C++面向对象编程
面向对象编程
- 面向对象编程和面向过程编程
-
- 面向过程
- 面向对象
- 类型设计
- 类的成员函数
- 对象的创建和使用
-
- C++对象模型
- this指针
- 构造函数和析构函数
-
- 构造函数定义和使用
- 析构函数的定义和使用
- 对象的生存周期
- 拷贝构造函数
-
- 深拷贝与浅拷贝
- 运算符的重载
面向对象编程和面向过程编程
面向过程
我们学过C语言,其就是一种面向过程的编程流程,以事件为中心,解决事件时分析出流程,然后用函数实现一系列流程,然后按照流程一步一步按顺序调用函数。
优点:流程化使得编程任务明确,在开发之前基本考虑了实现方式和最终结果,具体步骤清楚,便于节点分析。
效率高,面向过程强调代码的短小精悍,善于结合数据结构来开发高效率的程序。
缺点:需要深入的思考,耗费精力,代码重用性低,扩展能力差,后期维护难度比较大。
面向对象
在编程时,一些简单问题可以通过面向过程来解决,但是当问题规模变大的时候就有困难了。编程本质来源于现实生活,我们的生活中可以看成一个一个对象,每个对象拥有一定的属性,这就引入了面向对象编程的概念,面向对象是一种以“对象”为中心的编程思想,把要解决的问题分解成各个对象,建立对象的目的不是为了完成一个步骤,而是为了描叙某个对象在整个解决问题的步骤中的属性和行为。
优点:
结构清晰,程序是模块化和结构化,更加符合人类的思维方式;
缺点:
开销大,当要修改对象内部时,对象的属性不允许外部直接存取,所以要增加许多没有其他意义、只负责读或写的行为。这会为编程工作增加负担,增加运行开销。
类型设计
封装是C++中最基本的一个属性,但是封装从何而来呢?C++将对象的属性和操作都放入一个类里,这就是其面向对象的本质。
模板:
class 类型名称 {
public:成员列表;
private:成员列表;
protected:成员列表;
};
以上便是类的模板,模板中给了三个不同的数据类型,public是公有成员,可以从外部访问(例:此处的成员可以直接在主函数中调用),而private(私有的),protected(保护的)中的成员不能直接调用,只能通过公有函数进行访问改变其属性,这就体现了C++的封装特性。
类的成员函数
类是一种数据类型,定义时系统不为其分配存储空间,所以不能对类的数据从成员进行初始化。也不能使用extern,auto,register关键字限定其存储类型。
成员函数可以直接使用类定义中的任意成员,可以处理数据成员,也可以调用函数成员,成员函数的定义:
类中一般只对成员函数进行声明,函数定义通常在类的说明之后进行,格式:
返回值类型 类名::函数名(参数表) {}
//我们可以举例如下:
class mybook {
public:
void my_printf(char* name,int priace,int math,int nums);
private:
char name[10];//书名
int priace;//单价
int math;//数量
int nums;//总价
};
void mybook::my_printf(char* name,int priace,int math,int nums) {
cout<<"name"<<name<<"price"<<price<<"math"<<math<<"nuns"<<nums<<endl;
}
对象的创建和使用
类只是对象的模板,就像盖房子图纸,有了类不一定存在对象,只是告诉编译器可以通过类可以定义对象(盖房子),为在内存中开辟出该对象的实例,
定义对象时我们可以直接通过类名来定义一个对象。
int a;
mybook java;
我们通过mybook类型名创建了一个对象-》java,同时为他分配了一定的存储空间来存放其数据和操作函数(代码)。
对象的使用很简单,就是在对象名后加上’.',紧接着加上成员函数名,和调用函数一样加上实参即可,但是此处必须是公有成员函数,私有和受保护的只能在成员函数中被调用,不能在外部直接调用。
C++对象模型
当定义对象数量为4时,我们的对象属性很显然会在数据区申请到4份存放数据(对象属性)的区域,而不同之处在于其操作属性的行为,也就是函数,成员属性我们能理解,每个对象是独立的,成员属性也应该是独立的,但是成员函数是操作对象属性的行为,然后对象属性相同,因此如果在代码区存放4份成员函数就会显得浪费内存,所以此处有两种形式,一是对象拥有独立的代码区存放成员函数,二是对象公用一份成员函数的代码,放在公共代码区。
this指针
class Int
{
int value;
public:
Int(int x = 0) :value(x) { cout << "Create Int Object " << this << endl; }
Int(const Int& it) :value(it.value) { cout << "Copy Create Int Object" << this << endl; }
Int& operator=(const Int& it)
{
if (this != &it)
{
value = it.value;
}
return *this;
}
~Int() { cout << "Destroy Int " << this << endl; }
void PintInt() const { cout << value << endl; }
};
int main()
{
Int a(10), b(20), c;
Int d(b);
c=a;
c.PintInt();
return 0;
}
编译器对程序员自己设计的类型分三次编译:
第一:识别记录类体种的属性名称,类型和访问权限,与属性在类体中的位置无关。
第二:识别和记录类体中函数原型(返回类型+函数名+参数表),形参的默认值,访问限定,不识别函数体。
第三:改写在类中定义函数的参数列表,改写对象调用成员函数的形式。
在成员函数中一般都会存在this指针,例如构造函数,拷贝构造函数等
如上代码:我们以运算符重载函数为例,c=a <=>c.operator=(a)<=>operator(&c,a);我们可以看出c对象在调用运算符=重载函数时,此处this指针指向对象c,一般函数会省略掉this指针,我们可以还原函数编译阶段的参数,
Int& operator=(const Int& it)
//Int& operator(Int *const this,cosnt Int & it );而this指针便指向我们调用函数的对象
this指针特点:
- 只能在成员函数中使用,在全局函数,静态成员函数中都不能使用this指针。this指针始终指向当前对象。
- this指针是在成员函数的开始前构造,并且在成员函数结束后清楚。
- this指针会因编译器不同而有不同的存储位置,可能是栈,寄存器或全局变量。
构造函数和析构函数
构造函数定义和使用
类的数据成员多为私有的,不能从外部进行操作,因此需要通过公有的成员函数进行操作赋值,而构造函数便是再创建对象的同时进行初始化的函数,注意只能初始化一次。
作用:
- 创建对象
- 初始化对象
- 类型转换
构造函数的特点:
- 函数名同类型名
- 无函数返回类型,此处并非void,即什么也不写。其实构造函数本质上存在返回类型,同类名,返回的就是我们创建的对象。
- 程序运行时,当对象被创建时自动调用构造函数,并且只能调用一次,生存期也就仅仅这一次调用。
- 构造函数可以进行重载,其实可以构造多个构造函数,根据参数不同在创建对象的同时选择一个构造函数进行创建并初始化。
- 构造函数可以在类内定义,也可以在类内声明类外定义。
- 如果没有给出构造函数,那么编译器会默认给出一个缺省构造函数。但是如果给出了缺省构造函数那么编译器便不会给出构造函数。
class Int {
private: int value;
public:
Int(int c=0) {
this->value=c;
}
};
析构函数的定义和使用
当创建对象时,系统会自动调用构造函数从而进行初始化,当然当对象生命周期结束的时候页会自动调用析构函数,对对象进行注销并且做一系列善后工作,这就是析构函数。
- 析构函数名同类名,只是在类名前加上‘~’
- 析构函数没有给出的话,系统会自动生成析构函数。
- 析构函数没有返回值和无类型。
- 一个类只有一个析构函数。
class mystring {
private: char* ptr;
public:
mystring(const char* s=nullptr) {
if(this!=nullptr) {
int len=strlen(s)+1;
ptr=new char[len];
strcpy_s(ptr,len,s);
}else {
ptr=new char('\0');
}
}
~mystring() {
delete[]ptr;
ptr=nullptr;
}
};
构造函数和析构函数的区别是:1、构造函数可以接收参数,能够在创建对象时赋值给对象属性,析构函数不能带参数;2、创建对象时调用构造函数,析构函数是在销毁对象时自动调用的。
对象的生存周期
- 局部对象:对于局部定义的对象,当程序抵达对象定义时调用构造函数,程序运行走出局部域的时候会自动调用析构函数。
- 静态局部对象:程序运行首次到达对象定义时调用构造函数,整个程序结束时调用析构函数
- 全局对象:程序进入main函数之前就已经定义了对象,这时要调用构造函数,整个程序结束时调用析构函数。
- 动态创建对象:使用new创建对象,使用delete释放对象。
class mystring {
private: char* ptr;
public:
mystring(const char* s=nullptr) {
if(this!=nullptr) {
int len=strlen(s)+1;
ptr=new char[len];
strcpy_s(ptr,len,s);
}else {
ptr=new char('\0');
}
}
~mystring() {
delete[]ptr;
ptr=nullptr;
}
};
void fun() {
mystring d("ace");//局部对象
static mystring e("afa");//静态局部对象
}
mystring a;//全局对象
int main() {
mystring b("hello");
mystring *c=new mystring{"xxin"};//动态创建对象
delete c;
mystring q;
new(q) mystring("xxin");//定位new
fun();
}
拷贝构造函数
拷贝构造就是用一个对象的数据拷贝一份初始化另一个对象,这个过程需要拷贝数据成员。在建立对象的时候用一个已存在的对象来初始化该对象的内存空间,这就是拷贝构造函数。
mystring(const mystring& it) {
int len=strlen(it.ptr);
ptr=new char[len];
strcpy_s(ptr,len,it.ptr);
}
- 拷贝构造函数是构造函数的一个重载形式。
- 拷贝构造函数的参数只有一个且必须使用引用传参,使用传值回进入无穷递归调用。
- 若显示定义,系统自动生成默认的拷贝构造函数。默认的拷贝构造函数对象按内存存储按字节序完成拷贝,称为:位拷贝。
深拷贝与浅拷贝
我们知道在创建字符串这个类的时候,字符串存在于堆中,而对象中只存在一个指向堆区字符串的指针,正所谓浅拷贝就是在创建这个对象时,仅仅将这个对象的指针指向待拷贝对象的堆区字符串,两者公用一块堆区空间,记住此时只能释放一次,否则程序会崩掉。而深拷贝就是将堆区资源也进行了一份拷贝,在堆区重新申请了一块空间,待拷贝字符串复制一份存放在这块空间中,对象的指针指向这块新的堆区空间。大部分拷贝都是深拷贝,大家也可以用浅拷贝仿写一下mystring类并实现代码。
运算符的重载
运算符重载我觉得本质上是一种特殊的函数重载,一般为类的成员函数,
- 运算符重载的函数名必须为关键字operator加上一个合法的运算符。在调用该函数时,将右操作数作为函数的实参。
- 当用类的成员函数实现运算符重载时,运算符重载函数的参数为一个或者没有,运算符的左操作数一定是对象,因为重载的运算符是该对象的成员函数,而右操作数是该函数的参数。
- 单目运算符中前置++和后置++的问题
前置++:返回类型 类名::operator++() {}
后置++:返回类型 类名::operator++(int){}
后置++中的参数int用于区别是前置++还是后置++,并无实际意义,可以给一个变量名,也可以不给。大家发现很多经验丰富的程序员平时编写程序时会使用前置++,很少使用后置++,这是什么呢?
比如我们写一个for循环程序,而循环中++是对自己创建的一个类对象++,在运行时我们就会发现使用后置++会导致每一次自增都会生成一个新的对象,而前置++并不会,所以一般会使用前置++ - C++中只有极少数的运算符不允许重载:
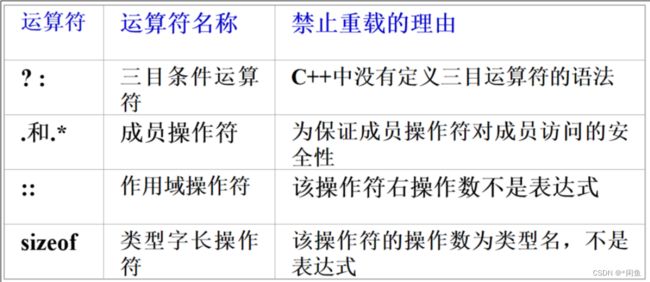
还有#,##,//,/*, */