kafka事务(伪事务)
事务要点知识
-
Kafka的事务控制原理
主要原理: 开始事务-->发送一个ControlBatch消息(事务开始)
提交事务-->发送一个ControlBatch消息(事务提交)
放弃事务-->发送一个ControlBatch消息(事务终止)
-
开启事务的必须配置参数(我不支持数据得回滚,但是我能做到,一荣俱荣,一损俱损)
Properties props = new Properties();
props.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"doit01:9092");
props.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// acks
props.setProperty(ProducerConfig.ACKS_CONFIG,"-1");
// 生产者的重试次数
props.setProperty(ProducerConfig.RETRIES_CONFIG,"3");
// 飞行中的请求缓存最大数量
props.setProperty(ProducerConfig.MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION,"3");
// 开启幂等性
props.setProperty(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG,"true");
// 设置事务id
props.setProperty(ProducerConfig.TRANSACTIONAL_ID_CONFIG,"trans_001");事务控制的代码模板
// 初始化事务
producer.initTransaction( )
// 开启事务
producer.beginTransaction( )
// 干活
// 提交事务
producer.commitTransaction( )
// 异常回滚(放弃事务) catch里面
producer.abortTransaction( )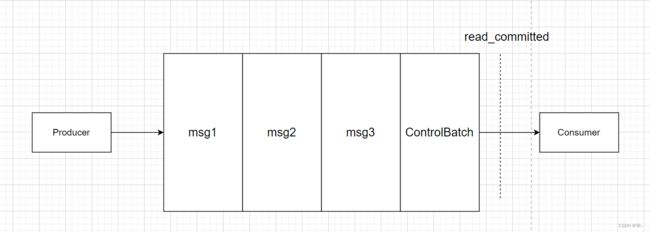
消费者api是会拉取到尚未提交事务的数据的;只不过可以选择是否让用户看到!
是否让用户看到未提交事务的数据,可以通过消费者参数来配置:
isolation.level=read_uncommitted(默认值)
isolation.level=read_committed
-
kafka还有一个“高级”事务控制,只针对一种场景:
用户的程序,要从kafka读取源数据,数据处理的结果又要写入kafka
kafka能实现端到端的事务控制(比起上面的“基础”事务,多了一个功能,通过producer可以将consumer的消费偏移量绑定到事务上提交)
producer.sendOffsetsToTransaction(offsets,consumer_id)事务api示例
为了实现事务,应用程序必须提供唯一transactional.id,并且开启生产者的幂等性
properties.put ("transactional.id","transactionid00001");
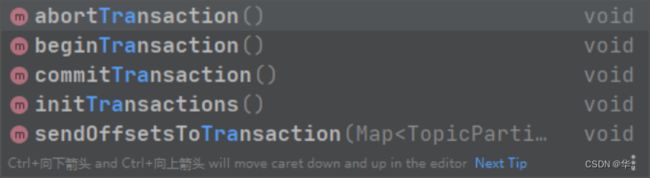
properties.put ("enable.idempotence",true);kafka生产者中提供的关于事务的方法如下:
“消费kafka-处理-生产结果到kafka”典型场景下的代码结构示例:
package com.doit.day04;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.errors.ProducerFencedException;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.apache.kafka.common.serialization.StringSerializer;
import java.time.Duration;
import java.util.Arrays;
import java.util.Properties;
public class Exercise_kafka2kafka {
public static void main(String[] args) {
Properties props = new Properties();
//消费者的
props.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"linux01:9092");
props.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "shouwei");
//自动提交偏移量
props.setProperty(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,"false");
props.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"earliest");
//写生产者的一些属性
props.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"linux01:9092");
props.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
//设置ack 开启幂等性必须设置的三个参数
props.setProperty(ProducerConfig.ACKS_CONFIG,"-1");
props.setProperty(ProducerConfig.RETRIES_CONFIG,"3");
props.setProperty(ProducerConfig.MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION,"3");
//开启幂等性
props.setProperty(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG,"true");
//开启事务
props.setProperty(ProducerConfig.TRANSACTIONAL_ID_CONFIG,"doit40");
//消费数据
KafkaConsumer consumer = new KafkaConsumer(props);
KafkaProducer producer = new KafkaProducer<>(props);
//初始化事务
producer.initTransactions();
//订阅主题
consumer.subscribe(Arrays.asList("eventlog"));
while (true){
//拉取数据
ConsumerRecords poll = consumer.poll(Duration.ofMillis(Integer.MAX_VALUE));
try {
//开启事务
producer.beginTransaction();
for (ConsumerRecord record : poll) {
String value = record.value();
//将value的值写入到另外一个topic中
producer.send(new ProducerRecord("k2k",value));
}
producer.flush();
//提交偏移量
consumer.commitAsync();
//提交事务
producer.commitTransaction();
} catch (ProducerFencedException e) {
//放弃事务
producer.abortTransaction();
}
}
}
} 事务实战案例
在实际数据处理中,consume-transform-produce是一种常见且典型的场景;
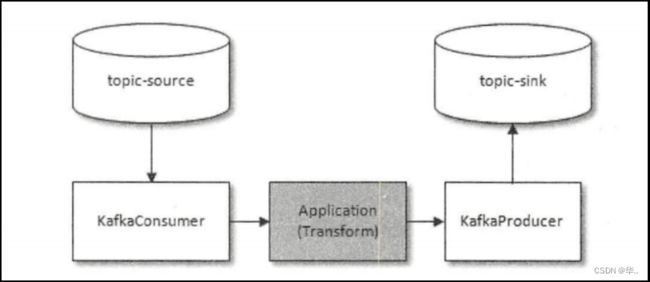
在此场景中,我们往往需要实现,从“读取source数据,至业务处理,至处理结果写入kafka”的整个流程,具备原子性:
要么全流程成功,要么全部失败!
(处理且输出结果成功,才提交消费端偏移量;处理或输出结果失败,则消费偏移量也不会提交)
要实现上述的需求,可以利用Kafka中的事务机制:
它可以使应用程序将消费消息、生产消息、提交消费位移当作原子操作来处理,即使该生产或消费会跨多个topic分区;
在消费端有一个参数isolation.level,与事务有着莫大的关联,这个参数的默认值为“read_uncommitted”,意思是说消费端应用可以看到(消费到)未提交的事务,当然对于已提交的事务也是可见的。这个参数还可以设置为“read_committed”,表示消费端应用不可以看到尚未提交的事务内的消息。
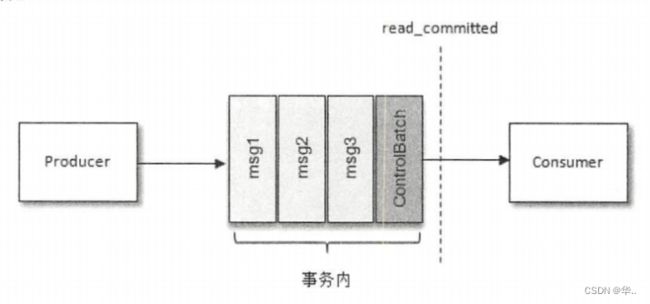
控制消息(ControlBatch:COMMIT/ABORT)表征事务是被提交还是被放弃