【JUC基础】16. Fork Join
1、前言
“分而治之”一直是一个非常有效的处理大量数据的方法。著名的MapReduce也是采取了分而治之的思想。。简单地说,就是如果你要处理 1000 个数据,但是你并不具备处理 1000个数据的能力,那么你可以只处理其中的 10 个,然后分阶段处理 100 次,将 100 次的结进行合成,就是最终想要的对原始 1000 个数据的处理结果。而这就是Fork Join的基本思想。
2、Fork/Join框架
Fork 一词的原始含义是吃饭用的叉子,也有分叉的意思。在 Linux 平台中,方法 fork()用来创建子进程,使得系统进程可以多一个执行分支。在 Java 中也沿用了类似的命名方式。
而 join()方法的含义在之前的章节中已经解释过,这里表示等待。也就是使用 fork()方法后系统多了一个执行分支(线程),所以需要等待这个执行分支执行完毕,才有可能得到最终的结果,因此join()方法就表示等待。

3、JUC中的Fork/Join
在实际使用中,如果毫无顾忌地使用 fork()方法开启线程进行处理,那么很有可能导致系统开启过多的线程而严重影响性能。所以,在JDK 中,给出了一个 ForkJoinPool线程池对于fork()方法并不急着开启线程,而是提交给 ForkJoinPool线程池进行处理,以节省系统资源。
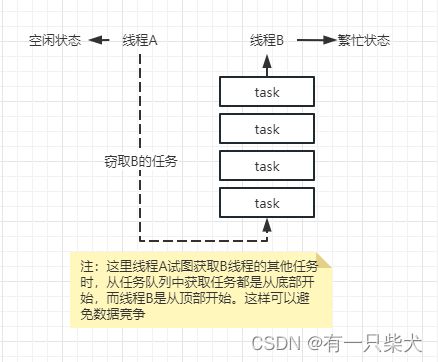
由于线程池的优化,提交的任务和线程数量并不是一对一的关系。在绝大多数情况下一个物理线程实际上是需要处理多个逻辑任务的。因此,每个线程必然需要拥有一个任务队列。因此,在实际执行过程中,可能遇到这么一种情况: 线程 A 已经把自己的任务都执行完了,而线程 B 还有一堆任务等着处理,此时,线程A 就会“帮助”线程 B,从线程 B的任务队列中拿一个任务过来处理,尽可能地达到平衡。也就是所谓的工作窃取。
3.1、实现1累计到1亿
这个是高频面试题,这时候当你回答用for循环去累加的时候,你就已经输了。正儿八经的,你高低说个fork join,面试官还能微微一笑。
下面我们简单写个示例实现这个场景,也更好的理解以下fork join。
public class ForkJoinTest {
public static void main(String[] args) {
long startTime = System.currentTimeMillis();
ForkJoinPool forkJoinPool = new ForkJoinPool();
CountTask task = new CountTask(1, 100000000L);
// 线程池调用方式一
long result = forkJoinPool.invoke(task);
long endTime = System.currentTimeMillis()
System.out.println("Sum: " + result + ", 计算耗时:" + (endTime - startTime) + "ms");
// 线程池调用方式二
// ForkJoinTask forkJoinTask = forkJoinPool.submit(task);
// System.out.println("Sum: " + result + ", 计算耗时:" + (endTime - startTime) + "ms");
}
}
class CountTask extends RecursiveTask {
// 批次数量,当数量达到10000,就继续分解
private static final int THRESHOLD = 10000;
private final long start;
private final long end;
public CountTask(long start, long end) {
this.start = start;
this.end = end;
}
@Override
protected Long compute() {
if (end - start <= THRESHOLD) {
// 如果任务足够小,直接计算结果
long sum = 0;
for (long i = start; i <= end; i++) {
sum += i;
}
return sum;
} else {
// 如果任务较大,将任务拆分为更小的子任务
long mid = (start + end) / 2;
CountTask leftTask = new CountTask(start, mid);
CountTask rightTask = new CountTask(mid + 1, end);
leftTask.fork();
rightTask.fork();
long leftSum = leftTask.join();
long rightSum = rightTask.join();
return leftSum + rightSum;
}
}
} 我们重点看CountTask中的compute()方法。首先我们定义了要计算的规模大小THRESHOLD=10000。意味着我们会把累计1亿(因为我们要从1累加到1亿)个任务,按照10000个分解成子任务。并使用fork()方法提交子任务,最终join()方法等待各个子任务结束,并将结果再次求和。
来看下执行结果:

从代码中,还有几个和平时使用不一样的地方:
- CountTask继承了RecursiveTask
- main中线程池使用了ForkJoinPool
3.2、RecursiveTask
Recursive翻译过来就是递归,RecursiveTask也就是递归任务。没错,fork join的思想其实就是分批递归做同样的事情,所以也不难理解。
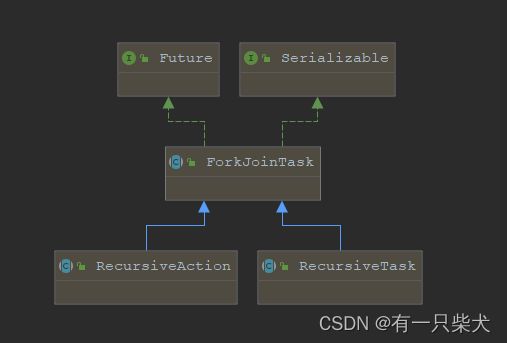
RecursiveTask是一个抽象类,用于支持Fork/Join框架的任务并行执行。他继承自ForkJoinTask。有如下特性:
- 继承关系:RecursiveTask是ForkJoinTask的子类,它继承了ForkJoinTask的一些方法和特性,比如执行任务、取消任务、等待任务完成等。
- 泛型类型:RecursiveTask是一个泛型类,通过类型参数V表示任务执行的结果类型。
- 抽象方法:RecursiveTask是一个抽象类,需要子类实现其唯一的抽象方法compute(),用于定义具体的任务逻辑。
- 任务拆分:RecursiveTask通常用于需要将大任务划分为小任务并以递归的方式执行的场景。在compute()方法中,可以通过判断任务的规模或条件,将任务拆分为更小的子任务,并在子任务中调用fork()方法提交并行执行。
- 任务合并:在子任务完成后,可以通过调用join()方法获取子任务的结果,并进行合并。这样,可以逐级向上合并子任务的结果,直到最终得到整个任务的结果。
- 返回结果:RecursiveTask的compute()方法必须返回一个结果,类型与泛型参数V一致。任务执行完成后,可以通过get()方法或join()方法获取任务的结果。
3.3、RecursiveAction
而RecursiveAction与RecursiveTask相似,RecursiveTask是带有返回值类型;而RecursiveAction是不带有返回值的任务。RecursiveAction不具备上面说到的RecursiveTask泛型的特性,以及无返回结果。

3.4、ForkJoinPool
上面提到的不管是RecursiveTask还是RecursiveAction,都无法独立使用,都是需要配合ForkJoinPool来执行任务,ForkJoinPool是一个线程池,同时也是一个任务调度机制。

主要有如下一些特性,包括我们前面提到的工作窃取也是他:
- 工作窃取算法:ForkJoinPool使用一种称为"工作窃取"(work-stealing)的算法来实现任务的调度和执行。每个线程都有一个自己的工作队列,当一个线程完成自己的任务后,它可以从其他线程的工作队列中窃取任务来执行。这种方式使得任务能够自动地在多个线程之间动态平衡,提高了并行执行的效率。
- 并行度控制:ForkJoinPool允许控制并行度,即同时执行的线程数量。可以通过构造函数或者ForkJoinPool.commonPool()方法来创建一个线程池实例,并指定最大的并行度。默认情况下,ForkJoinPool使用可用处理器的数量作为默认的并行度。
- 分治任务的执行:ForkJoinPool最适合执行可以通过递归的方式拆分成更小子任务的分治任务。通过提交RecursiveTask或RecursiveAction的实例给ForkJoinPool执行,框架会自动将任务拆分为更小的子任务,并提交给线程池中的线程进行执行。
- invoke()方法:ForkJoinPool提供了invoke()方法用于提交一个任务并等待其执行完成。该方法会阻塞直到任务执行完成并返回结果。
- submit()方法:除了invoke()方法,ForkJoinPool还提供了submit()方法用于异步提交一个任务,并返回一个ForkJoinTask的实例,可以通过该实例获取任务的结果。
- 任务的取消和异常处理:ForkJoinPool提供了一些方法用于任务的取消和异常处理,比如cancel()用于取消任务,isCancelled()用于判断任务是否被取消,getException()用于获取任务执行过程中的异常。
注:ForkJoinPool其实就是个CPU密集型的线程池。因此给定的线程个数最好是CPU的核心数+1。
使用ForkJoinPool可以充分利用多核处理器的性能,提高任务执行的效率。
4、进阶实现
到此,fork join基本的思想以及基础介绍也差不多了。但是如果3.1的问题,只回答到fork join可能只能得60分。从上面的代码上看有没有更高效的方法?答案是有的,高低我们现在用的开始JDK8啊,我们知道JDK8里面的stream也相应提供了并行流的计算。
public static void main(String[] args) throws ExecutionException, InterruptedException {
long startTime = System.currentTimeMillis();
long sum = LongStream.rangeClosed(0, 100000000L).parallel().reduce(0, Long::sum);
long endTime = System.currentTimeMillis();
System.out.println("Sum: " + sum + ", 计算耗时:" + (endTime - startTime) + "ms");
}e) + "ms"); }
执行结果:
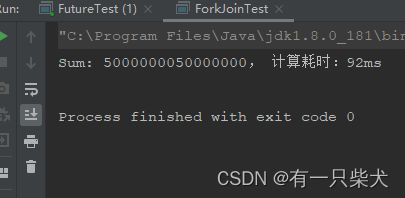
效率高得离谱。这里我们干脆把三种方式都实现一遍对比下结果:
package forkjoin;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveTask;
import java.util.stream.LongStream;
/**
* @author Shamee loop
* @date 2023/6/4
*/
public class ForkJoinTest {
public static void main(String[] args) {
System.out.println("==============传统实现方式================");
long start0 = System.currentTimeMillis();
long sum0 = 0;
for (int i = 0; i <= 1000000000L; i++) {
sum0 += i;
}
long end0 = System.currentTimeMillis();
System.out.println("Sum: " + sum0 + ", 计算耗时:" + (end0 - start0) + "ms");
System.out.println("==============传统实现方式================");
System.out.println();
System.out.println();
System.out.println("==============Fork Join 实现方式================");
long start1 = System.currentTimeMillis();
ForkJoinPool forkJoinPool = new ForkJoinPool();
CountTask task = new CountTask(0, 1000000000L);
long sum1 = forkJoinPool.invoke(task);
long end1 = System.currentTimeMillis();
System.out.println("Sum: " + sum1 + ", 计算耗时:" + (end1 - start1) + "ms");
System.out.println("==============Fork Join 实现方式================");
System.out.println();
System.out.println();
System.out.println("==============JDK8 Stream 实现方式================");
long start2 = System.currentTimeMillis();
long sum2 = LongStream.range(0, 1000000000L).parallel().reduce(0, Long::sum);
long end2 = System.currentTimeMillis();
System.out.println("Sum: " + sum2 + ", 计算耗时:" + (end2 - start2) + "ms");
System.out.println("==============JDK8 Stream 实现方式================");
}
}
class CountTask extends RecursiveTask {
// 批次数量,当数量达到10000,就继续分解
private static final int THRESHOLD = 10000;
private final long start;
private final long end;
public CountTask(long start, long end) {
this.start = start;
this.end = end;
}
@Override
protected Long compute() {
if (end - start <= THRESHOLD) {
// 如果任务足够小,直接计算结果
long sum = 0;
for (long i = start; i <= end; i++) {
sum += i;
}
return sum;
} else {
// 如果任务较大,将任务拆分为更小的子任务
long mid = (start + end) / 2;
CountTask leftTask = new CountTask(start, mid);
CountTask rightTask = new CountTask(mid + 1, end);
leftTask.fork();
rightTask.fork();
long leftSum = leftTask.join();
long rightSum = rightTask.join();
return leftSum + rightSum;
}
}
}
执行结果:
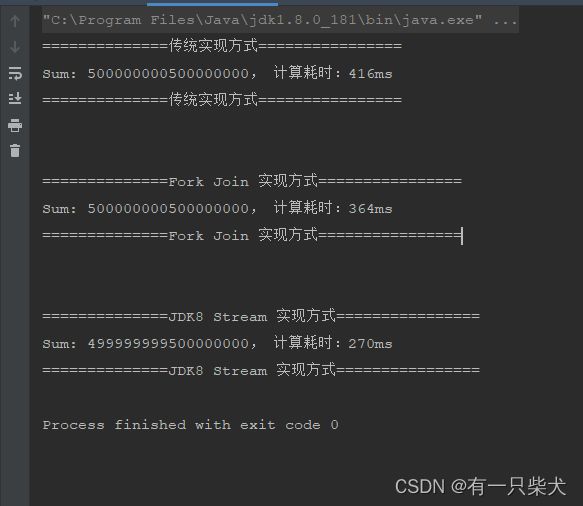
5、小结
在使用 Fork/Join 框架时需要注意: 如果任务的划分层次很多,一直得不到返回,可能出现两种情况。第一,系统内的线程数量越积越多,导致性能严重下降。第二.,医的调用层次变多,最终导致栈溢出。不同版本的 JDK 内部实现机制可能有差异,从而导其表现不同。
此外,ForkJoin 线程池使用一个无锁的栈来管理空闲线程。如果一个工作线程暂时取不到可用的任务,则可能会被挂起,挂起的线程将会被压入由线程池维护的栈中。待将来有任务可用时,再从栈中唤醒这些线程。