了解LLVM、Clang编译过程

LLVM 是一个自由软件项目,它是一种编译器基础设施,以 C++ 写成,包含一系列模块化的编译器组件和工具链,用来开发编译器前端和后端。它是为了任意一种编程语言而写成的程序,利用虚拟技术创造出编译时期、链接时期、运行时期以及“闲置时期”的最优化。它最早以 C/C++ 为实现对象,而当前它已支持包括 ActionScript、Ada、D语言、Fortran、GLSL、Haskell、Java字节码、Objective-C、Swift、Python、Ruby、Crystal、Rust、Scala 以及 C# 等语言。
– 维基百科
2000年,伊利诺伊大学厄巴纳-香槟分校(University of Illinois at Urbana-Champaign 简称UIUC)这所享有世界声望的一流公立研究型大学的 Chris Lattner(他的 twitter @clattner_llvm ) 开发了一个叫作 Low Level Virtual Machine 的编译器开发工具套件,后来涉及范围越来越大,可以用于常规编译器,JIT编译器,汇编器,调试器,静态分析工具等一系列跟编程语言相关的工作,于是就把简称 LLVM 这个简称作为了正式的名字。Chris Lattner 后来又开发了 Clang,使得 LLVM 直接挑战 GCC 的地位。2012年,LLVM 获得美国计算机学会 ACM 的软件系统大奖,和 UNIX,WWW,TCP/IP,Tex,JAVA 等齐名。
– 深入剖析 iOS 编译 Clang / LLVM
对于 iOS 开发者来说,Swift 之父 Chris Lattner 的大名应该都会有所耳闻。他和他的团队所开发的 LLVM 已经成为 iOS 乃至 macOS 整个生态中至关重要的底层基础设施。虽然 Lattner 本人已经去 Google 做人工智能了,但是对于 iOS 开发者了解并掌握一些关于 LLVM 的基本知识还是很有必要的。
LLVM 初探
LLVM 的官网是 http://llvm.org/。通过官网我们可以看到,LLVM 其实是一系列的编译组件的集合。而 Clang (标准读法是 克朗) 是作为其中的前端。这里的前端并不是 HTML5 这样的前端概念。说到这里,我们来简单回顾下传统编译器的设计吧
传统编译器
在 LLVM 诞生之前,使用最广泛的应该是 GCC 编译器了,当然,GCC 在当下仍然扮演着很重要的角色。

编译器前端 Front End
编译器前端的任务是解析源代码,具体工作内容包括下列三个流程:词法分析、语法分析、语义分析
检查源代码是否存在错误,然后构建抽象语法树(Abstract Syntax Tree, AST)。
LLVM的前端还会生成中间代码(intermediate representation, IR)。
优化器 Optimizer
优化器负责进行各种优化。改善代码的运行时间,例如消除冗余计算等。
编译器后端 Back End
将代码映射到目标指令集。生成机器语言,并且进行机器相关的代码优化。
有些资料也会把编译器后端成为 代码生成器 Code Generator。
从上面的内容可以看到,传统的编译器架构前端和后端之间耦合度太高,如果要支持一门新的编程语言,或者一个新的目标平台,工作量会非常大。
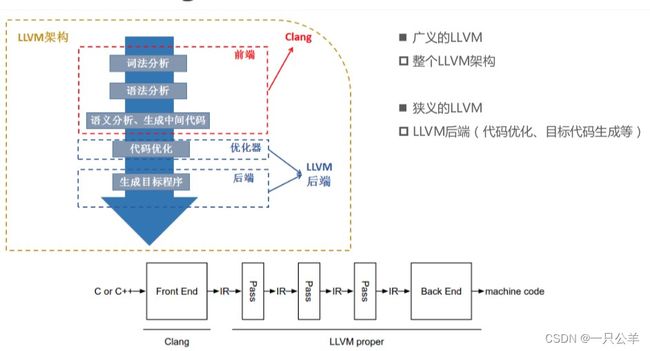
LLVM 架构
LLVM 之所以能够成为编译器中的中流砥柱,最重要的就是使用了通用的代码表现形式,也就是 IR。有了 IR,LLVM 就可以为任何编程语言独立编写前端,并且可以为任意硬件架构独立编写后端。

https://www.aosabook.org/en/llvm.html
Clang
Clang 是 LLVM 项目中的一个子项目。它是基于 LLVM 架构的轻量级编译器,诞生之初是为了替代 GCC,提供更快的编译速度。它是负责编译 C、C++、Objective-C 语言的编译器,它属于整个 LLVM 架构中的编译器前端。对于我们来说,研究 Clang 可以让我们更深刻的理解从源码到汇编再到机器码的这一过程。
Clang 的官网地址是 http://clang.llvm.org/
相比于 GCC,Clang 具有以下优点
- 编译速度快:在某些平台上,Clang的编译速度显著的快过GCC(Debug模式下编译OC速度比GGC快3倍)
- 占用内存小:Clang生成的AST所占用的内存是GCC的五分之一左右
- 模块化设计:Clang采用基于库的模块化设计,易于 IDE 集成及其他用途的重用
- 诊断信息可读性强:在编译过程中,Clang 创建并保留了大量详细的元数据 (metadata),有利于调试和错误报告
- 设计清晰简单,容易理解,易于扩展增强
也就是说,广义上的 LLVM 指的是整个 LLVM 架构,而狭义上的 LLVM 是指的 LLVM 后端。
而 LLVM 后端包括代码优化(优化器)和目标代码生成(后端)两个部分。
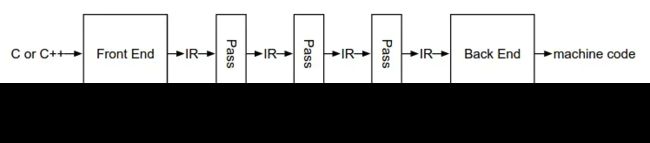
Clang 编译流程
clang -ccc-print-phases 源文件路径
- 输入文件:找到源文件
input, "main.m", objective-c
- 预处理阶段:这个过程处理包括宏的替换,头文件的导入
这个阶段主要是处理包括宏的替换,头文件的导入,可以执行命令 clang -E 源文件路径,执行完毕可以看到头文件的导入和宏的替换。define则在预处理阶段会被替换,所以经常被是用来进行代码混淆,目的是为了 app 安全,实现逻辑是:将 app 中核心类、核心方法等用系统相似的名称进行取别名,然后在预处理阶段就被替换,来达到代码混淆的目的。
preprocessor, {0}, objective-c-cpp-output
- 编译阶段:进行词法分析、语法分析、检测语法是否正确,最终生成IR
- 词法分析
预处理完成后就会进行词法分析,这里会把代码切成一个个 token,比如大小括号、等于号、还有字符串等, - 语法分析
语法分析,它的任务是验证语法是否正确,在词法分析的基础上将单词序列组合成各类此法短语,如程序、语句、表达式 等等 - 然后将所有节点组成抽象语法树(Abstract Syntax Tree AST),语法分析程序判断程序在结构上是否正确。
- 生成中间代码IR
完成以上步骤后,就开始生成中间代码 IR 了,代码生成器(Code Generation)会将语法树自顶向下遍历逐步翻译成 LLVM IR
compiler, {1}, ir
- 后端:这里LLVM会通过一个一个的pass去优化,每个pass做一些事情,最终生成汇编代码
backend, {2}, assembler
- 汇编代码生成目标文件
目标文件的生成,是汇编器以汇编代码作为插入,将汇编代码转换为机器代码,最后输出目标文件(object file)
assembler, {3}, object
- 链接:链接需要的动态库和静态库,生成可执行文件
链接主要是链接需要的动态库和静态库,生成可执行文件,其中静态库会和可执行文件合并,动态库是独立的。连接器把编译生成的 .o 文件和 .dyld、.a 文件链接,生成一个 mach-o 文件
linker, {4}, image(镜像文件)
- 绑定:通过不同的架构,生成对应的可执行文件
bind-arch, "x86_64", {5}, image
什么是LLVM?
http://events.jianshu.io/p/1ac7feeb4ed5