SS-ELM-AE与S2-BLS相关论文阅读记录
Broad learning system for semi-supervised learning
摘要:本文认为,原始BLS采用的稀疏自编码器来生成特征节点是一种无监督学习方法,这意味着忽略了标注数据的一些信息,并且难以保证同类样本之间的相似性和相邻性,同时SS-BLS和BLS都是构造线性模型,当不同类的样本分布存在重叠时,难以取得良好的分类效果。因此本文提出了一种新的半监督BLS——S2-BLS。
SS-ELM-AE
本文认为,SS-BLS或者是SS-ELM在引入非监督信息,即流形化的时候,考虑到选取k近邻点的情况,但是这种方法可能存在的缺点就是如果大多数标注样本它们所选择的k个近邻点都是标注样本,然后大多数无标注样本所选择的k个近邻点都是无标注样本,那么就没有充分利用到标注样本和未标注样本之间的关系。因此将SS-ELM-AE的目标函数定义为:
L S S − E L M − A E = 1 2 ∥ H W − X ∥ F 2 + C 2 ∥ W ∥ F 2 + λ 2 ( G L L + G L U ) L_{SS-ELM-AE}=\frac{1}{2}\Vert HW-X\Vert^2_F+\frac{C}{2}\Vert W\Vert^2_F+\frac{\lambda}{2}(G_{LL}+G_{LU}) LSS−ELM−AE=21∥HW−X∥F2+2C∥W∥F2+2λ(GLL+GLU)
其中X代表所有样本。而 G L L 、 G L U G_{LL}、G_{LU} GLL、GLU分别代表标注样本内部之间的信息以及标注样本和无标注样本之间的信息。
对于标注样本,其相似度矩阵定义为:
S i j L = { 1 y i , y j ∈ t 0 o t h e r w i s e S^L_{ij}=\begin{cases}1\quad y_i,y_j \in t\\0\quad otherwise\end{cases} SijL={1yi,yj∈t0otherwise
就是属于同类的相似度为1,否则为0。因此 G L L G_{LL} GLL表示为:
G L L = 1 2 ∑ i = 1 l ∑ j = 1 l S i j L ∥ g ( x i ) − g ( x j ) ∥ F 2 G_{LL}=\frac{1}{2}\sum_{i=1}^l\sum_{j=1}^lS^L_{ij}\Vert g(x_i)-g(x_j)\Vert ^2_F GLL=21i=1∑lj=1∑lSijL∥g(xi)−g(xj)∥F2
其中 g ( x ) g(x) g(x)代表模型对样本的输出。
而对于未标注样本,其相似性矩阵定义为:
S i j L U = { 1 x i ∈ k n n ( x j ) , j ∗ o r x j ∈ k n n ( x i ) , i ∗ 0 o t h e r w i s e S^{LU}_{ij}=\begin{cases}1\quad x_i\in knn(x_j),j^* ~~or ~~x_j\in knn(x_i),i^*\\0\quad otherwise\end{cases} SijLU={1xi∈knn(xj),j∗ or xj∈knn(xi),i∗0otherwise
其中 j ∗ j^* j∗表示如果 x j x_j xj是标注样本,那么其k个近邻点要从未标注样本之中选择。因此
G L U = 1 2 ∑ i = 1 l + u ∑ j = 1 l + u S i j L U ∥ g ( x i ) − g ( x j ) ∥ F 2 G_{LU}=\frac{1}{2}\sum_{i=1}^{l+u}\sum_{j=1}^{l+u}S^{LU}_{ij}\Vert g(x_i)-g(x_j)\Vert ^2_F GLU=21i=1∑l+uj=1∑l+uSijLU∥g(xi)−g(xj)∥F2
那么可以将该矩阵写为:
S L U = ( 0 L L S L U S U L S U U ) S_{LU}=\left(\begin{matrix}0_{LL}\quad S_{LU}\\S_{UL }\quad S_{UU}\end{matrix}\right) SLU=(0LLSLUSULSUU)
斜对角线两个矩阵应该是转置关系。 S U U S_{UU} SUU就是简单的knn来计算。因此有:
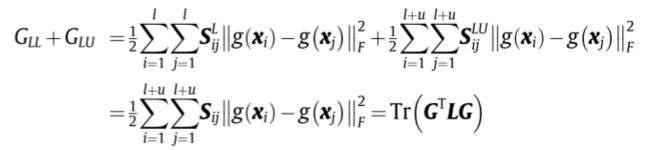
其中 G = [ g ( x 1 ) ; . . . ; g ( x l + u ) ] G=[g(x_1);...;g(x_{l+u})] G=[g(x1);...;g(xl+u)]。L定义为:
L = D − S D = d i a g ( d 1 , . . . , d l + u ) , d i = ∑ i = 1 l + u S i j S = ( S L S L U S U L S U U ) L=D-S\\D=diag(d_1,...,d_{l+u}),d_i=\sum_{i=1}^{l+u}S_{ij}\\S=\left(\begin{matrix}S^L\quad S_{LU}\\S_{UL}\quad S_{UU}\end{matrix}\right) L=D−SD=diag(d1,...,dl+u),di=i=1∑l+uSijS=(SLSLUSULSUU)
因此可以推导出:
L S S − E L M − A E = 1 2 ∥ H W − X ∥ F 2 + C 2 ∥ W ∥ F 2 + λ 2 T r ( W T H T L H W ) L_{SS-ELM-AE}=\frac{1}{2}\Vert HW-X\Vert^2_F+\frac{C}{2}\Vert W\Vert^2_F+\frac{\lambda}{2}Tr(W^TH^TLHW) LSS−ELM−AE=21∥HW−X∥F2+2C∥W∥F2+2λTr(WTHTLHW)
当输出节点输出多于隐藏层节点数目,可解出:

否则:

注意这里的损失函数是重构误差,因此可以看成是一个结合ELM思想的AE,是用来求解输入到隐藏层的权重的,而不是像ELM最终求解隐藏层到输出的权重的。
因此求解输入到特征节点映射的权重过程为:

S2-BLS
该算法就是对原有SS-BLS算法的改良,其利用了同样样本间的相似性和近邻点间的相似性信息来获取映射后的特征,同时考虑了类内紧性和类间可分性,获得更好的判别模型。具体来说:
其特征节点的定义比较特殊,用到了非线性激活函数,即:
Z i = ϕ i ( X W e i T ) , i = 1 , 2 , . . . , n Z_i=\phi_{i}(XW^T_{ei}),i=1,2,...,n Zi=ϕi(XWeiT),i=1,2,...,n
其中权重 W e i W_{ei} Wei正是通过SS-ELM-AE来获得的,而 ϕ \phi ϕ是非线性函数。然后狗仔增强节点的过程与普通BLS相同,因此得到 P = [ Z n ∣ H m ] P=[Z^n\mid H^m] P=[Zn∣Hm]
那么在计算输出权重时,其考虑了类内紧性和类间可分性,即:
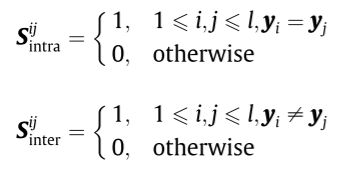
因此构造的损失项为:

其中 F = [ F 1 ; . . . ; F l + u ] F=[F_1;...;F_{l+u}] F=[F1;...;Fl+u]为对每个样本模型的预测向量, L i n t r a = D i n t r a − S i n t r a = d i a g ( d 1 i n t r a , . . . , d l + u i n t r a ) L_{intra}=D^{intra}-S_{intra}=diag(d^{intra}_1,...,d^{intra}_{l+u}) Lintra=Dintra−Sintra=diag(d1intra,...,dl+uintra), d i i n t r a = ∑ i = 1 l + u S i n t r a i j d^{intra}_i=\sum_{i=1}^{l+u}S^{ij}_{intra} diintra=∑i=1l+uSintraij。

其中 L i n t e r L_{inter} Linter也类似。
那么结合这两个L矩阵,可以用参数进行衡量。因此目标函数为:

其中
U = ( U l × l , 0 0 0 ) U l × l = d i a g ( 1 , . . . , 1 ) F = P β , β 为连接权重 L ~ = η L i n t r a − ( 1 − η ) L i n t e r U=\left(\begin{matrix}U_{l\times l},\quad 0\\~~~0\quad ~~~~0\end{matrix}\right)\\U_{l\times l}=diag(1,...,1)\\F=P\beta, ~~~~\beta 为连接权重\\\tilde{L}=\eta L_{intra}-(1-\eta)L_{inter} U=(Ul×l,0 0 0)Ul×l=diag(1,...,1)F=Pβ, β为连接权重L~=ηLintra−(1−η)Linter
当样本数目多于隐藏层节点数目,可解出

否则:
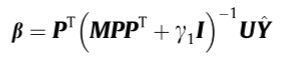
其示意图大致如下所示:

伪代码如下所示:

总结
这篇文章从两部分作为创新点,一是原先BLS的AE寻求特征节点映射的部分,这部分它结合了ELM的思想来求解权重向量,第二部分是在求解链接输出的权重时,加入了类内和类间样本之间的关系矩阵。