python调用腾讯api接口_python调用腾讯AI接口的坑
在百度和腾讯关于AI的接口对比,明显百度的接口简单明了很多,并且百度AI官方SDK支持python3,而腾讯的SDK for python就只有2.7版,至于是否兼容3.x版本我不知道,不想在研究它的代码上花太多的时间,自己看官方说明文档尝试自己写接入代码。
看了官方说明文档才知道,原来腾讯的AI接入SDK不支持3.x就算了,竟然还比百度的复杂,在写一个图片识别的脚本的时候,就在鉴权接口上被腾讯的官方说明文档给摆了一道

先看看官方对于鉴权接口的说明:

第一步,按照上面计算步骤说明,用python只能1、2作为一个步骤,因为python的字典是无序的,不像PHP关联数组那样有序,所以只能把字典用sorted()函数进行键值升序排序,然后用循环遍历字典的value并用quote()函数进行url编码,拼接成类似“key1=value1&key2=value2”的字符串。
第二部,加入app_key之后进行md5加密并把英文字母转换成大写,得到sign签名。def md5(src):
m1 = hashlib.md5()
m1.update(src.encode("utf-8"))
return m1.hexdigest()
def pic(img, appid, appkey):
data = {
"app_id": int(appid),
"time_stamp": int(time.time()),
"nonce_str": md5(str(time.time())),
"image": str(img),
"session_id": str(randint(100000000, 9999999999))
}
string = sorted(data)
ndata = ''
for i in string:
ndata += i + "=" + quote(str(data[i])) + "&"
urlparmer = ndata + "app_key=" + appkey
sign = md5(urlparmer).upper()
data["sign"] = sign
return data
根据官方说明写好相关代码,然后用requests提交数据,结果一直返回签名错误{
"ret": 16388,
"msg": "sign invalid",
"data": {
"text": ""
}
}
然后,就这么一个坑,浪费了我一个晚上的时间,先看看官方关于这个16388的ret是怎么解析的和怎么去排错:Q:接口返回16388是为什么?
A:参考返回码可以发现16388是服务器检查请求签名时,发现签名不正确。请开发者参考接口鉴权的示例代码进行检查。
Q:出现签名不正确的原因可能有哪些?
A:一般情况下,出现签名不正确的原因可能包含但不限于以下情况。设置计算签名的参数对有误(注意:每个接口的参数列表不一样,用于计算签名的参数列表也不一样)
没有正确按字典升序对参与签名的参数对进行排序,导致拼接URL键值对字符串有误
拼接URL键值对时,未对value部分进行URL编码
URL编码中,”%“后面两个字母为小写,但服务器要求大写形式(例如%2f是非法的,而%2F才是合法的)
URL编码实现不一致,例如空格符号编码成了"%20",但服务器实现是编码成"+"(可参考PHP的urlencode()函数实现其他语言的版本)
请求API时,发出的HTTP BODY中,所有参数都经过了二次urlencode(部分语言的http工具包会自动完成请求时所有参数的urlencode过程)
对于图片数据,在将图片进行base64编码时,未采用标准base64实现(编码结果仅由大小写字母、数字、+、/符号组成,不含回车换行符号,不含图片头data:image/jpg;base64,)
按照上面的说出现签名不正确的原因可能有哪些一步步检查,每个运算结果打印一遍出来检查,发现完全符合官方说明,到底是为什么呢?我一度以为是我的python版本问题,最后检查quote函数的时候,发现有个safe参数可选,默认值是'/',就是url编码的时候跳过safe参数指定的字符不进行编码,在我提交的参数当中,就只有base64编码的图片有这个符号,而且官方说明里面是允许有这个符号的(编码结果仅由大小写字母、数字、+、/符号组成,不含回车换行符号,不含图片头data:image/jpg;base64,)
没有办法,只能死马当活马医,试试把'/'也一起进行url编码,把代码修改成def md5(src):
m1 = hashlib.md5()
m1.update(src.encode("utf-8"))
return m1.hexdigest()
def pic(img, appid, appkey):
data = {
"app_id": int(appid),
"time_stamp": int(time.time()),
"nonce_str": md5(str(time.time())),
"image": str(img),
"session_id": str(randint(100000000, 9999999999))
}
string = sorted(data)
ndata = ''
for i in string:
ndata += i + "=" + quote(str(data[i]), safe='') + "&"
urlparmer = ndata + "app_key=" + appkey
sign = md5(urlparmer).upper()
data["sign"] = sign
return data
就是拼接字符串的时候,在quote函数里面添加参数"safe=''",不跳过任何字符进行urlencode,运行试试:
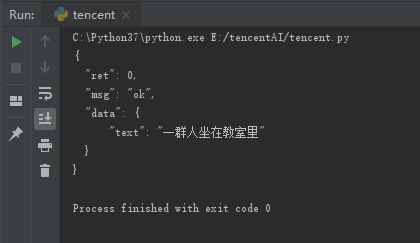
搞定,至此我觉得腾讯的一些说明文档也太坑爹了,明明说了可以有这个符号,却因为这个符号,浪费了我一个晚上的时间,代码写得烂,所以完整代码就不发了,需要得可以私信