spring如何解决循环依赖
一、代码
@Component
public class BService {
@Autowired
private AService aService;
public void work(){
System.out.println("bservice的工作");
}
}
@Component
public class AService {
@Autowired
private BService bService;
public void work(){
System.out.println("aservice的工作");
}
}
二、AService 的bean创建过程
- spring调用AService的无参构造方法实例化得到AService类得一个aService对象。
- spring通过依赖注入填充aService中的bservice属性。(先从单例池去找如果没有就创建BService
一直循环下去。。。。。
) - 填充其他属性
- 其他步骤
- 加入单例池
所以产生循环依赖。
三、spring三级缓存
Spring三级缓存指的是Spring框架在管理Bean时所维护的三级缓存机制,其作用是提高Bean的创建效率和管理效率。
1、singletonObjects:该缓存中缓存的是完全创建好的单例Bean,即在第二级缓存(factoryBeanInstanceCache)中返回了完整的Bean实例。
2、earlySingletonObjects:该缓存中缓存的是未完全创建好的单例Bean实例(即只完成了实例化和初始化部分),主要为了解决循环依赖问题,即当一个Bean A依赖于Bean B,而Bean B又依赖于Bean A时,通过从earlySingletonObjects缓存中获取到还未完成创建的Bean A实例,并将其注入到Bean B中,使得依赖注入操作可以顺利完成。
3、singletonFactories:该缓存中缓存的是创建Bean的工厂,即BeanFactory的getObject()方法返回的Bean,也即Bean的创建过程。主要针对的是动态代理类型的对象。
四、三级缓存的使用过程
1、获取singletonObjects缓存中的Bean实例,如果存在则直接返回Bean对象,否则继续操作;
2、获取earlySingletonObjects缓存中的Bean实例,如果存在则返回Bean对象,否则继续操作。
3、获取singletonFactories缓存中的Bean实例(即Bean的创建工厂),如果存在则通过工厂方法创建Bean实例并保存到earlySingletonObjects缓存中、从singletonFactories缓存中移除并返回Bean实例,否则继续操作。
当一个Bean被创建完成并添加到singletonObjects缓存中后,其它依赖该Bean的Bean便可以通过getBean()方法直接获取到完整的Bean实例,并完成依赖注入操作。
五、解决循环依赖
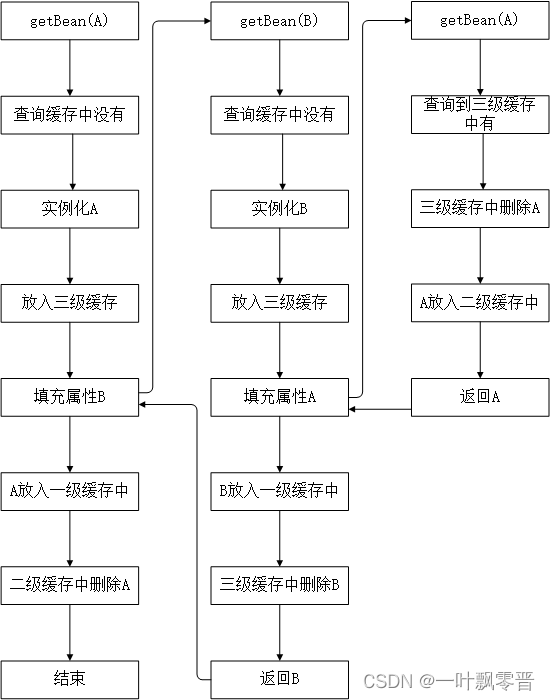
注意:
spring的依赖注入方式。分为setter注入和构造器注入。spring可以解决setter类型的构造注入,构造器形式的注入解决不掉。
spring的生命周期可以概括为四个大阶段,实例化,属性赋值,初始化,销毁。
五、如果只有一级缓存能否解决依赖的问题
理论上可以,但是实际操作的时候会有问题,一级缓存和二级缓存的区分点,一个存放的是成品对象,一个存放的是半成品对象,当只有一个map的时候就意味着半成品对象和成品对象放到一起,半成品对象不能够直接暴露给外部使用,因为会有空指针异常,所以如果非要用一个map存储就要添加一个标识,来标注是半成品对象还是成品对象。如果按照这样方式设计代码,会很不优雅,所以可以直接用两个map来解决.不需要一个。
六、如果只有二级级缓存能否解决依赖的问题。
理论上可以,但是前提是在创建对象中不能有代理对象。
七、为什么必须要有三级缓存来解决循环依赖问题?为什么三级缓存可以解决带有代理对象的循环依赖问题
1、同一个容器中能否出现同名的不同对象。
不能
2、如果出现了同名的不同对象,应该怎么办。 比如刚开始创建出原始对象,后续创建出了代理对象。
如果在创建过程中出现了同名的不同对象,那么后面创建的对象会覆盖前面所创建的对象。
3、为什么要使用lambda表达式这样的方式,或者为什么要加入三级缓存呢?
对象的属性的赋值是在 populateBean方法完成的
代理对象的创建是在BeanPostProcessor的后置处理方法里面完成的。
public interface BeanPostProcessor {
// 注意这个方法名称关键的是before这个单词
Object postProcessBeforeInitialization(Object bean, String beanName)
throws BeansException;
// 注意这个方法名称关键的是after这个单词
Object postProcessAfterInitialization(Object bean, String beanName)
throws BeansException;
}
populateBean()要比BeanPostProcessor的后置方法先执行也就是说
在进行对象属性赋值的时候,代理对象还没有创建出来,那么属性的赋值只能是原始对象而在后续的步骤中又创建出了代理对象,此时的代理对象会有赋值的过程吗?不会,所以会出现一个错误
this means that said other beans do not use the final version of the bean
就是说赋值是原始对象,而最终留下来的是代理对象,所以导致没有使用最终版本的bean对象。
如何解决?
将代理对象的创建过程提前执行,也就是说在进行对象赋值的时候必须要唯一性的确定出到底是原始对象还是代理对象,这个方法是在getEarlyBeanReference方法里执行的,而getEarlyBeanReference是在populateBean方法的中调用的。
为什么使用lambda表达式
lambda相当于延迟执行,因为此方法次方法并不会在方法的调用的时候立即执行,而是在对象必须要进行属性赋值的那一刻执行,也就是说在对象赋值的的那一刻确定出了最终的bean对象。
总结:使用三级缓存本质上是为了解决aop代理问题。当一个对象需要被代理的时候,在整个整个bean创建过程中,包含两个对象,一个是普通对象,一个是代理生成代理对象,bean默认都是单例的,那么在整个过程中三级缓存在getEarlyBeanReference进行了一个判断。如果不需要代理直接放回普通对象,如果需要代理就用代理对象替换。保证了bean的全局唯一性。所以能够解决aop代理问题。