字节跳动流式数仓和实时服务分析的思考与实践
本文整理自火山引擎云原生实时数仓技术专家汪建锋在 DataFun 现代数据栈在线峰会上的演讲,主要介绍字节跳动流式数仓和实时服务分析的思考与实践。
作者|火山引擎云原生实时数仓技术专家-汪建锋
字节跳动旗下有许多产品,每天有大量的数据需要接收和计算。其中,以抖音、头条等为代表的产品以实时推荐和流计算为核心,这些都需要消耗大量的计算资源和存储资源。巨大的数据量和快速准确的计算需求,给技术架构带来了巨大的挑战。
本次分享的主题为“字节跳动流式数仓和实时服务分析的思考和实践”,将围绕以下3点展开:
- 字节跳动产品架构的业务困境
- 流式数仓和实时服务分析的实践
- 火山引擎云原生计算
业务困境
字节内部场景分析

字节跳动(下称“字节”)旗下拥有今日头条、抖音等多款产品,每天服务着数亿用户,由此产生的数据量和计算量也非常大:
- EB 级别海量的存储空间
- 每天平均 70PB 数据的增量
- 每秒钟百万次数的实时推荐请求
- 超过 400 万核的流式计算资源、500 万核的批式计算资源
在进行大数据分析的时候,对数据通常有两种处理方式:
1、描述已经发生过的数据,比如,过去发生了什么,为什么发生,通常采用批计算来处理;
2、描述正在发生的数据,比如,此时正在发生什么,将要发生什么,这些通常采用流计算来处理,也是今日头条、抖音等产品实时推荐的核心。
遇到的典型问题
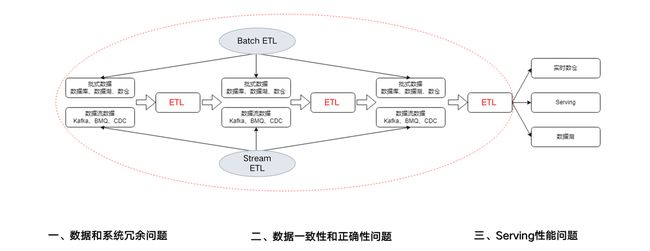
如上图所示,字节内部对于数据的处理也分为两条链路:流计算链路和批计算链路。两条链路有着不同的存储以及数据处理方式,给整个架构带来了挑战:
1、数据和系统冗余,流批两套系统采用了两套技术栈,两套存储系统,在使用过程中需要分别维护,这使工程师运维和学习的成本非常高;
2、数据一致性和正确性问题,数据来自多个源头,采用了流批两种处理方式,处理逻辑不一样,代码不可复用,在 ETL 的计算过程中数据被反复引用,这些都可能使最终的业务数据发生变化,导致数据不一致;
3、Serving 性能问题,有些业务的主要场景比较简单,但也需要消耗大量的资源,比如简单的点查,往往要求高 QPS。如果采用传统大数据的方案,把主键拼起来,那么中间的结合是松耦合的,如果要同时达到高 QPS,这种拼接方案在计算上和资源上的投资都会很大,性能问题也很严重。
针对上述困境,字节团队选择了流式数仓和实时服务分析融合的解决方案。
流式数仓和实时服务分析实践
流数仓和服务数仓融合

字节通过实践将 Streaming Warehouse 流式数仓和实时服务分析进行融合,Streaming Warehouse 做数据处理,实时服务分析做数据服务,两者结合可以解决三个问题:
- Flink Table Store 解决数据和系统冗余问题
- 基于 Flink 流批一体,解决数据冗余性和正确性问题
- 实时服务分析引擎优化解决服务性能问题
对流批一体的思考
在做流式数仓以及实时数仓的产品以前,字节内部的架构师一直在思考一个问题:流批一体的核心到底是什么?
最终团队认为,存储就是流批一体的核心,存储就是所有数据分析的基础。

如上图所示,流数据随着时间的推移不停地变化,没有边界,从数据库的角度来看,每次 Binlog 之后会有一定的存储写入到硬盘中做持久化,每一个 Snapshot 对应 Binlog 实时位点,这样整个 Snapshot 就是一个有边界的批式数据,像上图一样一个桶一个桶地放着,两者结合就是完整的流批一体。
Binlog 和 Snapshot 两个加起来,在数据库中既能处理流数据也可以处理批数据,所以字节团队将 Flink 的 Table Store 技术作为了最核心的基础支撑。
Flink Table Store
1、全新的 Flink 内置存储
Flink Table Store 有以下特性:
a、Snapshot + Log
b、满足所有“实时” User Case
c、存储易用,直接查询 DFS
从 Flink Table Store 的定位来看,Flink Table Store 有 Snapshot,支持批处理,加上 Log 流,同时还提供统一的存储,可满足所有面向实时分析服务的 User Case。
其次,Flink Table Store 存储易用,可直接像 DFS 分布式文件系统或对象存储一样使用,这对整个效率的提升、存储成本和性能的平衡都有很大作用。
2、存储结构
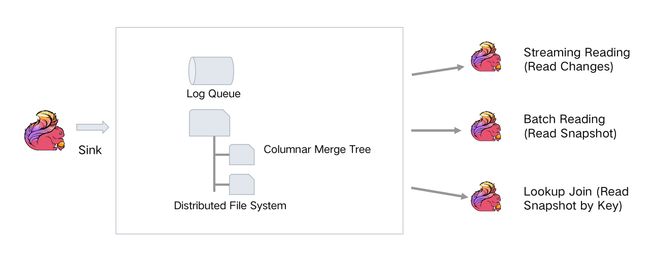
Flink Table Store 的存储结构包括两部分:
- 依赖于流式的其他消息队列组件的 Log Queue
- 基于列存的分布式文件系统
两部分结合可以支持流读(Streaming Reading)、批读(Batch Reading)以及 Lookup Join。
3、流批一体
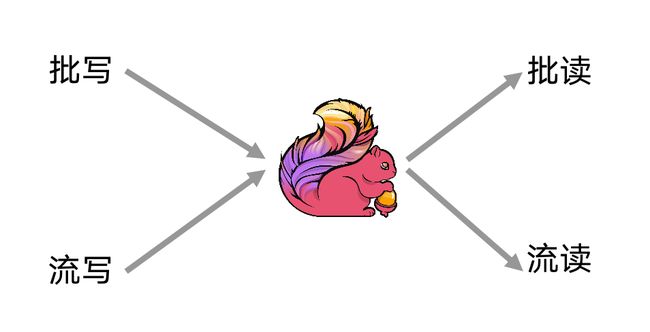
Flink 有支持流批一体的特性,在读取方面,可以支持流读,可以读取 Log Changes,也可以支持批读,读 Snapshot,还可以对批流进行融合读取,Hybrid read 读,还可以支持点查。在写入方面,既可以支持持续地流式数据插入,也可以支持分区,支持 Overwrite 的批写。
整个底层跟数据服务是类似的,可以基于分布式文件系统,底层是无服务的状态,能做到计算和存储分离 。同时,Flink Table Store 本身是基于列存的,也具备列存所具有的高性能的分析特性,比如压缩比。
4、全面支持 SQL
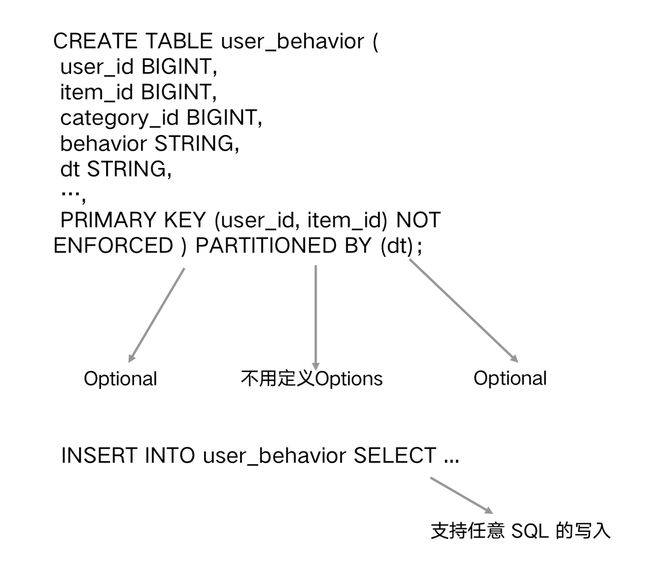
目前业界没有外部存储可以支持 Flink SQL 的所有能力,要么不支持定义,要么不支持 Change,或者不支持批写,也有的不支持 Online 查询,这会造成流式存储、读取、查询的困难。
Flink Table Store 可以全面支持 Flink SQL。通过 Flink Table Store 存储后的数据,只要有这个业务逻辑,有主键可选,就能够进行任意的 DDL 定义,还支持所有的类型,如消息类型或 DML。在此基础上,我们就可以把查询或定义做得更好。
5、Merge Tree
Merge Tree 是用于实时计算核心的内部基础,FlinkState,ClickHouse 及 HBase,包括 HSAP,都是基于 Merge Tree 的。Merge Tree 本身支持大量快速更新的能力,包括更新写增量文件,以及基于 Sorted File 按需 Merge。
Merge Tree 还可以支持高效分析和点查,它的全局有序性可以做到很好地 Data Skiping,提升检索、查询的效率。
根据这些特点,字节团队用 Flink Table Store 搭建实时数仓和实时服务分析的底层根基,并在上面进行进一步优化。
6、字节 Flink OLAP 优化
Flink OLAP 能力是流数仓的核心之一,字节团队基于 Flink 构建了全新的 OLAP 引擎,已支持 User Growth、电商、幸福里、飞书等业务,共 11 个集群 6000+ Core AP 资源,每天 Query 50w+。同时为了支持业务在使用 Flink OLAP 的过程中查询 Latency 和 QPS 的需求,对 Flink 引擎架构和功能实现进行了大量深入优化,使业务查询性能提升50%以上,节省了计算资源;在小规模数据量下,Flink 复杂作业执行的 QPS 从 10 提高到 100 以上,简单作业执行的 QPS 从 30 提高到 1000 以上。
我们在优化字节内部 Flink OLAP 能力的同时,正在跟社区合作,积极将相关优化回馈社区,在[FLINK-25318] Improvement of scheduler and execution for Flink OLAP 下创建了20多个子任务,有部分已经合并入主分支,剩余的也在设计和开发中,后续计划跟社区一起共同推进 Flink OLAP 能力建设和完善。
实现数据流端到端一致性
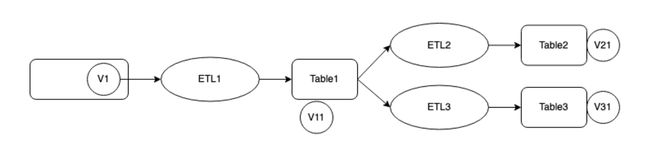
在 ETL 过程中,同一份数据源会进行多次计算,一些 ETL 的结果数据在对用户提供查询分析服务的同时也作为数据源执行下一轮,这时就会产生三个一致性问题:
a、数据源到 ETL exact once
b、ETL 写入单表 exact once
c、多个中间表的关联一致性
如上文所提到,在没有 Flink Table Store 和实现流批一体之前,计算分为流计算链路和批计算链路,两条链路有各自独立的计算集群和调度,数据有不同的入口和不同的处理方式,这种模式下做数据的端到端一致性挑战很大,成本非常高。
实现流批一体后,通过自动调度资源,自动调度流式链路的数据处理流程,把链路中的数据流程通过中间表的事务写入,保证中间数据链路的一致性。同时 Flink 的本身的 Exact Once 特性也能保证在 ETL 中间过程的链路上一致性。
字节团队通过流批一体化解决了数据跟系统的数据冗余以及一致性的问题,在此基础上,我们进一步对性能进行了优化。
采用云原生和实时服务分析提升性能
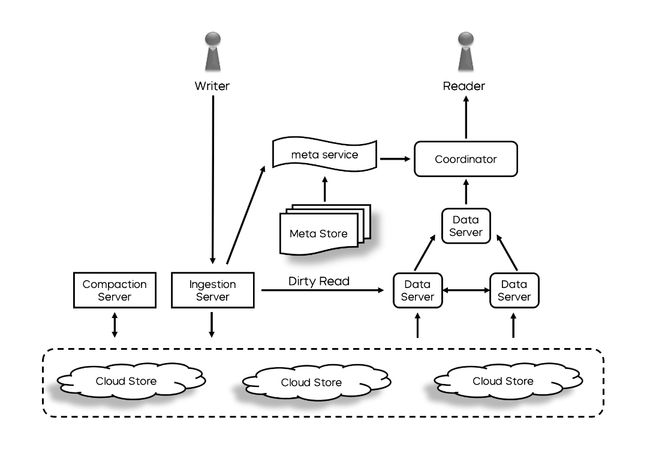
云原生架构
字节的产品基本都是基于云原生架构进行改造,基于容器化,在公共云上全托管的 Serverless 模式。
在这个模式下,上层的用户只需要关注业务应用和规划,下面的资源运维管理和调度分配由技术团队处理,用户使用门槛低,同时也避免业务深度介入运维管理。
同时,云原生基于存算分离,弹性很高,能够满足高效的横向扩展。像头条和抖音等产品,在晚上到睡觉之前,用户的使用需求很高,这个时候对实时计算性能要求也非常高,用户睡觉后,使用需求下降,此时对性能的要求相对较低,弹性就可以往下放,云原生的弹性优势在这个场景下得到了非常好的体现。
此外,团队还通过高效的分布式引擎来解决服务性能问题:
- 多方式加速查询,通过 SSD、RDMA、PMEM、内存等手段,提升查询及 Shuffle 效率
- 物化视图满足数据预计算
- 用 C++ 重写向量化引擎,提升整体效率
几个改变下来,可以满足像头条、抖音等产品实时的写入、更新、高并发要求以及数据的可视化,用户在产品内进行点击动作后就可以立即推送其关心或感兴趣的视频和新闻。
实时服务分析引擎
字节团队研发了新一代面向大数据场景的实时服务分析系统,既能够满足用户高 QPS,低 Latency 的在线 Serving 需求,也能满足用户对于海量数据的实时分析需求。
传统的 OLAP 分析模式实际上是静态的,在分析的时候需要预设好的视图或模型,海量分析时,通过预设的分析模型,分析出来的结果给到 Serving 对应的数据库,如 HBase,Redis,MySQL,在这个过程中 Serving 跟分析是分离的。
同时字节团队在业务的决策过程中发现,用 OLAP 的用户对分析的要求实际上是不固定的,且与 OLAP 本身的现状不相符,用户需要的是灵活、不固定、按需的分析。
因此,我们对实时分析的服务引擎做了两点优化:
1、服务与分析整合,使分析和服务一体化;
2、支持海量数据实时写入、实时更新、实时分析,支持标准 SQL(兼容MySQL语法)。
实时服务分析引擎典型场景
字节内部在使用实时服务的典型场景主要是推荐类的特征分析,如推荐中用的机器学习特征,这类场景带来了新的挑战:
- 数据需要实时写入,实时查询,用户需要数据实时可见;
- 数据写入吞吐大;
- 查询并发高(QPS 百万级别),对于查询时延要求(毫秒级别);用户特征明细数据庞大,任意时间窗口的在线聚合难以满足时延的需求;
- 当前没有一个系统能够满足用户所有需求,用户通常需要 KV+OLAP+Batch 来满足业务需求。
对于这些挑战,字节团队做了两个优化:一是使用 MV 对明细数据进行聚合,二是通过脏读来满足用户对时效性的要求。
以上,是字节云原生部门的两个重点的产品,流式数仓和实时服务分析引擎。
火山引擎云原生计算
 火山引擎云原生计算整体架构
火山引擎云原生计算整体架构
火山引擎产品的特点是,基于字节内部业务孵化,经过了大规模的实践检验后才进行商业化,技术比较成熟,相比开源最大的特点是云原生化。
火山引擎云原生计算的大数据整体框架,共由4部分组成。最中间部分是核心引擎:
- 用于流式计算的 Serverless Flink
- 用于批式计算的 Serverless Spark
- 云原生消息引擎BMQ和开放日志搜索 OpenSearch
- 用于存储的火山引擎自研的大数据统一存储 CloudFS
上述引擎基于开源,但根据字节的业务特性进行了增强和加固。
上层是引擎数据管理控制,包括Quata的服务,租户管理服务,运行时管理服务,API网关、交付部署等模块,满足云原生化引擎的管理和控制。
下层是云原生计算的运维平台,包括组件服务的生命周期管理,helmchart、日志审计监控等易用性功能,提供容灾等高可用的能力,提升产品已交付可运维能力。
最下层是基础底座,支持火山引擎的云原生 公有云版本的VKE/VCI,混合云版本和客户自有K8S的云原生环境,还支持多云管理和混合部署,提升计算链路使用过程中的资源利用效率。
Q&A
1、数据源做 ETL 写入到单表时 Exact Once 的度怎么保证?
采用了 Flink 的 Exact Once 特性。
2、Starrocks 的性能对比测试
据了解目前没有过性能的对比测试,另外,字节内部的站内场景比较多,碰到的问题也比较多,我们是基于云原生改造的,所以在 QPS 上做得比较深的,这是我们跟开源不太一样的地方。
3、怎么样看待 Flink Table Store
Flink Table Store 在流批一体的场景下是有非常好的能力,目前字节内部使用的 Flink Table Store 跟开源并行同步的。