总结:redis和Zookeeper中分布式锁的对比
集群中分布式锁
- 什么是分布式锁
- 单机
- 集群
-
- Redis
- Zookeeper
-
- 非公平锁加锁的原理
- 公平锁
- 共享锁
什么是分布式锁
锁,解决的是多线程或多进程情况下的数据一致性问题;分布式锁,解决的是分布式集群下的数据一致性问题。
为了保证一个方法或属性在高并发情况下的同一时间只能被同一个线程执行,在传统单体应用单机部署的情况下,可以使用Java并发处理相关的API(如ReentrantLock或Synchronized)进行互斥控制。
在单机环境中,Java中提供了很多并发处理相关的API。但是,随着业务发展的需要,原单体单机部署的系统被演化成分布式集群系统后,由于分布式系统多线程、多进程并且分布在不同机器上,这将使原单机部署情况下的并发控制锁策略失效,单纯的Java API并不能提供分布式锁的能力。为了解决这个问题就需要一种跨JVM的互斥机制来控制共享资源的访问,这就是分布式锁要解决的问题!
举个例子:
机器A , 机器B是一个集群, A, B两台机器上的程序都是一样的, 具备高可用性能.
A, B机器都有一个定时任务, 每天晚上凌晨2点需要执行一个定时任务, 但是这个定时任务只能执行一遍, 否则的话就会报错, 那A,B两台机器在执行的时候, 就需要抢锁, 谁抢到锁, 谁执行, 谁抢不到, 就不用执行了!
单机
单机和集群是指第三方p的部署形式。
单机场景下,首选redis实现分布式锁
理由是:
1.redis基于内存
2.redis单线程多路复用,减少了多个线程创建时的开销,避免了不必要的上下文切换已经资源竞争导致的锁开销。
3.用的hash结构
总之就一个字,速度贼鸡儿快!而zk的话是目录树结构,性能完全没得比。
集群
分布式锁,有不同的实现,redis和zookeeper均可以提供该功能,
Redis
基于Redis中setnx(),setnx也可以存入key,如果存入key成功返回1,如果存入的key已经存在了,返回0.
@RequestMapping("/deduct_stock")
public String deductStock() {
String lockKey = "product_101";
String clientId = UUID.randomUUID().toString();
try {
Boolean result = stringRedisTemplate.opsForValue().setIfAbsent(lockKey, "zhuge"); jedis.setnx(k,v)
stringRedisTemplate.expire(lockKey, 10, TimeUnit.SECONDS);
Boolean result = stringRedisTemplate.opsForValue().setIfAbsent(lockKey, clientId, 30, TimeUnit.SECONDS);
if (!result) {
return "error_code";
}
//加锁
int stock = Integer.parseInt(stringRedisTemplate.opsForValue().get("stock")); // jedis.get("stock")
if (stock > 0) {
int realStock = stock - 1;
stringRedisTemplate.opsForValue().set("stock", realStock + ""); // jedis.set(key,value)
System.out.println("扣减成功,剩余库存:" + realStock);
} else {
System.out.println("扣减失败,库存不足");
}
} finally {
if (clientId.equals(stringRedisTemplate.opsForValue().get(lockKey))) {
stringRedisTemplate.delete(lockKey);
}
}
return "end";
}
关键代码:
Boolean result = stringRedisTemplate.opsForValue().setIfAbsent(lockKey, clientId, 30, TimeUnit.SECONDS);
当在分布式情况下,多个线程请求时,假设有A和B,A第一个请求到了会在redis中创建一个(product_101,随机id),如果这是A下面的业务没有处理完,B请求过来,redis会根据这段代码会返回false,因为其A已经处理,根据下面if判断,会return出去,B无法执行下面的代码。第3,4参数是设置了30s内该key会自动失效,目的是为了解决防止死锁。
这只是一个简单思路,其实里面还是有问题的,如:30s内我的业务代码没有执行完,请自动进行"释放锁",会导致程序错乱,设置时间太长,会严重影响redis性能。所以,这个地方解决方案是:可以再开一个线程,定时轮询做检测,当A没有释放锁,就将时间进行延迟。
有个很好的框架Redisson 大家可以看看其底层源码其已经算是Redis中分布式锁的一个很好框架了。
Ression框架详解请看下面
https://github.com/redisson/redisson/wiki
基于AP原则。无法保证强一致性,但是Zookeeper可以。
Zookeeper
非公平锁加锁的原理
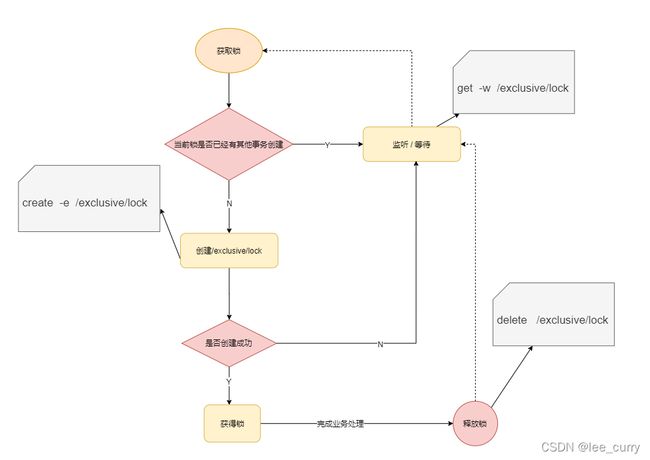
1.创建一个节点时,会进行判断是否创建成功,
2.如果创建成功获得锁,处理业务后,释放锁
3.如果创建失败,监听该节点(如果其他节点释放后,会对进行监听的所有节点进行通知)接到通知可以去获取锁了。
如上实现方式在并发问题比较严重的情况下,性能会下降的比较厉害,主要原因是,所有的连接都在对同一个节点进行监听,当服务器检测到删除事件时,要通知所有的连接,所有的连接同时收到事件,再次并发竞争,这就是羊群效应。这种加锁方式是非公平锁的具体实现:如何避免呢,我们看下面这种方式。
公平锁
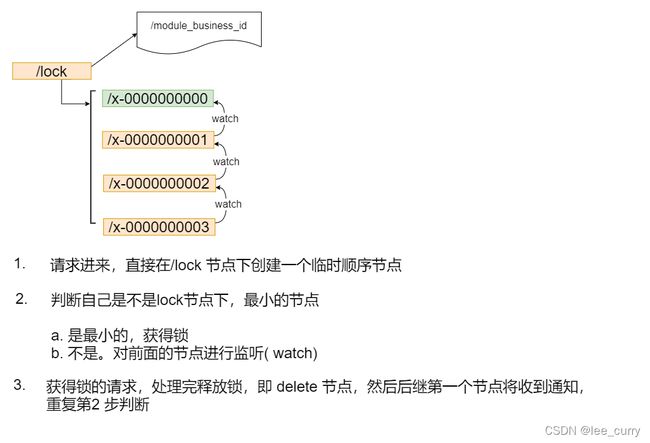
共享锁
前面这两种加锁方式有一个共同的特质,就是都是互斥锁,同一时间只能有一个请求占用,如果是大量的并发上来,性能是会急剧下降的,所有的请求都得加锁,那是不是真的所有的请求都需要加锁呢?答案是否定的,比如如果数据没有进行任何修改的话,是不需要加锁的,但是如果读数据的请求还没读完,这个时候来了一个写请求,怎么办呢?有人已经在读数据了,这个时候是不能写数据的,不然数据就不正确了。直到前面读锁全部释放掉以后,写请求才能执行,所以需要给这个读请求加一个标识(读锁),让写请求知道,这个时候是不能修改数据的。不然数据就不一致了。如果已经有人在写数据了,再来一个请求写数据,也是不允许的,这样也会导致数据的不一致,所以所有的写请求,都需要加一个写锁,是为了避免同时对共享数据进行写操作。
举个例子
1、读写并发不一致

2.

实现原理

1.写的时候,会去考虑前面所有的线程是否都执行完。跟公平的互斥锁一样。
2.读的时候,只需要考虑前面的跟写有关的线程是否都执行完。