OpenMMLab-AI实战营第二期-课程笔记-Class 2:人体姿态估计与MMpose
Class 2:人体姿态估计与MMpose
文章目录
- Class 2:人体姿态估计与MMpose
-
- **人体姿态估计概述**
-
- **what?**
- **下游任务**
- **2D 姿态估计**
-
- **主流算法**
-
- **基于回归坐标的方法**
- **基于热图(heatmap)的方法**
- **多人姿态估计**
- **基于回归的自顶向下方法**
-
- DeepPose
- RLE
- **基于热力图的自顶向下方法**
- **自底向上方法**
-
- SPM
- SPR
- **基于Transformer的方法**
-
- PRTP
- TokenPose
- **3D 姿态估计**
-
- 思路1:直接预测
- 思路2:利用视频信息
- 评估指标
-
- PCP:
- PDJ
- PCK
- 总结
主讲人:卢策吾 上海交通大学电院计算机系教授、博士生导师
课程地址:人体关键点检测与MMPose_哔哩哔哩_bilibili
MMPose主页:https://github.com/open-mmlab/mmpose
人体姿态估计概述
what?
人体姿态估计(Human Pose Estimation)是计算机视觉领域中的一个重要研究方向,也是计算机理解人类动作、行为必不可少的一步,人体姿态估计是指通过计算机算法在图像或视频中定位人体关键点,目前被广泛应用于动作检测、虚拟现实、人机交互、视频监控等诸多领域。
下游任务
- 行为识别:PoseC3D:基于人体姿态识别行为动作
- GC动画
- 人机交互
- 动物行为分析
最有趣:做cg动画,现在有很多工作是能够通过你的表情姿态,来驱动一个动画做很多有趣的东西

2D 姿态估计
2D Human Pose Estimation (以下简称 2D HPE) 旨在从图像或者视频中预测人体关节点(或称关键点,比如头,左手,右脚等)的二维空间位置坐标。2D HPE 的应用场景非常广泛,包括动作识别,动画生成,增强现实等。传统的 2D HPE 算法,设计手工特征提取图像信息,从而进行关键点的检测。近年来随着深度学习的快速发展,基于深度学习的 2D HPE 算法取得了重大突破,算法精度得到了大幅提升。
主流算法
基于回归坐标的方法
早期一些深度学习方法用神经网络直接预测人体关键点的 2D 坐标 。

DeepPose 是这类方法的经典代表。DeepPose 采用级联的神经网络来预测人体各个关键点的相对坐标。每一个阶段都拿上一阶段的输出坐标作为输入,并进一步预测更为准确的坐标位置。最终,将预测得到的归一化的相对坐标转换为绝对坐标。
直接回归坐标的方法思路直接,可以直接获得关键点位置,往往有更快的预测速度。然而,由于人体姿态的自由度很大,直接预测坐标的建模方式对神经网络的预测并不友好,预测精度受到了一定制约。
基于热图(heatmap)的方法
近些年,基于热图(heatmap)的人体姿态估计方法成为了主流。基于热图的方法在每个位置预测一个分数,来表征该位置属于关键点的置信度。根据预测的热图,进一步提取关键点的坐标位置。基于热图的方法更好地保留了空间位置信息,更符合卷积神经网络(Convolutional Neural Network, CNN)的设计特性,从而取得了更好的预测精度。
模型预测热力图比直接回归坐标相对容易,模型精度相对更高,因此主流算法更多基于热力图 但预测热力图的计算消耗大于直接回归.
算法流程:

多人姿态估计
当前主流的 2D HPE 方法主要可以分为自底向上(bottom up)和自顶向下(top down)两种方式。自底向上的方法同时预测图片中的所有关键点,然后将不同类型的关键点组合成人体。自顶向下的方法首先检测出输入图片中的一个或者多个人,然后对于每个个体单独预测其关键点。
自底向上方法的推断时间不随人数的增加而上升,而自顶向下的方法对于不同尺寸的人体更加鲁棒。
基于回归的自顶向下方法
DeepPose

优势:
- 回归模型理论上可以达到㱙限精度,热力图方法的精度受限于特征图的空间分辨率
- 回归模型不需要维持高分辨率特征图,计算层面更高效,相比之下,热力图方法需要计算和存储高分 辨率的热力图和特征图,计算成本更高
劣势:
- 图像到关键点坐标的映射高度非线性,导致回归坐标比回归热力图更难,回归方法的精度也弱于热力 图方法,因此 DeepPose 提出之后的很长一段时间内,2D 关键点预测算法主要基于热力图
RLE
RLE整体设计 :
-
RLE 的目标是建模关键点位置的概率分布,即给定图像 I ,给出每个关键点 x 的位置分布 P Θ ( x ∣ I ) P_{\Theta}(x \mid I) PΘ(x∣I) 可以基于标准化流构建该分布,但 RLE 算法还引入了两个技巧以降低模型拟合真实分布的难度:
-
重参数化.
为降低建模分布的难度,假设所有关键点的分布属于同一个位置尺度族,即所有分布由某个零均值的 基础分布通过平移缩放得来。基于这个假设,让标准化流拟合该基础分布 x ˉ \bar{x} xˉ ,卷积网络预测平移缩放参 μ ^ \widehat{\mu} μ 和 σ ^ \hat{\sigma} σ^
推理阶段,将卷积网络预测的平移参数 μ ^ \widehat{\mu} μ 作为 关键点的预测结果,不需要推理标准化流,保证计算高效性。 -
残差似然函数
借鉴残差网络的思路,进一步假设 x ˉ \bar{x} xˉ 的概率密度为标准高斯分布 Q ( x ˉ ) Q(\bar{x}) Q(xˉ) 与一个变形分布 G ϕ ( x ˉ ) G_{\phi}(\bar{x}) Gϕ(xˉ) 之积(或对数概率密度之和),如果 Q ( x ˉ ) Q(\bar{x}) Q(xˉ) 已经可以很好拟合数据,变形分布的对数退化为,让标准化流拟合该变形分布可以进一步降低模型训练的难度
-
基于热力图的自顶向下方法

e.g. CPM(Convolutional Pose Machines) 利用序列化的卷积神经网络来学习纹理信息和空间信息,实现 2D 人体姿态估计。CPM 通过设计多阶段的网络结构逐渐扩大网络的感受野,获取远距离的结构关系。每一阶段融合空间信息,纹理信息和中心约束来得到更为准确的热图预测。
HRNet 针对人体姿态估计设计了一个高效的网络结构。不同于以往方法利用低分辨率的特征预测高分辨率的热图,HRNet 设计了多个不同分辨率的平行分支。高分辨率特征始终被保持,并且不同尺度的特征能够相互融合。这种设计结合局部纹理特征和全局语义信息,实现了更加准确和鲁棒的姿态预测。
自底向上方法
Step 1. 使用关键点模型 检测出所有人体关键点
Step 2. 基于位置关系或其他辅助信息将关键点组合成不同的人
SPM
SPM首次提出了人体姿态估计的单阶段解决方案,在取得速度优势的同时,也取得了不逊色于二阶段方 法的检测率。并且该方法可以直接从2D图像扩展到3D图像的人体姿态估计。
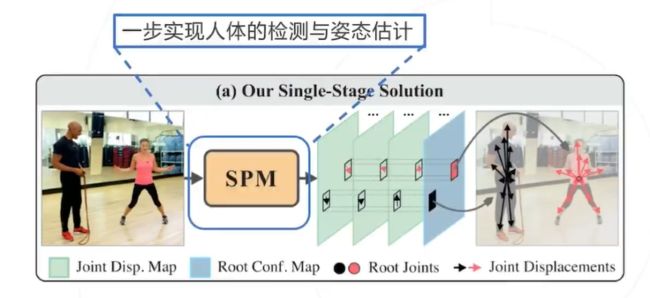
SPR
为了统一人体实例和身体关节的位置信息,为多人姿势估计提供单阶段解决方案,SPR引入了一个辅助 关节,即根关节以表示人员实例位置,它是唯一标识关节。

基于Transformer的方法
PRTP
人体姿态估计和物体检测有一定相似性,都涉及对图像内容的定位 在 DETR 中 query 通过注意力机制逐渐聚焦到特定物体上 姿态估计可模仿 DETR:让 query 逐渐聚焦到特定人体关键点上.

TokenPose
将视觉 token 和 关键点 token 一起送入 encoder 可以同时从图像中学习外观视觉表现和关键点间的 约束关系
分类模型 ViT 也使用类似方法,将一个分类 token 和visual token 一起做自注意力

3D 姿态估计
3D Human Pose Estimation(以下简称 3D HPE )的目标是在三维空间中估计人体关键点的位置。3D HPE 的应用非常广泛,包括人机交互、运动分析、康复训练等,它也可以为其他计算机视觉任务(例如行为识别)提供 skeleton 等方面的信息。关于人体的表示一般有两种方式:第一种以骨架的形式表示人体姿态,由一系列的人体关键点和关键点之间的连线构成;另一种是参数化的人体模型(如 SMPL ),以 mesh 形式表示人体姿态和体型。
思路1:直接预测
直接基于从 2D 图像回归 3D 坐标,但 2D 图像不包含深度,这是一个病态问题 实际上隐式借助了语义特征或人体的刚性实现了 3D 姿态的推理。

这类方法不依赖 2D HPE,直接从图像回归得到 3D 关键点坐标。代表作 C2F-Vol 借鉴了 2D HPE 中的 Hourglass 网络结构,并以 3D Heatmap 的形式表示 3D pose。为了降低三维数据带来的巨大存储消耗,采用了在 depth 维度上逐渐提升分辨率的方法。
思路2:利用视频信息
基于视频的方法就是在以上两类方法的基础上引入时间维度上的信息。相邻帧提供的上下文信息可以帮助我们更好地预测当前帧的姿态。对于遮挡情况,也可以根据前后几帧的姿态做一些合理推测。另外,由于在一段视频中同一个人的骨骼长度是不变的,因此这类方法通常会引入骨骼长度一致性的约束限制,有助于输出更加稳定的 3D pose。
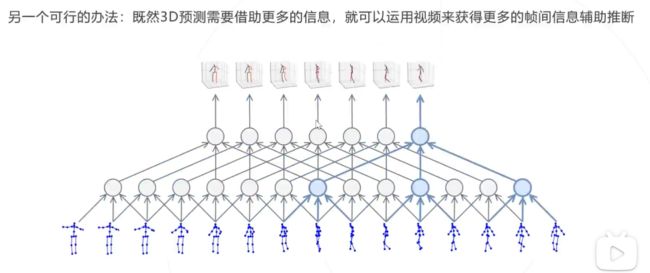
VideoPose3D 以 2D pose 序列作为输入,利用 Temporal Convolutional Network (TCN) 处理序列信息并输出 3D pose。TCN 的本质是在时间域上的卷积,它相对于 RNN 的最大优势在于能够并行处理多个序列,且 TCN 的计算复杂度较低,模型参数量较少。在 VideoPose3D 中,作者进一步利用 dilated convolution 扩大 TCN 的感受野。具体的网络结构与 SimpleBaseline3D 类似,采用了残差连接的全卷积网络。除此以外,VideoPose3D 还包含了一种半监督的训练方法,主要思路是添加一个轨迹预测模型用于预测根关节的绝对坐标,将相机坐标系下绝对的 3D pose 投影回 2D 平面,从而引入重投影损失。半监督方法在 3D label 有限的情况下能够更好地提升精度。
评估指标
PCP:
P C P 以肢体的检出率作为评价指标
考虑每个人的左右大臂、小臂、大腿、小腿共计 4 × 2 = 8 4 \times 2=8 4×2=8 个肢体
如果两个预测关节位置和真实肢体关节位置之间的距离小于等于肢体长度的一半,则认为肢体已检测到 且是正确的部分。
PDJ
PDJ 以关节点的位置精度作为评价指标
通常考虑头、肩、时、腕、臀、膝、踝几个关键点,如果预测关节和真实关节之间的距离在躯干直径的 某个比例范围内,则认为检测到检测到了关节。并且可以通过改变该比例,可以获得不同程度的定位精 度的检测率。
PCK
PCK以关键点的检测精度作为评价指标
如果预测关节和真实关节之间的距离在某个阈值(可变)内,则认为检测到的关键点是正确的。在2D 与3D (PCK3D) 任务中均可使用。
PCK阈值通常是根据对象的比例设置的,对象的比例封闭在边界框内。例如,阈值可以是: [email protected] 阈值=头部骨骼链接的 50 50 % ;[email protected] 50阈值=0.2*躯干直径;有时也以 150 m m 150 \mathrm{~mm} 150 mm 作为阈值
PCK based mAP以关键点相似度 (OKS) 作为评价指标计算mAP,OKS是MS COCO竞赛指定的关键点 评价指标
总结
