神经网络学习小记录73——Pytorch CA(Coordinate attention)注意力机制的解析与代码详解
神经网络学习小记录73——Pytorch CA(Coordinate attention)注意力机制的解析与代码详解
- 学习前言
- 代码下载
- CA注意力机制的概念与实现
- 注意力机制的应用
学习前言
CA注意力机制是最近提出的一种注意力机制,全面关注特征层的空间信息和通道信息。

代码下载
Github源码下载地址为:
https://github.com/bubbliiiing/yolov4-tiny-pytorch
复制该路径到地址栏跳转。
CA注意力机制的概念与实现
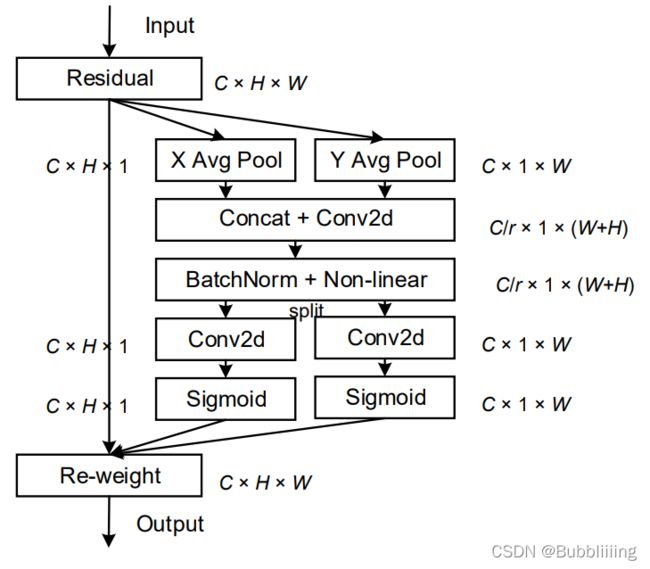
该文章的作者认为现有的注意力机制(如CBAM、SE)在求取通道注意力的时候,通道的处理一般是采用全局最大池化/平均池化,这样会损失掉物体的空间信息。作者期望在引入通道注意力机制的同时,引入空间注意力机制,作者提出的注意力机制将位置信息嵌入到了通道注意力中。
CA注意力的实现如图所示,可以认为分为两个并行阶段:
将输入特征图分别在为宽度和高度两个方向分别进行全局平均池化,分别获得在宽度和高度两个方向的特征图。假设输入进来的特征层的形状为[C, H, W],在经过宽方向的平均池化后,获得的特征层shape为[C, H, 1],此时我们将特征映射到了高维度上;在经过高方向的平均池化后,获得的特征层shape为[C, 1, W],此时我们将特征映射到了宽维度上。
然后将两个并行阶段合并,将宽和高转置到同一个维度,然后进行堆叠,将宽高特征合并在一起,此时我们获得的特征层为:[C, 1, H+W],利用卷积+标准化+激活函数获得特征。
之后再次分开为两个并行阶段,再将宽高分开成为:[C, 1, H]和[C, 1, W],之后进行转置。获得两个特征层[C, H, 1]和[C, 1, W]。
然后利用1x1卷积调整通道数后取sigmoid获得宽高维度上的注意力情况。乘上原有的特征就是CA注意力机制。
实现的python代码为:
class CA_Block(nn.Module):
def __init__(self, channel, reduction=16):
super(CA_Block, self).__init__()
self.conv_1x1 = nn.Conv2d(in_channels=channel, out_channels=channel//reduction, kernel_size=1, stride=1, bias=False)
self.relu = nn.ReLU()
self.bn = nn.BatchNorm2d(channel//reduction)
self.F_h = nn.Conv2d(in_channels=channel//reduction, out_channels=channel, kernel_size=1, stride=1, bias=False)
self.F_w = nn.Conv2d(in_channels=channel//reduction, out_channels=channel, kernel_size=1, stride=1, bias=False)
self.sigmoid_h = nn.Sigmoid()
self.sigmoid_w = nn.Sigmoid()
def forward(self, x):
_, _, h, w = x.size()
x_h = torch.mean(x, dim = 3, keepdim = True).permute(0, 1, 3, 2)
x_w = torch.mean(x, dim = 2, keepdim = True)
x_cat_conv_relu = self.relu(self.bn(self.conv_1x1(torch.cat((x_h, x_w), 3))))
x_cat_conv_split_h, x_cat_conv_split_w = x_cat_conv_relu.split([h, w], 3)
s_h = self.sigmoid_h(self.F_h(x_cat_conv_split_h.permute(0, 1, 3, 2)))
s_w = self.sigmoid_w(self.F_w(x_cat_conv_split_w))
out = x * s_h.expand_as(x) * s_w.expand_as(x)
return out
注意力机制的应用
注意力机制是一个即插即用的模块,理论上可以放在任何一个特征层后面,可以放在主干网络,也可以放在加强特征提取网络。
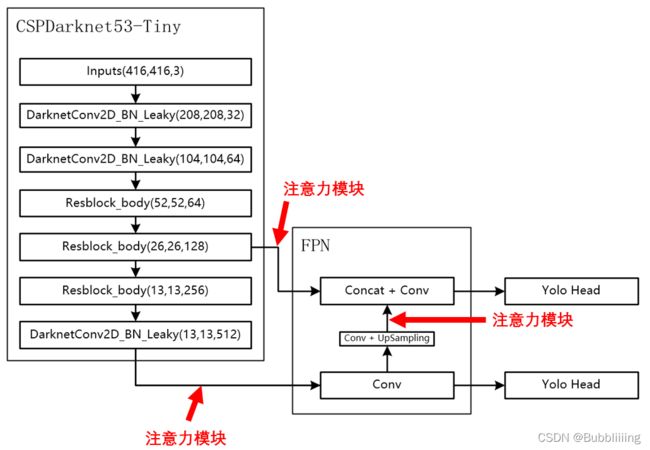
由于放置在主干会导致网络的预训练权重无法使用,本文以YoloV4-tiny为例,将注意力机制应用加强特征提取网络上。
如下图所示,我们在主干网络提取出来的两个有效特征层上增加了注意力机制,同时对上采样后的结果增加了注意力机制。
实现代码如下:
attention_block = [se_block, cbam_block, eca_block, CA_Block]
#---------------------------------------------------#
# 特征层->最后的输出
#---------------------------------------------------#
class YoloBody(nn.Module):
def __init__(self, anchors_mask, num_classes, phi=0):
super(YoloBody, self).__init__()
self.phi = phi
self.backbone = darknet53_tiny(None)
self.conv_for_P5 = BasicConv(512,256,1)
self.yolo_headP5 = yolo_head([512, len(anchors_mask[0]) * (5 + num_classes)],256)
self.upsample = Upsample(256,128)
self.yolo_headP4 = yolo_head([256, len(anchors_mask[1]) * (5 + num_classes)],384)
if 1 <= self.phi and self.phi <= 3:
self.feat1_att = attention_block[self.phi - 1](256)
self.feat2_att = attention_block[self.phi - 1](512)
self.upsample_att = attention_block[self.phi - 1](128)
def forward(self, x):
#---------------------------------------------------#
# 生成CSPdarknet53_tiny的主干模型
# feat1的shape为26,26,256
# feat2的shape为13,13,512
#---------------------------------------------------#
feat1, feat2 = self.backbone(x)
if 1 <= self.phi and self.phi <= 3:
feat1 = self.feat1_att(feat1)
feat2 = self.feat2_att(feat2)
# 13,13,512 -> 13,13,256
P5 = self.conv_for_P5(feat2)
# 13,13,256 -> 13,13,512 -> 13,13,255
out0 = self.yolo_headP5(P5)
# 13,13,256 -> 13,13,128 -> 26,26,128
P5_Upsample = self.upsample(P5)
# 26,26,256 + 26,26,128 -> 26,26,384
if 1 <= self.phi and self.phi <= 3:
P5_Upsample = self.upsample_att(P5_Upsample)
P4 = torch.cat([P5_Upsample,feat1],axis=1)
# 26,26,384 -> 26,26,256 -> 26,26,255
out1 = self.yolo_headP4(P4)
return out0, out1