【Sql】根据字段分组排序,取其第一条数据
【Sql】根据字段分组排序,取组内第一条数据
- 【一】问题描述
- 【二】解决方案(oracle和mysql都可用)
- 【三】总结
【一】问题描述
(1)问题描述
有时候我们需要对数据进行去重处理,例如查询结果里的文件名有重复,我们希望可以按照创建时间排序,最终结果里每个文件名只取创建时间最近的一个。
(2)有哪些问题
想到去重,可以想到使用distinct或者group by分组。但是这两者有个问题,例如我们查询结果中包含多个目标字段【文件id,文件名,文件所属项目,文件创建时间,文件类型】等等。
distinct是对组合进行去重,必须加在select中和所有目标字段之前,也就是只有当上面的5个字段都重复了,这条数据才算是重复。
group by也是要求select中的字段必须出现在group by中,同样是上面的5个字段都重复了,这条数据才算是重复。
而我们的目标是只根据【文件名】进行分组,在分组中根据文件创建时间进行排序,然后每组中只选取创建时间最近的那条数据,且这条数据是完整的包含上面5个字段。
(3)为什么不在业务代码里进行过滤处理?
因为还有分页查询的功能,所以查询的工作就必须得在sql里实现(就当学习sql了)
【二】解决方案(oracle和mysql都可用)
(1)当前sql
SELECT
T.ID,
R.TASK_ID,
T.CRT_DT_TM,
'RST_TABLE' AS TYPE,
T.FULL_NM AS NAME
FROM
period_script_x_rst_table T
JOIN period_script_revision R ON R.ID = T.PERIOD_SCRIPT_REV_ID
JOIN period_script_info S ON S.ID = R.PERIOD_SCRIPT_ID
WHERE
S.MASTER_REV_ID = T.PERIOD_SCRIPT_REV_ID
查询结果
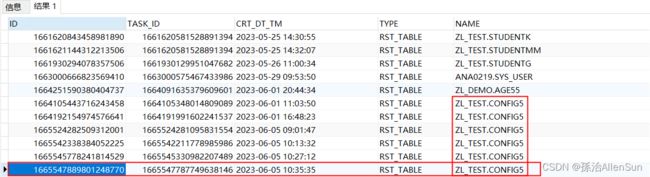
可以看到NAME有很多重复的,我们只想取到时间最近的那一条,同时还不能用group by进行分组
(2)加上分组语句和组内排序
SELECT
T.ID,
R.TASK_ID,
'RST_TABLE' AS TYPE,
T.FULL_NM AS NAME,
rank () over ( partition BY T.FULL_NM ORDER BY T.CRT_DT_TM DESC ) rankNo
FROM
period_script_x_rst_table T
JOIN period_script_revision R ON R.ID = T.PERIOD_SCRIPT_REV_ID
JOIN period_script_info S ON S.ID = R.PERIOD_SCRIPT_ID
WHERE
S.MASTER_REV_ID = T.PERIOD_SCRIPT_REV_ID
查询结果
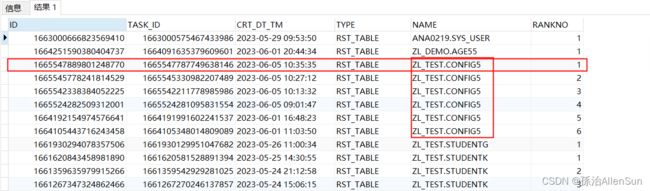
可以看到结果是根据NAME进行了分组,并且进行了组内排序,最后给每条数据加了一个组内排序序号。
(3)加上条件过滤实现组内取第一条目标数据
SELECT
*
FROM
(
SELECT
T.ID,
R.TASK_ID,
T.CRT_DT_TM,
'RST_TABLE' AS TYPE,
T.FULL_NM AS NAME,
rank () over ( partition BY T.FULL_NM ORDER BY T.CRT_DT_TM DESC ) rankNo
FROM
period_script_x_rst_table T
JOIN period_script_revision R ON R.ID = T.PERIOD_SCRIPT_REV_ID
JOIN period_script_info S ON S.ID = R.PERIOD_SCRIPT_ID
WHERE
S.MASTER_REV_ID = T.PERIOD_SCRIPT_REV_ID
) e
WHERE
e.rankNo = 1
查询结果
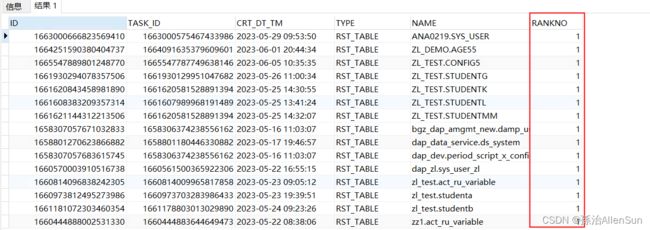
可以看到,根据组内排序序号rankNo=1来过滤,就实现了去重的效果
【三】总结
如果想要实现去重,而distinct和group by都无法满足需求,就可以考虑试试这个方案
rank() over(partition by e.commandid order by e.systemid desc) rankNo (
partition by 根据什么进行分组,
order by 根据什么进行排序,
rank() over() 进行排名
rankNo 别名
)