【Linux】线程分离和线程互斥
终于到线程互斥了~
文章目录
- 前言
- 一、线程分离
- 如何理解线程库和线程ID
- 二、线程互斥
- 总结
前言
在上一篇文章中我们学习了线程控制,比如创建一个线程,取消一个线程以及等待线程,这篇文章我们讲两个非常重要的概念,一个是线程分离,另一个是线程互斥
一、线程分离

下面我们先写一个测试代码,让程序跑起来然后我们再测试线程分离接口:
#include
#include
#include
#include
#include
#include
using namespace std;
void *threadRoutine(void* args)
{
string name = static_cast(args);
int cnt = 5;
while (cnt)
{
cout< 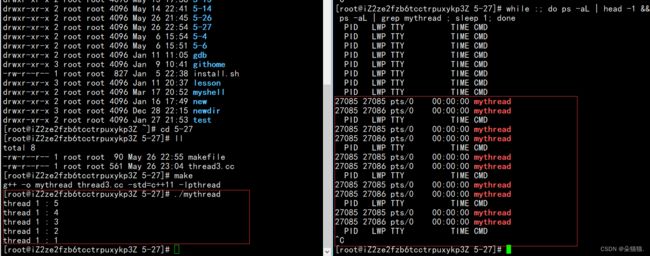
可以看到线程运行后5秒都退出了,下面下面我们加入分离接口:

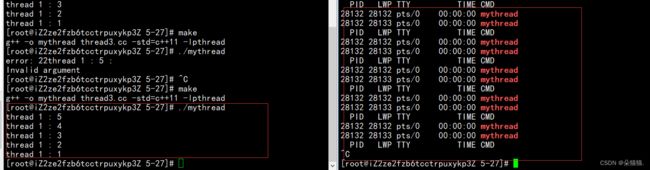
这段代码的意思是我们刚创建一个新线程就将新线程分离了,而我们将线程分离后如果还是正常的去join线程是会出错的,下面我们运行起来看看:
 果然出错了,Invalid argument说明我们的参数是错误的,这是因为我们刚刚pthread_detach的参数是不合法的,所以:一个线程被设置为分离状态后,是不需要join的!
果然出错了,Invalid argument说明我们的参数是错误的,这是因为我们刚刚pthread_detach的参数是不合法的,所以:一个线程被设置为分离状态后,是不需要join的!
那么如果我们让这个线程自己分离自己呢?
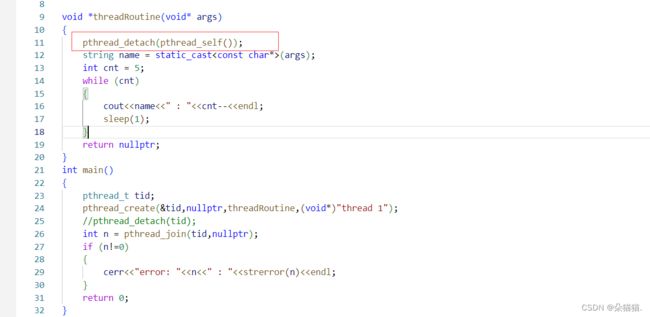
 通过运行我们发现并没有什么问题,我们让主线程sleep(1)再看一下:
通过运行我们发现并没有什么问题,我们让主线程sleep(1)再看一下:
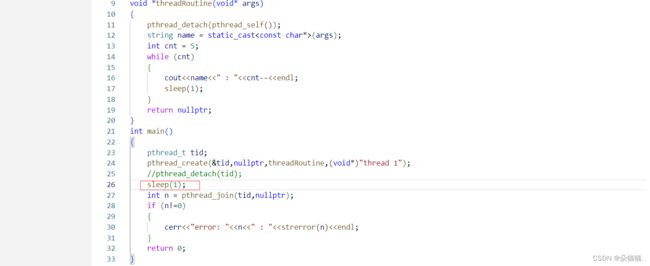
 可以看到又报参数错误了,出现这种错误的原因是:我们调度哪个线程是不确定的,像刚才的代码如果我们直接调度主线程导致新线程一行代码也没跑直接主线程就join了,就又会像之前那样出现参数错误。
可以看到又报参数错误了,出现这种错误的原因是:我们调度哪个线程是不确定的,像刚才的代码如果我们直接调度主线程导致新线程一行代码也没跑直接主线程就join了,就又会像之前那样出现参数错误。
下面我们总结一下线程分离:当我们想join一个线程的时候那就不要进行分离,当我们不想去join一个线程那就直接将这个线程分离即可。
如何理解线程库和线程ID:
线程库:

首先我们学动静态库的时候知道,库是在磁盘中存放的,从磁盘映射到了物理内存然后经过页表的转化映射到进程地址空间的共享区当中,又因为我们的线程是共享进程的进程地址空间的,所以我们的线程是可以随时随地访问共享区中的库的。
那么线程库是如何管理线程的呢?先描述再组织。先给线程创建类似的管理线程的TCB(类似于PCB),下面我们看一张图:
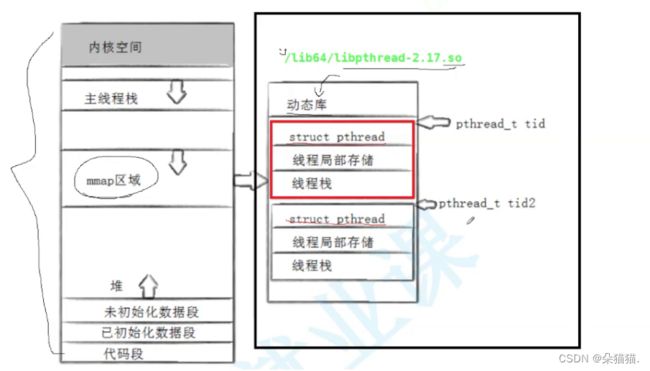
在这张图中,mmap区域就是我们的共享区,右边的动态库等信息就是我们的线程库,里面有管理线程的结构体等,而要找我们的线程ID该怎么去找呢?我们可以看到pthread_t tid的小箭头指向结构体,实际上pthread_t 就是一个地址数据,用来标识线程相关属性集合的起始地址。所以我们之前打印线程id的时候是很长的数据,为什么长呢因为那是地址!!下面我们将代码修改一下演示出id:
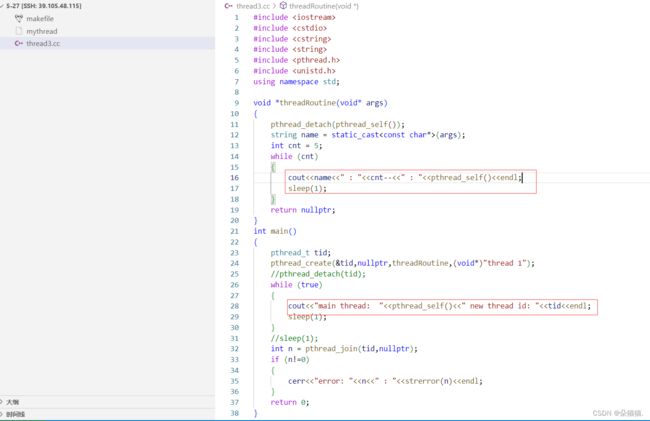
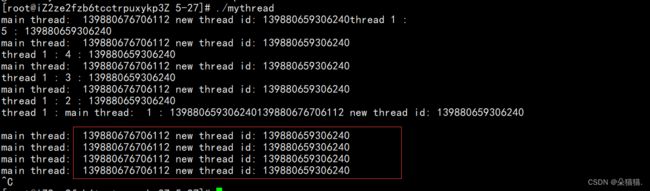
可以看到确实打印出来的ID是很长,下面我们将这个ID转换为16进制的地址:
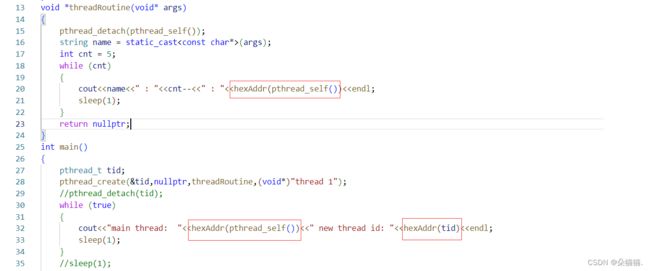
string hexAddr(pthread_t tid)
{
char buffer[64];
snprintf(buffer,sizeof(buffer),"0x%x",tid);
return buffer;
}
下面我们运行起来:

这一次我们可以看到地址变的正常了。我们在上面线程的图中可以看到线程局部存储和线程栈,其实学过线程的都知道线程是有自己的私有栈的,只不过不知道这个栈在哪里,从图中我们可以看到这个栈是在线程自己的地址当中,每个线程有struct,线程局部存储和线程栈,通过地址找到这些内容。
总结:线程库的作用是给用户提供操作线程的接口,在我们创建线程的时候会在线程库里面给我们创建一个描述线程相关的struct,然后还会创建一个轻量级进程,线程结构体里会包含线程自己的栈结构,局部存储等信息。线程的ID就是描述线程结构体TCB的起始地址,每个线程都有自己的栈在库当中存放。
下面我们编写代码验证一下每个线程中的私有栈:
int main()
{
pthread_t t1,t2,t3;
pthread_create(&t1,nullptr,threadRoutine,(void*)"thread 1");
pthread_create(&t2,nullptr,threadRoutine,(void*)"thread 2");
pthread_create(&t3,nullptr,threadRoutine,(void*)"thread 3");
pthread_join(t1,nullptr);
pthread_join(t2,nullptr);
pthread_join(t3,nullptr);
return 0;
}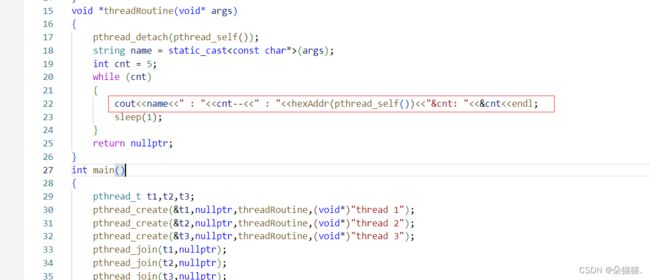
我们开3个线程,然后每个线程进入routine函数的时候都打印一下cnt这个变量的地址,如果不一样则说明他们有自己独立的栈:
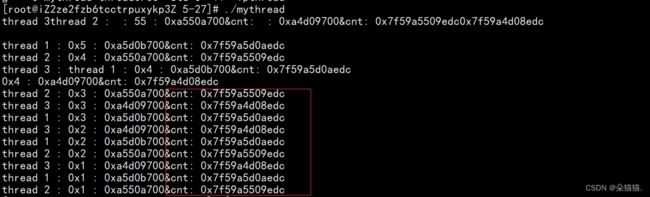
仔细观察可以看到地址是不一样的,地址很相似是因为他们都在共享区。下面我们再看看全局变量的地址:

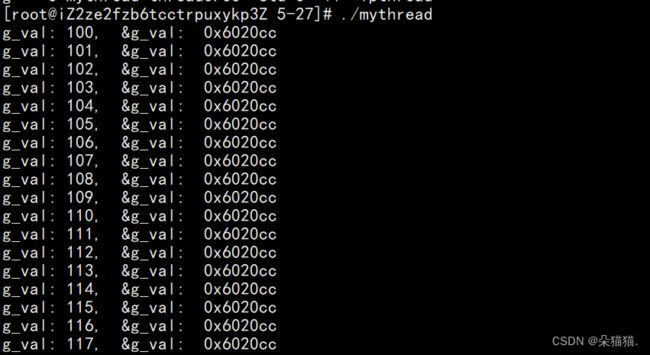 我们可以看到全局变量的地址一样说明3个线程都是同一个全局变量,这就证明了线程共享进程的地址空间。当然我们也可以在全局变量前面加上__thread让全局变量变成每个线程的局部存储:
我们可以看到全局变量的地址一样说明3个线程都是同一个全局变量,这就证明了线程共享进程的地址空间。当然我们也可以在全局变量前面加上__thread让全局变量变成每个线程的局部存储:

 运行后我们可以看到地址确实不一样了。下面我们进入互斥的内容
运行后我们可以看到地址确实不一样了。下面我们进入互斥的内容
二、线程互斥
在多线程中,有一个全局的变量,是被所有执行流共享的,而线程中大部分资源都会直接或者间接共享,而这就可能会存在并发访问的问题,如下图:

当我们要对一个全局变量进行--操作时,先将内存中的代码加载到CPU的寄存器当中,计算后将结果再写会内存中,这样内存中的100就变成了99:
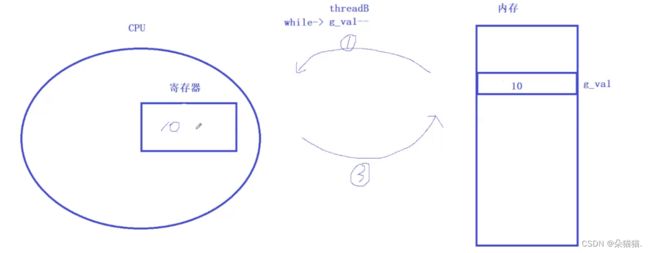
这个时候另一个线程过来了,这个线程是将100减到10所以在寄存器中减到10后将10写入内存中,然后线程B的时间片到了就重新调度线程A:

本来线程B好不容易将数减到10了结果A线程回来后数据又变成了99。所以当我们对全局变量做--操作时,如果没有保护的话,会存在并发访问的问题,进而导致数据不一致问题。所以为了解决这样的问题,引入了互斥这个概念。
int tickets = 10000;
void *threadRoutine(void* name)
{
string tname = static_cast(name);
while (true)
{
if (tickets>0)
{
usleep(2000); //模拟抢票花费的时间
cout< 上面代码中我们创建线程第一个参数是t+i是因为这个参数是指针类型,t是首元素地址所以这样写,join中第一个参数是线程id所以直接用t[i]即可。usleep可以让线程休眠:
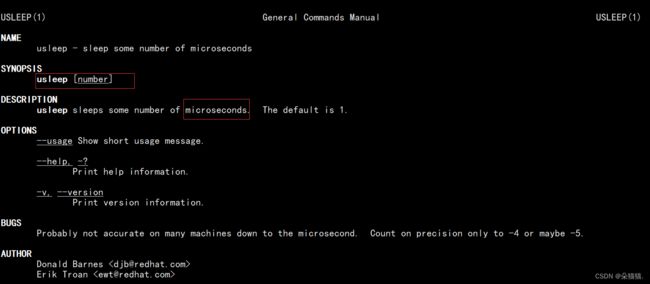
usleep休眠的时间是微秒为单位,所以我们相当于休眠0.002秒。下面我们运行起来:
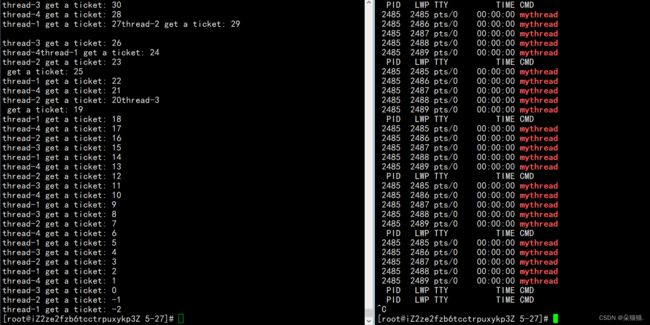
运行后经过多次抢票我们发现最后票数变成了负数,为什么是负数呢?这就是我们提到的并发问题了,和我们之前说的那个全局变量一样,由于没有对全局变量的上下问进行保护,所以会减到负数去,(比如说我们现在的票数是1,四个线程都进入到这个判断逻辑tickets>0,然后四个线程都进行--操作,这样票数就变成了-3 )要解决这个问题需要三点:
下面我们演示如何完成互斥:
在我们对临界资源进行加锁前需要学习一下互斥锁的概念:
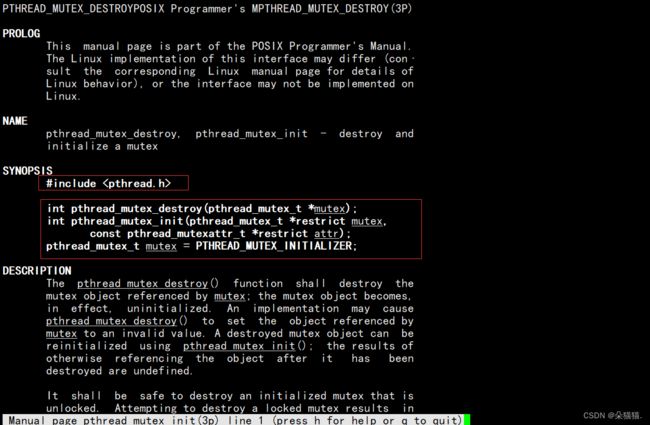
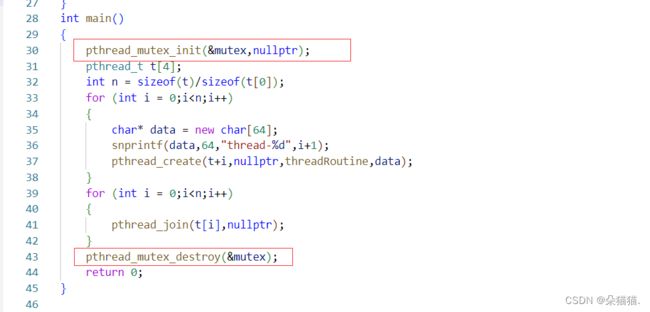
然后我们有了锁后还需要知道加锁的接口:pthread_mutex_lock:

对于加锁这个接口如果加锁成功就会对临界资源进行加锁,失败就会将当前线程阻塞住。当我们用完临界资源需要对这个资源进行解锁操作,我们解锁的时候必须保证一定能解锁,所以修改代码如下:
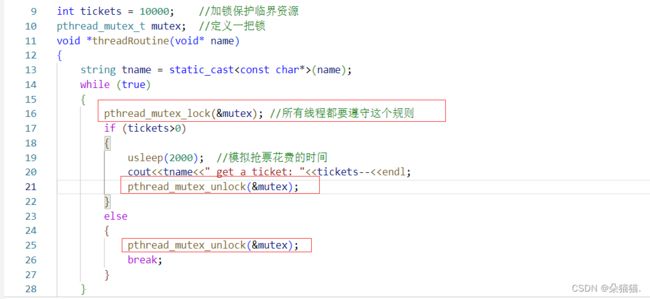
下面我们将代码运行起来:
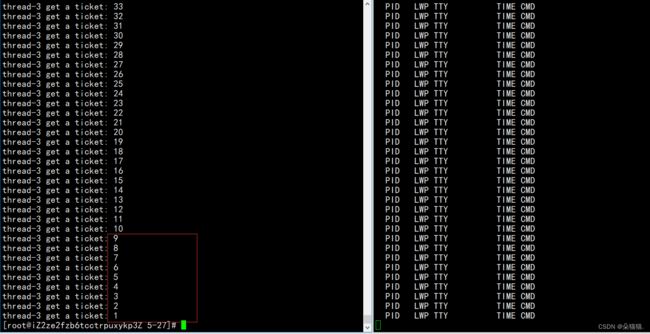 这次我们可以看到没有并发访问的情况了,但是为什么只有一个线程在抢票呢?这是因为我们抢完票还要将票放入用户的数据库当中,但是我们的代码并没有这个场景,下面我们用usleep模拟一下:
这次我们可以看到没有并发访问的情况了,但是为什么只有一个线程在抢票呢?这是因为我们抢完票还要将票放入用户的数据库当中,但是我们的代码并没有这个场景,下面我们用usleep模拟一下:
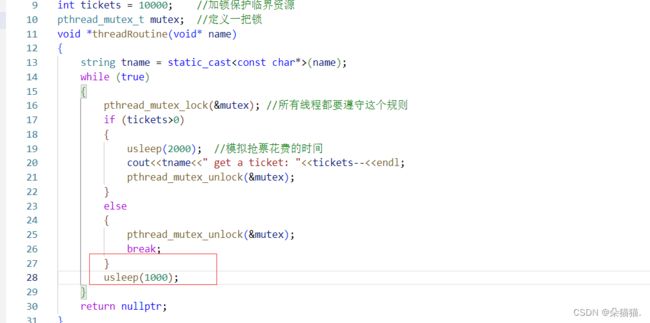
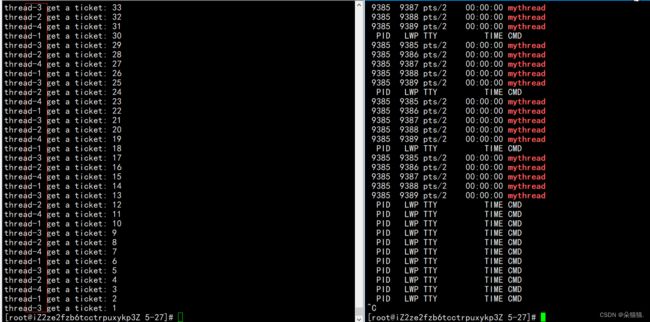
这样就让多个线程一起抢票了,以上就是我们对互斥锁的接口的使用,下面我们补充一些互斥锁的细节,我们先把代码修改一下:
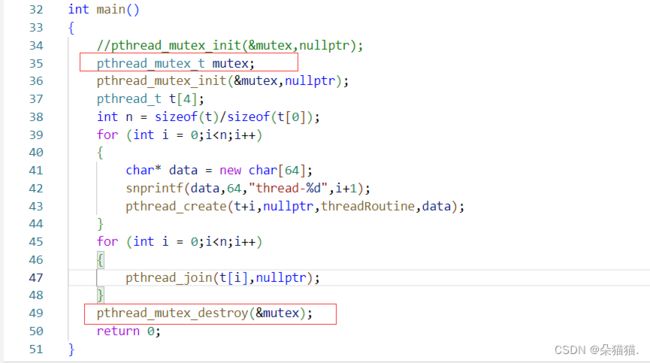
我们先创建一个局部的锁,然后对这个锁进行初始化,在结束前将这个锁销毁,那么局部的锁该如何被所有线程看到呢?我们用类解决这个问题:
class TData
{
public:
TData(const string& name,pthread_mutex_t* mutex)
:_name(name)
,_pmutex(mutex)
{
}
public:
string _name;
pthread_mutex_t* _pmutex;
};
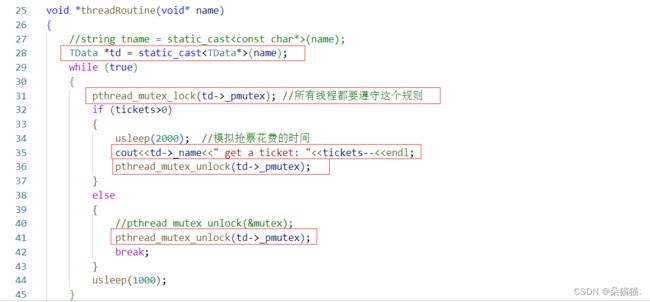
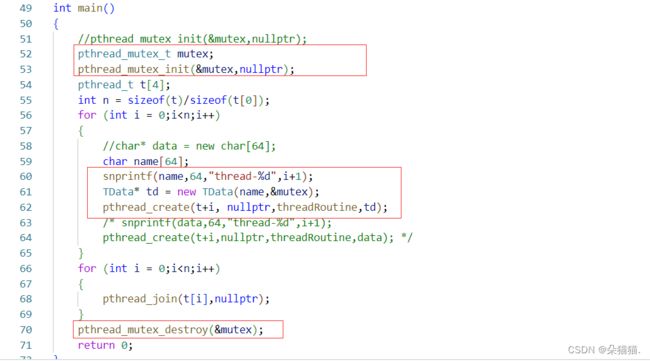
我们的思想很简单,就是让所有的线程都能看到我们的局部锁,所以我们定义了一个对象,对象中有线程的名字和锁,每个线程进入回调函数后都会给自己进行加锁解锁操作,下面我们运行起来看:
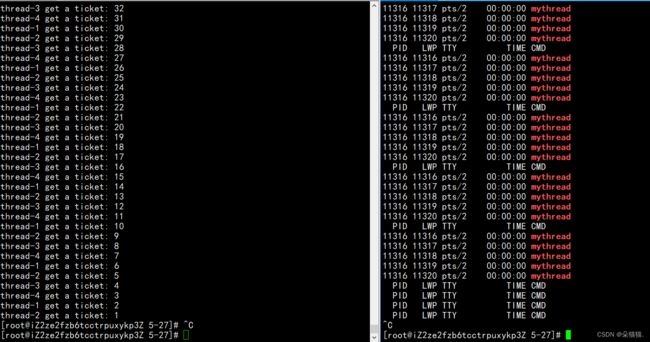
运行起来后我们可以看到和我们一开始的局部变量的效果一模一样,对于加锁我们总结四点:
1.凡是访问同一个临界资源的线程,都要进行加锁保护,而且必须加同一把锁,这是一个都遵守的规则,不能有例外。
2.每一个线程访问临界区之前,得加锁,加锁本质是给临界区加锁,加锁的粒度尽量要细一些。
3.线程访问临界区的时候,需要先加锁。所有线程都必须要先看到同一把锁,锁本身就是公共资源,锁如何保证自己的安全呢?因为锁是原子性的,所以无需保证。
4.临界区可以是一行代码,可以是一批代码。当一个线程已经申请到锁了,那么这个线程有可能被切换吗?当然是可能的,加锁只是保护这个线程的上下文数据。那么切换会有影响吗?不会。因为在我不在期间任何人都没有办法进入临界区,并且他无法成功的申请到锁,因为锁被原先申请到的那个进程拿走了。
5.加锁解锁正是体现互斥带来的串行化表现,站在其他线程的角度,对其他线程有意义的状态就是:锁被我申请(持有锁),锁被我释放了(不持有锁),原子性就体现在这里,要不有锁,要不没锁。
总结
以上就是线程分离和线程互斥的全部知识,本篇文章重点在于:
1.线程共享进程的地址空间。
2.线程有自己独立的栈结构(其实不只是栈,还有寄存器等)
3.线程分离后不需要join,如果不想join某个线程可以将它分离
还有就是我们加锁所总结的5点内容。