过程。
1、删除和更新都是写操作,但是 Elasticsearch 中的文档是不可变的,因此不能被删除或者改动以展示其变更;
2、磁盘上的每个段都有一个相应的.del 文件。当删除请求发送后,文档并没有真的被删除,而是在.del 文件中被标记为删除。该文档依然能匹配查询,但是会在结果中被过滤掉。当段合并时,在.del 文件中被标记为删除的文档将不会被写入新段。
3、在新的文档被创建时,Elasticsearch 会为该文档指定一个版本号,当执行更新时,旧版本的文档在.del 文件中被标记为删除,新版本的文档被索引到一个新段。旧版本的文档依然能匹配查询,但是会在结果中被过滤掉。
分布式搜索DSL
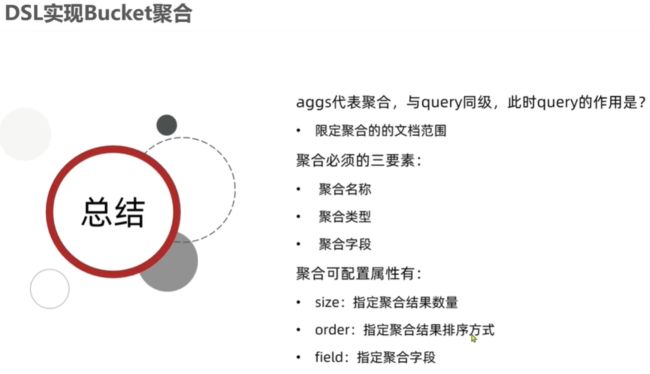
基于JSON的 **DSL (Domain Specific Language)**来定义查询
查所有 match_all
全文检索 match_query multi_match-query
精确查询 ids range term 根据精确词条值查数据,比如数值,日期,布尔等类型字段
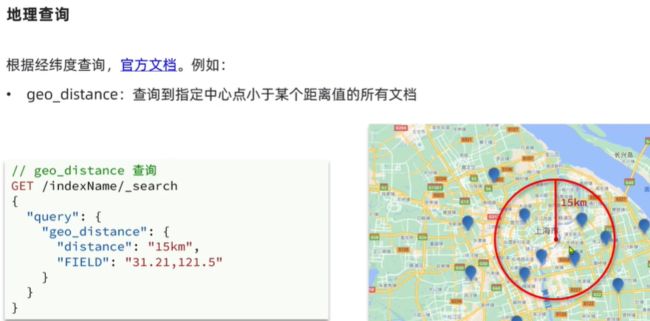
地理geo查询 经纬度 geo_distance geo_bounding_box
复合查询compound查询 bool function_score




MySQL 和 ES 数据同步问题
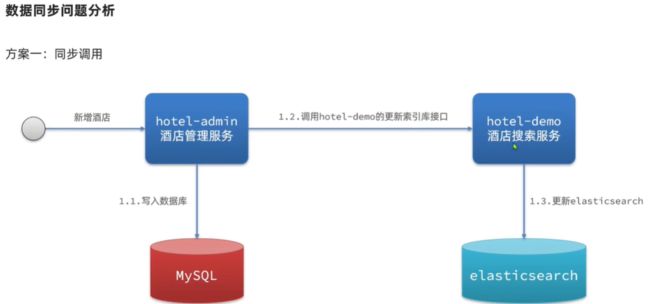
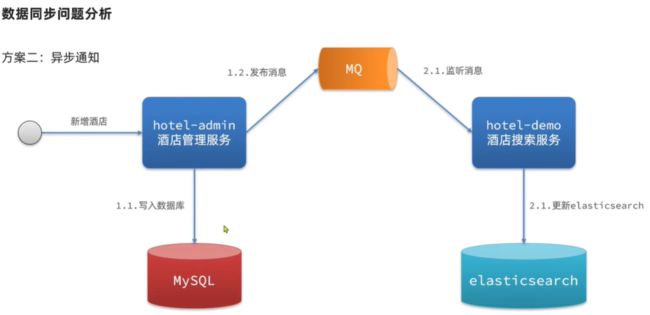
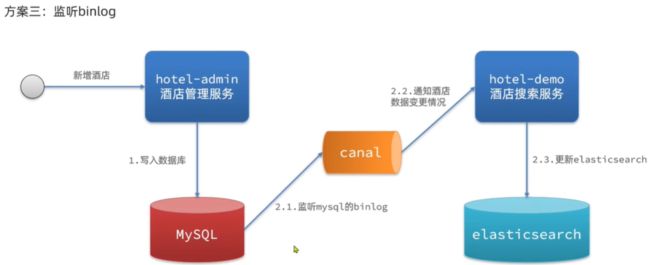
| 分类 | 同步调用 | 异步通知 | 监听binlog |
|---|---|---|---|
| 优点 | 实现简单粗暴 | 低耦合,实现难度一般 | 完全解除服务间耦合 |
| 缺点 | 业务耦合度高 | 依赖mq的可靠性 | 开启binlog增加数据库负担,实现复杂度高 |
ES集群
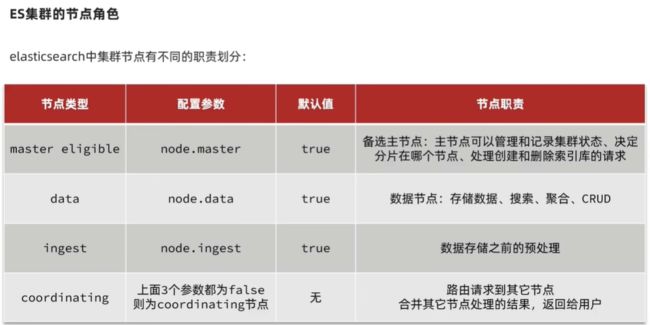

分布式新增如何确定分片
- coordinating node 根据id做hash运算,得到结果对shard 数量取余,余数就是对应的分片
分布式查询:
- 分散阶段 : coordinating node 将查询请求分发给不同分片
- 收集阶段 : 将查询结果汇总到coordinating node, 整理并返回给用户
故障转移 :
- master 宕机后, EligibleMaster选举成为新的主节点;
- master 节点监控分片,节点状态,将故障节点上的分片转移到正常节点,确保数据安全.