Spark2.1.0的Standalone模式部署
1.下载并解压spark安装包:spark-2.1.0-bin-hadoop2.7.tgz,配置好每台机器上spark的环境变量
cd /home/hadoop273/spark
tar -zxvf /data/soft/spark/spark-2.1.0-bin-hadoop2.7.tgz -C .
vim ~/.bash_profile
export SPARK_HOME=/home/hadoop273/spark/spark-2.1.0-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin
source .bash_profile2.配置spark
进入到Spark安装目录
cd /home/hadoop273/spark/spark-2.1.0-bin-hadoop2.7进入conf目录并重命名并修改spark-env.sh.template文件
cd conf/
mv spark-env.sh.template spark-env.sh
vim spark-env.sh在该配置文件中添加如下配置
#指定JAVA_HOME位置
export JAVA_HOME=/data/java/jdk1.7.0_79
#指定spark老大Master的IP
export SPARK_MASTER_IP=hadoop1
#指定spark老大Master的端口
export SPARK_MASTER_PORT=7077
#指定可用的CPU内核数量(默认:所有可用,实际使用时没有配置最后这两个参数)
export SPARK_WORKER_CORES=2
#作业可使用的内存容量,默认格式为1000m或者2g(默认:所有RAM去掉给操作系统用的1GB)
export SPARK_WORKER_MEMORY=2g重命名并修改slaves.template文件
mv slaves.template slaves
vim slaves在该文件中添加子节点所在的位置(Worker节点)
hadoop2
hadoop3
hadoop43.将配置好的spark分发到其他节点上
scp -r spark-2.1.0-bin-hadoop2.7/ hadoop273@hadoop2:/home/hadoop273/spark
scp -r spark-2.1.0-bin-hadoop2.7/ hadoop273@hadoop3:/home/hadoop273/spark
scp -r spark-2.1.0-bin-hadoop2.7/ hadoop273@hadoop4:/home/hadoop273/spark4.在hadoop1上启动spark集群
cd /home/hadoop273/spark/spark-2.1.0-bin-hadoop2.7/sbin
./start-all.sh启动成功!Spark集群配置完毕,目前是1个Master,3个Work
启动后执行jps命令,主节点上有Master进程,其他子节点上有Work进行,登录Spark管理界面查看集群状态(主节点):http://hadoop1:8080/

5.启动spark shell
/home/hadoop273/spark/spark-2.1.0-bin-hadoop2.7/bin/spark-shell \
--master spark://hadoop1:7077 \
--executor-memory 1g \
--total-executor-cores 2启动过程中的控制台日志信息如下:
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
16/12/31 09:49:47 WARN SparkContext: Support for Java 7 is deprecated as of Spark 2.0.0
16/12/31 09:49:48 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
16/12/31 09:49:59 WARN ObjectStore: Version information not found in metastore. hive.metastore.schema.verification is not enabled so recording the schema version 1.2.0
16/12/31 09:49:59 WARN ObjectStore: Failed to get database default, returning NoSuchObjectException
16/12/31 09:50:01 WARN ObjectStore: Failed to get database global_temp, returning NoSuchObjectException
Spark context Web UI available at http://192.168.2.1:4040
Spark context available as 'sc' (master = spark://hadoop1:7077, app id = app-20161231094949-0000).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.1.0
/_/
Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.7.0_79)
Type in expressions to have them evaluated.
Type :help for more information.
scala> 注意:
如果启动spark shell时没有指定master地址,但是也可以正常启动spark shell和执行spark shell中的程序,其实是启动了spark的local模式,该模式仅在本机启动一个进程,没有与集群建立联系。
启动spark shell后jps查看进程,可以看到一个SparkSubmit进程
46113 SparkSubmitSpark Shell中已经默认将SparkContext类初始化为对象sc。用户代码如果需要用到,则直接应用sc即可
6.启动hdfs
start-dfs.sh7.在spark-shell中编写wordcount程序
sc.textFile("hdfs://hadoop1:9000/input/words.tsv").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).saveAsTextFile("hdfs://hadoop1:9000/output")执行后我们可以从控制界面上看到如下步骤说明:
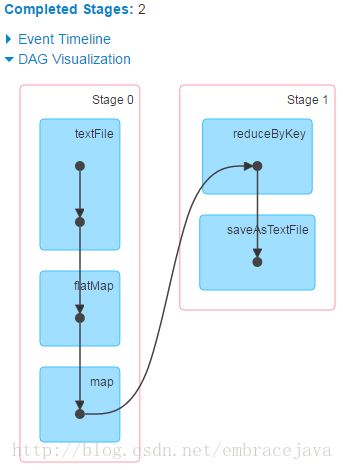
至此,Spark2.1.0的Standalone模式部署完成